Animagine XL 4.0 - v4 Opt
Palabras Clave y Etiquetas Relacionadas
Imágenes destacadas





Prompts Recomendados
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
Prompts Negativos Recomendados
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
Parámetros Recomendados
samplers
steps
cfg
resolution
Consejos
Use captions basados en etiquetas con método de ordenamiento de etiquetas para mejores resultados: 1girl/1boy/1other, nombre del personaje, serie, clasificación, otras etiquetas, luego mejora de calidad.
Agregue etiquetas de mejora de calidad al final del prompt: masterpiece, high score, great score, absurdres.
Use prompts negativos recomendados para evitar artefactos y errores no deseados.
La escala CFG óptima está entre 4 y 7, recomendada en 5.
Los pasos de muestreo óptimos están entre 25 y 28, con 28 recomendado.
El sampler preferido es Euler Ancestral (Euler a).
Tenga en cuenta las limitaciones del modelo como dificultad con anatomía compleja y renderizado de texto.
Los personajes recientes podrían tener menor precisión debido a datos de entrenamiento limitados.
Aspectos Destacados de la Versión
Con el lanzamiento de Animagine XL 4.0 Opt (Optimizado), el modelo ha sido refinado aún más con un conjunto adicional de datos, mejorando su rendimiento para uso general. Esta actualización trae varias mejoras:
Mejor estabilidad para salidas más consistentes
Anatomía mejorada con proporciones más precisas
Ruido y artefactos reducidos en las generaciones
Solucionados problemas de baja saturación, resultando en colores más ricos
Mejor precisión del color para resultados más atractivos visualmente
Patrocinadores del Creador
Apoye el Desarrollo de Animagine XL
- Done ETH/USDT a
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - Patrocinadores en GitHub: https://github.com/sponsors/cagliostrolab/
- Únase a la comunidad de Discord: https://discord.gg/cqh9tZgbGc
Por favor lea nuestra guía detallada para prompts en Blog de Cagliostrolab
Resumen
Animagine XL 4.0, también estilizado como Anim4gine, es el modelo definitivo afinado para Stable Diffusion XL con temática anime y la última entrega de la serie Animagine XL. A pesar de ser una continuación, el modelo fue reentrenado desde Stable Diffusion XL 1.0 con un extenso conjunto de datos de 8.4M de imágenes de estilo anime diversas provenientes de varias fuentes, con corte de conocimiento del 7 de enero de 2025 y afinado por aproximadamente 2650 horas de GPU. Similar a la versión anterior, este modelo fue entrenado usando el método de ordenamiento de etiquetas para identidad y estilo.
Con el lanzamiento de Animagine XL 4.0 Opt (Optimizado), el modelo fue refinado aún más con un conjunto adicional de datos, mejorando la estabilidad, precisión anatómica, reducción de ruido, saturación de color y la precisión general del color. Estas mejoras hacen que Animagine XL 4.0 Opt sea más consistente y visualmente atractivo, manteniendo la calidad característica de la serie.
Historial de cambios
- 2025-02-13 – Añadidos Animagine XL 4.0 Opt y Animagine XL 4.0 Zero
Mejor estabilidad para salidas más consistentes
Anatomía mejorada con proporciones más precisas
Ruido y artefactos reducidos en las generaciones
Solucionados problemas de baja saturación, resultando en colores más ricos
Mejor precisión del color para resultados más atractivos visualmente
- 2025-01-24 – Lanzamiento inicial
Detalles del Modelo
Desarrollado por: Cagliostro Research Lab
Tipo de modelo: Modelo generativo texto-a-imagen basado en difusión
Licencia: CreativeML Open RAIL++-M
Descripción del modelo: Modelo usado para generar y modificar imágenes con temática anime basadas en prompts de texto
Afinado desde: Stable Diffusion XL 1.0
Guía de Uso
Se puede ver el resumen en la imagen para la guía de prompts.

1. Estructura del Prompt
El modelo fue entrenado con captions basados en etiquetas y el método de ordenamiento de etiquetas. Use esta plantilla estructurada:
1girl/1boy/1other, nombre del personaje, de qué serie, clasificación, todo lo demás en cualquier orden y termine con mejora de calidad
2. Etiquetas de Mejora de Calidad
Agregue estas etiquetas al final de su prompt:
masterpiece, high score, great score, absurdres
3. Prompt Negativo Recomendado
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Configuraciones Óptimas
CFG Scale: 4-7 (5 recomendado)
Pasos de muestreo: 25-28 (28 recomendado)
Sampler preferido: Euler Ancestral (Euler a)
5. Resoluciones Recomendadas
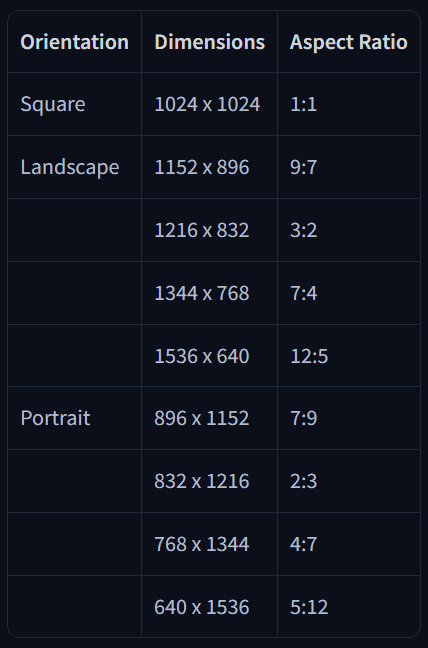
6. Ejemplo de Estructura Final de Prompt
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
Etiquetas Especiales
El modelo soporta varias etiquetas especiales que se pueden usar para controlar diferentes aspectos del proceso de generación de imágenes. Estas etiquetas están cuidadosamente ponderadas y probadas para proporcionar resultados consistentes en distintos prompts.
Etiquetas de Calidad
Las etiquetas de calidad son controles fundamentales que influyen directamente en la calidad general y nivel de detalle de la imagen. Etiquetas de calidad disponibles:
masterpiecebest qualitylow qualityworst quality
Etiquetas de Puntuación
Las etiquetas de puntuación ofrecen un control más matizado sobre la calidad de la imagen en comparación con las etiquetas básicas de calidad. Tienen un impacto más fuerte para guiar la calidad del resultado en este modelo. Etiquetas de puntuación disponibles:
high scoregreat scoregood scoreaverage scorebad scorelow score
Etiquetas Temporales
Las etiquetas temporales permiten influir en el estilo artístico basado en períodos de tiempo o años específicos. Esto es útil para generar imágenes con características artísticas propias de una era. Etiquetas de años soportadas:
year 2005year {n}year 2025
Etiquetas de Clasificación
Las etiquetas de clasificación ayudan a controlar el nivel de seguridad del contenido de las imágenes generadas. Estas etiquetas deben usarse responsablemente y conforme a leyes aplicables y políticas de plataforma. Clasificaciones soportadas:
safesensitivensfwexplicit
Información de Entrenamiento
El modelo fue entrenado usando hardware de última generación y parámetros optimizados para asegurar la más alta calidad de salida. A continuación están las especificaciones técnicas detalladas y parámetros usados durante el proceso de entrenamiento:

Agradecimientos
Este proyecto a largo plazo no habría sido posible sin el trabajo innovador, las contribuciones y la documentación completa proporcionadas por Stability AI, Novel AI y Waifu Diffusion Team. Estamos especialmente agradecidos por la subvención inicial de Main que nos permitió avanzar más allá de la V2. Para esta iteración, expresamos nuestro más sincero agradecimiento a toda la comunidad por su apoyo continuo, en particular:
Moescape AI: Nuestro valioso socio en distribución y pruebas del modelo
Lesser Rabbit: Por proveer subvenciones esenciales para investigación y computación
Kohya SS: Por desarrollar el completo marco de entrenamiento open-source
discus0434: Por crear el predictor estético 2.5 open-source líder en la industria
Probadores tempranos: Por su dedicación brindando retroalimentación crítica y aseguramiento de calidad exhaustivo
Colaboradores
Extendemos nuestro más profundo agradecimiento a los miembros dedicados del equipo que han contribuido significativamente a este proyecto, incluyendo pero no limitado a:
Modelo
Gradio
Relaciones, finanzas y aseguramiento de calidad
Datos
¡La Recaudación de Fondos está Abierta de Nuevo!
Estamos emocionados de presentar nuevos métodos de recaudación de fondos mediante GitHub Sponsors para apoyar el entrenamiento, investigación y desarrollo del modelo. Su apoyo nos ayuda a expandir los límites de lo posible con IA.
Puede ayudarnos con:
Donar: Contribuya vía ETH o USDT a la dirección abajo.
Compartir: ¡Difunda la palabra sobre nuestros modelos y comparta sus creaciones!
Retroalimentación: Díganos cómo podemos mejorar.
Dirección para donaciones:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
Patrocinio en Github: https://github.com/sponsors/cagliostrolab/
¿Por qué usamos criptomonedas?:
Cuando inicialmente abrimos la recaudación a través de Ko-fi y PayPal como método de retiro, nuestra cuenta PayPal fue señalada y eventualmente prohibida, a pesar de nuestros esfuerzos de explicar el propósito del proyecto. Lamentablemente, esto nos obligó a reembolsar todas las donaciones y quedamos sin un método confiable para recibir apoyo. Para evitar tales problemas y garantizar transparencia, ahora usamos criptomonedas para recaudar fondos.
¿Quieres donar en moneda no cripto?
Aunque tuvimos una mala experiencia con PayPal y desea apoyarnos sin usar criptomonedas, puede contactarnos mediante Servidor de Discord para métodos alternativos de donación.
Únase a nuestro Servidor de Discord
Siéntase libre de unirse a nuestro servidor de Discord: https://discord.gg/cqh9tZgbGc
Limitaciones
Formato del Prompt: Limitado a texto basado en etiquetas; la entrada en lenguaje natural puede no ser eficaz
Anatomía: Puede tener dificultades con detalles anatómicos complejos, especialmente poses de manos y conteo de dedos
Generación de Texto: Actualmente no se soporta ni recomienda la renderización de texto en imágenes
Personajes Nuevos: Personajes recientes pueden tener menor precisión debido a datos limitados
Múltiples Personajes: Escenas con múltiples personajes pueden requerir ingeniería cuidadosa de prompts
Resolución: Resoluciones más altas (por ejemplo, 1536x1536) pueden mostrar degradación ya que el entrenamiento usó resolución original de SDXL
Consistencia de Estilo: Puede requerir etiquetas específicas de estilo ya que el entrenamiento se centró más en preservar identidad que en consistencia de estilo
Licencia
Este modelo adopta la licencia original CreativeML Open RAIL++-M License de Stability AI sin modificaciones o restricciones adicionales. Los términos de la licencia permanecen exactamente como se especifica en la licencia original de SDXL, que incluye:
✅ Permitido: Uso comercial, modificaciones, distribuciones, uso privado
❌ Prohibido: Actividades ilegales, generación de contenido dañino, discriminación, explotación
⚠️ Requisitos: Incluir copia de la licencia, indicar cambios, preservar avisos
📝 Garantía: Proporcionado "TAL CUAL" sin garantías
Consulte la licencia original de SDXL para los términos y condiciones completos y oficiales.

Detalles del Modelo
Tipo de modelo
Modelo base
Versión del modelo
Hash del modelo
Creador
Discusión
Por favor log in para dejar un comentario.
Colección de Modelos - Animagine XL 4.0
Imágenes por Animagine XL 4.0 - v4 Opt
Imágenes con anime










Imágenes con modelo base

Imágenes con sdxl


