Stable Cascade - base
Immagini in evidenza


Parametri Consigliati
steps
resolution
Suggerimenti
Usa la versione da 3,6 miliardi di parametri della Fase C per i migliori risultati poiché il finetuning principale è stato effettuato su di essa.
Usa la variante da 1,5 miliardi di parametri per la Fase B per eccellere nella ricostruzione di dettagli piccoli e fini.
Il modello è adatto per addestramento e inferenza efficienti grazie allo spazio latente più piccolo e supporta estensioni come finetuning, LoRA, ControlNet, IP-Adapter e LCM.
Il modello è destinato esclusivamente a scopi di ricerca e non deve essere utilizzato per generare rappresentazioni fattuali o violare la Acceptable Use Policy di Stability AI.
Volti e persone potrebbero non essere generati correttamente poiché l'autoencoding del modello comporta perdita di dati.
Sponsor del Creatore
Demo:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Demo:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
Questo modello è costruito sull'architettura Würstchen e la sua principale
differenza rispetto ad altri modelli come Stable Diffusion è che opera in uno spazio latente molto più piccolo. Perché è
importante? Più piccolo è lo spazio latente, più veloce è possibile eseguire l'inferenza e più economico diventa l'addestramento.
Quanto è piccolo lo spazio latente? Stable Diffusion utilizza un fattore di compressione di 8, con un'immagine 1024x1024
codificata in 128x128. Stable Cascade raggiunge un fattore di compressione di 42, il che significa che è possibile codificare un
immagine 1024x1024 in 24x24, mantenendo ricostruzioni nitide. Il modello condizionato dal testo viene quindi addestrato nello
spazio latente altamente compresso. Versioni precedenti di questa architettura hanno raggiunto una riduzione dei costi di 16x rispetto a Stable
Diffusion 1.5. <br> <br>
Pertanto, questo tipo di modello è ben adatto a usi in cui l'efficienza è importante. Inoltre, tutte le estensioni note
come finetuning, LoRA, ControlNet, IP-Adapter, LCM ecc. sono possibili anche con questo metodo.
Dettagli del Modello
Descrizione del Modello
Stable Cascade è un modello di diffusione addestrato per generare immagini a partire da un prompt testuale.
Sviluppato da: Stability AI
Finanziato da: Stability AI
Tipo di modello: Modello generativo testo-immagine
Fonti del Modello
Per scopi di ricerca, consigliamo il nostro StableCascade repository Github (https://github.com/Stability-AI/StableCascade).
Repository: https://github.com/Stability-AI/StableCascade
Panoramica del Modello
Stable Cascade consiste in tre modelli: Fase A, Fase B e Fase C, che rappresentano una cascata per generare immagini,
da cui il nome "Stable Cascade".
Le Fasi A e B sono utilizzate per comprimere le immagini, similmente al ruolo del VAE in Stable Diffusion.
Tuttavia, con questa configurazione, è possibile ottenere una compressione molto più elevata delle immagini. Mentre i modelli di Stable Diffusion utilizzano un
fattore di compressione spaziale di 8, codificando un'immagine con risoluzione 1024 x 1024 in 128 x 128, Stable Cascade raggiunge
un fattore di compressione di 42. Questo codifica un'immagine 1024 x 1024 in 24 x 24, potendo comunque decodificare accuratamente
l'immagine. Ciò comporta il grande vantaggio di addestramento e inferenza più economici. Inoltre, la Fase C è responsabile
della generazione dei piccoli latenti 24 x 24 a partire da un prompt testuale. L'immagine seguente mostra questo concetto visivamente.
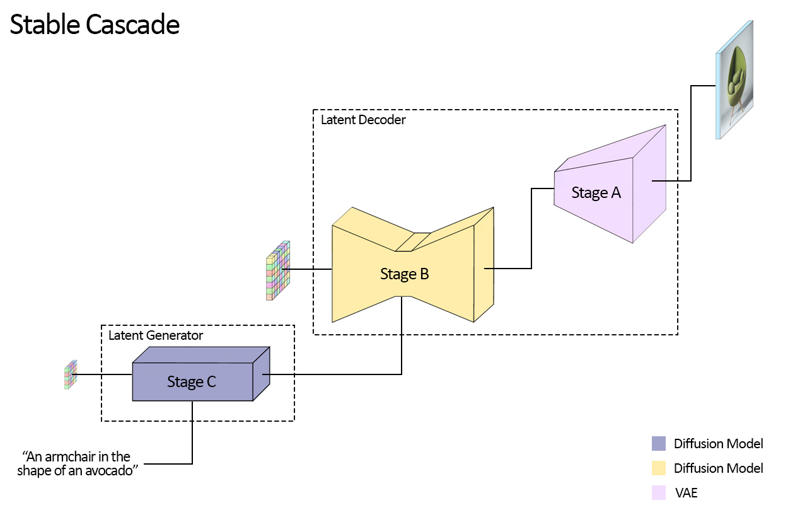
Per questa versione, forniamo due checkpoint per la Fase C, due per la Fase B e uno per la Fase A. La Fase C è disponibile in
versioni da 1 miliardo e 3,6 miliardi di parametri, ma consigliamo vivamente di usare la versione da 3,6 miliardi, poiché la maggior parte del lavoro di finetuning è stato fatto su di essa.
Le due versioni per la Fase B sono da 700 milioni e 1,5 miliardi di parametri. Entrambe ottengono ottimi risultati,
ma quella da 1,5 miliardi eccelle nel ricostruire dettagli piccoli e fini. Pertanto, otterrete i migliori risultati utilizzando la variante più grande di ciascuna. Infine, la Fase A contiene 20 milioni di parametri ed è fissa a causa delle sue dimensioni ridotte.
Valutazione
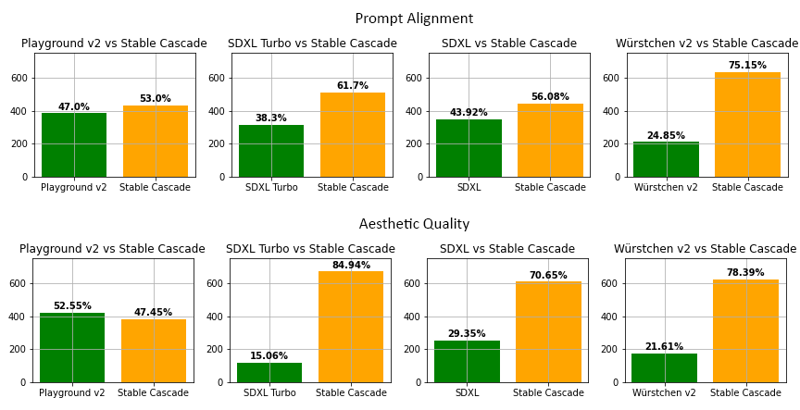
Secondo la nostra valutazione, Stable Cascade performa al meglio sia nell'allineamento del prompt che nella qualità estetica in quasi tutti
i confronti. La figura sopra mostra i risultati di una valutazione umana usando una miscela di parti-prompts (link) e prompt estetici. In particolare, Stable Cascade (30 passi di inferenza) è stato confrontato con Playground v2 (50 passi di inferenza), SDXL (50 passi di inferenza), SDXL Turbo (1 passo di inferenza) e Würstchen v2 (30 passi di inferenza).
Esempio di Codice
⚠️ Importante: per far funzionare il codice sottostante, devi installare diffusers da questo branch mentre il PR è in WIP.
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Gatto antropomorfo vestito da pilota"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#Ora decoder_output è una lista con le tue immagini PILUsi
Uso Diretto
Il modello è attualmente destinato a scopi di ricerca. Possibili aree e compiti di ricerca includono
Ricerca su modelli generativi.
Implementazione sicura di modelli con potenziale di generare contenuti dannosi.
Esplorazione e comprensione dei limiti e dei bias dei modelli generativi.
Generazione di opere d'arte e uso in design e altri processi artistici.
Applicazioni in strumenti educativi o creativi.
Gli usi esclusi sono descritti di seguito.
Uso Non Consentito
Il modello non è stato addestrato per rappresentazioni fattuali o veritiere di persone o eventi,
e pertanto l'uso del modello per generare tali contenuti è fuori dallo scopo delle capacità di questo modello.
Il modello non deve essere utilizzato in modo da violare la Acceptable Use Policy di Stability AI.
Limitazioni e Bias
Limitazioni
I volti e le persone in generale potrebbero non essere generati correttamente.
La parte di autoencoding del modello è con perdita di dati.
Raccomandazioni
Il modello è destinato esclusivamente a scopi di ricerca.
Come Iniziare con il Modello

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Creatore
Discussione
Per favore log in per lasciare un commento.




































