Colossus Project Flux - v10_int4_SVDQ
Parole Chiave e Tag Correlati
Immagini in evidenza

Prompt Negativi Consigliati
blurry
Parametri Consigliati
samplers
steps
cfg
resolution
vae
Suggerimenti
Usa prompt negativi con la parola 'blurry' per migliorare la qualità dell'output.
Per le versioni FP4, usa solo schede grafiche Nvidia serie 50xx; le versioni int4 supportano 40xx e inferiori (minimo serie 20xx).
I modelli 'All in One' contengono Clip_l, T5xxl e VAE integrati per semplificare l'uso.
Prova vari sampler come Euler, Heun, DPM++2M, deis, DDIM; scheduler consigliato 'Simple'.
Sperimenta con la scala di guida (cfg) da 1.5 a 3, con default intorno a 2.2-2.3 per i migliori risultati.
La versione FP8 offre un buon equilibrio tra qualità e prestazioni.
Per versioni speciali ‘de-distilled’, disabilita la scala Flux Guidance e usa solo cfg.
Se compaiono artefatti, prova un piccolo upscaling (es. 1.14x invece di 1.2x) per mitigare i problemi.
Workflow e guide dettagliate sono forniti tramite link ad articoli Civitai.
Punti Salienti della Versione
Versione V10_int4_SVDQ "Nunchaku"
Installazione: visita la mia guida workflow/installazione: https://civitai.com/articles/15610
Prima voglio ringraziare theunlikely https://huggingface.co/theunlikely che ha convertito FP16_Unet in int4_SVDQ. Visita la sua pagina e lascia un like.
Questa versione è più o meno uguale alla versione FP8. Anche in modalità normale nel mio workflow questa è circa 2X-3X più veloce del modello regolare.. Con la "modalità veloce" del workflow posso generare un'immagine 2MP in circa 19 secondi con la mia 3090ti.
Cos'è SVDQ "Nunchaku"?
Questo nuovo metodo di quantizzazione permette di ridurre i modelli Flux (in questo caso un modello nativo FP16) da 24GB a circa 6.7GB. Ma non è tutto: puoi eseguire generazioni più velocemente che mai senza perdere troppa qualità. Sicuramente noterai una piccola differenza rispetto al mio 32GB_Behemoth, ma per questo modello avrai bisogno di molta più VRAM/RAM per farlo girare.
Per maggiori informazioni visita: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Sponsor del Creatore
Supporta il creatore su Ko-Fi: https://ko-fi.com/afroman4peace
Scarica modelli quantizzati di Muyang Li da Nunchakutech: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
Guide workflow su Civitai:
https://civitai.com/articles/17313
https://civitai.com/articles/17358
https://civitai.com/articles/17163
https://civitai.com/articles/15610
https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
https://civitai.com/articles/8419
https://civitai.com/articles/7946
GitHub per la quantizzazione Nunchaku SVDQ: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
In profondità sotto una montagna vive un gigante addormentato, capace di aiutare l'umanità o di creare distruzione...
Un Colosso si risveglia...
Dopo la serie SDXL è il momento della serie FLUX di questo progetto... Questa volta ho addestrato tutto da zero. Per l'addestramento ho usato le mie immagini. Le ho create con il mio modello schnell Flux DemonFlux/Colossus Project schnell + il mio SDXL Colossus Project 12 come raffinatore.
Questo SD Flux-Checkpoint è capace di produrre quasi tutto.. Colossus è molto bravo a creare immagini estremamente realistiche, anime e arte.
Se ti piace, sentiti libero di lasciarmi un feedback. Inoltre, se vuoi supportarmi puoi farlo qui. Ho speso un bel po' di soldi per costruire un computer in grado di addestrare modelli Flux.. L'addestramento e i test richiedono anche molto tempo e elettricità..
https://ko-fi.com/afroman4peace
Versione V12 "Hephaistos"
Pubblicare questo checkpoint mi rende felice e triste allo stesso tempo.. V12 sarà l'ultimo checkpoint di questa serie.. La ragione principale sono le imminenti leggi UE sull'IA... Un'altra ragione è la licenza di Flux .1 DEV stesso. Grazie a tutti per il supporto! Ho dedicato molto tempo a questo progetto nell'ultimo anno. Ora è tempo di passare a un progetto diverso.
Comunque.. concluderò questa serie con una nota alta...
V12 si basa su V10B "BOB" ma ha fondamentalmente le migliori parti di questa serie fuse in un singolo checkpoint. (È stato il risultato di un nuovo metodo di merge che ha richiesto circa 1:30h e ha usato tutta la mia RAM da 128GB). Ho anche migliorato le texture del volto e della pelle rispetto a V10. Gli occhi sono molto più realistici e più "vivi" di prima.
Provalo tu stesso e dammi un feedback su V12. "Grazie" alla mia lenta connessione internet caricherò prima il FP8_UNET, poi la versione FP8 "all in one" e infine FP16_unet e FP16_BEHEMOTH. Cercherò anche di convertirlo in int4 e fp4 (augurami buona fortuna).
Come sempre, dammi un feedback su V12..
Versione V12 "Behemoth" (AIO)
Questo modello "all in one" è il meglio della mia serie V12.. e ovviamente il più grande in dimensioni :-)
Il Behemoth ha un T5xxl custom e Clip_l integrati nel modello. Se preferisci qualità alla quantità questo è il checkpoint per te!
Versione V12 FP4/int4
Grazie a Muyang Li di Nunchakutech che ha fatto la quantizzazione di V12. https://huggingface.co/nunchaku-tech e ai loro incredibili nunchaku!
Questa versione è davvero sorprendente. Combina qualità con velocità mai viste prima.
ATTENZIONE!
Ci sono due versioni FP4 e int4. FP4 è solo per schede grafiche Nvidia serie 50xx! Mentre int4 funziona con 40xx e inferiori. (serve almeno una scheda grafica della serie 20xx)
Puoi anche scaricare entrambe le versioni direttamente qui: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
GUIDA ALL'INSTALLAZIONE e WORKFLOW
Ecco una guida rapida all'installazione e un workflow in WIP.
https://civitai.com/articles/17313
GUIDA DETTAGLIATA per il workflow
https://civitai.com/articles/17358
Sto ancora lavorando ai miei nuovi workflow per Nunchaku.. quindi questo workflow è ancora molto WIP (work in progress). Aggiungerò un articolo dettagliato nel weekend.
Versione V12 Variante FP16_B
Per un piccolo errore fatto a tarda notte (2AM) ho rinominato e caricato il checkpoint "sbagliato". È un checkpoint molto sperimentale mai destinato a essere pubblicato. Non è molto testato ma ha avuto ottime prestazioni quando ho creato la demo. Potrebbe essere migliore della versione standard.
Predilige volti asiatici.. Questo perché volevo testare qualcosa da mixare in un progetto secondario su cui sto ancora lavorando. Dimmi la tua esperienza con questo checkpoint :-)
Versione V12 AIO FP8
Questa versione è una versione all in one di V12. Questo significa che tutti i clip sono integrati. Fornirà lo stesso output della FP8_unet con il mio clip_l custom
Versione V12 GGUF Q5_1
Questa versione è stata richiesta. La qualità non è male..
Versione V10B "BOB"
Questa è una versione alternativa di V10. L'ho creata per migliorare la versione FP8 di V10. In generale la versione FP8 è più precisa e i colori sono migliori. Purtroppo ultimamente ho poco tempo.. (la vita reale viene prima). Per questo ci è voluto molto tempo.. Fammi sapere se preferisci questa versione. Ho anche una versione FP16 di "BOB". A seconda del feedback potrei considerare di pubblicare una versione int4.
WORKFLOW:
Ecco il workflow per V12 e V10: https://civitai.com/articles/17163
Versione V10_int4_SVDQ "Nunchaku"
Prima voglio ringraziare theunlikely https://huggingface.co/theunlikely che ha convertito FP16_Unet in int4_SVDQ. Visita la sua pagina e lascia un like.
Questa versione è più o meno uguale alla versione FP8. Anche in modalità normale nel mio workflow questa è circa 2X-3X più veloce del modello regolare.. Con la "modalità veloce" del workflow posso generare un'immagine 2MP in circa 19 secondi con la mia 3090ti.
Cos'è SVDQ "Nunchaku"?
Questo nuovo metodo di quantizzazione permette di ridurre i modelli Flux (in questo caso un modello nativo FP16) da 24GB a circa 6.7GB. Ma non è tutto: puoi eseguire generazioni più velocemente che mai senza perdere troppa qualità. Sicuramente noterai una piccola differenza rispetto al mio 32GB_Behemoth, ma per questo modello avrai bisogno di molta più VRAM/RAM per farlo girare.
Per maggiori informazioni visita: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Installazione: visita la mia guida workflow/installazione: https://civitai.com/articles/15610
Versione V10 "Behemoth" (FP16_AIO)
Questa versione è ancora sperimentale. L'obiettivo principale era ottenere risultati più realistici. Sono anche riuscito a ridurre alcune "linee Flux". Questo modello si basa su Colossus Project V5.0_Behemoth, V9.0 e un altro progetto chiamato "Ouroborus Project"
La versione FP16 è molto stabile. Sto anche preparando una versione FP8. Questa è molto buona ma meno stabile..
Ti lascio sperimentare con questa versione.. Dimmi cosa ne pensi.
Divertiti a crearla :-)
Versione V9.0:
Devo spiegare molto.. Prima perché è V9.0?
Mi sono recentemente trasferito in un nuovo appartamento e a causa di errori del provider internet non avevo una vera connessione.. Così durante il trasloco ho lasciato il computer acceso. Il risultato è stato la creazione di molti checkpoint (molti rotti). Ho comunque alcune ottime versioni V8 che potrei pubblicare.
Cosa è cambiato?
Ho addestrato nuovi volti e texture della pelle prendendo soprattutto i migliori risultati di V5.0. Inoltre il modello ha un training su piedi/gambe per una migliore anatomia. Le versioni V5.0 a volte tagliavano testa e piedi.. credo di aver risolto alcuni di questi problemi..
In aggiunta ho addestrato con più delle mie immagini di paesaggi.. E sì, l'ho fatto tutto durante il trasloco... Penso che il tempo totale di addestramento sia stato circa 2 settimane di calcolo, che non è proprio economico.. (ogni ora mi costa circa 25 cent di elettricità)
Comunque spero che questa versione ti piaccia.. Se vuoi supportarmi: pubblica belle immagini/ o magari tipami con buzz o su Ko-fi..
Dimmi cosa ne pensi :-)
Versione 5.0:
La V5.0 si basa in realtà su V4.2 e V4.4 (che sarà pubblicata presto). Ha un addestramento aggiuntivo su dettagli della pelle e anatomia generale che ha per lo più sistemato parti come mani e capezzoli. I dettagli del volto sono molto migliori. Ho anche cercato di correggere alcune piccole linee Flux..
In generale questa versione è più realistica di V4.2 e migliore nei dettagli più piccoli.. Come la versione 4.2 anche questa è un modello ibrido de-distilled. Puoi usarlo con le stesse impostazioni di V4.2.
Ecco un nuovo Workflow da provare: https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Dimmi cosa ne pensi rispetto a 4.2 o V2.1..
Versione 4.4 "Research":
Ho aggiunto questa versione solo per completezza.. È leggermente più realistica di V4.2 e la base di V5.0. Puoi provarla se vuoi. Puoi anche usare il workflow per V5.0 e V4.2..
Versione 4.2:
Questa versione è sostanzialmente uno sviluppo ulteriore di Demoncore Flux e Colossus Project Flux. L'obiettivo era ottenere un risultato più stabile, con texture della pelle migliori, mani più curate e una maggiore varietà di volti. Così l'ho addestrato su un modello ibrido in parte Demoncore Flux. Ho anche migliorato un po' capezzoli e NSFW. Dimmi se preferisci V4.2 rispetto alla versione 2.1 :-)
Per le immagini showcase: ho usato solo immagini native con risoluzione SDXL o 2MP (es. 1216x1632). Questo modello può gestire anche risoluzioni più alte.. Ho testato questo checkpoint fino a 2500x2500 ma consiglio di stare intorno a 2000x2000.
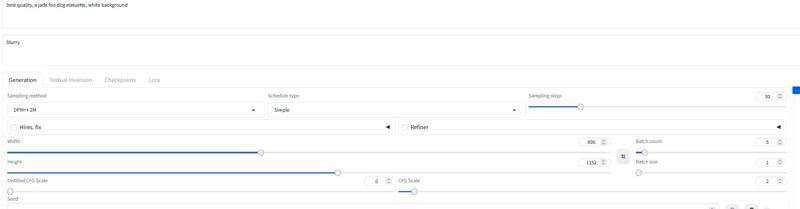
Per le impostazioni consiglio circa 30 passi e 2-2.5 cfg. Io uso soprattutto 2.2 o 2.3 nel workflow. Per la demo ho usato DPM++ 2M con scheduler Simple.
Presto aggiungerò altre versioni ma prima di Natale ho poco tempo..
Impostazioni
Presto aggiungerò un nuovo workflow dedicato per Comfy. Puoi comunque scaricare e aprire le immagini showcase per ora..
La versione "All in One" funziona bene anche con Forge..
Fondamentalmente funziona con le stesse impostazioni della versione 2.1 (vedi sotto)
Usa 20-30 passi con circa 2.2 cfg..
Versione 2.1_de-distilled_experimental (MERGE)
Questa versione è completamente diversa e funziona diversamente da un modello Flux normale!
È un merge sperimentale tra la mia versione 2.0 e una versione de-distilled https://huggingface.co/nyanko7/flux-dev-de-distill. È successo un po' per caso ma i risultati sono sorprendenti. Otterrai dettagli incredibili. Segue molto bene i prompt... Quindi il prossimo passo sarà addestrare direttamente sul modello de-distilled. Ho già fatto dei test Lora con questo. È molto sperimentale quindi fammi sapere se trovi errori che non sono elencati qui sotto. Se hai buone immagini, postale.. anche quelle brutte possono aiutare a migliorare :-). Proverò anche la versione 2.0 e dimmi quale checkpoint preferisci.
!Attenzione!
Il workflow Flux normale non funziona con questa versione. DEVI scaricare il mio workflow per usarla!
Puoi anche provare a trovare una tua soluzione ma non incolparmi per immagini brutte. Inoltre è un modello molto sperimentale... controlla gli svantaggi qui sotto..
Pro e contro di questo checkpoint:
Questo checkpoint può creare dettagli estremi.. Ha però un costo.. È più lento rispetto ai normali checkpoint Flux. Il vantaggio è che spesso non serve un upscaling aggiuntivo. Invece di usare Flux Guidance questo modello usa la scala cfg. Il che significa anche che non funzionerà con workflow standard.
Puoi usare prompt negativi! Questo aiuta a rimuovere elementi indesiderati dall'immagine.
A volte possono apparire artefatti.. Puoi risolverli con un piccolo e semplice upscaling (sto lavorando su questo). Ecco un esempio.. questo succede stranamente non con ogni seed.. AGGIORNAMENTO: non è un problema del modello.. ma del workflow.. Sto lavorando a una soluzione. Se succede prova a impostare il primo upscaling a 1.14 invece che 1.2.

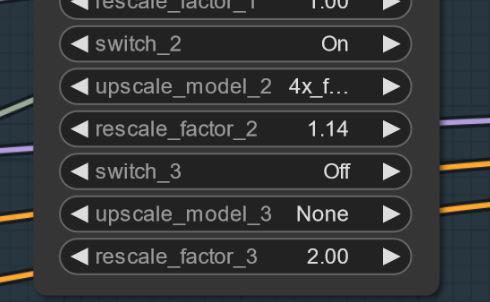
Impostazioni e workflow V2.1:
Qui trovi il workflow: https://civitai.com/articles/8419
Impostazioni: a differenza del Flux normale non serve la scala Flux Guidance. Usa la cfg invece. Io uso di solito 3 cfg per il workflow.. Alcune immagini possono richiedere cfg più bassi
La cosa più importante potrebbe essere disattivare la scala Flux Guidance..
Senza il workflow l'ho testato con 30 passi e 2-3 cfg. Queste possono essere anche le impostazioni per Forge. Prova a sperimentare.
Consiglio di usare la parola "blurry" nei negativi
Sampler e scheduler:
Puoi scegliere tra vari sampler funzionanti:
Euler, Heun, DPM++2m, deis, DDIM funzionano bene.
Io uso principalmente "simple" come scheduler
Se trovi impostazioni migliori dimmi.. :-)
Per Forge consiglio di usare il modello AIO.. ecco un esempio di impostazioni per Forge
Versione 2.0_dev_experimental
Beh.. questa è una versione sperimentale.. L'obiettivo era creare un modello più coerente e veloce. Ho addestrato alcuni lora propri e poi li ho uniti con un merge speciale (Tensor merge). Ha un T5xxl custom modificato con "Attention Seeker". Per velocità e qualità aggiuntiva ho integrato l'Hyper Flux lora da ByteDance. Ciò significa che ha spostato l'area di lavoro.. Ti mostro cosa significa.. Ecco l'immagine principale..
16 passi V 2.0
 30 passi V 1.0
30 passi V 1.0
 Svantaggi:
Svantaggi:
Beh prima di tutto.. Questa versione è un po' più grande della precedente.. secondo devo ancora creare la versione solo Unet. Aggiornerò quando sarà pronta..
Impostazioni e workflow V2.0:
Ora puoi eseguire il modello con meno passi.. 16 passi equivalgono a 30 della vecchia versione.
Consiglio comunque di usare tra 20 e 30 passi per ottenere più qualità nella maggior parte dei casi.
Sampler: preferisco Euler con Simple come scheduler. La scala di guida può essere impostata da 1.5 a 3 (ovviamente puoi testare anche fuori da questi valori). La scala 1.8 funziona bene per immagini realistiche. Puoi anche provare altri sampler, DPM++2M e Heun sono ottimi.
Workflow 2.0:
Ho creato un nuovo workflow per V2.0 e V1.0, con il nuovo Flux Prompt Generator. Inoltre ho attivato il secondo stadio di upscaling. https://civitai.com/articles/7946
Forge:
Ho testato questo modello anche con Forge e ha funzionato molto bene.. Le immagini possono variare tra Comfy UI e Forge però..
Versione 1.0_dev_beta:
Questo modello è la mia prima versione della serie. Perciò per favore lasciami feedback e pubblica immagini. Questo mi aiuta a migliorare ulteriormente il progetto. Ci sono varie versioni tra cui scegliere. Il miglior modello per qualità è la versione FP16 La versione FP16 è molto grande e necessita di una scheda grafica potente e molta RAM. La versione FP8 è un buon compromesso tra qualità e prestazioni. Se vuoi una versione GGUF scarica la Q8_0. La versione GGUF Q4_0/4.1 è stata richiesta. Sono di dimensioni ridotte ma perdi un po' di qualità.
Fondamentalmente ci sono due tipi di modelli: gli "All in one" che richiedono solo un file da scaricare. Contengono Clip_l, T5xxl fp8 e VAE integrati. (vedi sotto). Metti questo file nella cartella checkpoints.
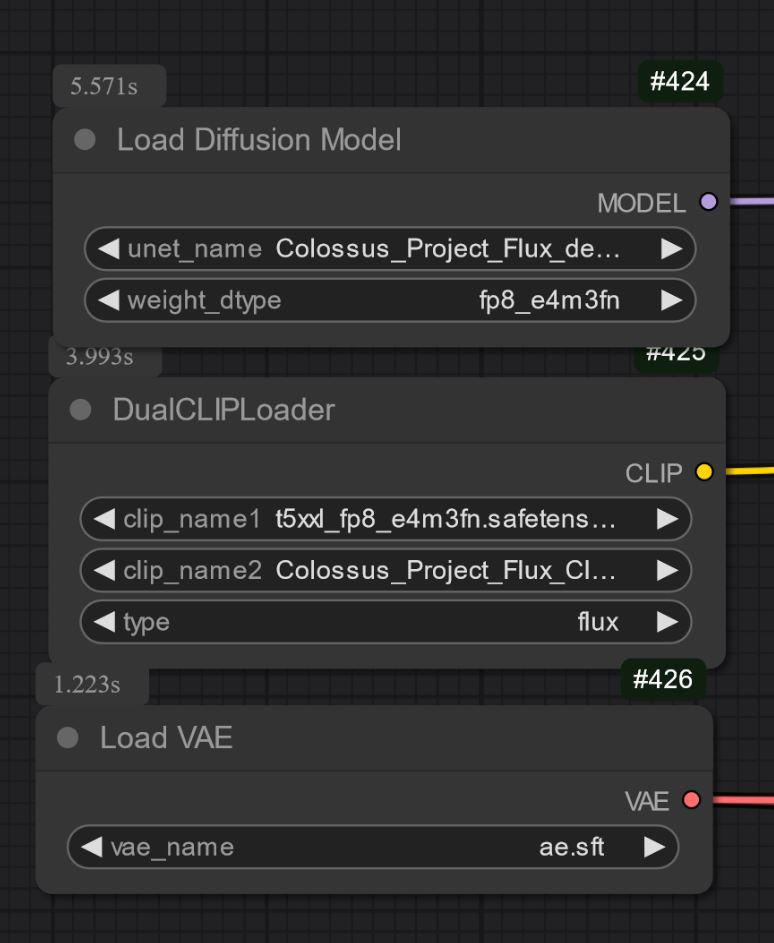
Le altre versioni sono solo UNET. Qui devi caricare tutti i file separatamente.
In ogni caso devi scaricare il mio Clip_L per farli funzionare correttamente..
Importante anche scegliere il T5xxl clip giusto. Per la versione FP8 è il fp8_e4m3fn t5xxl clip. Per la FP16 è il clip FP16. Assicurati di selezionare il tipo di peso default. (sotto c'è un'immagine di esempio per la versione fp8)
Per la versione GGUF ti serve il loader GGUF!
Alcune note conosciute per ora sulla V1.0:
Questo è solo il primo modello della serie quindi per ora può avere difficoltà con alcuni prompt o stili come arte. La prossima versione riceverà più training. Fammi sapere cosa non riesce a fare il modello..
Impostazioni e workflow:
L'ho testato con circa 30 passi, Euler con Simple come scheduler. La scala di guida puoi impostarla da 1.5 a 3 (ovviamente puoi testarla anche fuori da questo intervallo)
La scala 1.8 funziona bene per immagini realistiche.
Sentiti libero di sperimentare con queste impostazioni.. Se ottieni buoni risultati, per favore pubblicali.
Ho aggiunto le immagini showcase come dati di training.. Include il workflow per Comfy. Ecco il workflow da scaricare: https://civitai.com/articles/7946
Modello "All in one":
Solo UNET:
 Devi scaricare anche il clip_L. È un file da 240MB.
Devi scaricare anche il clip_L. È un file da 240MB.
GGUF: Ho aggiunto il workflow per GGUF qui: https://civitai.com/articles/7946
Importante:
Il modello dev non è destinato all'uso commerciale. Per questo pubblicherò il modello "schnell" altrove. È più pensato per uso personale o scientifico.
LICENZA:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
Crediti:
theunlikely https://huggingface.co/theunlikel (grazie ancora)
Versione 2.1/V4.2/5.0: Flux_dev_de-distill da nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
Da V2.0: Hyper Lora da ByteDance https://huggingface.co/ByteDance/Hyper-SD
Black Forrest per il loro incredibile modello Flux https://huggingface.co/black-forest-labs

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Creatore
Discussione
Per favore log in per lasciare un commento.
Collezione di Modelli - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8
















































