Old Consistency V32 Lora [FLUX1.D/PDXL] - Feminine v1.1 - e500 PDXL
Palabras Clave y Etiquetas Relacionadas
Imágenes destacadas


Prompts Recomendados
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
Prompts Negativos Recomendados
greyscale, monochrome, multiple views
Parámetros Recomendados
samplers
steps
cfg
clip skip
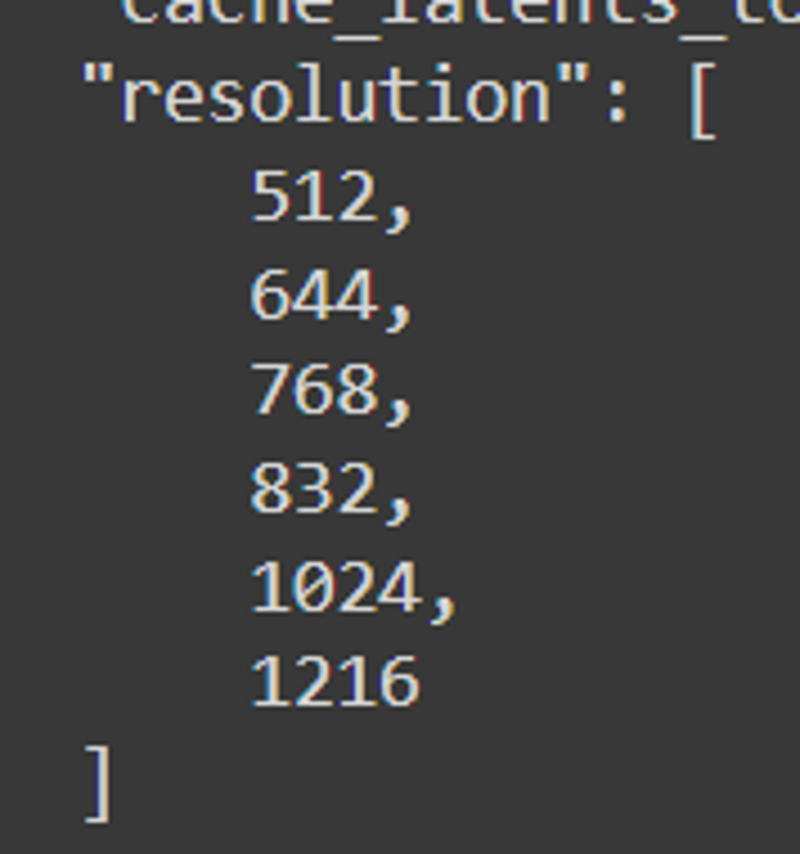
resolution
vae
other models
Parámetros Recomendados de Alta Resolución
upscaler
upscale
denoising strength
Consejos
Usa múltiples loopbacks para mejorar la fidelidad y consistencia de imagen.
Mantén prompts estándar y orden lógico para evitar aberraciones.
Usa etiquetas centrales de pose y ángulo de visión como 'desde frente', 'desde lado', 'desde arriba' para mejorar precisión de poses.
Evita usar poses sexuales hasta que estén debidamente refinadas.
Experimenta con etiquetas de rasgos varios para cabello, ojos, colores de ropa y materiales.
El orden de carga afecta resultados al fusionar con otros modelos y LoRAs.
El modo seguro está activo por defecto con opciones para desbloquear contenido cuestionable y explícito.
Usa el sistema de etiquetas de pose y directiva para mejor control de posición de personaje y ángulos de cámara.
Aspectos Destacados de la Versión
Cheques de estabilidad;
concepto - imágenes/imagenes probadas
cuerpo entero - 48/48
plano medio - 48/48
retrato - 48/48
primer plano - 48/48
**************************************
La próxima iteración tendrá un subconjunto de poses para ojos que induce capas, etiquetado con ángulos de poses además de más imágenes de ojos para variar ángulos y solidificar la superposición. Los colores directos de ojos probablemente no serán necesarios, la forma parece crucial según mi investigación.
ojos rojos - 39/48
cuerpo entero - 6/12
plano medio - 9/12
retrato - 12/12
primer plano - 12/12
ojos azules - 48/48
todas las poses - 12/12
ojos verdes - 48/48
todas las poses -12/12
ojos amarillos - 42/48
cuerpo entero - 6/12 - razón inestable desconocida.
ojos aqua - 48/48
todas las poses
ojos púrpura - 48/48
todas las poses
látex - 36/48
primer plano - 5/12
retrato - 7/12 - requiere imágenes de retrato y primer plano
plano medio - 12/12
cuerpo entero - 12/12
lencería - 36/48
primer plano - 7/12
retrato - 4/12 ? por qué? - requiere retrato directo y prime plano
plano medio - 11/12
cuerpo entero - 12/12
casual - 48/48
todas las poses - 12/12
bikini - 48/48
todas las poses - 12/12
vestido - 16/48
ninguna pose coincidió con vestido correcto a menos que se usaran etiquetas adicionales -> necesidad de etiquetar vestidos más específicamente
La estabilidad de salida es mucho mayor de lo esperado con muchas etiquetas útiles ya implementadas en pony, incluyendo;
<color> cabello
<color> ropa
pecho <tamaño>
<maduro> femenino
<color> aretes
<color> ojos
<borroso> objeto
<área> <fondo>
Hay un montón de etiquetas potencialmente útiles aquí, así que juega con ellas como yo hice.
Éxitos en capas;
ojos rojos -> ojos azules;
[ojos rojos:0.5], [ojos azules:0.5] -> sangrado ocasional, inestable.
ojos rojos, ojos azules -> menos sangrado inconsistente
ojos rojos Y ojos azules -> sangrado consistente, se necesita más investigación
La mayoría de ojos enfrentan problema donde modelo impone demasiado color sobre la forma del ojo, así que el experimento de capas de ojos se pausará y aplicará basado en el experimento de manchas en vez de secuencialmente con este.
vestido -> látex
vestido, abertura lateral, vestido cóctel, látex, traje látex -> forma un atuendo a partir de múltiples partes superpuestas. La consistencia es inestable pero el resultado es prometedor.
látex -> vestido
látex, traje látex, vestido, abertura lateral -> forma un objeto más de vestido, implica superponer huecos de piel vestido más que si usaras vestido primero. Esto implica que el entrenamiento para vestido está sobreajustado, necesita reevaluación.
látex -> bikini
látex, traje látex, bikini, -> forma leggings látex mezclados con bikini, también implica sobreajuste.
Creo tener solución para la superposición de ropa, y con eso la solución para ojos, color piel y más. La mayor consistencia debería venir de difuminados.
Patrocinadores del Creador
Consulta el Modelo Illustrious para capacidades complementarias.
Usa el flujo de trabajo ComfyUI para mejor generación y experimenta con loops.
Explora el potente Modelo Flux como base IA.
Apoya a NovelAI para sinergia superior en historia e imagen.
Créditos a Black Forest Labs por diseñar el modelo Flux.
Mejora la gestión de etiquetas con TagGUI.
Configuración de entrenamiento con AIToolkit.
Inspirado y rival de PonyDiffusion.

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious no es un derivado de PDXL, es diferente y muy bueno. Pruébalo si tienes oportunidad.
Entrené una versión de Simulacrum específicamente para él.
V3-2 en lugar de V3.22:
El objetivo de la v3.22 terminó cambiando y me perdí en el agujero del testeo de flux y la comprensión de nuevos mecanismos. Tras aprender lo suficiente y determinar mi conocimiento sobre cómo fijar sujetos, cómo etiquetar, y cómo flux interpreta la etiquetación; puedo construir una versión 3 adecuada.
Gracias a todos los que soportaron mi ciclo de aprendizaje y experimentación. Ha sido una montaña rusa de pruebas, fallos y algunos verdaderos éxitos. Sé lo que se puede hacer, cómo hacerlo y tengo una metodología para abordar e iterar sobre lo aprendido para crear lo que deseo. El proceso no es perfecto y se seguirá refinando, así que será cuestión de entender y desarrollar iterativamente lo que construya. Tengo suficiente confianza de haber cruzado el primer gran pico del efecto Dunning-Kruger para comenzar a aprender y enseñar información útil tras los experimentos, tratando de procesar y entender la información de forma útil tanto para usuarios básicos como avanzados.
He determinado que mi enfoque original hacia la V4 es viable, pero el proceso que estaba usando no es válido como pensaba originalmente mientras aprendía los sistemas de forma iterativa. Más aspectos aprendidos y más fallos de los cuales aprender para preparar el terreno para futuros éxitos.
Versiones basadas en directrices.
Planeo introducir TRES entrenamientos de directrices centrales por versión y una versión "vanilla nd" singular.
Usaré entrenamientos con directrices muy generales no sólo para el sistema central sino para imágenes temáticas específicas para que todos los aspectos temáticos deseados se reflejen a lo largo del sistema.
La parte técnica del proceso de etiquetado será única y difícil de entender si no se está familiarizado con el motivo de ciertas acciones en el sistema, así que las imágenes y etiquetas probablemente serán muy confusas si buscas detalles específicos.
El sistema sencillo de etiquetado seguirá existiendo por derecho propio y seguirá siendo plenamente capaz de producir los resultados necesarios cuando se requiera.
La versión "nd" o "no directive" para cada lanzamiento garantizará que las diferencias de pruebas y resultados sean similares, como el pájaro en la mina; es hora de irse cuando el pájaro deja de cantar. Seguramente estos modelos hermanos podrán fusionarse y normalizarse para reutilizar y mezclar conceptos que hayan funcionado o no debido a la directriz usada.
La fijación en personajes INDIVIDUALES es ahora el objetivo primordial para este modelo. Solo habrá un personaje fijado y su resolución se ajustará a una proporción descendente y ascendente según los parámetros de formato de entrenamiento correctos de FLUX.
Los problemas de V3.2 fueron menos pronunciados de lo que pensé:
La mayoría de los resultados problemáticos se basaban en información faltante que planeo corregir con el tiempo. Es solo cuestión de desarrollo iterativo.
Dicho esto, la versión entrenada 3.21 está actualmente en pruebas y será lanzada pronto. Tiene mejor capacidad con control de poses y un enfoque centrado en el modelo usando una directriz basada en cámara bastante larga.
El resultado ha mostrado buena compatibilidad con la mayoría de las loras que probé e incluso funciona con algunas loras muy rígidas que no se pueden manipular o rotar con la v32 actual.
Muestra buena compatibilidad con Flux Unchained, múltiples modelos de personajes, modelos faciales, humanos, y demás. La mayoría del sistema no solapa ni rompe otros sistemas hasta ahora, lo cual es bueno.
Problemas de V3.2 a resolver:
Hay problemas de consistencia con algunas poses y ángulos. También existe contaminación cruzada con diversas loras cuando usan etiquetas de lado, desde atrás, desde arriba y desde abajo. Usaré nuevas etiquetas como unidad de verificación y entrenaré un LORA separado para asegurar la fidelidad del control de cámara en el futuro.
Parece funcionar bien mayormente para anime, pero surgen problemas al usar loras.
Etiquetas combinadas para versión 3.21;
Hay algunas pruebas básicas que debo hacer para asegurar que la cámara funcione correctamente según la posición, así que probaré etiquetas como:
un sujeto de vista frontal desde ángulo superior
un sujeto de vista lateral frontal mientras está arriba
un sujeto de vista trasera desde ángulo superior mientras está enfrente
un sujeto de vista lateral desde ángulo superior mientras está atrás
y más etiquetas similares en el flujo base flux_dev, para asegurar que lo que construí posicione correctamente la cámara y la fidelidad de la imagen no se pierda.
Por lo que he visto, el sistema entrena gran profundidad si usas opciones genéricas así. Se necesitan más pruebas para estar seguros.
Etiquetas como "agarrar por atrás", "sexo por atrás", etc., probablemente no cooperen con etiquetas de detrás, así que usaré etiquetas "rear".
"from side", "from behind", "straight-on", "facing the viewer", y cualquier cosa asociada directamente con safebooru, danbooru, gelbooru específicos para personajes o rotaciones de posición no serán entrenadas. Se basará completamente en VER al personaje, en lugar de INTERACTUAR con el personaje.
Tampoco queremos que brazos en POV estén presentes la mayoría del tiempo, por lo que se harán muchas pruebas para asegurar que las etiquetas no generen brazos, piernas, torsos accidentalmente y se fije correctamente en el sujeto individual en cuestión.
Algunas poses, francamente, no funcionaron:
Hay un sistema de combinación de etiquetas que simplemente no cumplió su función, así que se necesitará un nuevo conjunto de combinaciones de etiquetas para controlar personajes correctamente.
Las piernas están deformadas o no existen.
Los brazos pueden estar deformados o mal posicionados.
Faltan los pies.
El torso superior demasiado pronunciado con mucha frecuencia. <<< sobreajustado
El torso inferior no muestra la ropa correctamente.
El cuello no muestra prendas correctas como bufandas, toallas, chokers, cuellos, y más.
Los pezones y genitales son un desastre absoluto. Se necesita una carpeta adecuada con sus variaciones para un controlador NSFW apropiado en este caso.
NAI debería ser ajustado específicamente por estilo y afinado como estilo.
Las opciones de ropa generan tipos de cuerpo más a menudo de lo que deberían.
La clasificación explícita es casi imposible de acceder a veces, otras veces aparece de manera excesiva.
No hay suficientes imágenes cuestionables para ponderar, y el sistema etiquetado explícito también debería incluir la etiqueta cuestionable para asegurar acceso a esa información.
Algunos personajes de anime aparecen con mala perspectiva, lo cual es un problema considerando que el objetivo es perspectiva asociativa correcta.
En cuatro patas funciona bastante bien, pero tiene problemas de perspectiva. No parece tratar personajes anime como 3D con la frecuencia necesaria, así que los entornos alrededor necesitan mejor fidelidad.
Cuatro patas no funciona en una formación sin muchos ajustes.
Arrodillarse no funciona en una formación sin muchos ajustes.
Las formaciones y grupos parecen estar formateados de forma única para flux y esto merece más investigación. Casi como habilitar un bucle interno para cada elemento.
Hubo algunos éxitos:
La fidelidad base no sufrió para la mayoría de las imágenes.
Muchas poses nuevas FUNCIONAN, aunque a veces extrañas.
El estilo anime ha cambiado con un enfoque único de NAI con un toque adicional de realismo.
Se pueden posar múltiples personajes, aunque a veces de forma muy extraña.
Pararse en cualquier ángulo tiene una fidelidad y calidad de imagen absolutamente fantástica con el estilo de NAI.
La V3.3 tendrá que esperar.
Hoja de ruta V3.3:
He actualizado los recursos al final de este documento y ramificado la documentación antigua a un artículo aparte para archivo.
Con el resultado reflejando mejor mi visión, puedo cambiar mi foco al próximo paso en la lista de objetivos; Superposiciones.
La V3.3 introducirá lo que llamo etiquetas con compensación de alfa quemada alta, que facilitarán tareas como hacer cómics, interfaces de juegos, superposiciones, barras de salud, displays, etc.
Teóricamente puedes crear tus propios juegos falsos en consistency si hago una superposición correcta con las quemaduras adecuadas.
Esto sentará las bases para imponer personajes en cualquier posición a cualquier profundidad de una escena, pero eso viene después.
YA puede crear hojas de sprites de forma decente, así que exploraré el sistema de etiquetas integrado en los próximos días para probar estos subsistemas con un poco de esfuerzo en prompts y potencia computacional. Hay alta probabilidad de que esto ya exista y solo sea cuestión de descubrirlo.
Objetivos V4:
Si todo va bien, el sistema completo debería estar listo para producción total incluyendo modificación de imágenes, edición de video, edición 3d y mucho más que aún no comprendo.
v33 superposiciones
Es un poco un nombre engañoso, es más un marco de definición de escena para la próxima estructura.
Esta tarea tomará tanto el mínimo como el máximo tiempo y tengo algunos experimentos que correr con alfa para hacerlo funcionar, pero estoy bastante seguro que la superposición será una opción para mostrar mensajes y controlar escenas debido a cómo funciona la profundidad.
v34 imposición de personajes, planificación de valor de rotación y compensaciones cuidadosas desde el punto de vista:
Asegurar que ciertos personajes existan y sigan directrices es un objetivo primario porque a veces simplemente no lo hacen.
Se implementará un sistema completo basado en valores numéricos de rotación usando pitch/yaw/roll en grados. No será perfecto porque no tengo las habilidades matemáticas ni conjuntos de imágenes ni habilidades de software 3d para hacerlo, pero será un buen comienzo y espero que se integre con lo que FLUX ya ofrece.
v35 controladores de escena
Puntos de interacción complejos en escenas, control de cámara, enfoque, profundidad y más que permitan construir escenas completas junto con los personajes que coloques.
Piénsalo como una versión 3d del controlador de superposición, pero más potente si lo quieres así.
v36 controladores de iluminación
Cambios de iluminación segmentados y controlados por escena que afectarán a todos los personajes, objetos y creaciones contenidos.
Cada luz será colocada y generada según reglas específicas definidas en unreal usando diversos tipos de iluminación, fuentes, colores, etc.
Teóricamente FLUX debería suplir las lagunas.
v37 tipos de cuerpo y personalización
Con la introducción de tipos de cuerpo básicos, quiero introducir creación más compleja de tipos de cuerpo que incluya pero no se limite a:
arreglar poses que no funcionan bien
agregar múltiples poses adicionales
cabello más complejo:
interacción del cabello con objetos, cabello cortado, dañado, descolorido, multicolor, recogido, pelucas, etc.
ojos más complejos:
ojos de varios tipos, abiertos, cerrados, entrecerrados, etc.
expresiones faciales de muchos tipos:
feliz, triste, :o, sin ojos, cara simple, sin rostro, etc.
tipos de orejas:
puntiagudas, redondeadas, sin orejas, etc.
colores de piel variados:
claro, rojo, azul, verde, blanco, gris, plateado, negro, negro azabache, marrón claro, marrón, marrón oscuro y más.
Intentaré evitar temas sensibles aquí porque la gente parece preocuparse mucho por el color de piel, pero realmente quiero muchos colores como en la ropa.
Controladores de tamaño para brazos, piernas, torso superior, cintura, caderas, cuello y cabeza:
bíceps, hombro, codo, muñeca, manos, dedos, etc., con tamaños para longitud, ancho y circunferencia.
clavícula y etiquetas de torso que existan
cintura y etiquetas de cintura que existan
especificaciones de tamaño corporal basado en un gradiente de 1 a 10 en lugar de algún sistema predefinido usado en boorus
v38 atuendos y personalización de atuendos
Casi 200 atuendos más o menos, cada uno con sus parámetros personalizados.
v39 500 personajes de videojuegos, anime y manga recolectados de datos de alta fidelidad
quinientos cig... eh... muchos personajes. Sí. Definitivamente no una gran cantidad de personajes meme sin vínculo racional con diseño o arquetipo.
Luego de eso puedes construir o entrenar cualquier personaje.
gran aumento en fidelidad y calidad:
incluyendo decenas de miles de imágenes de diversas fuentes de anime de alta y muy alta calidad, modelos 3d y semirrealismo fotográfico para superponer y entrenar esta versión finamente ajustada de flux dentro de parámetros estilísticos.
cada imagen será puntuado en fidelidad y etiquetada dentro de una escala de score_1 a score_10 de manera similar a pony, aunque con mi toque único dependiendo de qué tan bien o mal vaya.
Lanzamiento V3.2 - 4000 pasos:
Este no es para niños, definitivamente. Es un modelo base SFW/QUESTIONABLE/NSFW que puede entrenarse para cualquier cosa.
Tampoco está construido para ser un generador de smut, pero puede si se le indica. Es parte del paquete cuando habilitas ciertos comportamientos enseñando cosas a la IA, obtienes carga. Las imágenes están aproximadamente 33% / 33% / 33% actualmente, más o menos. Está ponderado HACIA seguro similar a como funciona NAI.
Vengo de un enfoque firme de habilitar y enseñar información para que el individuo decida qué hacer con ella. Enseñar a una IA sin censura muchas cosas usando un grado bastante controlado y cuidadoso, creo que es saludable para la progresión y crecimiento de la IA hacia una comprensión completa, así como saludable para quienes generan imágenes DESDE la IA sin tener que ver pesadillas 24/7.
Esta cosa muestra una promesa más allá de todo lo que he visto por mucho.
Usa mi carga de trabajo ComfyUI. Está adjunta a todas las imágenes abajo.
Seguridad habilitada por defecto:
cuestionable < desbloquea más rasgos cuestionables aleatorios
explícito < desbloquea cosas divertidas para que aparezcan aleatoriamente
Etiquetas de activación de perspectiva: prueba combinando; desde frente, vista lateral, etc.
desde frente, vista frontal,
desde lado, vista lateral,
desde atrás, vista trasera,
desde arriba, vista superior,
desde abajo, vista inferior,
Poses principales añadidas y mejoradas:
en cuatro patas
arrodillado
en cuclillas
de pie
inclinado
apoyado
acostado
al revés
boca abajo
boca arriba
colocación de brazos
colocación de piernas
inclinación de cabeza
dirección de cabeza
dirección de los ojos
posición de ojos
solidez color ojos
solidez color cabello
tamaño de pecho
tamaño de trasero
tamaño de cintura
variedad de opciones de ropa
variedad de opciones de personaje
variedad de expresiones faciales
poses sexuales aún en desarrollo y recomiendo evitar usarlas hasta que estén pulidas. Están MUY fuera de mi alcance y no tengo la capacidad mental ahora mismo para decidir el rumbo.
El creador de poses, generador de ángulos, configurador de situaciones, impone conceptos y estructura de interpolación está listo y entrenaré más versiones.
Disfruten.
Hoja de ruta V3.2:
25/8/2024 5:16 - He identificado que el proceso ha funcionado y el sistema es funcional a un alto grado más allá de expectativas. La IA ha desarrollado comportamientos emergentes que han posado personajes de manera exponencialmente más potente de lo esperado. Comienzan las pruebas y el resultado se ve fantástico.
Resoluciones finales: 512, 640, 768, 832, 1024, 1216
25/8/2024 15:00 - Todo está correctamente etiquetado y las poses preparadas. El entrenamiento real comienza ahora, e involucrará pruebas múltiples de dimensiones, conteos de lr, chequeo de pasos y más para evaluar al candidato correcto para el lanzamiento v32.
25/8/2024 4:00 - La primera versión de v32 mostró deformidades mínimas alrededor del paso 1400 y deformidades graves alrededor del paso 2200, lo que significa que el etiquetado perezoso WD14 no funcionó. Se viene etiquetado manual. Va a ser una mañana divertida.
24/8/2024 por la tarde - Está cocinándose ahora.
 Sospecho que esta no funcionará. Automatizé las etiquetas y eliminé los ángulos de pose por ahora. Voy a ver qué puede hacer wd14 solo. Tras el entrenamiento exitoso o fallido, restauraré los ángulos de pose originales y el orden establecido de etiquetas. Veamos cómo funciona ahora que todos los datos intencionados están agrupados y los casos de uso son densos.
Sospecho que esta no funcionará. Automatizé las etiquetas y eliminé los ángulos de pose por ahora. Voy a ver qué puede hacer wd14 solo. Tras el entrenamiento exitoso o fallido, restauraré los ángulos de pose originales y el orden establecido de etiquetas. Veamos cómo funciona ahora que todos los datos intencionados están agrupados y los casos de uso son densos.Con 4000 imágenes sospecho que tomará tiempo cachear los latentes, pero con la atención puesta en los "dolls" y cuerpos de casos de uso específicos, debería salir bien al menos.
24/8/2024 al mediodía -
 Seguimos avanzando.
Seguimos avanzando. Todo está formateado para tener fondos con implicación de sombra, lo que ayuda a flux a generar imágenes basadas en superficies y ubicaciones. Todo está construido para posicionar basado en poses faltantes que flux no puede manejar. Todo está construido para fijarse en sujetos que pueden superponerse multiplicativamente en múltiples ubicaciones.
Todo está formateado para tener fondos con implicación de sombra, lo que ayuda a flux a generar imágenes basadas en superficies y ubicaciones. Todo está construido para posicionar basado en poses faltantes que flux no puede manejar. Todo está construido para fijarse en sujetos que pueden superponerse multiplicativamente en múltiples ubicaciones.He estado enfocándome en la colocación correcta de brazos y asegurar que los brazos etiquetados que se superponen formen brazos de punto A a B.
24/8/2024 por la mañana - Hay algunos problemas con los brazos también, pero está bien, lo añadiré a la lista. Gracias por señalar esto, hay contaminación cruzada que debe atenderse. Uso un sistema específico de retroalimentación loopback en comfyui que no está presente en el sistema del sitio web, así que podría deshabilitar la generación en sitio para esta versión.
 23/8/2024 - Ya tengo cerca de 340 imágenes anime nuevas de alto detalle con poses casi uniformes, identificadores pitch/yaw/roll para asegurar solidez, cambios de color, diferenciación de tamaño con pechos, cabello y trasero. Faltan 554 más. V3.2 estará dedicada fuertemente a anime, luego planeo usar pony para producir realismo sintético suficiente para crear los elementos necesarios de realismo también. A menos que flux lo permita tras el entrenamiento, en cuyo caso usaré flux.
23/8/2024 - Ya tengo cerca de 340 imágenes anime nuevas de alto detalle con poses casi uniformes, identificadores pitch/yaw/roll para asegurar solidez, cambios de color, diferenciación de tamaño con pechos, cabello y trasero. Faltan 554 más. V3.2 estará dedicada fuertemente a anime, luego planeo usar pony para producir realismo sintético suficiente para crear los elementos necesarios de realismo también. A menos que flux lo permita tras el entrenamiento, en cuyo caso usaré flux. Esto DEBERÍA asegurar la fidelidad y separación por clasificación pose a pose, especialmente porque tengo una metodología nueva usando palabras clave from y view. Teóricamente debería funcionar casi idéntico al control de poses de NovelAI cuando termine, que básicamente es mi objetivo. La diferenciación de personajes es otra historia por supuesto.
Esto DEBERÍA asegurar la fidelidad y separación por clasificación pose a pose, especialmente porque tengo una metodología nueva usando palabras clave from y view. Teóricamente debería funcionar casi idéntico al control de poses de NovelAI cuando termine, que básicamente es mi objetivo. La diferenciación de personajes es otra historia por supuesto.Todo debe estar perfectamente ordenado y alineado, o no agregará el contexto necesario a las tasas necesarias para afectar el modelo base lo suficiente para ser útil.
Por diseño, SAFE será el predeterminado, así que todo el sistema estará ponderado hacia lo seguro, con capacidad para habilitar NSFW.
Entrenaré múltiples iteraciones de este LORA en particular para asegurar que la diferencia entre ambos pueda mantenerse estricta, aún permitiendo que la versión más NSFW entretenga al público correspondiente.
Espero que, cuando esto esté entrenado, pueda cargar un conjunto seleccionado de 50,000 imágenes en el sistema y cree algo mágico. Algo potencialmente al mismo nivel de poder que pony para cualquier cosa que el corazón desee. Luego podré descansar sabiendo que el universo está agradecido. Después podrán cargar lo que quieran y hará lo que deseen gracias al poder innato de flux con la columna vertebral de consistency.
Planeo liberar los datos de entrenamiento para el conjunto inicial completo de imágenes de consistency v3.2 cuando esté organizado, entrenado, probado y listo. Liberaré los datos v3 este fin de semana cuando tenga tiempo.
He identificado consistencias problemáticas, principalmente con la palabra clave lying combinada con las de ángulo. Probaré cada combinación y corregiré la consistencia antes de pasar a la siguiente fase; elecciones base de atuendo, cambios de atuendo y derivados basados en poses que sí y no funcionan. También necesito incluir más información detallada para elementos cuestionables y NSFW después. Pueden adivinar qué son tras la siguiente versión.
Hasta entonces, necesito asegurar que las poses funcionen según las directrices, así que crearé nuevas palabras clave combinadas intencionales, aumentaré el conteo de imágenes por pose y ángulo y crearé datos que funcionen como marcadores para situaciones e imágenes más complejas. También incluiré etiquetas "base" que asignarán ciertas cosas por defecto cuando fallen otras para ayudar con la consistencia.
Documentación V3:
Probado principalmente en FLUX.1 Dev e4m3fn con fp8, por lo que la fusión del checkpoint reflejará este valor cuando la subida esté completa. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
Funciona con el modelo base FLUX.1 Dev, pero también en otros modelos, merges y loras. Los resultados serán mixtos. Experimenta con el orden de carga, ya que los valores del modelo cambian en secuencia y grados diversos.
Esto es nada menos que la columna vertebral de FLUX. Potencia etiquetas útiles muy similares a danbooru para establecer control y asistencias de cámara que facilitan hacer personajes muy personalizables en situaciones que FLUX probablemente PUEDE HACER, pero requiere más esfuerzo por defecto.
Sugiero usar un sistema de múltiples loopbacks para asegurar la fidelidad de imagen. Consistency mejora estabilidad y calidad con iteraciones.
Esto está MUY enfocado en individuos. Sin embargo, debido a cómo estructuré las resoluciones, puede manejar MUCHAS personas en situaciones similares. Las loras que causan cambios inmediatos sin contexto suelen ser inútiles porque no contribuyen al contexto. Las loras más específicas para añadir RASGOS a personas o crear interacciones contextuales funcionan bien. La ropa funciona, tipos de cabello funcionan, control de género funciona. La mayoría de las loras que probé funcionan, aunque algunas no hacen nada.
Esto no es un merge ni una combinación de loras. Este lora fue creado usando datos sintéticos generados por NAI y AutismPDXL durante un año. El conjunto de imágenes es complejo y las imágenes elegidas para crear esto no fueron fáciles de seleccionar. Tomó mucho ensayo y error. Muchísimo.
Se introduce una SERIE de etiquetas centrales con este lora. Añade una columna vertebral entera a FLUX que por defecto no tiene. El patrón de activación es complejo, pero si construyes tu personaje similar a NAI, parecerá similar a cómo NAI crea personajes.
El potencial y poder de este modelo no deben subestimarse. Es una potencia absoluta y su potencial escapa a mi alcance.
Aun así puede producir aberraciones si no tienes cuidado. Si usas prompts estándar y orden lógico, deberías crear arte hermoso en breve.
Resoluciones: 512, 768, 816, 1024, 1216
Pasos sugeridos: 16
Guía FLUX: 4 o 3-5 si tiene resistencia, 15+ si es muy resistente
CFG: 1
Lo usé con 2 loopbacks. El primero con upscale 1.05x y denoise entre 0.72-0.88, y el segundo denoise 0.8 casi nunca cambiado, dependiendo de cuántos rasgos quiera añadir o eliminar.
CONJUNTO DE ETIQUETAS CENTRALES:
anime - convierte el estilo de poses, personajes, atuendos, caras, etc. a anime
realista - convierte el estilo a realista
desde frente - vista frontal de una persona, con hombros alineados mirando hacia el espectador, donde la masa central del torso enfrenta al espectador.
desde lado - vista lateral de una persona, hombro vertical frente al espectador, donde los hombros están verticales significando que el personaje está de lado.
desde atrás - vista directamente trasera de la persona
directo - vista vertical recta, pensada para ángulo horizontal plano
desde arriba - inclinación de 45 a 90 grados mirando hacia abajo a un individuo
desde abajo - inclinación de 45 a 90 grados mirando hacia arriba a un individuo
cara - imagen enfocada en detalles faciales, buena para incluir detalles cuando son difíciles
cuerpo entero - vista completa de un individuo, bueno para poses complejas
cowboy shot - etiqueta estándar de plano medio, funciona bien en anime, no tanto en realismo
mirando al espectador, mirando a un lado, mirando hacia adelante
de lado, mirando al espectador, de espaldas
mirando atrás, mirando adelante
las etiquetas mixtas crean resultados mixtos, pero con resultados variados
desde lado, directo - cámara horizontal apuntando al lado de un individuo o individuos
desde frente, desde arriba - inclinación 45 grados descendente desde cámara frontal superior
desde lado, desde arriba - inclinación 45 grados descendente desde cámara lateral superior
desde atrás, desde arriba - inclinación 45 grados descendente desde cámara trasera superior
desde frente, desde abajo
desde frente, desde arriba
desde frente, directo
desde frente, desde lado, desde arriba
desde frente, desde lado, desde abajo
desde frente, desde lado, directo
desde atrás, desde lado, desde arriba
desde atrás, desde lado, desde abajo
desde atrás, desde lado, directo
desde lado, desde atrás, desde arriba
desde lado, desde atrás, desde abajo
desde lado, desde atrás, directo
Estas etiquetas pueden parecer similares, pero el orden crea resultados diferentes. Usar "desde atrás" antes de "desde lado" hará que el sistema estime más "trasera" que "lado", pero usualmente verás torsos torsionados y cuerpo girado 45 grados a cada lado.
El resultado es mixto, pero definitivamente viable.
rasgos, colores, ropa, etc. también funcionan
cabello rojo, cabello azul, cabello verde, cabello blanco, cabello negro, cabello dorado, cabello plateado, cabello rubio, cabello castaño, cabello púrpura, cabello rosa, cabello aqua
ojos rojos, ojos azules, ojos verdes, ojos blancos, ojos negros, ojos dorados, ojos plateados, ojos amarillos, ojos marrones, ojos púrpura, ojos rosas, ojos aqua
traje de látex rojo, traje de látex azul, traje de látex verde, traje de látex negro, traje de látex blanco, traje de látex dorado, traje de látex plateado, traje de látex amarillo, traje de látex marrón, traje de látex púrpura
bikini rojo, bikini azul, bikini verde, bikini negro, bikini blanco, bikini amarillo, bikini marrón, bikini púrpura, bikini rosa
vestido rojo, vestido azul, vestido verde, vestido negro, vestido blanco, vestido amarillo, vestido marrón, vestido rosa, vestido púrpura
faldas, camisas, vestidos, collares, atuendos completos
varios materiales; látex, metálico, denim, algodón, etc.
las poses pueden o no funcionar con la cámara, puede requerir ajustes
en cuatro patas
arrodillado
acostado
acostado, boca arriba
acostado, de lado
acostado, al revés
arrodillado, desde atrás
arrodillado, desde frente
arrodillado, de lado
en cuclillas
en cuclillas, desde atrás
en cuclillas, desde frente
en cuclillas, de lado
controlar piernas y demás puede ser muy detallista, así que experimenta un poco
piernas
piernas juntas
piernas separadas
piernas abiertas
pies juntos
pies separados
cientos de otras etiquetas usadas e incluidas, millones de combinaciones posibles
Úsalas antes de cualquier especificador de rasgos de persona, pero después del prompt para flux mismo.
ENVÍO DE PROMPTS:
Sólo hazlo. Escribe lo que quieras y ve qué pasa. FLUX ya tiene mucha información, así que usa las poses y demás para mejorar tus imágenes.
Ejemplo:
una mujer sentada en una silla en una cocina, desde lado, desde arriba, plano medio, 1 chica, sentada, desde lado, cabello azul, ojos verdes

una mujer superhéroe volando en el cielo lanzando una roca, tiene un aura poderosa, brillante y amenazante, realista, 1 chica, desde abajo, traje de látex azul, choker negro, uñas negras, labios negros, ojos negros, cabello púrpura
 una mujer comiendo en un restaurante, desde arriba, desde atrás, en cuatro patas, trasero, tanga
una mujer comiendo en un restaurante, desde arriba, desde atrás, en cuatro patas, trasero, tanga Sí funcionó. Usualmente sí.
Sí funcionó. Usualmente sí.
Legítimamente, esto debería manejar la mayoría de locuras, aunque definitivamente va más allá de mi comprensión. Intenté mitigar el caos e incluir suficientes etiquetas de poses para que funcione, así que trata de usar las más esenciales y útiles.
Más de 430 intentos fallidos para crear esto finalmente llevaron a una serie de teorías exitosas. Haré un informe completo de la información necesaria y seguramente liberar los datos usados para el entrenamiento este fin de semana. Fue un proceso largo y difícil. Espero que lo disfruten todos.
Documentación V2:
Anoche estaba muy cansado, así que no terminé de compilar todo el informe y hallazgos. Esperen pronto, probablemente durante el día mientras trabajo haga pruebas y marque valores.
Introducción al entrenamiento Flux:
Antes, PDXL solo requería pocas imágenes con etiquetas danbooru para producir resultados finos comparables a NAI. Menos imágenes era una ventaja porque reducía potencial, en este caso menos imágenes no funcionó. Necesitaba algo más. Con más potencia.
El modelo tiene mucho, pero la diferencia entre los datos aprendidos es mayor de lo esperado. Más varianza implica más potencial, y no entendía por qué funcionaba con tanta varianza.
Tras investigar encontré que el modelo es tan poderoso POR ESTO. Puede producir imágenes “DIRIGIDAS” basadas en profundidad, donde la imagen está segmentada y superpuesta sobre otra usando el ruido de esa otra imagen como guía. Pensé, cómo entrenar >>ESTO<< sin dañar detalles centrales. Pensé en redimensionar, luego recordé el bucketing. Esto es la primera pieza.
Entré en esto a ciegas, configurando basado en sugerencias y evaluando según lo que veía. Es lento, he leído papers a la par para acelerar. Quería correr 50 entrenamientos simultáneos, pero no tengo tiempo. Podría pagarlo pero no sé cómo configurarlo.
Elegí lo que creí mejor formato basándome en experiencia con SD1.5, SDXL y entrenamientos PDXL lora. Salió BIEN, pero hay algo mal claro en esto, les contaré luego.
Formato de entrenamiento:
Corrí algunas pruebas.
Prueba 1 - 750 imágenes aleatorias de mi muestra danbooru:
UNET LR - 4e-4
La mayoría de los otros elementos poco importaban y se dejaron por defecto, excepto atención a resolución y bucketing.
Solo 1024x1024, recorte central
Entre 2k-12k pasos
Escogí 750 imágenes aleatoriamente de un conjunto de etiquetas danbooru asegurando uniformidad.
Usé moat tagger para añadir etiquetas al archivo sin sobrescribir.
El resultado no fue prometedor. El caos era esperado. Introducción de elementos humanos nuevos como genitales fue irregular o inexistente. Coincide con hallazgos de otros.
No esperaba que el modelo sufriera, pues las etiquetas casi no se superponían pensaba.
Hice la prueba dos veces y tengo dos loras inútiles con 12k pasos cada una. Probar pasos 1k-8k mostró casi nada útil hacia objetivos, incluso con atención al pico y curva de etiquetas.
Hay algo más. Algo que me perdí, no es humano o clip. Es más.
Descubrí que este sistema de profundidad es interpolativo y depende de dos prompts diferentes y divergentes. Estos dos prompts son interpolativos y cooperativos. Cómo determina esto es desconocido, leeré papers para entender la matemática.
Prueba 2 - 10 imágenes:
UNET LR - 0.001 <<< LR muy potente
256x256, 512x512, 768x768, 1024x1024
Los pasos iniciales mostraban desviación, similar al impacto en pruebas SD3. No fue bueno. La mezcla comenzó en paso ~500. Básicamente inútil en paso 1000. Seguro repetí, pero fue buen experimento para fallar.
Las desviaciones son muy dañinas. Introduce un nuevo contexto y luego lo convierte en artefactos inútiles o quemados similares a mal inpainting. Sorprende la resiliencia y capacidad de FLUX para resistir.
Fue un fracaso, se requieren más pruebas con ajustes diferentes.
Prueba 3 - 500 imágenes de poses:
UNET LR - 4e-4 <<< debería dividirse por 4 y dar doble de pasos.
Bucketing completo - 256x256, 256x316, etc. Dejé hacerlo libre con muchas imágenes y tamaños. El resultado fue inesperado.
El resultado es literal el núcleo de este modelo de consistencia, muestra el potencial verdadero. Hizo algo más de daño del esperado, pero fue importante.
Nota: Anime usualmente no usa profundidad de campo. Este modelo parece prosperar con profundidad de campo y desenfoque para diferenciar profundidad. Necesita un control de profundidad tipo controlnet en estas imágenes para variar profundidad, no tengo idea cómo hacerlo ahora. Mapas de profundidad junto con normales podría funcionar o destruir el modelo por falta de prompting negativo.
Se necesitan más pruebas y datos de entrenamiento adicionales.
Prueba 4 - paquete de consistencia de 5000:
UNET LR - 4e-4 <<< debería dividirse por 40 y dar 20 veces más pasos, dar o recibir. Entrenar algo así no es simple ni rápido, la matemática no es buena para preservar el modelo central. Corrí esta prueba y publiqué hallazgos iniciales.
Había escrito sección entera aquí y seguida e iba a mis hallazgos pero accidentalmente borré todo, reescribiré luego.
Los grandes fracasos:
La tasa de aprendizaje fue DEMASIADO ALTA para mis loras iniciales de 12k pasos. El sistema usa aprendizaje por gradiente, pero la tasa a la que entrené fue DEMASIADO ALTA para retener información sin romper el modelo. Simplificando, no los quemé, reentrené el modelo para hacer lo que quería. El problema es que no sabía qué quería, así que el sistema se basó en cosas no dirigidas y sin profundidad de gradiente. Estaba destinado a fallar, con pasos extra o no.
El ESTILO para FLUX no es lo que la gente cree basado en PDXL y SD1.5. El sistema de gradiente estilizará cosas sí, pero la estructura entera sufre mucho cuando intentas imponer DEMASIADA información rápido. Es MUY destructivo, en comparación con loras PDXL que eran más imposición y aumentaban lo existente en lugar de entrenar información nueva desde cero.
Hallazgos críticos:
ALFA, ALFA y MÁS ALFA<<<< Este sistema depende mucho de gradientes alfa, es fundamental. Todo debe manejar explícitamente gradientes alfa basados en detalles fotográficos. Distancia, profundidad, proporción, rotación, compensación, etc. son claves para la composición y para crear estilizadores compuestos el sistema los necesita en más de un prompt.
Todo debe describirse correctamente. Simple etiquetado danbooru es solo estilo. Forzar el sistema a reconocer tu estilo deseado no es suficiente, debes incluir etiquetas de concepto necesarias. Si no, enlace de estilo y concepto falla y obtienes basura. Basura entra, basura sale.
Entrenamiento de poses es MUY potente con gran cantidad de información de poses. El sistema ya reconoce la mayoría de etiquetas, solo no sabemos qué reconoce exactamente. Entrenar pose para conectar lo que está con lo que quieres usando etiquetas específicas será potente para organización y afinación.
Documentación de pasos;
v2 - 5572 imágenes -> 92 poses -> 4000 pasos FLUX
El objetivo original de llevar NAI a SDXL también se aplica a FLUX. Habrá más versiones.
Se requieren pruebas de estabilidad, hasta ahora se muestra muy capaz más allá de PDXL. Necesita más entrenamiento pero es más potente de lo esperado a bajos pasos.
Creo que la primera capa de entrenamiento de poses usa unas 500 imágenes más o menos, así que eso debería tener impacto fuerte. El conjunto completo se liberará en HuggingFace cuando tenga los datos organizados. No quiero liberar imágenes erróneas o basura.
Continúa leyendo aquí:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
Referencias importantes:
No fumo, pero FLUX lo necesita ocasionalmente.
Un asistente de flujos de trabajo y generación de imagen. Uso principalmente nodos de ComfyUI core, pero continuo experimentando y guardando con otros.
Un modelo IA muy potente y difícil de entender con tremendo potencial.
Sin ellos, nunca habría creado esto. Gracias al staff de NAI por su esfuerzo y poderosísima IA generadora de imagen y su asistente de escritura. Apóyenlos.
Creadores de flux, merecen gran parte del crédito por la flexibilidad del modelo. Solo ajusto y dirijo este leviatán a su destino.
Un potente asistente de etiquetas. Casi escribí el mío propio hasta encontrar este.
Lo que usé para entrenar mis versiones de Flux. Un poco delicado pero funciona bien en varios sistemas.
No olvidar al rival en el campo. Este monstruo genera imágenes en alto gradiente, es invaluable para investigación y gran inspiración.

Detalles del Modelo
Tipo de modelo
Modelo base
Versión del modelo
Hash del modelo
Creador
Discusión
Por favor log in para dejar un comentario.
![Old Consistency V32 Lora [FLUX1.D/PDXL] Feminine v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































