Old Consistency V32 Lora [FLUX1.D/PDXL] - Feminine v1.1 - e500 PDXL
Hervorgehobene Bilder


Empfohlene Prompts
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
Empfohlene Negative Prompts
greyscale, monochrome, multiple views
Empfohlene Parameter
samplers
steps
cfg
clip skip
resolution
vae
other models
Empfohlene Hires (Hochauflösungs-) Parameter
upscaler
upscale
denoising strength
Tipps
Verwende mehrere Loopbacks, um Bildtreue und Konsistenz zu verbessern.
Halte dich an Standard-Prompts und logische Reihenfolge, um Abscheulichkeiten zu vermeiden.
Nutze Kern-Posen- und Blickwinkel-Tags wie 'von vorne', 'von der Seite', 'von oben', um Posegenauigkeit zu verbessern.
Vermeide sexuelle Posen, bis sie ordentlich verfeinert sind.
Experimentiere mit verschiedenen Merkmals-Tags für Haar, Augen, Kleidungfarben und Materialien.
Die Lade-Reihenfolge wirkt sich auf Ergebnisse bei Merges mit anderen Modellen und LoRAs aus.
Der Safe-Modus ist standardmäßig aktiviert mit Optionen, fragwürdige und explizite Inhalte zu entsperren.
Nutze das Pose- und Direktiven-Tagging-System für bessere Kontrolle über Figurenpositionen und Kamerawinkel.
Versions-Highlights
Stabilitätsprüfungen;
Konzept - Bilder/getestete Bilder
Vollkörper - 48/48
Cowboy-Shot - 48/48
Porträt - 48/48
Nahaufnahme - 48/48
**************************************
Die nächste Iteration wird eine einzelne Augen-Posen-Untergruppe mit Pose-Winkeln haben sowie mehr Bilder von Augen für jede Winkelvariante enthalten, um das "Burn" zu festigen. Die direkte Augenfarbe wird wahrscheinlich nicht notwendig sein, jedoch scheint die Form laut meiner Forschung entscheidend zu sein.
rote Augen - 39/48
Vollkörper - 6/12
Cowboy-Shot - 9/12
Porträt - 12/12
Nahaufnahme - 12/12
blaue Augen - 48/48
alle Posen - 12/12
grüne Augen - 48/48
alle Posen - 12/12
gelbe Augen - 42/48
Vollkörper - 6/12 - unklar warum instabil.
aqua Augen - 48/48
alle Posen
lila Augen - 48/48
alle Posen
Latex - 36/48
Nahaufnahme - 5/12
Porträt - 7/12 - benötigt Porträt- und Nahaufnahmebilder
Cowboy-Shot - 12/12
Vollkörper - 12/12
Unterwäsche - 36/48
Nahaufnahme - 7/12
Porträt - 4/12 ? Warum? - benötigt direkte Porträt- und Nahaufnahme-Gesichter
Cowboy-Shot - 11/12
Vollkörper - 12/12
Lässig - 48/48
alle Posen - 12/12
Bikini - 48/48
alle Posen - 12/12
Kleid - 16/48
Keine Pose passte zum passenden Kleid, außer mit zusätzlichen Tags -> Kleider müssen genauer getaggt werden
Die Output-Stabilität war deutlich höher als erwartet mit vielen nutzbaren Tags aus Pony, darunter;
<Farbe> Haar
<Farbe> Kleidung
Brustgröße <Größe>
<reif> weiblich
<Farbe> Ohrringe
<Farbe> Augen
<unscharf> Objekt
<Ort> <Hintergrund>
Hier gibt es viele nützliche Tag-Möglichkeiten, also spielt damit, wie ich es getan habe.
Layering-Erfolge;
rote Augen -> blaue Augen;
[rote Augen:0.5], [blaue Augen:0.5] -> gelegentlich Überlagerung & "Bluten", instabil.
rote Augen, blaue Augen -> weniger konsistente Überlagerung
rote UND blaue Augen -> konsistentere Überlagerung, weitere Untersuchung nötig
Bei den meisten Augen besteht das Problem, dass zu viele Augenfarben über die Form gelegt werden, daher wird das Layering der Augen eher pausiert und auf die Kleckse-Methode umgestellt.
Kleid -> Latex
Kleid, Seitenschlitz, Cocktailkleid, Latex, Latex-Overall -> bildet Outfit aus mehreren Layern. Stabilität schwankt, aber das Ergebnis ist vielversprechend.
Latex -> Kleid
Latex, Latex-Overall, Kleid, Seitenschlitz -> bildet ein eher elegantes Objekt durch Überlagerung der Kleidhautlücken mehr als beim ersten Beispiel. Deutet für mich auf Überanpassung hin, also muss das Kleid neu bewertet werden.
Latex -> Bikini
Latex, Latex-Overall, Bikini -> bildet Latex-Leggings mit Bikini, auch Überanpassung.
Ich glaube, ich habe eine Lösung für das Layering-Problem bei Kleidung und damit auch für Augen, Hautfarbe etc. Die meiste Konsistenz entsteht durch "Blotting" (Klecksmethode).
Ersteller-Sponsoren
Schau dir das Illustrious Model für ergänzende Fähigkeiten an.
Nutze den ComfyUI-Workflow für bessere Bildgenerierung und experimentiere mit Schleifen.
Erkunde das mächtige Flux Modell als Basis-KI-Framework.
Unterstütze NovelAI für überlegene Story- und Bild-Erzeugungssynergie.
Danke an Black Forest Labs für die Gestaltung des Flux-Modells.
Verbessere den Tagging-Workflow mit TagGUI.
Training mit AIToolkit.
Inspiriert von und Rivale zu PonyDiffusion.

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious ist kein PDXL-Ableger, es ist anders und sehr gut. Probier es aus, wenn du die Möglichkeit hast.
Ich habe eine Version von Simulacrum speziell dafür trainiert.
V3-2 statt V3.22:
Das Ziel von v3.22 hat sich verschoben, und ich habe mich im Kaninchenbau der Flux-Tests und der Erforschung neuer Mechanismen verloren. Nachdem ich genug gelernt und festgestellt habe, wie ich auf Subjektfixierung, Tagging und die Flux-Tagging-Verständnis eingehen kann, kann ich tatsächlich eine richtige Version 3 erstellen.
Danke an alle, die meine Lern- und Experimentierzyklen ausgehalten haben. Es war eine echte Achterbahnfahrt aus Tests, Fehlern und einigen Erfolgen. Ich weiß jetzt, was möglich ist, wie man es macht, und habe eine Methode, um das Gelernte iterativ umzusetzen und das Gewünschte zu erschaffen. Der Prozess ist nicht perfekt und wird sich mit der Zeit verfeinern, sodass es immer um Verständnis und iterative Entwicklung geht. Ich bin zuversichtlich, dass ich die erste große Dunning-Kruger-Klippe überschritten habe und nun wirklich lernen und nützliches Wissen vermitteln kann, während ich versuche, Info sowohl für Anfänger als auch Fortgeschrittene sinnvoll aufzubereiten.
Ich habe erkannt, dass mein ursprünglicher Ansatz für V4 machbar ist, aber der Prozess, den ich nutzte, ist nicht wie ursprünglich gedacht gültig, während ich die Systeme iterativ lernte. Mehr gelerntes Zeug und mehr Fehler, aus denen ich lernen kann, um den Boden für kommende Erfolge vorzubereiten.
Versionsverwaltung basierend auf Direktiven.
Ich plane, DREI Kern-Direktiv-Trainings pro Version einzuführen sowie eine einzelne Vanilla-nd-Version.
Ich werde sehr allgemeine Direktiv-basierte Trainings sowohl für das Kernsysten als auch für spezifische Kern-Theme-Bilder verwenden, um alle beabsichtigten Themenaspekte im System zu verbreiten.
Der technische Teil des Tagging-Prozesses wird einzigartig und schwer verständlich sein, wenn du nicht den Hintergrund meiner Maßnahmen kennst, daher sind Bilder und Tagging möglicherweise verwirrend, wenn du detaillierte Spezifika erwartest.
Das vereinfachte Tagging-System bleibt weiterhin eigenständig und in der Lage, die nötigen Resultate bei Bedarf zu erzeugen.
Die "nd"- bzw. "no directive"-Version jeder Veröffentlichung stellt sicher, dass Testunterschiede und Ergebnisse ähnlich bleiben, wie ein Vogel in einer Mine; es ist Zeit zu gehen, wenn der Vogel aufhört zu zwitschern. Wahrscheinlich können diese Schwester-Modelle zusammengeführt und normalisiert werden, um Konzepte zu kombinieren, die je nach verwendeter Direktive funktionieren oder nicht.
Fixierung auf EINZELNE Charaktere ist jetzt das oberste Ziel für dieses Modell. Es gibt nur einen fixierten Charakter, und dessen Auflösung wird auf ein nach unten und oben abgestimmtes Verhältnis skaliert, das den korrekten FLUX-Trainingsformatparametern entspricht.
Probleme bei V3.2 waren weniger stark als erwartet:
Der Großteil der Bedenken beruhte auf fehlenden Informationen, die ich mit der Zeit ergänzen werde. Einfach iterative Entwicklungssache.
Die trainierte Version 3.21 ist derzeit in der Testphase und wird bald veröffentlicht. Sie hat verbesserte Pose-Steuerung und einen verschobenen Fokus auf das Modell mit einer recht langen kamerabasierten Direktive.
Das Ergebnis zeigte gute Kompatibilität mit den meisten getesteten LoRAs und funktioniert sogar mit einigen sehr starren LoRAs, die sich mit der aktuellen v32 kaum bewegen oder drehen lassen.
Es zeigte auch gute Kompatibilität mit Flux Unchained, vielen Charaktermodellen, gesichtsbasierten Modellen, menschlichen Modellen usw. Das System überschneidet oder zerstört bisher keine anderen Systeme, was gut ist.
Probleme in V3.2, die behoben werden müssen:
Es gibt Konsistenzprobleme bei einigen Posen und Winkeln. Es gibt auch eine Kreuzkontamination mit verschiedenen anderen LoRAs, wenn sie die Tags von der Seite, von hinten, von oben und von unten verwenden. Ich werde neue Tags als Verifikationseinheit einführen und eine ganz separate LORA trainieren, um in Zukunft die Kamerakontrolltreue zu gewährleisten.
Funktioniert überwiegend gut für Anime, aber bei Einsatz von LoRAs gibt es Probleme.
Kombinationstags für Version 3.21;
Ich muss einige Basistests machen, um sicherzustellen, dass die Kamera basierend auf der Platzierung richtig funktioniert, deshalb teste ich Tags wie:
ein Subjekt aus Frontansicht, oberer Winkel
ein Subjekt aus Frontansicht seitlicher Winkel bei oben
ein Subjekt aus Rückansicht oberer Winkel bei vorne
ein Subjekt aus Seitenansicht oberer Winkel bei hinten
und weitere ähnliche Tags in flux_dev, damit ich sichergehen kann, dass meine Konstruktion die Kamera korrekt positioniert und die Bildtreue dabei nicht verloren geht.
Nach meinem Verständnis trainiert das System große Tiefen, wenn man solche generischen Optionen nutzt. Weitere Tests sind nötig, um sicher zu sein.
Tags wie "von hinten greifen", "Sex von hinten" etc. werden wahrscheinlich nicht mit "von hinten" Tags kooperieren, daher werde ich rein "Rücken" Tags nutzen.
"von der Seite", "von hinten", "geradeaus", "den Betrachter ansehen" und alles, was mit spezifischen Charakter-Safebooru-, Danbooru-, Gelbooru-Platzierungsrotationen zusammenhängt, wird nicht trainiert. Es basiert vollständig aufs ANSEHEN eines Charakters, nicht aufs INTERAGIEREN mit ihm.
Wir wollen auch meist keine POV-Arme, daher muss viel getestet werden, dass das Tagging nicht versehentlich Arme, Beine, Torsos entstehen lässt und den individuellen Charakter fixiert.
Einige Posen haben ehrlich gesagt nicht funktioniert:
Das Kombinationstagsystem hat einfach versagt, darum braucht es neue Kombinationen zur korrekten Figurenkontrolle.
Beine sind verformt oder fehlen.
Arme können verformt oder schlecht platziert sein.
Füße fehlen.
Oberer Torso ist zu oft zu ausgeprägt. <<< überangepasst
Unterer Torso zeigt Kleidung nicht korrekt.
Hals zeigt nicht korrekte Kleidung wie Schals, Handtücher, Halsbänder, Krägen usw.
Brustwarzen und Genitalien sind ein absolutes Chaos. Es braucht einen ordentlichen Ordner mit Variationen für einen vernünftigen NSFW-Controller.
NAI sollte stil-spezifisch sein und als Stil feinabgestimmt werden.
Kleidungsoptionen erzeugen Körperformen öfter als nötig.
Explizite Bewertungen sind manchmal kaum zugänglich, an anderen Stellen durchbrechen sie wie ein Güterzug.
Es gibt nicht genug fragwürdige Bilder zur Gewichtung, das explizite Tagging sollte ebenfalls mit "fragwürdig" versehen werden, sodass diese Informationen ebenfalls abrufbar sind.
Einige Anime-Charaktere haben schlechte Perspektiven, was beim Ziel einer korrekten assoziativen Perspektive schlecht ist.
Vierfüßlerstand ist ziemlich stabil, hat aber einige Perspektivprobleme. Anime-Charaktere werden nicht oft genug als 3D behandelt, somit benötigen die Umgebungen rund um die Bilder mehr Detailtreue.
Vierfüßlerstand funktioniert in einer Aufstellung ohne viel Feinjustierung nicht.
Knieen funktioniert in einer Aufstellung ohne viel Feinjustierung nicht.
Aufstellungen und Gruppen scheinen für Flux besonders formatiert zu sein, was weitere Untersuchungen verdient. Fast wie eine interne foreach-Schleife.
Es gab einige Erfolge:
Basis-Treue litt bei den meisten Bildern nicht.
Viele neue Posen FUNKTIONIEREN, wenn auch manchmal etwas holprig.
Anime-Stil wurde auf einzigartige NAI-Art mit etwas Realismus angepasst.
Mehrere Charaktere können posiert werden, wenn auch manchmal auf sehr seltsame Weise.
Stehen aus jedem Winkel bietet fantastische Bildtreue und Qualität im NAI-Stil.
V3.3 muss noch warten.
V3.3 Fahrplan:
Ich habe die Ressourcen unten im Dokument aktualisiert und die ältere Dokumentation für Archivzwecke ausgegliedert.
Da das Ergebnis jetzt meine Vision etwas besser widerspiegelt, kann ich mich auf den nächsten Schritt in der Zielsetzung konzentrieren: Overlays.
V3.3 wird sogenannte High-Alpha-Burned-Offset-Tags einführen, die Dinge wie Comics, Spiel-UIs, Overlays, Gesundheitsbalken, Anzeigen usw. vereinfachen.
Theoretisch kannst du damit eigene Fake-Spiele in Consistency machen, wenn ich das korrekte Overlay mit den richtigen Burns erstelle.
Das legt die Grundlage, um Charaktere in beliebiger Position aus beliebiger Tiefenschicht einer Szene zu platzieren, aber das kommt später.
Es kann BEREITS Sprite-Sheets einigermaßen fair erzeugen, daher werde ich in den nächsten Tagen das integrierte Tagging-System erforschen, um all diese Subsysteme mit ein wenig Prompting-Aufwand und Rechenleistung zu testen. Es ist sehr wahrscheinlich, dass das schon existiert und nur noch herausgefunden werden muss.
V4 Ziele:
Wenn das alles gut läuft, sollte das gesamte System bereit für die volle Produktionsfähigkeit sein, inklusive Bildmodifikation, Video-Editing, 3D-Bearbeitung und vielem mehr, was ich aktuell noch nicht begreife.
v33 Overlays
Das ist etwas irreführend, da es eher ein Szenendefinitions-Framework für die nächste Struktur ist.
Das wird sowohl die wenigste als auch die meiste Zeit beanspruchen, ich habe einige Alpha-Experimente geplant, um es zum Laufen zu bringen. Ich bin mir aber ziemlich sicher, dass Overlaying nicht nur zum Anzeigen von Nachrichten gewählt wird, sondern auch zur Szenensteuerung, aufgrund der Tiefenwirkung.
v34 Charakter-Einblendung, Rotationswerte-Planung und sorgfältige Blickwinkelausgleichswerte:
Das Sicherstellen, dass bestimmte Charaktere existieren und Anweisungen folgen, ist ein Hauptziel, da sie das manchmal einfach nicht tun.
Eine vollständige, zahlenbasierte Rotationsbewertung mit Pitch/Yaw/Roll in Grad wird implementiert. Es wird nicht perfekt, da ich weder mathematische Fähigkeiten noch passende Bildersätze oder 3D-Software-Kenntnisse habe, aber ein guter Start und hoffentlich an FLUX angehängt.
v35 Szenensteuerungen
Komplexe Interaktionspunkte in Szenen, Kamerasteuerung, Fokus, Tiefenwirkung usw., die vollständiges Szenenaufbauen mit platzierten Figuren ermöglichen.
Man kann es sich wie eine 3D-Version des Overlay-Controllers vorstellen, aber auf Steroiden, wenn gewünscht.
v36 Beleuchtungssteuerungen
Segmentierte und szenensteuernde Beleuchtungsänderungen, die alle Charaktere, Objekte und Kreationen beeinflussen.
Jede Lichtquelle wird basierend auf spezifischen Regeln, definiert in Unreal, mit verschiedenen Lichttypen, Quellen, Farben usw. platziert und generiert.
Theoretisch sollte FLUX die Lücken füllen.
v37 Körpertypen und Körperanpassung
Mit Einführung der Grundkörpertypen möchte ich komplexere Körpererstellungen hinzufügen, die unter anderem folgendes beinhalten:
Korrektur der Posen, die nicht korrekt funktionieren
Hinzufügen einer Vielzahl weiterer Posen
Komplexeres Haar:
Haar-Interaktion mit Gegenständen, geschnittenes Haar, beschädigtes Haar, verfärbtes Haar, mehrfarbiges Haar, zusammengebundenes Haar, Perücken usw.
Komplexere Augen:
verschiedene Augentypen, offen, geschlossen, zusammengekniffen usw.
Verschiedene Gesichtsausdrücke:
glücklich, traurig, :o, keine Augen, einfaches Gesicht, gesichtslos usw.
Ohrtypen:
spitz, rund, keine Ohren usw.
Viele Hautfarben:
hell, rot, blau, grün, weiß, grau, silber, schwarz, pechschwarz, hellbraun, braun, dunkelbraun und mehr.
Ich versuche sensible Themen zu vermeiden, da Hautfarbe oft ein sensibles Thema ist, ich möchte einfach eine Vielzahl von Farben, wie bei Kleidung.
Arme-, Bein-, Oberkörper-, Taillen-, Hüft-, Hals- und Kopfgrößen-Regler:
Bizeps, Schulter, Ellbogen, Handgelenk, Hände, Finger usw., mit Größenreglern für Länge, Breite und Umfang.
Schlüsselbein und die vorhandenen Torso-Tags
Taillen-Tags
Körperspezifische Größenbereiche basierend auf einer Skala von 1 bis 10 statt vordefinierter Systeme wie bei den Boorus.
v38 Outfits und Outfit-Anpassung
Nahezu 200 Outfits, jeweils mit eigenen Parametern.
v39 500 ausgewählte Videospiel-, Anime- und Manga-Charaktere aus hochwertigen Daten
Fünfhundert Cigaret- ähm... also... viele Charaktere. Definitiv keine große Menge Meme-Charaktere ohne rationalen Bezug zu Design oder Archetypen.
Danach kannst du alles bauen oder jeden Charakter trainieren.
massiver Qualitäts- und Detaillierungs-Boost:
inklusive Zehntausender Bilder aus hochwertigen Anime-, 3D- und foto-realistischen Quellen, um diese feinabgestimmte Version von Flux stilistisch zu trainieren.
jedes Bild wird mit einem Treue-Score zwischen score_1 und score_10 getaggt, ähnlich wie bei Pony, aber mit eigenem spin je nach Erfolg.
V3.2 Veröffentlichung - 4k Schritte:
Diese Version ist definitiv nicht für Kinder. Es ist ein SFW/FRAGWÜRDIG/NSFW-Basis-Modell, das zu allem trainiert werden kann.
Es ist NICHT zum Smut-Erzeugen gebaut, kann es aber mit entsprechender Aufforderung. Das ist Teil des Pakets, wenn man einer KI gewisse Verhaltensweisen beibringt – man bekommt "Gepäck" mit. Die Bilder sind aktuell etwa 33 % SFW/33 % fragwürdig/33 % NSFW, mit leichter Gewichtung zu sicher, ähnlich wie bei NAI.
Ich vertrete die Auffassung, dass das Lehren von einer zensurfreien KI mit kontrollierter Präzision gesund für deren Entwicklung ist und für die Bildgenerierenden wichtig: nicht ständig auf "Alptraummaterial" zu treffen.
Dieses Modell zeigt weit mehr Potenzial, als ich je zuvor gesehen habe.
Benutze meine ComfyUI-Workload, sie ist an alle unten angehängten Bilder gekoppelt.
Standardmäßig ist Safe-Modus aktiviert:
fragwürdig < entsperrt mehr fragwürdige zufällige Merkmale
explizit < entsperrt die spaßigen Sachen, die zufällig auftauchen
Perspektiv-Aktivierungs-Tags: versuch Kombinationen wie; von vorne, Seitenansicht, usw.
von vorne, Frontansicht,
von der Seite, Seitenansicht,
von hinten, Rückansicht,
von oben, Draufsicht,
von unten, Untersicht,
Primär hinzugefügte und verbesserte Posen:
Vierfüßlerstand
Knieend
Hocken
Stehend
Vorgebeugt
Lehnend
Liegend
Auf dem Kopf stehend
Auf dem Bauch
Auf dem Rücken
Armpositionierungen
Beinpositionierungen
Kopfhaltung
Kopfrichtungen
Blickrichtungen
Blickposition
Augenfarbkonstanz
Haarfarbkonstanz
Brustgröße
Gesäßgröße
Taillengröße
Vielzahl an Kleidungsoptionen
Vielzahl an Charakteroptionen
Vielfalt an Gesichtsausdrücken
Sexuelle Posen sind stark in Arbeit und ich würde empfehlen, diese erst zu benutzen, wenn sie fertig sind. Sie gehen weit über meinen aktuellen Wissensstand hinaus und ich habe momentan nicht die Kapazität, den richtigen Weg zu bestimmen.
Der Pose-Maker, Winkel-Maker, Situations-Aufsetzer, Konzept-Einsetzer und Interpolations-Struktur sind vorhanden und ich werde weitere Versionen trainieren.
Viel Spaß.
V3.2 Fahrplan:
25.08.2024 5:16 - Ich habe festgestellt, dass der Prozess funktioniert und das System weit über Erwartungen hinaus leistungsfähig ist. Die KI hat emergente Verhaltensweisen entwickelt, die die Charakterposes exponentiell mächtiger machen als erwartet. Tests laufen, Ergebnis sieht fantastisch aus.
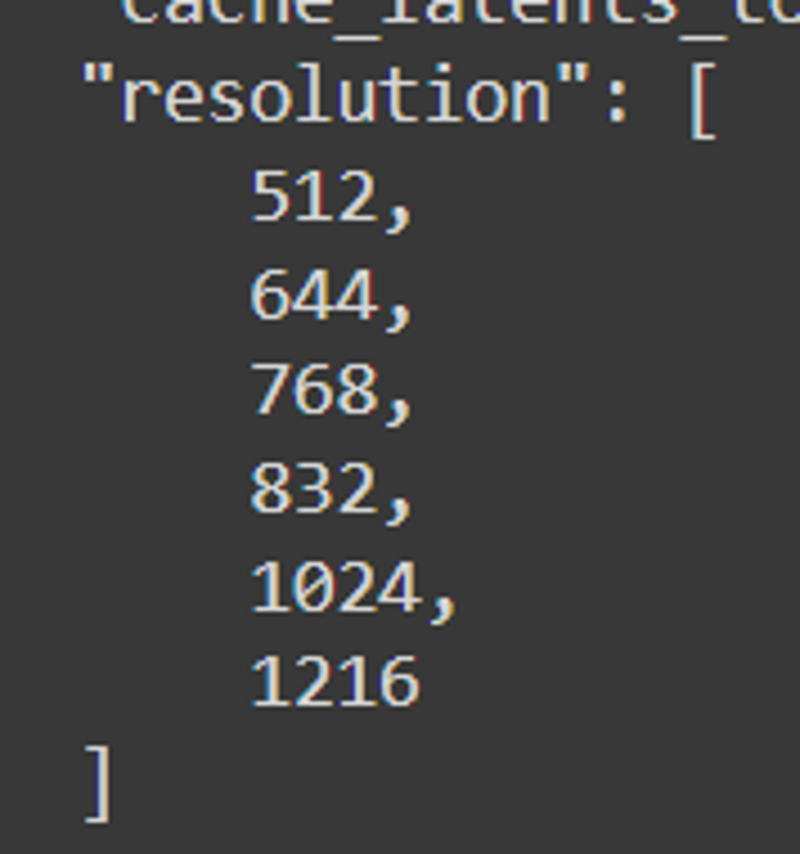
Endauflösungen waren: 512, 640, 768, 832, 1024, 1216
25.08.2024 15:00 - Alles ist ordnungsgemäß getaggt und die Posen vorbereitet. Das echte Training beginnt jetzt mit Tests zu Dimensionen, Lernrate, Schrittzahl und mehr, um den richtigen Kandidaten für den v32 Release auszuwählen.
25.08.2024 04:00 - Erste v32 Version zeigte minimale Deformierung ab Schritt 1400 und starke Deformierung ab Schritt 2200, also hat das Lazy-WD14-Tagging nicht funktioniert. Manuelles Taggen folgt. Ein spannender Morgen.
24.08.2024 Abend - Das Training läuft.
 Ich vermute, diese Version wird nicht funktionieren. Ich habe alles autotaggt und die Pose-Winkel erstmal ausgeschnitten. Ich werde testen, was WD14 alleine kann. Nach dem erfolgreichen oder erfolglosen Training wird die originale Pose-Winkel- und Tag-Reihenfolge wiederhergestellt. Mal sehen, wie es läuft, jetzt wo alle Daten konzentriert und Anwendungsfälle dicht sind.
Ich vermute, diese Version wird nicht funktionieren. Ich habe alles autotaggt und die Pose-Winkel erstmal ausgeschnitten. Ich werde testen, was WD14 alleine kann. Nach dem erfolgreichen oder erfolglosen Training wird die originale Pose-Winkel- und Tag-Reihenfolge wiederhergestellt. Mal sehen, wie es läuft, jetzt wo alle Daten konzentriert und Anwendungsfälle dicht sind.Mit 4000 Bildern vermute ich, dass das Cache der Latents einige Zeit dauern wird, aber durch den speziellen Fokus auf "Use Case" Puppen und Körper sollte es zumindest brauchbar werden.
24.08.2024 Mittag -
 Wir arbeiten dran.
Wir arbeiten dran. Alles ist so formatiert, dass es Schatten-Implikation-Hintergründe hat, was Flux beim Erzeugen von Bildern basierend auf Oberflächen und Orten hilft. Alles ist aufgebaut, um fehlende Posen zu kompensieren, die Flux nicht beherrscht. Es fixiert sich auf Subjekte, die multiplikativ an mehreren Orten überlagert werden können.
Alles ist so formatiert, dass es Schatten-Implikation-Hintergründe hat, was Flux beim Erzeugen von Bildern basierend auf Oberflächen und Orten hilft. Alles ist aufgebaut, um fehlende Posen zu kompensieren, die Flux nicht beherrscht. Es fixiert sich auf Subjekte, die multiplikativ an mehreren Orten überlagert werden können.Mein Fokus lag auf korrekter Armplatzierung und sicherstellen, dass getaggte Arme, die sich überlappen, Arme von Punkt A zu B bauen.
24.08.2024 morgens - Es gibt offenbar auch Armprobleme, aber die liste ich auf. Danke für den Hinweis, hier ist definitiv Kreuzkontamination, die adressiert werden muss. Ich nutze ein spezielles ComfyUI-Loopback-System, das auf der Website fehlt, deswegen muss ich für diese Version die On-Site-Generierung eventuell deaktivieren.
 23.08.2024 - Ich habe etwa 340 neue hochdetaillierte Anime-Bilder mit fast einheitlicher Pose, Pitch/Yaw/Roll-IDs gesammelt, damit die Farbigkeit, Größenunterschiede in Brust, Haar und Po gesichert sind. Es fehlen noch 554 Bilder. V3.2 wird stark auf Anime fokussiert sein, danach will ich Pony-Quellen holen, um ausreichend synthetischen Realismus zu erzeugen; es sei denn, Flux schafft es nach dem Training, dann nutze ich Flux.
23.08.2024 - Ich habe etwa 340 neue hochdetaillierte Anime-Bilder mit fast einheitlicher Pose, Pitch/Yaw/Roll-IDs gesammelt, damit die Farbigkeit, Größenunterschiede in Brust, Haar und Po gesichert sind. Es fehlen noch 554 Bilder. V3.2 wird stark auf Anime fokussiert sein, danach will ich Pony-Quellen holen, um ausreichend synthetischen Realismus zu erzeugen; es sei denn, Flux schafft es nach dem Training, dann nutze ich Flux. Diese sollten auf Pose-Basis Treue und Bewertung sicherstellen, besonders da ich eine neue Methodologie mit den Schlüsselwörtern "from" und "view" habe. Theoretisch sollte es fast wie NovelAIs Posekontrolle funktionieren, was mein Ziel ist. Charaktere und Differenzierung der Charaktere sind natürlich eine andere Sache.
Diese sollten auf Pose-Basis Treue und Bewertung sicherstellen, besonders da ich eine neue Methodologie mit den Schlüsselwörtern "from" und "view" habe. Theoretisch sollte es fast wie NovelAIs Posekontrolle funktionieren, was mein Ziel ist. Charaktere und Differenzierung der Charaktere sind natürlich eine andere Sache.Alles muss perfekt geordnet und ausgerichtet sein, sonst wird der nötige Kontext nicht im richtigen Maß geliefert, um das Basismodell nützlich zu beeinflussen.
SAFE ist standardmäßig aktiviert, das ganze System wird auf Sicherheit gewichtet sein mit Möglichkeit, NSFW zu aktivieren.
Ich werde mehrere Iterationen dieser LORA trainieren, um die Trennung streng zu halten, aber auch die NSFW-Community mit der entsprechenden Version zu bedienen.
Ich hoffe, wenn das trainiert ist, kann ich ein ausgesuchtes Dataset von 50.000 Bildern ins System eingeben, und es wird Magie erzeugen. Vielleicht vergleichbar mit Pony für Alles, was das Herz begehrt. Dann kann ich beruhigt sein, dass das Universum dankbar ist. Danach könnt ihr wahrscheinlich alles reinwerfen und es wird alles umsetzen können dank der angeborenen Kraft von Flux mit dem Rückgrat von Consistency.
Ich plane, die Trainingsdaten für das vollständige Consistency Initial v3.2 Bilderset freizugeben, wenn es organisiert, trainiert, getestet und bereit ist. Die v3-Daten werde ich dieses Wochenende veröffentlichen.
Ich habe eine Reihe von Inkonsistenzen bei Posen festgestellt, vor allem bei dem 'liegend' Keyword in Kombination mit Winkelkeywords. Ich werde jede Kombination testen und ihre Grundkonsistenz verbessern, bevor ich zur nächsten Phase übergehe: Basis-Outfit-Optionen, Outfit-Wechsel und Ableitungen basierend auf funktionierenden und nicht funktionierenden Posen. Später muss ich detailliertere Informationen zu den fragwürdigen und NSFW-Elementen ergänzen. Errate ruhig, was das sein wird.
Bis dahin muss ich sicherstellen, dass die Posen nach Vorgabe funktionieren, also werde ich neue absichtliche Kombinations-Keywords erstellen, Pose-Anzahlen auf mehr Bilder pro Pose, mehr Bilder pro Winkel und mehr Winkel pro Situation erhöhen. Ich werde auch eine Reihe von "Basis" Tags hinzufügen, die manche Dinge bei Fehlerpunkten auf andere standardisieren. Das sollte die Konsistenz verbessern.
V3 Dokumentation:
Primär getestet auf FLUX.1 Dev e4m3fn bei fp8, daher spiegelt das vorbereitete Checkpoint-Merge diesen Wert wider, sobald der Upload abgeschlossen ist. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
Läuft auf dem Basis-FLUX.1 Dev-Modell, funktioniert aber auch auf anderen Modellen, Merges und LoRAs. Die Ergebnisse sind gemischt. Experimentiére mit der Lade-Reihenfolge, da die Modellwerte in unterschiedlicher Reihenfolge variieren.
Dies ist nichts anderes als das Rückgrat von FLUX. Es ermöglicht nützliche Tags, ähnlich wie Danbooru, um Kamerasteuerung und Hilfestellungen zu etablieren, die es erheblich erleichtern, sehr anpassbare Charaktere in Szenen zu erstellen, die FLUX wahrscheinlich KANN, aber mit viel mehr Aufwand im Default.
Ich rate dringend, ein Mehrfach-Loopback-System zu verwenden, um Bildtreue sicherzustellen. Consistency verbessert Qualität und Treue über mehrere Iterationen.
Das Modell ist sehr auf Individuen ausgerichtet. Aufgrund der Auflösungsstruktur kann es aber viele Menschen in ähnlichen Situationen handhaben. LoRAs, die unmittelbar Bildveränderungen ohne Kontext bewirken, sind oft nutzlos, da sie nichts zur Szene beitragen. LoRAs, die eher Merkmale hinzufügen oder Kontext-Interaktion zwischen Personen erzeugen, funktionieren ziemlich gut. Kleidung, Haartypen, Geschlechterkontrolle funktioniert. Die meisten getesteten LoRAs funktionieren, aber einige überhaupt nicht.
Dies ist kein Merge oder eine Kombination von LoRAs. Diese LORA wurde über ein Jahr mit synthetischen Daten von NAI und AutismPDXL erstellt. Das Bilderset ist ziemlich komplex und die Auswahlbilder waren schwer herauszufiltern. Es gab sehr viel Trial & Error, wirklich eine riesige Menge.
Es gibt eine SERIE von Kerntags mit dieser LORA. Sie fügt FLUX ein Rückgrat hinzu, das es von Haus aus nicht hat. Das Aktivierungsmuster ist komplex, aber wenn man den Charakter ähnlich NAI baut, wirkt es ähnlich wie bei NAI.
Das Potenzial und die Power dieses Modells dürfen nicht unterschätzt werden. Es ist eine absolute Power-LORA, die mein Verständnis übersteigt.
Sie kann trotzdem Abscheulichkeiten erzeugen, wenn man nicht vorsichtig ist. Mit Standard-Prompting und logischer Reihenfolge kannst du schnell schöne Kunst erschaffen.
Auflösungen: 512, 768, 816, 1024, 1216
Empfohlene Schritte: 16
FLUX-Anleitung: 4 oder 3-5 bei sturen Fällen, 15+ bei sehr sturen
CFG: 1
Ich habe es mit 2 Loopbacks laufen lassen. Erste: Upscale 1.05x und Denoise 0.72–0.88, zweite: Denoise 0.8, abhängig von Anzahl der gewünschten Merkmale.
KERN-TAG-POOL:
anime - wandelt Stil von Posen, Charakteren, Outfits, Gesichtern usw. in Anime um
realistisch - wandelt Stil in realistisch um
von vorne - Ansicht von vorne einer Person, Schultern sind ausgerichtet und auf den Betrachter gerichtet, Mittelpunkt des Oberkörpers zur Kamera
von der Seite - Seitenansicht mit senkrechtem Schulterwinkel, Charakter ist von der Seite sichtbar
von hinten - direkt rückwärtige Ansicht
geradeaus - vertikale Frontansicht, horizontaler Planwinkel
von oben - 45-90 Grad Neigung nach unten auf eine Person
von unten - 45-90 Grad Neigung nach oben auf eine Person
Gesicht - auf Gesichtsdetails fokussiertes Bild, gut für problematische Details
Vollkörper - Ganzkörperansicht einer Person, gut für komplexe Posen
Cowboy Shot - Standard-Cowboy-Shot, funktioniert gut mit Anime, weniger mit Realismus
Blick zum Betrachter, zur Seite schauen, geradeaus schauen
Abgewandt, Betrachter zugewandt, wegschauen
Rückblickend, nach vorne schauend
Gemischte Tags erzeugen gemischte Resultate, haben aber unterschiedliche Ausgänge
von der Seite, geradeaus - horizontale Kamera an der Seite einer oder mehrerer Personen
von vorne, von oben - 45 Grad Neigung nach unten von vorne oben
von der Seite, von oben - 45 Grad Neigung nach unten von oben seitlich
von hinten, von oben - 45 Grad Neigung nach unten von hinten oben
von vorne, von unten
von vorne, von oben
von vorne, geradeaus
von vorne, von der Seite, von oben
von vorne, von der Seite, von unten
von vorne, von der Seite, geradeaus
von hinten, von der Seite, von oben
von hinten, von der Seite, von unten
von hinten, von der Seite, geradeaus
von der Seite, von hinten, von oben
von der Seite, von hinten, von unten
von der Seite, von hinten, geradeaus
Die Tags erscheinen ähnlich, aber die Reihenfolge erzeugt oft sehr unterscheidbare Resultate. "von hinten" vor "von der Seite" gewichtet das System z.B. mehr nach hinten, oft sieht man dabei eine Verdrehung des Oberkörpers und Körperwinkel um 45 Grad in beide Richtungen.
Das Ergebnis ist gemischt, aber definitiv praktikabel.
Merkmale, Farbgebung, Kleidung usw. funktionieren ebenfalls
rotes Haar, blaues Haar, grünes Haar, weißes Haar, schwarzes Haar, goldenes Haar, silbernes Haar, blondes Haar, braunes Haar, lila Haar, pinkes Haar, aqua Haar
rote Augen, blaue Augen, grüne Augen, weiße Augen, schwarze Augen, goldene Augen, silberne Augen, gelbe Augen, braune Augen, lila Augen, pinke Augen, aqua Augen
roter Latex-Overall, blauer Latex-Overall, grüner Latex-Overall, schwarzer Latex-Overall, weißer Latex-Overall, goldener Latex-Overall, silberner Latex-Overall, gelber Latex-Overall, brauner Latex-Overall, lila Latex-Overall
roter Bikini, blauer Bikini, grüner Bikini, schwarzer Bikini, weißer Bikini, gelber Bikini, brauner Bikini, lila Bikini, pinker Bikini
rotes Kleid, blaues Kleid, grünes Kleid, schwarzes Kleid, weißes Kleid, gelbes Kleid, braunes Kleid, pinkes Kleid, lila Kleid
Röcke, Hemden, Kleider, Halsketten, komplette Outfits
Verschiedene Materialien; Latex, Metallisch, Denim, Baumwolle usw.
Posen funktionieren eventuell nicht immer zusammen mit der Kamera, Feineinstellungen nötig
Vierfüßlerstand
Knieend
Liegend
Liegend, auf dem Rücken
Liegend, seitlich
Liegend, auf dem Kopf
Knieend, von hinten
Knieend, von vorne
Knieend, von der Seite
Hocken
Hocken, von hinten
Hocken, von vorne
Hocken, von der Seite
Beine zu steuern ist heikel, probier sie etwas aus
Beine
Beine zusammen
Beine auseinander
Beine gespreizt
Füße zusammen
Füße auseinander
Hunderte weitere Tags enthalten, Millionen Kombinationsmöglichkeiten
Verwende sie vor allen Eigenschaftsspezifizierern einer Person, aber nach dem Flux-Prompt.
PROMPTING:
Mach es einfach. Tippe irgendwas und schau, was passiert. Flux hat schon sehr viel Wissen, nutze Posen und Co., um deine Bilder zu verbessern.
Beispiele:
eine Frau, die auf einem Stuhl in der Küche sitzt, von der Seite, von oben, Cowboy-Shot, 1 Mädchen, sitzend, von der Seite, blaue Haare, grüne Augen

eine Superheldin, die am Himmel fliegt und einen Felsen wirft, sie hat eine mächtige, leuchtende Aura, realistisch, 1 Mädchen, von unten, blauer Latex-Anzug, schwarzer Halsband, schwarze Fingernägel, schwarze Lippen, schwarze Augen, lila Haare
 eine Frau isst im Restaurant, von oben, von hinten, vierfüßlerstand, Po, Stringtanga
eine Frau isst im Restaurant, von oben, von hinten, vierfüßlerstand, Po, Stringtanga Ja, es hat funktioniert. Meist klappt das.
Ja, es hat funktioniert. Meist klappt das.
Das Modell sollte die meisten Verrücktheiten handhaben, aber es liegt außerhalb meines umfassenden Verständnisses. Ich habe versucht, Chaos zu minimieren und genug Pose-Tags für Funktion einzubauen, also bleib lieber bei den Kern- und nützlichen Tags.
Nach über 430 gescheiterten Versuchen entstand eine Reihe erfolgreicher Theorien. Ich werde wahrscheinlich am Wochenende eine vollständige Dokumentation mit den verwendeten Trainingsdaten veröffentlichen. Es war ein langer und schwieriger Prozess. Ich hoffe, ihr habt Spaß damit.
V2 Dokumentation:
Letzte Nacht war ich sehr müde, daher ist die vollständige Zusammenstellung der Ergebnisse noch nicht fertig. Erwartet sie so bald wie möglich, wahrscheinlich tagsüber während der Arbeit mit Tests und Wertmarkierungen.
Flux Training Einführung:
Früher brauchte PDXL nur wenige Bilder mit danbooru-Tags um feinjustierte, NAI-ähnliche Ergebnisse zu erzielen. Weniger Bilder waren hier ein Vorteil, weil sie die Möglichkeiten einschränkten; hier reichten weniger Bilder nicht. Es brauchte mehr Power.
Das Modell hat viel Potential, aber die Varianz zwischen verschiedenen Trainingsdaten ist viel größer als zuerst gedacht. Mehr Varianz bedeutet mehr Potenziale, aber ich verstand nicht, warum das mit hoher Varianz funktioniert.
Nach Recherche stellte ich fest, dass das Modell gerade wegen dieser Varianz so stark ist. Es kann "gerichtete" Bilder basierend auf Tiefe erzeugen, bei denen das Bild segmentiert wird und über einem anderen Bild mit einem Rauschmuster als Leitbild überlagert wird. Ich fragte mich, wie ich >>DAS<< trainieren kann, ohne die Kerndetails des Modells zu zerstören. Ich dachte zuerst an Resizing, dann fiel mir Bucketing ein. Das ist das erste wichtige Element hier.
Ich startete blind, probierte Settings nach Vorschlägen und bewertete die Ergebnisse visuell. Es ist ein langsamer Prozess, weshalb ich parallel Papers las und recherchierte, um schneller voranzukommen. Ich habe sehr viel investiert, hätte ich mehr Zeit, hätte ich 50 Prozesse parallel laufen lassen, aber ich bin nur eine Person mit Arbeit. Ich hätte dafür zahlen können, aber kein Setup dafür.
Ich entschied mich basierend auf Erfahrungen mit SD1.5, SDXL und PDXL LORA-Trainings für ein Format. Die Resultate sind okay, aber es gibt eindeutig Fehler, auf die ich später eingehe.
Trainings-Formatierung:
Ich machte einige Tests.
Test 1 - 750 Zufallsbilder aus meinem Danbooru-Sample:
UNET LR - 4e-4
Die meisten anderen Elemente spielten kaum eine Rolle und konnten auf Default bleiben, außer der Beachtung der Auflösungs-Bucketing.
Nur 1024x1024, zentriert zugeschnitten
Zwischen 2k und 12k Schritten
750 zufällige Bilder mit einheitlichen Tags aus einer Poolauswahl ausgewählt.
Moat-Tagger lief darüber und ergänzte Tags, ohne bestehende zu überschreiben.
Das Ergebnis war nicht vielversprechend. Das Chaos war erwartet. Einführung neuer menschlicher Merkmale wie Genitalien war mal vorhanden, mal nicht existent. Das stimmte mit anderen Erkenntnissen überein.
Ich erwartete nicht, dass das ganze Modell leidet, da ich dachte, Tags überschneiden sich nicht.
Ich habe den Test zweimal gemacht und zwei nutzlose LORAs mit je ca. 12k Schritten erhalten. Tests zwischen 1k und 8k zeigten kaum nützliche Abweichungen in Richtung Ziel, trotz Beachtung der Tagpool-Verteilungen.
Es gibt etwas anderes. Etwas, das ich verpasst habe und nichts mit Menschlichem oder CLIP-Beschreibung zu tun hat: Es gibt etwas Weiteres.
Um diese Misserfolgskurve machte ich eine Entdeckung: Das Tiefe-System ist interpolativ und basiert auf zwei vollkommen verschiedenen und gegensätzlichen Prompts, die kooperativ sind. Wie genau das genutzt wird, weiß ich nicht, werde heute die Paper lesen, um die Mathematik dahinter zu verstehen.
Test 2 - 10 Bilder:
UNET LR - 0.001 <<< sehr hohe Lernrate
256x256, 512x512, 768x768, 1024x1024
Die ersten Schritte zeigten etwas Abweichung, ähnlich wie SD3 Burn. Es war aber schlecht. Das Überbluten begann schon ab Schritt 500, und ab Schritt 1000 war das Ergebnis nahezu unbrauchbar. Ich weiß, ich verwende "repeat", aber es war ein guter Test zum Scheitern.
Abweichungen sind hier sehr schädlich. Ein neues Kontextelement wird eingeführt und dann in Ramsch verwandelt. Elemente werden durch unbrauchbare Artefakte ersetzt, ähnlich wie schlecht gesetztes Inpaint. Es war interessant, wie viel FLUX aushält und trotzdem funktioniert. Der Test zeigte die Resilienz von FLUX.
Ein Fehlschlag, weitere Tests mit anderen Settings nötig.
Test 3 - 500 Pose-Bilder:
UNET LR - 4e-4 <<< Dieser Wert sollte durch 4 geteilt und mit doppelt so vielen Schritten trainiert werden.
Vollständiges Bucketing - 256x256, 256x316, etc. Ich ließ alles wild zu und versorgte es mit Bildern in verschiedenen Größen. Ergebnis war unerwartet.
Das Resultat ist buchstäblich der Kern dieses Konsistenz-Modells, so mächtig war das Ergebnis. Es verursachte etwas mehr Schaden als erwartet, aber es war bemerkenswert.
Zu beachten: Anime nutzt meist keine Tiefenschärfe. Dieses Modell lebt von Schärfentiefe und Unschärfe, um Tiefe zu unterscheiden. Eine Art Depth Controlnet müsste hier eingesetzt werden, ich weiß aber nicht, wie ich das umsetzen soll. Training mit Tiefenkarten und Normal Maps könnte funktionieren, könnte aber das Modell zerstören, da es keine Negativ-Prompts hat.
Mehr Tests nötig. Mehr Trainingsdaten und Infos erforderlich.
Test 4 - 5000 Konsistenz-Bündel:
UNET LR - 4e-4 <<< Sollte durch 40 geteilt und mit 20-facher Schrittanzahl trainiert werden. Training von so etwas im Kernmodell ist nicht einfach und nicht schnell erledigt. Die Mathematik passt aktuell nicht zur Aufrechterhaltung des Basismodells, daher veröffentlichte ich erste Erkenntnisse.
Ich hatte hier einen Abschnitt geschrieben und dann aus Versehen gelöscht, daher muss ich das später nochmal schreiben.
Die großen Fehler:
Die Lernrate war VIEL ZU HOCH für meine initialen 12k Trainingsschritte. Das gesamte System basiert auf Gradientenlernen, aber die Lernrate war zu hoch, sodass das Modell beschädigt wurde. Ich habe sie nicht angebrannt, sondern das Modell für etwas anderes neu trainiert. Das Problem war, ich wusste nicht, was ich wollte. Das System basierte auf ungerichteter Information ohne Gradiententiefe, also war Scheitern vorprogrammiert, egal wie viele Schritte.
Der STYLE für FLUX ist nicht das, was man basierend auf PDXL und SD1.5 unter Stil versteht. Das Gradienten-System stilisiert Dinge, aber die gesamte Struktur leidet stark, wenn zu viel Information zu schnell einprogrammiert wird. Es ist extrem destruktiv, im Vergleich zu PDXL LoRAs, die mehr eine Ergänzung als eine neue Informationsquelle sind.
Kritische Erkenntnisse:
ALPHA, ALPHA und noch mehr ALPHA<<<< Das System läuft stark über Alpha-Gradienten. Alles MUSS speziell für Alpha-Gradienten in Bezug auf fotorealistische Details behandelt werden. Distanz, Tiefe, Verhältnis, Rotation, Offset usw. sind integrale Bestandteile der Modelkomposition. Für einen guten Kompositionsstil braucht man diese Details mehr als in einem einzigen Prompt.
ALLES muss korrekt beschrieben werden. Einfaches Danbooru-Tagging ist im Grunde nur Stil. Man zwingt das System, den Stil des gewünschten Systems zu erkennen, also kann man nicht ohne die nötigen Konzept-Tags neue Konzepte einbringen. Sonst scheitert der Stil- und Konzeptlinker und es kommt Müll raus. Garbage in, garbage out.
Pose-Training ist hoch wirksam bei Verwendung großer Mengen an Pose-Information. Das System erkennt schon viele Tags, wir wissen nur nicht welche. Pose-Training zur Verknüpfung der IST-Situation mit den WÜNSCHEN über spezifische Tags wird stark wirken bei Tag-Organisation und Feinabstimmung.
Schrittdokumentation:
v2 - 5572 Bilder -> 92 Posen -> 4000 Schritte FLUX
Das ursprüngliche Ziel, NAI zu SDXL zu bringen, wurde auf FLUX angewendet. Bleibt dran für weitere Versionen.
Stabilitätstests sind nötig, bisher zeigt es Fähigkeiten, die PDXL übertreffen. Zusätzliche Trainings nötig, aber bereits erstaunlich stark bei wenigen Trainingsschritten.
Die erste Ebene des Pose-Trainings umfasst etwa 500 Bilder, somit wird hauptsächlich diese Ebene ausschlaggebend sein. Die Trainingsdaten werden auf HuggingFace veröffentlicht, sobald sie organisiert sind. Ich will keine ungeeigneten Bilder oder schlechten Mix veröffentlichen.
Weiterlesen:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
Wichtige Verweise:
Ich rauche nicht, aber FLUX braucht hin und wieder eine Pause.
Ein Workflow- und Bildgenerierungsassistent. Ich nutze hauptsächlich die Kern-Komponenten, aber experimentiere immer wieder mit anderen.
Ein sehr mächtiges und schwer verständliches KI-Modell mit großem Potenzial.
Ohne sie hätte ich das gar nicht machen wollen. Großer Dank an das Staff von NAI für ihre Arbeit und den starken Bild- und Schreibassistenten. Unterstützt sie.
Sie haben Flux entwickelt und verdienen einen großen Anteil am Erfolg. Ich finetune und leite das "Leviathan" nur in die richtige Richtung.
Ein starker Tagging-Assistent. Ich wollte erst selbst einen schreiben, bis ich diesen gigantischen Helfer fand.
Zum Trainieren meiner Flux-Versionen genutzt. Es ist etwas zickig, aber funktionierte gut auf verschiedenen Systemen.
Der große Rivalen auf dem Spielfeld. Ein Monster bei der Generierung großer Gradientfelder, wertvolles Forschungs- und Verständnistool und Inspiration für diesen Fortschritt.

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
![Old Consistency V32 Lora [FLUX1.D/PDXL] Feminine v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































