SD XL - v1.0 correzione VAE
Parole Chiave e Tag Correlati
Immagini in evidenza












Prompt Negativi Consigliati
(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera
Parametri Consigliati
samplers
steps
cfg
resolution
Suggerimenti
Il modello è destinato a scopi di ricerca inclusi generazione di opere d’arte, strumenti educativi e implementazioni sicure.
Non è destinato a generare rappresentazioni fattuali o veritiere di persone o eventi.
Le limitazioni includono fotorealismo non perfetto, incapacità di rendere testo leggibile, difficoltà con prompt composizionali e possibile generazione imprecisa di volti.
Il modello utilizza due encoder testuali pretrained: OpenCLIP-ViT/G e CLIP-ViT/L.
La pipeline in due fasi include la generazione base dei latenti seguita dal raffinamento ad alta risoluzione usando SDEdit (img2img).
Sponsor del Creatore
Originariamente Pubblicato su Hugging Face e condiviso qui con il permesso di Stability AI.
Originariamente Pubblicato su Hugging Face e condiviso qui con il permesso di Stability AI.
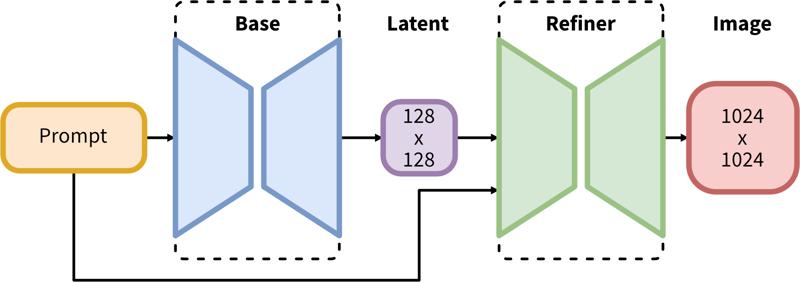
SDXL consiste in una pipeline in due fasi per la diffusione latente: prima, utilizziamo un modello base per generare latenti della dimensione desiderata dell’output. Nella seconda fase, usiamo un modello specializzato ad alta risoluzione e applichiamo una tecnica chiamata SDEdit (https://arxiv.org/abs/2108.01073, conosciuta anche come "img2img") ai latenti generati nella prima fase, usando lo stesso prompt.
Descrizione del Modello
Sviluppato da: Stability AI
Tipo di modello: Modello generativo testo-immagine basato su diffusione
Descrizione del modello: Questo è un modello che può essere usato per generare e modificare immagini basate su prompt testuali. È un Modello di Diffusione Latente che usa due encoder testuali pretrained fissi (OpenCLIP-ViT/G e CLIP-ViT/L).
Risorse per maggiori informazioni: Repository GitHub.
Fonti del Modello
Repository: https://github.com/Stability-AI/generative-models
Demo [opzionale]: https://clipdrop.co/stable-diffusion
Utilizzi
Uso Diretto
Il modello è destinato esclusivamente a scopi di ricerca. Aree e compiti di ricerca possibili includono
Generazione di opere d’arte e utilizzo in processi di design e altri processi artistici.
Applicazioni in strumenti educativi o creativi.
Ricerca sui modelli generativi.
Implementazione sicura di modelli che possono generare contenuti nocivi.
Analisi e comprensione delle limitazioni e dei bias dei modelli generativi.
Gli usi esclusi sono descritti di seguito.
Uso Fuori Scopo
Il modello non è stato addestrato per rappresentazioni fattuali o veritiere di persone o eventi, pertanto l’uso del modello per generare tali contenuti è fuori dallo scopo delle capacità di questo modello.
Limitazioni e Bias
Limitazioni
Il modello non raggiunge un fotorealismo perfetto
Il modello non può rendere testo leggibile
Il modello fatica con compiti più complessi che coinvolgono la composizionalità, come rendere un'immagine corrispondente a “Un cubo rosso sopra una sfera blu”
Volti e persone in generale possono non essere generati correttamente.
La parte di autoencoding del modello è lossy.
Bias
Pur essendo impressionanti, le capacità dei modelli di generazione immagini possono anche rafforzare o esacerbare pregiudizi sociali.
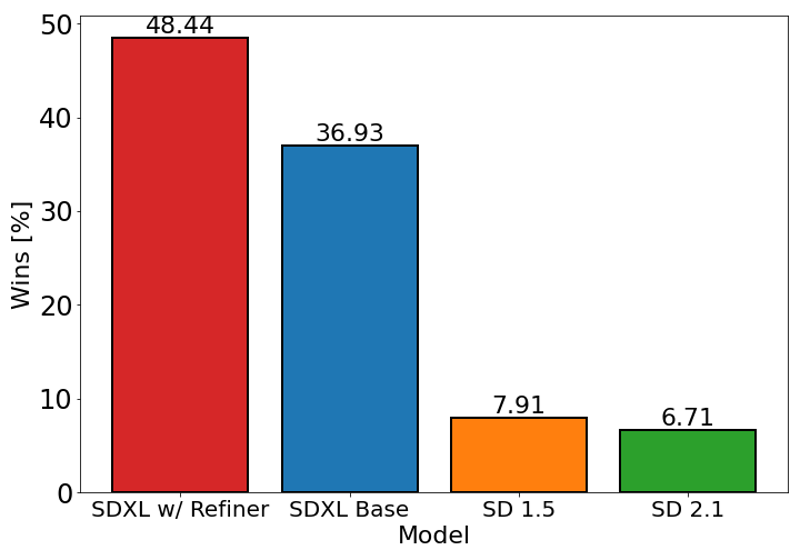
Il grafico sopra valuta la preferenza degli utenti per SDXL (con e senza raffinamento) rispetto a Stable Diffusion 1.5 e 2.1. Il modello base SDXL ha prestazioni significativamente migliori rispetto alle versioni precedenti, e il modello combinato con il modulo di raffinamento ottiene la migliore performance complessiva.

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Discussione
Per favore log in per lasciare un commento.
Collezione di Modelli - SD XL


Immagini di SD XL - v1.0 correzione VAE
Immagini con modello base

Immagini con sdxl



Immagini con stability ai



