Stable Cascade - Basis
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder


Empfohlene Parameter
steps
resolution
Tipps
Verwenden Sie die Version von Stufe C mit 3,6 Milliarden Parametern für beste Ergebnisse, da das Haupt-Finetuning darauf erfolgte.
Verwenden Sie die Variante mit 1,5 Milliarden Parametern für Stufe B, um bei der Rekonstruktion kleiner und feiner Details zu überzeugen.
Das Modell eignet sich aufgrund des kleineren latenten Raums gut für effizientes Training und Inferenz und unterstützt Erweiterungen wie Finetuning, LoRA, ControlNet, IP-Adapter und LCM.
Das Modell ist ausschließlich für Forschungszwecke gedacht und sollte nicht verwendet werden, um faktische Darstellungen zu erzeugen oder gegen die Nutzungsrichtlinien von Stability AI zu verstoßen.
Gesichter und Personen werden möglicherweise nicht korrekt generiert, da das Autoencoding des Modells verlustbehaftet ist.
Ersteller-Sponsoren
Demos:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Demos:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
Dieses Modell basiert auf der Würstchen-Architektur und unterscheidet sich hauptsächlich von anderen Modellen wie Stable Diffusion dadurch, dass es in einem deutlich kleineren latenten Raum arbeitet.
Warum ist das wichtig? Je kleiner der latente Raum, desto schneller kann die Inferenz ausgeführt und desto kostengünstiger wird das Training.
Wie klein ist der latente Raum? Stable Diffusion verwendet einen Kompressionsfaktor von 8, wodurch ein 1024x1024 Bild auf 128x128 kodiert wird. Stable Cascade erreicht einen Kompressionsfaktor von 42, was bedeutet, dass ein 1024x1024 Bild auf 24x24 kodiert werden kann und dabei scharfe Rekonstruktionen erhalten bleiben. Das textkonditionierte Modell wird dann im hochkomprimierten latenten Raum trainiert. Frühere Versionen dieser Architektur erreichten eine Kostenreduktion um das 16-fache im Vergleich zu Stable Diffusion 1.5. <br> <br>
Daher eignet sich dieses Modell besonders für Anwendungen, bei denen Effizienz wichtig ist. Zudem sind alle bekannten Erweiterungen wie Finetuning, LoRA, ControlNet, IP-Adapter, LCM usw. mit dieser Methode möglich.
Modelldetails
Modellbeschreibung
Stable Cascade ist ein Diffusionsmodell, das trainiert wurde, Bilder auf Basis eines Textprompts zu erzeugen.
Entwickelt von: Stability AI
Finanziert von: Stability AI
Modelltyp: Generatives Text-zu-Bild-Modell
Modellquellen
Für Forschungszwecke empfehlen wir unser StableCascade Github-Repository (https://github.com/Stability-AI/StableCascade).
Repository: https://github.com/Stability-AI/StableCascade
Modellübersicht
Stable Cascade besteht aus drei Modellen: Stufe A, Stufe B und Stufe C, die zusammen eine Kaskade zur Bilderzeugung darstellen, daher der Name „Stable Cascade“.
Stufe A & B dienen der Bildkompression, ähnlich der Funktion des VAE in Stable Diffusion.
Mit diesem Aufbau wird jedoch eine deutlich höhere Bildkompression erreicht. Während Stable Diffusion einen räumlichen Kompressionsfaktor von 8 verwendet und ein Bild mit der Auflösung 1024 x 1024 auf 128 x 128 kodiert, erreicht Stable Cascade einen Kompressionsfaktor von 42. Dadurch wird ein 1024 x 1024 Bild auf 24 x 24 kodiert und kann dennoch präzise dekodiert werden. Dies bietet den großen Vorteil günstigerer Trainings- und Inferenzkosten. Stufe C ist für die Erzeugung der kleinen 24 x 24 latenten Repräsentationen anhand eines Textprompts verantwortlich. Das folgende Bild zeigt dies visuell.
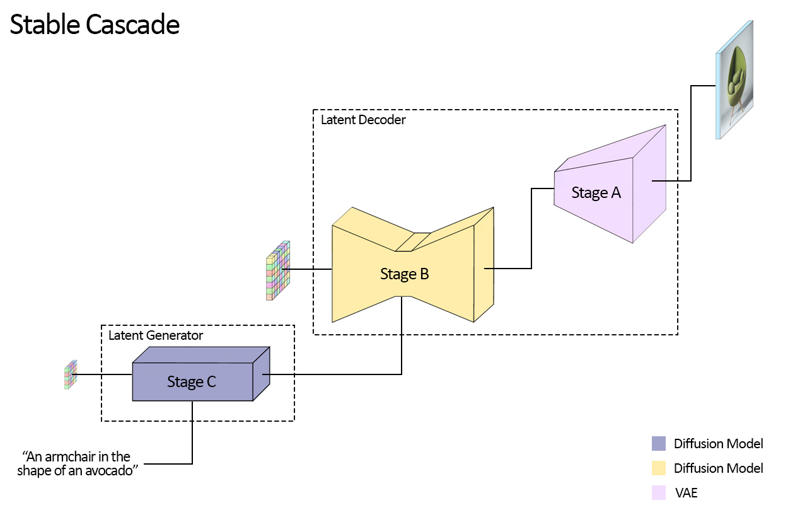
Zu dieser Veröffentlichung stellen wir zwei Checkpoints für Stufe C, zwei für Stufe B und einen für Stufe A bereit. Stufe C gibt es in einer Version mit 1 Milliarde und 3,6 Milliarden Parametern; wir empfehlen jedoch dringend die 3,6 Milliarden-Version, da der Großteil des Finetunings darauf basierte. Die beiden Versionen für Stufe B umfassen 700 Millionen und 1,5 Milliarden Parameter. Beide liefern hervorragende Ergebnisse, wobei die 1,5 Milliarden-Version besonders bei der Rekonstruktion kleiner und feiner Details überzeugt. Für die besten Resultate empfiehlt sich also jeweils die größere Variante. Stufe A enthält 20 Millionen Parameter und ist aufgrund ihrer kleinen Größe festgelegt.
Bewertung
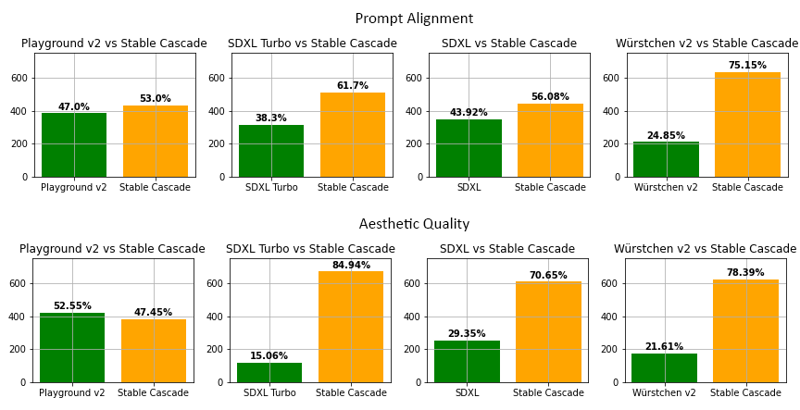
Laut unserer Bewertung erzielt Stable Cascade in fast allen Vergleichen sowohl bei der Übereinstimmung mit dem Prompt als auch bei der ästhetischen Qualität die besten Ergebnisse. Das obige Bild zeigt Resultate einer menschlichen Bewertung mit einer Mischung aus partiellen Prompts (Link) und ästhetischen Prompts. Konkret wurde Stable Cascade (30 Inferenzschritte) gegenüber Playground v2 (50 Inferenzschritte), SDXL (50 Inferenzschritte), SDXL Turbo (1 Inferenzschritt) und Würstchen v2 (30 Inferenzschritte) verglichen.
Beispielcode
⚠️ Wichtig: Damit der folgende Code funktioniert, müssen Sie diffusers aus diesem Branch installieren, solange der PR in Arbeit ist.
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Anthropomorpher Kater, der als Pilot verkleidet ist"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
# Jetzt ist decoder_output eine Liste Ihrer PIL-BilderAnwendungen
Direkte Verwendung
Das Modell ist vorerst für Forschungszwecke gedacht. Mögliche Forschungsfelder und Aufgaben umfassen
Forschung an generativen Modellen.
Sichere Bereitstellung von Modellen, die potenziell schädliche Inhalte erzeugen können.
Erforschung und Verständnis der Einschränkungen und Verzerrungen generativer Modelle.
Erzeugung von Kunstwerken und Verwendung in Design- und anderen künstlerischen Prozessen.
Anwendungen in Bildungs- oder Kreativwerkzeugen.
Nicht zugelassene Verwendungen sind unten beschrieben.
Nicht erlaubte Verwendungen
Das Modell wurde nicht darauf trainiert, faktische oder wahre Darstellungen von Personen oder Ereignissen zu erzeugen,
und daher ist die Verwendung des Modells zur Generierung solcher Inhalte außerhalb dessen Fähigkeiten.
Das Modell darf nicht in einer Weise verwendet werden, die gegen die Nutzungsrichtlinien von Stability AI verstößt.
Einschränkungen und Verzerrungen
Einschränkungen
Gesichter und Personen werden möglicherweise nicht richtig generiert.
Der autoencoding-Teil des Modells ist verlustbehaftet.
Empfehlungen
Das Modell ist ausschließlich für Forschungszwecke vorgesehen.
Erste Schritte mit dem Modell
Besuchen Sie https://github.com/Stability-AI/StableCascade

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - Stable Cascade
Bilder von Stable Cascade - Basis
Bilder mit Anime










Bilder mit Kunst










Bilder mit Basismodell

Bilder mit logo










