SD XL - v1.0 VAE Fix
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder












Empfohlene Negative Prompts
(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera
Empfohlene Parameter
samplers
steps
cfg
resolution
Tipps
Das Modell ist für Forschungszwecke vorgesehen, einschließlich der Generierung von Kunstwerken, Bildungswerkzeugen und sicherer Bereitstellung.
Es ist nicht dazu bestimmt, faktische oder wahre Darstellungen von Personen oder Ereignissen zu erzeugen.
Einschränkungen umfassen unvollkommene Fotorealität, Unfähigkeit, lesbaren Text darzustellen, Schwierigkeiten bei kompositorischen Prompts und mögliche fehlerhafte Gesichtsgenerierung.
Das Modell nutzt zwei vortrainierte Textencoder: OpenCLIP-ViT/G und CLIP-ViT/L.
Die zweistufige Pipeline umfasst die Generierung von Basis-Latents, gefolgt von einer Hochauflösungsverfeinerung mit SDEdit (img2img).
Ersteller-Sponsoren
Ursprünglich auf Hugging Face veröffentlicht und hier mit Erlaubnis von Stability AI geteilt.
Ursprünglich auf Hugging Face veröffentlicht und hier mit Erlaubnis von Stability AI geteilt.
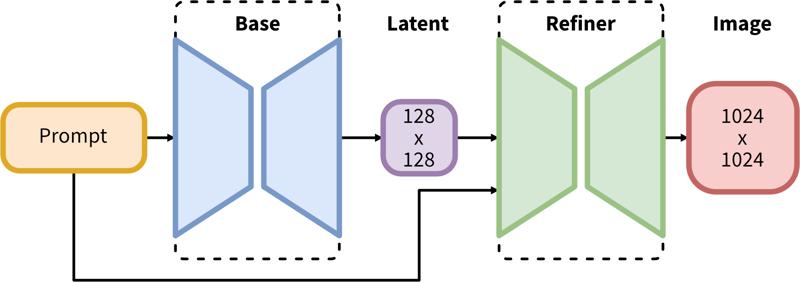
SDXL besteht aus einer zweistufigen Pipeline für latente Diffusion: Zuerst verwenden wir ein Basismodell, um Latents der gewünschten Ausgabengröße zu erzeugen. Im zweiten Schritt verwenden wir ein spezialisiertes Hochauflösungsmodell und wenden eine Technik namens SDEdit (https://arxiv.org/abs/2108.01073, auch bekannt als "img2img") auf die im ersten Schritt generierten Latents an, wobei derselbe Prompt verwendet wird.
Modellbeschreibung
Entwickelt von: Stability AI
Modelltyp: Diffusionsbasiertes Text-zu-Bild-Generierungsmodell
Modellbeschreibung: Dies ist ein Modell, das zur Generierung und Modifikation von Bildern basierend auf Textprompts verwendet werden kann. Es ist ein Latent Diffusion Model, das zwei feste, vortrainierte Textencoder nutzt (OpenCLIP-ViT/G und CLIP-ViT/L).
Ressourcen für weitere Informationen: GitHub Repository.
Modellquellen
Repository: https://github.com/Stability-AI/generative-models
Demo [optional]: https://clipdrop.co/stable-diffusion
Anwendungen
Direkte Nutzung
Das Modell ist ausschließlich für Forschungszwecke vorgesehen. Mögliche Forschungsbereiche und Aufgaben umfassen
Generierung von Kunstwerken und Einsatz im Design sowie anderen künstlerischen Prozessen.
Anwendungen in Bildungs- oder Kreativwerkzeugen.
Forschung zu generativen Modellen.
Sichere Bereitstellung von Modellen, die potenziell schädliche Inhalte erzeugen könnten.
Untersuchung und Verständnis der Einschränkungen und Verzerrungen generativer Modelle.
Ausgeschlossene Anwendungen werden unten beschrieben.
Nicht abgedeckte Nutzung
Das Modell wurde nicht trainiert, um faktische oder wahrheitsgetreue Darstellungen von Personen oder Ereignissen zu liefern, daher fällt die Nutzung zur Erzeugung solcher Inhalte außerhalb des Anwendungsbereichs dieses Modells.
Einschränkungen und Verzerrungen
Einschränkungen
Das Modell erreicht keinen perfekten Fotorealismus
Das Modell kann keine lesbaren Texte darstellen
Das Modell hat Schwierigkeiten mit komplexeren Aufgaben, die Kompositionalität erfordern, wie z. B. die Darstellung eines Bildes mit "Ein roter Würfel auf einer blauen Kugel"
Gesichter und Menschen werden möglicherweise nicht korrekt generiert.
Der autoencoding Teil des Modells ist verlustbehaftet.
Verzerrungen
Obwohl die Fähigkeiten der Bildgenerierungsmodelle beeindruckend sind, können sie soziale Verzerrungen verstärken oder verschärfen.
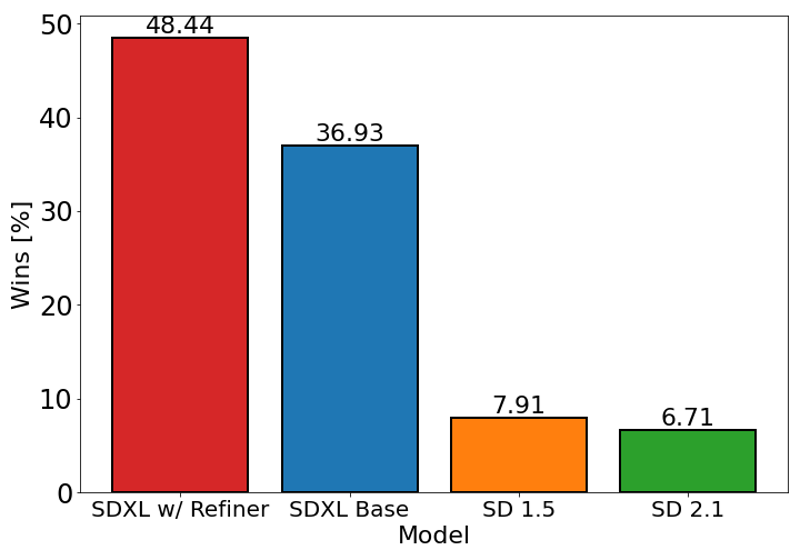
Das obige Diagramm bewertet die Nutzerpräferenz für SDXL (mit und ohne Verfeinerung) gegenüber Stable Diffusion 1.5 und 2.1. Das SDXL Basismodell performt deutlich besser als die vorherigen Varianten, und das Modell in Kombination mit dem Verfeinerungsmodul erreicht die beste Gesamtleistung.

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.










