Anime Illust Diffusion XL - v0.5-alpha
Palabras Clave y Etiquetas Relacionadas
Imágenes destacadas





Prompts Recomendados
frieren from sousou no frieren,impasto style,beautiful color, detailed, aesthetic
best quality,masterpiece,vivid color,1girl,solo,bangs
Prompts Negativos Recomendados
worst quality:1.3,low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxl_neg
Parámetros Recomendados
samplers
steps
cfg
resolution
vae
other models
Parámetros Recomendados de Alta Resolución
denoising strength
Consejos
Reduce el peso en palabras clave de estilo de artista, por ejemplo (by xxx:0.6).
Ordena tus etiquetas del prompt para mejores resultados.
Usa el VAE del modelo o sdxl-vae.
Aspectos Destacados de la Versión
Se añadieron 143 palabras clave nuevas. Esta versión es beta de AIDXLv0.5. Los nuevos estilos no son estables. Recomendaría AIDXLv0.41 para mejor experiencia.
Add 143 new trigger words. This version is a beta version of AIDXLv0.5. The new styles are not stable. I would recommend AIDXLv0.41 for better experience.
Patrocinadores del Creador
Patrocinio de potencia computacional: Gracias a la comunidad @NieTa (捏Ta (nieta.art)) por proveer soporte computacional;
Soporte de datos: Gracias a @KirinTea_Aki (Perfil KirinTea_Aki | Civitai) y a @Chenkin (Civitai | Comparte tus modelos) por proveer gran cantidad de datos;
No existiría la versión 0.7 sin ellos.
Introducción al Modelo (parte en inglés)
I Contenidos
En esta introducción, aprenderás sobre:
Información del modelo (ver Sección II);
Instrucciones de uso (ver Sección III);
Parámetros de entrenamiento (ver Sección IV);
Lista de Palabras Clave (ver Apéndice Parte A)
II AIDXL
Anime Illustration Diffusion XL, o AIDXL, es un modelo dedicado a generar ilustraciones de anime estilizadas. Cuenta con más de 800 (con más actualizaciones constantes) estilos incorporados, que se activan mediante palabras clave específicas (ver Apéndice A).
Ventajas:
Composición flexible en lugar de poses tradicionales de IA.
Detalles hábiles en lugar de caos desordenado.
Reconocimiento mejor de personajes de anime.
III Guía del Usuario
1 Uso básico
1.1 Prompt
Palabras clave: Añade las palabras clave proporcionadas en Apéndice A para estilizar la imagen. Las palabras clave adecuadas mejorarán enormemente la calidad;
Se recomienda reducir el peso de las palabras clave del estilo del artista, por ejemplo, (by xxx:0.6).
Orden semántico: Ordenar tus etiquetas o frases en el prompt ayudará al modelo a entender tu intención.
Orden recomendado: Palabra clave (by xxx) -> personaje (una chica llamada frieren de la serie sousou no frieren) -> raza (elfo) -> composición (plano vaquero) -> estilo (estilo impasto ) -> tema (fantasía) -> ambiente principal (en el bosque, de día) -> fondo (fondo degradado) -> acción (sentada en el suelo) -> expresión (sin expresión) -> características principales (cabello blanco) -> características del cuerpo (coletas, ojos verdes, labios separados) -> ropa (vestido blanco) -> accesorios de ropa (volantes) -> otros objetos (un gato) -> ambiente secundario (césped, sol) -> estética (color hermoso, detallado, estético) -> calidad ((mejor calidad:1.3))
Prompts negativos: (peor calidad:1.3), baja calidad, baja resolución, desordenado, abstracto, feo, deforme, mala anatomía, borrador, manos deformes, dedos fusionados, firma, texto, vistas múltiples
1.2 Parámetros de Generación
Resolución: Asegura que el número total de píxeles (=ancho * alto) esté alrededor de 1024*1024 y que ancho y alto sean divisibles entre 32, así AIDXL producirá el mejor resultado. Por ejemplo, 832x1216 (2:3), 1216x832 (3:2), y 1024x1024 (1:1), etc.
Sampler y pasos: Usa el sampler "Euler Ancester", llamado Euler A en webui. Realiza aproximadamente ~28 pasos con una escala CFG de 7 a 9.
'Refinar': La imagen generada desde text2image a veces está borrosa, en ese caso necesitas 'refinarla' usando image2image o inpainting, etc.
Para un escalado simple, puedes referirte a: Escalar a tamaños enormes y añadir detalle con SD Upscale, ¡es fácil! : r/StableDiffusion (reddit.com)
Otros componentes: No es necesario usar ningún modelo refinador. Usa el VAE del modelo mismo o el
sdxl-vae.
Q: ¿Cómo reproducir la portada del modelo? ¿Por qué no puedo generar la misma imagen que la portada con los mismos parámetros?
A: Porque los parámetros de generación mostrados en la portada no son los parámetros de text2image, sino los parámetros de image2image (para escalar). La imagen base es generada mayoritariamente con el sampler Euler Ancester y no con el sampler DPM.
2 Uso especial
2.1 Estilos Generalizados
Desde la versión 0.7, AIDXL resume varios estilos similares e introduce palabras clave de estilo generalizado. Estas representan una categoría común de estilo de ilustración de animación. Ten en cuenta que estas palabras clave no necesariamente siguen el significado artístico literal, sino que son palabras clave especiales redefinidas.
2.2 Personajes
Desde la versión 0.7, AIDXL ha mejorado el entrenamiento para personajes. Algunos disparadores de personajes ya pueden lograr efectos similares a Lora y separan bien el concepto del personaje de su vestimenta.
El método para activar personajes es: {character} \({copyright}\). Por ejemplo, para activar a la heroína Lucy en la animación "Cyberpunk: Edgerunners", usa lucy \(cyberpunk\); para activar al personaje Gan Yu en el juego "Genshin Impact", usa ganyu \(genshin impact\). Aquí, "lucy" y "ganyu" son nombres de personajes, "\(cyberpunk\)" y "\(genshin impact\)" son los orígenes de dichos personajes, y los paréntesis se escapan con barras "\" para evitar que se interpreten como etiquetas ponderadas. Para algunos personajes, la parte de copyright no es necesaria.
Desde la versión v0.8, hay un método más fácil para activar personajes: a {girl/boy} named {character} from {copyright} series.
Para la lista de palabras clave de personajes, consulta: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). También pueden incluirse palabras clave adicionales no mencionadas en este documento.
Algunos personajes requieren pasos adicionales para activarse. Si no se puede restaurar completamente un personaje con una sola palabra clave, se deben añadir sus características principales al prompt.
AIDXL soporta cambio de ropa para personajes. Las palabras clave de personajes usualmente no incluyen la vestimenta del personaje. Para añadir ropa, debes incluir etiquetas de ropa en el prompt. Por ejemplo, silver evening gown, plunging neckline da el vestido del personaje St. Louis (Luxurious Wheels) del juego Azur Lane. De modo similar, puedes añadir etiquetas de ropa de cualquier personaje a otros.
2.3 Etiquetas de Calidad
Calidad y estética son etiquetas formalmente entrenadas. Incluirlas en los prompts influirá en la calidad de la imagen generada.
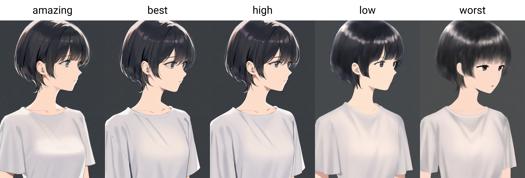
Desde la versión 0.7, AIDXL entrena e introduce oficialmente etiquetas de calidad. Estas se dividen en seis niveles, de mejor a peor: amazing quality, best quality, high quality, normal quality, low quality y worst quality.
Se recomienda añadir más peso a las etiquetas de calidad, por ejemplo (amazing quality:1.5).
2.4 Etiquetas Estéticas
Desde la versión 0.7 se introdujeron etiquetas estéticas para describir características visuales especiales de las imágenes.
2.5 Fusión de Estilos
Puedes fusionar algunos estilos en tu estilo personalizado. "Fusionar" significa usar varias palabras clave de estilo a la vez. Por ejemplo, chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Algunos consejos:
Controla el peso y orden de los estilos para ajustar el estilo final.
Añade las etiquetas al final y no al principio del prompt.
IV Estrategia y Parámetros de Entrenamiento
AIDXLv0.1
Utilizando SDXL1.0 como modelo base, con aproximadamente 22k imágenes etiquetadas, se entrenó durante unas 100 épocas con un programador coseno y una tasa de aprendizaje de 5e-6, con número de ciclos = 1, obteniendo el modelo A. Luego, usando una tasa de aprendizaje de 2e-7 bajo los mismos parámetros, se obtuvo el modelo B. El modelo AIDXLv0.1 se obtiene fusionando los modelos A y B.
AIDXLv0.51
Estrategia de Entrenamiento
Se reanuda el entrenamiento desde AIDXLv0.5, con tres fases de entrenamiento en secuencia:
Entrenamiento con captions largas: Utiliza todo el conjunto de datos, con algunas imágenes etiquetadas manualmente. Comienza entrenando el U-Net y el codificador de texto con el optimizador AdamW8bit, una tasa de aprendizaje alta (alrededor de 1.5e-6) y programador coseno. Detén el entrenamiento cuando la tasa de aprendizaje baje de cierto umbral (aprox. 5e-7).
Entrenamiento con captions cortas: Reinicia el entrenamiento desde el resultado del paso 1 con los mismos parámetros pero con un conjunto de datos con captions más cortas.
Paso de refinamiento: Prepara un subconjunto de alta calidad del dataset del paso 1. Reinicia desde el resultado del paso 2 con una tasa de aprendizaje baja (alrededor de 7.5e-7), usando el programador coseno con reinicios de 5 a 10 ciclos. Entrena hasta lograr un resultado estéticamente bueno.
Parámetros de Entrenamiento Fijos
Sin ruido extra como offset de ruido.
Min snr gamma = 5: acelera el entrenamiento.
Precisión completa bf16.
Optimizador AdamW8bit: equilibrio entre eficiencia y rendimiento.
Conjunto de Datos
Resolución: 1024x1024 con estrategia modificada de bucketing oficial de SDXL.
Captioning: Etiquetado por modelo WD14-Swinv2 con umbral 0.35.
Recorte de primeros planos: Corta imágenes en varios primeros planos, útil para imágenes grandes o escasas.
Palabras clave: Mantén la primera etiqueta de las imágenes como sus palabras clave.
AIDXLv0.6
Estrategia de Entrenamiento
Se reanuda desde AIDXLv0.52 con una estrategia adaptativa de repeticiones: para cada imagen etiquetada, incrementa el número de repeticiones en el entrenamiento sujeto a las siguientes reglas:
Regla 1: Mientras mayor calidad tenga la imagen, más repeticiones tendrá;
Regla 2: Si la imagen pertenece a una clase de estilo:
Si la clase está sin ajustar o poco ajustada, incrementar manualmente las repeticiones de la clase, o aumentar automáticamente hasta que las repeticiones totales para esa clase alcancen alrededor de 100.
Si la clase ya está ajustada o sobreajustada, reducir manualmente las repeticiones a 1 y eliminar si la calidad es baja.
Regla 3: Limitar el número final de repeticiones para que no supere un umbral, alrededor de 10.
Esta estrategia ofrece ventajas:
Protege la información original del modelo de nuevo entrenamiento, similar a una imagen regularizada;
Hace el impacto del conjunto de entrenamiento más controlable;
Equilibra el entrenamiento entre clases motivando las no ajustadas y previniendo sobreajuste en las ya ajustadas;
Reduce significativamente el uso de recursos computacionales y facilita añadir nuevos estilos al modelo.
Parámetros Fijos de Entrenamiento
Iguales a AIDXLv0.51.
Conjunto de Datos
Basado en AIDXLv0.51, se aplican optimizaciones:
Orden semántico en captions: Ordena las etiquetas de captions por orden semántico, por ejemplo "gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun".
Eliminación de duplicados en captions: Elimina etiquetas duplicadas, conserva la que retenga más información. Duplicados incluyen etiquetas similares como "long hair" y "very long hair".
Etiquetas adicionales: Añade manualmente etiquetas adicionales a todas las imágenes, por ejemplo "alta calidad", "impasto", etc. Esto puede hacerse rápidamente con herramientas.
V Agradecimientos especiales
Patrocinio de potencia computacional: Gracias a la comunidad @NieTa (捏Ta (nieta.art)) por proveer soporte de potencia computacional;
Soporte de datos: Gracias a @KirinTea_Aki (Perfil de Creadores KirinTea_Aki | Civitai) y a @Chenkin (Civitai | Comparte tus modelos) por proveer gran cantidad de datos;
No habría versión 0.7 sin ellos.
VI AIDXL vs AID
08/08/2023. AIDXL se entrena con el mismo conjunto que AIDv2.10, pero supera a AIDv2.10. AIDXL es más inteligente y puede hacer muchas cosas que los modelos basados en SD1.5 no pueden. También distingue muy bien conceptos, aprende detalles de imágenes, maneja composiciones difíciles o imposibles para SD1.5 y AID. En general, tiene potencial absoluto. Continuaré actualizando AIDXL.
VII Patrocinio
Si te gusta nuestro trabajo, puedes patrocinarnos vía Ko-fi(https://ko-fi.com/eugeai) para apoyar nuestra investigación y desarrollo. ¡Gracias por tu apoyo~
Introducción al Modelo (parte en chino)
I Índice
En esta introducción, aprenderás:
Introducción al modelo (ver Sección II);
Guía de uso (ver Sección III);
Parámetros de entrenamiento (ver Sección IV);
Lista de palabras clave (ver Apéndice A)
II Introducción al modelo
Anime Illust Diffusion XL, o AIDXL, es un modelo dedicado a generar ilustraciones de estilo anime. Cuenta con más de 800 estilos incorporados (en continuo aumento) activados por palabras clave específicas (ver Apéndice A).
Ventajas: composición audaz, sin sensación de pose rígida, sujeto destacado, sin detalles desordenados, reconoce muchos personajes de anime (activado por nombres en romanización japonesa, como "ayanami rei" para "绫波丽" o "kamado nezuko" para "祢豆子").
III Guía de uso (actualizable)
1 Uso básico
1.1 Escritura de prompts
Usa palabras clave: Utiliza las palabras clave del Apéndice A para estilizar las imágenes. Las adecuadas mejorarán en gran medida la calidad;
Etiqueta el prompt: Usa etiquetas para describir el objeto generado;
Ordena el prompt: ordenar tus prompts ayudará al modelo a entender mejor. Orden recomendado:
palabra clave (by xxx)->sujeto principal (1girl)->personaje (frieren)->raza (elf)->composición (cowboy shot)->estilo (impasto)->tema (fantasía)->ambiente principal (bosque, día)->fondo (fondo degradado)->acción (sentada)->expresión (sin expresión)->características principales (cabello blanco)->características corporales (coletas, ojos verdes, labios separados)->vestimenta (vestido blanco)->accesorios (volantes)->otros objetos (varita mágica)->ambiente secundario (césped, sol)->estética (color hermoso, detallado, estético)->calidad (best quality)
Prompts negativos: peor calidad, baja calidad, baja resolución, desordenado, abstracto, feo, deformado, mala anatomía, manos deformes, dedos fusionados, firma, texto, vistas múltiples
1.2 Parámetros de generación
Resolución: Asegúrate de que la resolución total (alto x ancho) esté cerca de 1024*1024 y que ancho y alto sean múltiplos de 32. Ejemplos: 832x1216 (3:2), 1216x832 (3:2), y 1024x1024 (1:1).
No usar Clip Skip, es decir, Clip Skip = 1.
Sampler y pasos: usar el sampler “euler_ancester”, llamado Euler A en webui, con 28 pasos en CFG Scale 7.
No utilizar refiner.
Usar VAE base o sdxl-vae.
2 Uso especial
2.1 Estilización generalizada
Versión 0.7 agrupa estilos similares e introduce palabras clave de estilo generalizado que representan categorías comunes de estilo de ilustración.
Estas palabras clave no necesariamente se corresponden con su significado artístico literal, sino que han sido redefinidas.
2.2 Personajes
Versión 0.7 mejora el entrenamiento para personajes. Algunas palabras clave logran efectos tipo lora y separan bien concepto y ropa.
Activación de personajes con nombre_personaje \(obra\). Ejemplo, para "Cyberpunk: Edgerunners" y heroína Lucy: lucy \(cyberpunk\); para "Genshin Impact" y Gan Yu: ganyu \(genshin impact\). Los nombres y obras se escapan con \ para evitar confusión con pesos.
Lista de palabras clave de personajes en selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co).
Si un personaje no se puede reproducir completamente con una palabra, añade características principales en el prompt.
Las palabras de personajes no suelen incluir ropa. Para ropa, añade etiquetas específicas, como silver evening gown, plunging neckline para el vestido de St. Louis (Luxurious Wheels) en Azur Lane.
2.3 Etiquetas de calidad
En la versión 0.7, las etiquetas de calidad y estética son entrenadas formalmente y afectan la calidad al usarlas.
Seis niveles: amazing quality, best quality, high quality, normal quality, low quality y worst quality.
2.4 Etiquetas estéticas
Desde 0.7 se incluyen etiquetas para describir características estéticas especiales.
2.5 Fusión de estilos
Puedes mezclar varios estilos en uno personalizado usando múltiples palabras clave a la vez, como chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Consejos:
Controla pesos y orden para ajustar el estilo.
Añade al final del prompt, no al principio.
3 Precauciones
Usa modelos VAE, embeddings y Lora compatibles con SDXL. Nota: sd-vae-ft-mse-original no soporta SDXL; EasyNegative, badhandv4 y otros embeddings negativos tampoco.
Para versiones ≤ 0.61: al generar imágenes, se recomienda usar embeddings negativos dedicados al modelo (disponibles en recursos sugeridos), ya que benefician casi exclusivamente al modelo.
Las palabras clave nuevas en cada versión pueden tener efectos más débiles o inestables en dicha versión.
IV Parámetros de entrenamiento
Basado en SDXL1.0, con unas 20k imágenes etiquetadas propias, tasa de aprendizaje 5e-6 y un programador coseno con 1 ciclo, entrenado durante ~100 épocas para obtener modelo A. Luego, con tasa de aprendizaje 2e-7 y mismos parámetros, se obtuvo modelo B. Se fusionaron los modelos A y B para formar AIDXLv0.1.
Más parámetros en la versión en inglés.
V Agradecimientos especiales
Patrocinio computacional: gracias a la comunidad @捏Ta ( 捏Ta (nieta.art)) por su soporte;
Soporte de datos: gracias a @秋麒麟热茶 (Perfil KirinTea_Aki | Civitai) y @风吟 (Perfil Chenkin | Civitai) por proveer muchos datos;
Sin ellos no existiría la versión 0.7.
VI Registro de cambios
08/08/2023: AIDXL fue entrenado con el mismo set que AIDv2.10 pero lo supera. AIDXL es más inteligente y puede lograr cosas que SD1.5 no puede. Discierne conceptos, aprende detalles, maneja construcciones difíciles, y perfecciona estilos que AID viejo no podía. En resumen, tiene más potencial que SD1.5 y seguiré actualizándolo.
27/01/2024: La versión 0.7 añade mucho contenido, con un dataset más del doble que la anterior.
Para lograr anotaciones adecuadas, probé muchos algoritmos nuevos como ordenación de etiquetas, estratificación aleatoria de etiquetas y separación de características de personajes. Proyecto en: Eugeoter/sd-dataset-manager (github.com);
Para control y obediencia al entrenamiento, hice un script especial basado en Kohya-ss;
Para controlar la fusión de generaciones en diferentes modelos, desarrollé algoritmos heurísticos para fusionar modelos; para estilización suficiente descarté fusionar capas OUT de texto y UNET para mantener estabilidad y estética porque afecta estilo.
Para filtrar datos entrené modelos de detección de marcas de agua, clasificación de imágenes y puntuación estética que ayudan a limpiar el dataset.
VII Patrocínanos
Si te gusta nuestro trabajo, apóyanos con Ko-fi(https://ko-fi.com/eugeai) para apoyar nuestra investigación y desarrollo. ¡Gracias!
Apéndice / 附录
A. Lista de Palabras Clave Especiales / 特殊触发词列表
Palabras clave de estilo artístico: Haz clic aquí
Palabras clave de estilo de pintura: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Colores planos, usando líneas para describir luces y sombras
平涂:色 plano, usa líneas y bloques de color para describir luces y sombras
clean color: Estilo entre flat color y flat-pasto. Colores simples y ordenados.
色彩 limpia: Entre flat color y flat-pasto, coloreado simple y ordenado.
celluloid: Coloreado de anime
赛璐璐: coloreado en anime
flat-pasto: Color casi plano, usando gradientes para luces y sombras
Plano-pasto: color casi plano, usa gradientes para luces y sombras
thin-pasto: Contorno fino, usando gradientes y grosor de pintura para luces, sombras y capas
Pastel fino: contorno fino usando gradientes y grosor de pintura para luces, sombras y capas
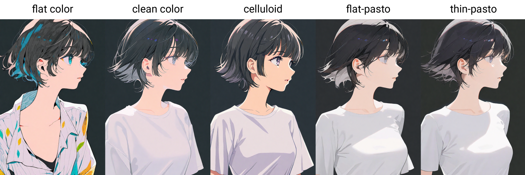
pseudo-impasto: Usa gradientes y grosor de pintura para luces, sombras y capas
Pseu-impasto / semi-impasto: Usa gradientes y grosor de pintura para luces, sombras y capas
impasto: Usa grosor de pintura para luces, sombras y gradaciones
Impasto: Usa grosor de pintura para luces, sombras y gradaciones
realistic
Realista
photorealistic: Redefinido como estilo más cercano al real
Foto-realista: redefinido a estilo cercano al mundo real
cel shading: Estilo de modelado 3D de anime
Cel shading: estilo 3D de anime
3d

Palabras clave estéticas:
beautiful
Hermoso
aesthetic: sentido artístico ligeramente abstracto
Estético: sentido artístico ligeramente abstracto
detailed
Detalle
beautiful color: uso sutil del color
Color armonioso: uso sutil del color
lowres
messy: composición o detalles desordenados
Desordenado: composición o detalles desordenados
Palabras clave de calidad: amazing quality, best quality, high quality, low quality, worst quality




Detalles del Modelo
Tipo de modelo
Modelo base
Versión del modelo
Hash del modelo
Palabras entrenadas
Creador
Discusión
Por favor log in para dejar un comentario.
Colección de Modelos - Anime Illust Diffusion XL


Imágenes por Anime Illust Diffusion XL - v0.5-alpha
Imágenes con anime










Imágenes con modelo base

Imágenes con ilustración









