Anime Illust Diffusion XL - v0.5-alpha
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder





Empfohlene Prompts
frieren from sousou no frieren,impasto style,beautiful color, detailed, aesthetic
best quality,masterpiece,vivid color,1girl,solo,bangs
Empfohlene Negative Prompts
worst quality:1.3,low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxl_neg
Empfohlene Parameter
samplers
steps
cfg
resolution
vae
other models
Empfohlene Hires (Hochauflösungs-) Parameter
denoising strength
Tipps
Verringern Sie das Gewicht von Künstler-Stil Auslösewörtern, z. B. (by xxx:0.6).
Sortieren Sie Ihre Eingabeaufforderungen für bessere Ergebnisse.
Verwenden Sie das VAE des Modells oder sdxl-vae.
Versions-Highlights
143 neue Auslösewörter hinzugefügt. Diese Version ist eine Beta-Version von AIDXLv0.5. Die neuen Stile sind nicht stabil. Für ein besseres Erlebnis empfehle ich AIDXLv0.41.
Added 143 neue Auslösewörter. Diese Version ist eine Beta von AIDXLv0.5. Die neuen Stile sind nicht stabil. Ich empfehle AIDXLv0.41 für eine bessere Erfahrung.
Ersteller-Sponsoren
Rechenleistungssponsoring: Dank an die @NieTa Community (捏Ta (nieta.art)) für die Bereitstellung von Rechenleistung;
Datenunterstützung: Dank an @KirinTea_Aki (KirinTea_Aki Creator Profile | Civitai) und @Chenkin (Civitai | Share your models) für umfangreiche Datenunterstützung;
Ohne sie gäbe es keine Version 0.7.
Modelleinführung (Englischer Teil)
I Inhalt
In dieser Einführung lernen Sie:
Modelinformationen (siehe Abschnitt II);
Gebrauchsanweisungen (siehe Abschnitt III);
Trainingsparameter (siehe Abschnitt IV);
Liste der Auslösewörter (siehe Anhang Teil A)
II AIDXL
Anime Illustration Diffusion XL, oder AIDXL, ist ein Modell, das speziell für die Erzeugung stilisierter Anime-Illustrationen entwickelt wurde. Es verfügt über mehr als 800 (mit kontinuierlichen Updates) integrierte Illustrationsstile, die durch bestimmte Auslösewörter aktiviert werden (siehe Anhang A).
Vorteile:
Flexible Komposition statt traditioneller KI-Posing.
Feinfühlige Details statt chaotischem Durcheinander.
Bessere Kenntnis von Anime-Charakteren.
III Benutzerhandbuch
1 Basisanwendung
1.1 Eingabeaufforderung
Auslösewörter: Fügen Sie die im Anhang A bereitgestellten Auslösewörter hinzu, um das Bild zu stilisieren. Geeignete Auslösewörter verbessern die Qualität erheblich;
Es wird empfohlen, das Gewicht für Künstlerstil-Auslösewörter zu reduzieren, z. B. (by xxx:0.6).
Semantische Sortierung: Das Sortieren Ihrer Eingabeaufforderungs-Tags oder Sätze hilft dem Modell, Ihre Bedeutung besser zu verstehen.
Empfohlene Tag-Reihenfolge: Auslösewort (by xxx) -> Charakter (ein Mädchen namens frieren aus der sousou no frieren Serie) -> Rasse (Elf) -> Komposition (Cowboy-Shot) -> Stil (Impasto-Stil) -> Thema (Fantasy-Thema) -> Hauptumgebung (im Wald, tagsüber) -> Hintergrund (Verlaufshintergrund) -> Aktion (auf dem Boden sitzend) -> Ausdruck (ausdruckslos) -> Hauptmerkmale (weißes Haar) -> Körpermerkmale (Doppelzöpfe, grüne Augen, gespaltener Lippenbereich) -> Kleidung (trägt ein weißes Kleid) -> Kleidung Zubehör (Rüschen) -> andere Gegenstände (eine Katze) -> Sekundäre Umgebung (Gras, Sonnenschein) -> Ästhetik (schöne Farbe, detailliert, ästhetisch) -> Qualität ((beste Qualität:1.3))
Negative Eingabeaufforderungen: (schlechteste Qualität:1.3), niedrige Qualität, niedrige Auflösung, chaotisch, abstrakt, hässlich, entstellt, schlechte Anatomie, Entwurf, deformierte Hände, verschmolzene Finger, Signatur, Text, Mehrfachansichten
1.2 Generierungsparameter
Auflösung: Stellen Sie sicher, dass die Gesamtpixelanzahl (=Breite * Höhe) ungefähr 1024*1024 beträgt und Breite und Höhe durch 32 teilbar sind, damit AIDXL die besten Ergebnisse liefert. Zum Beispiel 832x1216 (2:3), 1216x832 (3:2) und 1024x1024 (1:1) usw.
Sampler und Schritte: Verwenden Sie den "Euler Ancester" Sampler, der im WebUI als Euler A bezeichnet wird. Probieren Sie ungefähr ~28 Schritte bei einer CFG-Skala von 7 bis 9 aus.
'Verfeinerung': Das Bild, das aus text2image erzeugt wird, ist manchmal unscharf; in diesen Fällen sollten Sie es durch image2image, Inpainting oder Ähnliches 'verfeinern'.
Für einfaches Hochskalieren können Sie sich auf folgenden Link beziehen: Upscale to huge sizes and add detail with SD Upscale, it's easy! : r/StableDiffusion (reddit.com)
Andere Komponenten: Es ist nicht nötig, ein Verfeinerungsmodell zu verwenden. Nutzen Sie das VAE des Modells selbst oder das
sdxl-vae.
F: Wie reproduziere ich das Titelseitenbild? Warum erhalte ich bei gleicher Generierungskonfiguration nicht dasselbe Bild wie auf dem Cover?
A: Weil die Generierungsparameter auf dem Cover NICHT die Parameter für text2image sind, sondern die Parameter für image2image (zum Hochskalieren). Das Ausgangsbild wurde größtenteils mit dem Euler Ancester Sampler anstelle des DPM Samplers erzeugt.
2 Spezielle Nutzung
2.1 Generalisierte Stile
Ab Version 0.7 fasst AIDXL mehrere ähnliche Stilarten zusammen und führt generalisiert-stil Auslösewörter ein. Diese Auslösewörter repräsentieren jeweils eine häufige Anime-Illustrationsstil-Kategorie. Beachten Sie, dass generalisierte Stil-Auslösewörter nicht unbedingt die künstlerische Bedeutung des Wortes entsprechen, sondern spezielle Auslösewörter sind, die neu definiert wurden.
2.2 Charaktere
Ab Version 0.7 wurde das Training von Charakteren verstärkt. Die Wirkung einiger Charakter-Auslösewörter kann bereits den Effekt von Lora erreichen und trennt Konzepte des Charakters gut von der eigenen Kleidung.
Die Charakter-Auslösung erfolgt mit: {character} \({copyright}\). Beispiel: Um die Heldin Lucy aus der Animation "Cyberpunk: Edgerunners" auszulösen, verwenden Sie lucy \(cyberpunk\); um den Charakter Gan Yu im Spiel "Genshin Impact" auszulösen, verwenden Sie ganyu \(genshin impact\). Hierbei sind "lucy" und "ganyu" Charakternamen, "\(cyberpunk\)" und "\(genshin impact\)" sind die Ursprünge der entsprechenden Charaktere, und die Klammern werden mit "\" maskiert, damit sie nicht als gewichtete Tags interpretiert werden. Für einige Charaktere ist der Copyright-Teil nicht notwendig.
Ab Version v0.8 gibt es eine einfachere Auslöseart: ein {Mädchen/Junge} namens {character} aus der {copyright}-Serie.
Eine Liste der Charakter-Auslösewörter finden Sie unter: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Außerdem sind einige zusätzliche Auslösewörter, die in diesem Dokument nicht erwähnt sind, möglicherweise ebenfalls enthalten.
Manche Charaktere benötigen einen zusätzlichen Auslöse-Schritt. Wenn der Charakter nicht vollständig mit einem einzigen Auslösewort dargestellt wird, müssen die Hauptmerkmale des Charakters in die Eingabeaufforderung aufgenommen werden.
AIDXL unterstützt das Ankleiden von Charakteren. Charakter-Auslösewörter enthalten in der Regel keine Kleidungseigenschaften des Charakters. Möchten Sie die Kleidung des Charakters hinzufügen, müssen Sie das Kleidungs-Tag in der Eingabeaufforderung ergänzen. Zum Beispiel beschreibt silver evening gown, plunging neckline das Kleid des Charakters St. Louis (Luxurious Wheels) aus dem Spiel Azur Lane. Ebenso können Sie die Kleidung eines beliebigen Charakters den Eingabeaufforderungen anderer Charaktere hinzufügen.
2.3 Qualitäts-Tags
Qualitäts- und ästhetische Tags sind offiziell trainiert. Das Hinzufügen dieser Tags in der Eingabeaufforderung beeinflusst die Qualität des generierten Bildes.
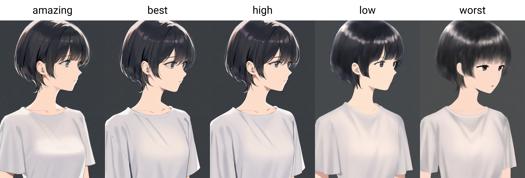
Ab Version 0.7 werden Qualitäts-Tags offiziell trainiert und eingeführt. Die Qualität wird in sechs Stufen unterteilt, von der besten bis zur schlechtesten: amazing quality, best quality, high quality, normal quality, low quality und worst quality.
Es wird empfohlen, Qualitäts-Tags mit erhöhtem Gewicht zu verwenden, z. B. (amazing quality:1.5).
2.4 Ästhetik-Tags
Seit Version 0.7 wurden Ästhetik-Tags eingeführt, die die speziellen ästhetischen Eigenschaften von Bildern beschreiben.
2.5 Stilfusion
Sie können einige Stile zu Ihrem benutzerdefinierten Stil zusammenführen. „Fusionieren“ bedeutet hier, mehrere Stil-Auslösewörter gleichzeitig zu verwenden. Zum Beispiel: chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Einige Tipps:
Steuern Sie das Gewicht und die Reihenfolge der Stile, um den Stil anzupassen.
Fügen Sie die Stil-Tags ans Ende Ihrer Eingabeaufforderung an, statt sie an den Anfang zu stellen.
IV Trainingsstrategie & Parameter
AIDXLv0.1
Verwendet SDXL1.0 als Basismodell, trainiert mit etwa 22.000 markierten Bildern ca. 100 Epochen auf einem Cosine-Scheduler mit einer Lernrate von 5e-6 und einer Anzahl Zyklen = 1, um Modell A zu erhalten. Danach mit einer Lernrate von 2e-7 und denselben anderen Parametern trainiert, um Modell B zu erhalten. Das Modell AIDXLv0.1 entsteht durch Zusammenführen von Modell A und B.
AIDXLv0.51
Trainingsstrategie
Fortsetzen des Trainings von AIDXLv0.5 in drei nacheinander ablaufenden Trainingsdurchläufen:
Langes Caption-Training: Verwenden Sie den gesamten Datensatz mit einigen manuell beschrifteten Bildern. Trainieren Sie sowohl das U-Net als auch den Text-Encoder mit dem AdamW8bit-Optimierer, einer hohen Lernrate (ca. 1.5e-6) und Cosine Scheduler. Stoppen Sie das Training, wenn die Lernrate unter eine Schwelle (ca. 5e-7) fällt.
Kurzcaption-Training: Starten Sie das Training erneut aus dem Ergebnis von Schritt 1 mit denselben Parametern und Strategien, aber einem Datensatz mit kürzeren Captions.
Verfeinerungsschritt: Bereiten Sie eine Teilmenge des Datensatzes aus Schritt 1 vor, die manuell ausgewählte qualitativ hochwertige Bilder enthält. Starten Sie das Training erneut aus Schritt 2 mit niedriger Lernrate (ca. 7.5e-7) und einem Cosine Scheduler mit 5 bis 10 Neustarts. Trainieren Sie so lange, bis das Ergebnis ästhetisch gut ist.
Feste Trainingsparameter
Kein zusätzliches Rauschen wie Rauschoffset.
Min SNR Gamma = 5: Beschleunigt das Training.
Volle bf16-Präzision.
AdamW8bit Optimierer: Ausgewogenheit zwischen Effizienz und Leistung.
Datensatz
Auflösung: 1024x1024 Gesamtauflösung (= Höhe mal Breite) mit modifizierter SDXL-Standard-Bucket-Strategie.
Beschriftung: Beschriftet durch WD14-Swinv2-Modell mit Schwellenwert 0.35.
Naheinstellungen zuschneiden: Bilder in mehrere Nahaufnahmen zuschneiden. Sehr nützlich, wenn die Trainingsbilder groß oder selten sind.
Auslösewörter: Erhalt des ersten Tags der Bilder als Auslösewort.
AIDXLv0.6
Trainingsstrategie
Fortsetzung des Trainings von AIDXLv0.52 mit adaptiver Wiederholungsstrategie – Für jedes beschriftete Bild im Datensatz wird die Anzahl der Trainingswiederholungen basierend auf den folgenden Regeln erhöht:
Regel 1: Je höher die Qualität des Bildes, desto mehr Wiederholungen;
Regel 2: Gehört das Bild zu einer Stilklasse:
Ist die Klasse noch nicht gut angepasst oder unterangepasst, wird die Wiederholungsanzahl der Klasse manuell erhöht oder automatisch so gesteigert, dass die Gesamtwiederholungen der Daten in der Klasse ungefähr 100 erreichen.
Ist die Klasse bereits gut angepasst oder überangepasst, wird die Wiederholungsanzahl manuell auf 1 gesetzt und bei geringer Qualität der Daten fallen gelassen.
Regel 3: Die maximale Wiederholungszahl überschreitet eine bestimmte Schwelle, die etwa 10 beträgt, nicht.
Diese Strategie hat folgende Vorteile:
Sie schützt die ursprünglichen Informationen des Modells vor den neuen Trainingsdaten und folgt dem Gedanken regulierter Bilder;
Sie macht die Wirkung der Trainingsdaten besser steuerbar;
Sie balanciert das Training zwischen verschiedenen Klassen, indem weniger gut angepasste Klassen motiviert und überangepasste Klassen gebremst werden;
Sie spart erheblich Rechenressourcen und erleichtert das Hinzufügen neuer Stile in das Modell.
Feste Trainingsparameter
Wie bei AIDXLv0.51.
Datensatz
Der Datensatz von AIDXLv0.6 basiert auf AIDXLv0.51. Zusätzlich wurden folgende Optimierungen angewendet:
Semantische Sortierung der Beschriftungen: Sortierung der Tags nach semantischer Reihenfolge, z. B. "gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun".
Entfernen von doppelten Tags: Duplikate werden entfernt, wobei diejenigen beibehalten werden, die die meisten Informationen enthalten. Duplikate sind Tags mit ähnlicher Bedeutung, z. B. "long hair" und "very long hair".
Zusätzliche Tags: Manuelles Hinzufügen weiterer Tags zu allen Bildern, z. B. "high quality", "impasto" usw. Dies kann mithilfe einiger Werkzeuge schnell durchgeführt werden.
V Besonderer Dank
Rechenleistungssponsoring: Dank an die @NieTa Community (捏Ta (nieta.art)) für die Bereitstellung von Rechenleistung;
Datenunterstützung: Dank an @KirinTea_Aki (KirinTea_Aki Creator Profile | Civitai) und @Chenkin (Civitai | Share your models) für umfangreiche Datenunterstützung;
Ohne sie gäbe es keine Version 0.7.
VI AIDXL vs AID
2023/08/08. AIDXL wurde mit demselben Trainingsdatensatz wie AIDv2.10 trainiert, übertrifft jedoch AIDv2.10. AIDXL ist intelligenter und kann viele Dinge leisten, die auf SD1.5 basierende Modelle nicht können. Es kann Konzepte gut unterscheiden, Bilddetails erlernen und Kompositionen bewältigen, die für SD1.5 und AID schwierig oder unmöglich sind. Insgesamt hat es enormes Potenzial. Ich werde AIDXL weiterhin aktualisieren.
VII Sponsoring
Wenn Sie unsere Arbeit mögen, können Sie uns gerne über Ko-fi (https://ko-fi.com/eugeai) unterstützen, um unsere Forschung und Entwicklung zu fördern. Vielen Dank für Ihre Unterstützung~
Modellvorstellung (Chinesischer Teil)
I Inhaltsverzeichnis
In dieser Einführung erfahren Sie:
Modellvorstellung (siehe Abschnitt II);
Gebrauchsanleitung (siehe Abschnitt III);
Trainingsparameter (siehe Abschnitt IV);
Liste der Auslösewörter (siehe Anhang A)
II Modellvorstellung
Anime Illustrationsdesign XL, auch AIDXL genannt, ist ein Modell, das sich auf die Erzeugung von Anime-Illustrationen spezialisiert hat. Es integriert über 800 integrierte Illustrationsstile (die mit Updates weiter wachsen) und wird durch bestimmte Auslösewörter aktiviert (siehe Anhang A).
Vorteile: Mutige Komposition, kein gestellter Eindruck, Hauptmotiv im Fokus, keine überflüssigen Details, kennt viele Anime-Charaktere (ausgelöst durch japanische Namens-Pinyin der Figuren, z. B. „ayanami rei“ für Charakter „Rei Ayanami“, „kamado nezuko“ für „Nezuko Kamado“).
III Gebrauchsanleitung (fortlaufend aktualisiert)
1 Basisverwendung
1.1 Eingabeaufforderung schreiben
Benutzen von Auslösewörtern: Verwenden Sie die im Anhang A bereitgestellten Auslösewörter, um Bilder stilistisch zu gestalten. Passende Auslösewörter verbessern deutlich die Qualität;
Eingabeaufforderung als Tags: Beschreiben Sie das Objekt mit getaggten Eingabeaufforderungen;
Sortierung der Eingabeaufforderung: Das Sortieren Ihrer Eingabeaufforderung hilft dem Modell, Bedeutungen besser zu verstehen. Empfohlene Reihenfolge:
Auslösewort (by xxx) -> Hauptfigur (1girl) ->Charakter (frieren) -> Rasse (elf) ->Komposition (cowboy shot) -> Stil (impasto) -> Thema (fantasy) -> Hauptumgebung (forest, day) ->Hintergrund (gradient background) -> Aktion (sitting) -> Gesichtsausdruck (expressionless) ->Wesentliche Charaktermerkmale (white hair) ->Körpermerkmale (twintails, green eyes, parted lip) ->Kleidung (white dress) -> Kleidungszubehör (frills) -> andere Gegenstände (magic wand) -> Nebenumgebung (grass, sunshine) ->Ästhetik (beautiful color, detailed, aesthetic) ->Qualität (best quality)
Negative Eingabeaufforderungen: schlechteste Qualität, niedrige Qualität, niedrige Auflösung, chaotisch, abstrakt, hässlich, entstellt, schlechte Anatomie, deformierte Hände, verschmolzene Finger, Signatur, Text, Mehrfachansichten
1.2 Generierungsparameter
Auflösung: Stellen Sie sicher, dass die Gesamtauflösung (Auflösung = Höhe x Breite) ca. 1024x1024 beträgt und Breite und Höhe durch 32 teilbar sind. Zum Beispiel: 832x1216 (3:2), 1216x832 (3:2), oder 1024x1024 (1:1).
Kein "Clip Skip" (Clip Skip = 1).
Sampler und Schritte: Verwenden Sie den "euler_ancester" Sampler, im WebUI als Euler A bekannt. Sampling mit 28 Schritten bei CFG Scale 7.
Kein Verfeinerungsmodell (Refiner) erforderlich.
Verwenden Sie das VAE des Basismodells oder sdxl-vae.
2 Spezielle Anwendung
2.1 Generalisierte Stilarten
Version 0.7 fasst ähnliche Illustrationsstile zusammen und führt allgemeine Stil-Auslösewörter ein. Diese repräsentieren häufige Anime-Illustrationsstil-Kategorien.
Beachten Sie, dass generalisierte Stilauslösewörter nicht unbedingt der künstlerischen Bedeutung ihres Wortes entsprechen, sondern speziell neu definiert sind.
2.2 Charaktere
Version 0.7 verstärkte das Training von Charakteren. Einige Charakter-Auslösewörter erreichen bereits Wirkung wie Lora und trennen Konzepte von Kleidung gut.
Charakterauslösung mit Charaktername \(Werk\). Beispiel: Für Lucy aus "Cyberpunk: Edgerunners" lucy \(cyberpunk\); für Ganyu aus "Genshin Impact" ganyu \(genshin impact\). Klammern werden maskiert, damit sie nicht als gewichtete Tags interpretiert werden. Für einige Charaktere ist die Urheberrechtsangabe nicht notwendig.
Liste der Charakter-Auslösewörter unter: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2.
Kann nicht vollständig mit einem Wort ausgelöst werden, dann fügen Sie Hauptmerkmale zum Prompt hinzu.
AIDXL unterstützt Kostümänderungen. Charakter-Auslösewörter enthalten meist keine Kleidung. Um Kleidung hinzuzufügen, fügen Sie das Kleidungs-Tag hinzu, z. B. silver evening gown, plunging neckline für St. Louis aus Azur Lane. Sie können Kleidung beliebiger Charaktere beliebig zusammenführen.
2.3 Qualitäts-Tags
Ab Version 0.7 sind Qualitäts- und Ästhetik-Tags offiziell trainiert. Sie beeinflussen die Bildqualität, wenn sie an Prompts angehängt werden.
Dazu gehören sechs Qualitätsstufen: amazing quality, best quality, high quality, normal quality, low quality und worst quality.
2.4 Ästhetik-Tags
Seit 0.7 beschreiben diese spezielle ästhetische Eigenschaften von Bildern.
2.5 Stil Verschmelzung
Sie können mehrere Stil-Auslösewörter gleichzeitig verwenden, um Ihren eigenen Stil zu formen. Zum Beispiel: chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Tipps:
Steuern Sie Gewicht und Reihenfolge.
Fügen Sie diese Tags ans Ende an.
3 Hinweise
Verwenden Sie VAE-, Einbettungs- (embeddings) und Lora-Modelle, die SDXL unterstützen. Achtung: sd-vae-ft-mse-original unterstützt SDXL nicht; negative Text-Embeddings wie EasyNegative oder badhandv4 unterstützen SDXL ebenfalls nicht;
Für Version 0.61 und niedriger: Für die Bildgenerierung wird dringend empfohlen, das negative Text-Embedding speziell für das Modell zu verwenden (siehe Download bei Suggested Resources), da dies speziell für das Modell ausgelegt ist und fast nur positive Effekte hat;
Neue Auslösewörter in jeder Version sind anfangs schwächer oder instabil im Effekt.
IV Trainingsparameter
Basierend auf SDXL1.0 trainiert mit ca. 20.000 selbst markierten Bildern bei Lernrate 5e-6 auf einem Cosine Scheduler mit 1 Zyklus für ca. 100 Epochen, um Modell A zu erhalten. Danach bei Lernrate 2e-7 unter gleichen Bedingungen Modell B trainiert. Das Zusammenführen von A und B ergibt AIDXLv0.1.
Weitere Trainingsparameter siehe englische Beschreibung.
V Besonderer Dank
Rechenleistung: Dank an die @捏Ta Community (捏Ta (nieta.art)) für die Bereitstellung von Rechenleistung;
Datenunterstützung: Dank an @秋麒麟热茶 (KirinTea_Aki Creator Profile | Civitai) und @风吟 (Chenkin Creator Profile | Civitai) für große Datenunterstützung;
Ohne sie gäbe es keine Version 0.7.
VI Update-Log
2023/08/08: AIDXL wurde mit exakt demselben Trainingsdatensatz wie AIDv2.10 trainiert, übertrifft jedoch AIDv2.10. AIDXL ist klüger und kann viele Dinge, die basierend auf SD1.5 nicht möglich sind. Es unterscheidet Konzepte gut, lernt Bilddetails, bewältigt für SD1.5 schwierige Kompositionen und kann nahezu perfekt Stile lernen, die ältere AID-Versionen nicht beherrschen. Insgesamt hat es höhere Leistung als SD1.5. Ich werde AIDXL weiterentwickeln.
2024/01/27: Version 0.7 enthält viele neue Inhalte, der Datensatz ist mehr als doppelt so groß gegenüber der vorherigen Version.
Zur Gewinnung zufriedenstellender Beschriftungen habe ich viele neue Label-Algorithmen ausprobiert, z. B. Tag-Sortierung, Tag-Hierarchien, Charaktermerkmalstrennung usw. Projektadresse: Eugeoter/sd-dataset-manager (github.com);
Für kontrolliertes Training habe ich ein spezielles Trainingsskript basierend auf Kohya-ss erstellt;
Für Steuerung des Fusionsprozesses verschiedener Generationen von Modellen habe ich heuristische Modellfusion-Algorithmen erstellt; Um das Modell ausreichend stilisiert zu bekommen, verzichtete ich darauf, die Text-Encoder- und UNET-OUT-Schichten zu fusionieren, da dies die Stil-Stabilität und Ästhetik einschränken würde.
Zum Aussortieren und Filtern des Datensatzes trainierte ich ein Wasserzeichen-Erkennungsmodell, ein Bildklassifizierungsmodell und ein Ästhetik-Bewertungsmodell, um die Daten zu bereinigen.
VII Unterstützen Sie uns
Wenn Ihnen unsere Arbeit gefällt, unterstützen Sie uns gerne über Ko-fi (https://ko-fi.com/eugeai), um unsere Forschung und Entwicklung zu fördern. Vielen Dank für Ihre Unterstützung!
Anhang / Appendix
A. Liste spezieller Auslösewörter / 特殊触发词列表
Künstler-Stil Auslösewörter: Klicken Sie mich
Malerische Stil Auslösewörter: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Flache Farben, Linien zur Darstellung von Licht und Schatten
平涂:Flächige Farbgestaltung mit Linien und Farbblöcken zur Darstellung von Licht und Tiefe
clean color: Stil zwischen flat color und flat-pasto. Einfach und sauber koloriert.
Einfacher, sauberer Farbauftrag, zwischen flat color und flat-pasto
celluloid: Anime-Farbgebung
Flache Zellerfärbung: Anime-Farbgestaltung
flat-pasto: Fast flache Farbe, Verläufe zur Beschreibung von Licht und Schatten
Annähernd flache Farbe mit Farbverläufen zur Darstellung von Licht und Schatten
thin-pasto: Dünne Konturen, Verläufe und Farbauftrag zur Beschreibung von Licht, Schatten und Tiefe
Dünne Konturlinien mit Verläufen und Farbschichtdicke zur Darstellung von Licht und Tiefe
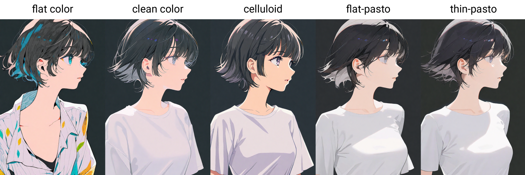
pseudo-impasto: Verläufe und Farbauftrag zur Beschreibung von Licht, Schatten und Tiefe
Pseudo-Impasto / Halbdickauftrag: Verwendung von Verläufen und Farbauftrag zur Darstellung von Licht und Tiefe
impasto: Verwendung der Farbauftragstärke zur Darstellung von Licht, Schatten und Farbverläufen
Impasto: Dickauftrag zur Darstellung von Licht und Farbverläufen
realistic
Realistisch
photorealistic: Neudefiniert als Stil nahe der realen Welt
Photorealistisch: Neu definiert als an die Realität angelehnter Stil
cel shading: Anime 3D-Modellstil
Cel-Shading: Anime-3D-Modellierungsstil
3d

Ästhetische Auslösewörter:
beautiful
Schön
aesthetic: leicht abstraktes künstlerisches Empfinden
Ästhetisch: leicht abstraktes künstlerisches Gefühl
detailed
Detailliert
beautiful color: subtile Farbverwendung
Schöne Farbe: feine Farbnuancen
lowres
messy: chaotische Komposition oder Details
Unordentlich: chaotische Komposition oder Details
Qualitäts-Auslösewörter: amazing quality, best quality, high quality, low quality, worst quality




Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Trainierte Wörter
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.





















