AlbedoBase XL - v3.1-Large
ハイライトされた画像






推奨プロンプト
(incredibly ultra lifelike, perfect professional precise, masterpiece, extremely beautiful, light and shadow
推奨ネガティブプロンプト
strabismus
(worst quality, normal quality, score_3, score_4
推奨パラメータ
samplers
steps
cfg
resolution
vae
ヒント
画像生成が全く結果を出さない場合は、CLIP SKIP 2に切り替えるか、語順や語句を少し変えてプロンプトを調整してください。
文章形式のプロンプトを使うと、タグリストのプロンプトよりも画像品質が向上しやすいです。
ネガティブプロンプト欄を空白にすると、より良い画像結果が得られることが多いです。
使用前に最適な設定をスペックグリッドで確認してください。
左右非対称な目やピクセル化などの問題解決には、“strabismus”のような特定のネガティブプロンプトをいくつか試してください。
バージョンのハイライト
• V3で用いられた再帰スクリプトを使い、50以上の選択された最新SDXLモデルを統合。
クリエイタースポンサー
モデルに価値を感じていただけた場合は、ぜひご支援を検討してください。皆様からのご支援はすべてSDXLコミュニティの発展に充てられます。
🙋🏼♂️ 参加はこちら (discord) ㅤ|ㅤ 🛒 購入する ㅤ|ㅤ 🌱 寄付する
モデルに価値を感じていただけた場合は、ぜひご支援を検討してください。皆様からのご支援はすべてSDXLコミュニティの発展に充てられます。
🙋🏼♂️ 参加はこちら (discord) ㅤ|ㅤ 🛒 購入するㅤ |ㅤ 🌱 寄付する
AlbedoBase XL (SFW&NSFW)
リファイナーは不要で、VAEが含まれています。
目標
Stable Diffusion XLは35億のパラメーターを持ち(リファイナーを除く)、これはSD v1.5の約3.6倍です。これは単なる数字ではなく、大きな性能向上につながる数字だと考えています。
コミュニティの爆発的な貢献によりSD v1.5の全体性能が想像以上に向上したことを受け、この性能向上をXLバージョンでも最適に再現するためにAlbedoBase XLモデルの完成を目指しています。
目標は、Civitaiに公開されているすべてのチェックポイントとLoRAの性能を直接テストし、複数のフィルターを経て最適と判断されたリソースのみを統合することです。これによりMidjourneyなどの企業の画像生成AIの性能を超えることを目指します。
現在、AlbedoBase XL v3.1 Largeは約200の選択されたチェックポイントと251のLoRAを統合しています。
更新記録
v3.1-Large
• V3で使用された再帰スクリプトを用いて、50以上の最新の選択されたSDXLモデルを統合しました。
スペックグリッド(370.7 MB): ダウンロード


v3-mini
長らくお待たせして申し訳ありませんでした。
個人的な事情に対応しながら新バージョンの作業を進めていましたが、健康面の問題にも直面しています。これを書いている現在もその問題と闘っています。
簡単な更新だけでは不十分だと感じ、より詳しいメッセージを共有させていただきます。ご理解のほどよろしくお願いいたします。
バージョン2.0のリリース以降、深層学習を独学で勉強してきました。正式な学位はなく、プログラミングの素養はわずかにある程度で、背景は芸術のみです。そのため、時間と労力を投入しても大きな突破口を開くための数学的・科学的基盤が不足しています。しかし、この自己主導の学習と研究の経験は私の人生にとってかけがえのない宝物となりました。
最近、画期的な突破口となり得るアイデアを思いつきました。バージョン2.0以降、何百もの数式や手法を見直した結果、非常に興味深く成功したアルゴリズムを開発できました。モデルの統合プロセスはSDXL1.0とSD1.5、その他厳選したモデルに基づき、「ANIME」「REALISM」「ARTISTIC」「NSFW」「BASE」の五つの主要分類に分け、これらをデータセットとして統合アルゴリズムに投入しました。このアプローチは興味深い結果をもたらしています。
しかし、アルゴリズムの開発は困難でしたが、性能テストのフェーズほど厳しいものはありませんでした。この期間に身体的・精神的健康は大きく悪化し、一人で継続できないと悟りました。これが本バージョン公開の決断につながりました。
そして今、待望のAlbedoBaseXL V3 Miniバージョンのリリースをお知らせできることを嬉しく思います。このモデルは小規模な統合ですが、特定の領域に限定されず様々な分野で優れた性能を発揮します。SDXL1.0の新たなベースモデルとしての可能性を秘めています。(私の統合アルゴリズムは「線形統合」ではなく、新しいファインチューニングモデルと見なせます。)
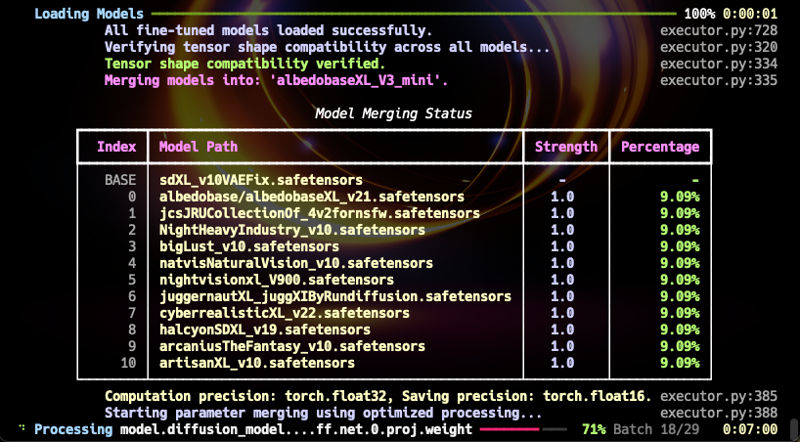
このモデルは既存のAlbedoBaseモデルとともに多用途で、あらゆる点で前バージョンを超えています。(NSFWコンテンツは過激ではないものの、v2.1など以前のバージョンより広範な表現が可能です。専用のNSFW統合モデルは今後リリース予定です。)
最近、多くの共有モデルが統合や外部商用利用を禁止するライセンスを採用し始めていることに気づき、優れたモデルを統合に使えなくなったのは残念です。
時間と労力をかけた高品質モデルを無料ライセンスで提供してくださった開発者の皆様に心より感謝いたします。
また戻ってきます。
ANIME、REALISM、ARTISTIC、2.5D、3D、NSFWなど幅広い分野での性能テストを心待ちにしています。
モデル開発者は種をまくだけであり、最終的にその種を育て花や果実を実らせるのはモデルの利用者やアーティストの皆様です。
いつもありがとうございます。
私の活動を小額でも支援していただける方は、以下のリンクをご利用ください。現在雇用が確保できず、生活の見通しが不透明な状況です。
スペックグリッド(380.5 MB): ダウンロード


v2.1
新しい統合アルゴリズムと数式を用いてv0.1から2.0までを再統合および調整。
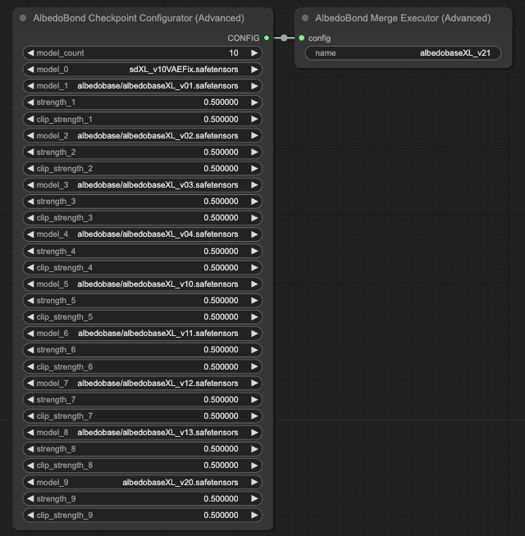
スペックグリッド(424.5 MB): ダウンロード

v2.0
AlbedoBase XL Preにご協力くださった皆様に感謝します。皆様がいなければリリースはもっと遅れたでしょう。本当にありがとうございました!
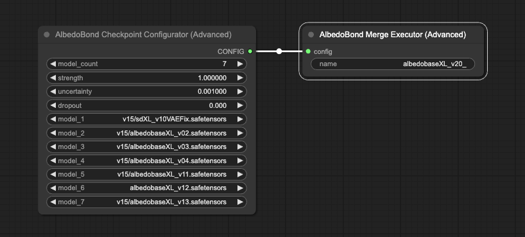
既存のAlbedoBase XLモデルを一つに収束させるためのカスタムスクリプトを書きました。全U-NETおよびCLIPブロックの行列の重みを私独自の数式に沿って精密に整合させています。
画像生成に不具合がある(何も生成されない)場合はCLIP SKIP 2に切り替えるか、プロンプトの語順や語句を少し変更してください。CLIPが認識できないプロンプトの組み合わせが存在する可能性があります。その際は語順や語句を変えるか、最も簡単な方法としてCLIP SKIPを変更してください。これらの問題は将来的にv1.3のように徐々に解決していきます。
スペックグリッド(403.5 MB): ダウンロード
v1.3
モデルのランダム性に伴う品質を示すため、全ショーケース画像のシード値を『9』に統一し即時生成しました。
特に本バージョンでは、ネガティブプロンプトの影響が大きいため、ネガティブプロンプト欄を空白にすると、良質な結果を得やすいです。
スペックグリッド(438.7 MB): ダウンロード

ご覧の通り、Steps数が増えるほど、全サンプラーに対応可能となり、品質も向上します。
下記に示すように、私が作成し統合したLoRAの効果により、タグ(単語リスト)よりも文章形式のプロンプトを使うほうが品質向上に直結します。
チェックポイント45個とLoRA7個を統合しました。その後、AlbedoBase v0.4とv0.3を順に0~5%未満で統合し、統合モデルの希薄化した古い部分を再活性化しました。
7つのLoRAのうち1つは私が作成したもので、GPT4-Vを用いて合計174枚の高品質写真のキャプションを解析・注釈付けし、それを統合した結果、非常に鮮明な画像と卓越したプロンプト理解が実現されました。
私が自作したLoRAは、Creativeレベル以上のKo-fi支援者の方のみに購入可能です。
v1.2
22の最新チェックポイントを統合。
スペックグリッド(565.6 MB): ダウンロード
v1.1
安定化。
より詳細に。
高度なユーザーなら、バージョン1.0を推奨します。1.0が適切な設定を見つけると、より鮮明な作品を生成できます。
スペックグリッド(349.7 MB): ダウンロード
v1.0
106個のLoRAを統合。
19個のチェックポイントを統合。
設定によって異なる結果を得るため、使用前にスペックグリッドで確認することが重要です。
左右非対称な目やピクセル化の問題解決に役立つ特定のネガティブプロンプトがいくつか見つかっています。スペックグリッドはCPUやGPUによって異なる場合がありますので参考にしてください。ネガティブプロンプトを試しながら品質向上に取り組んでください(例:斜視)。統合LoRAの数が増えるほどすべての設定を満足させるのは難しくなりますが、1.0では正しい設定により様々な面で驚異的な品質の作品を生成可能という利点に注目してほしいです。今後さらに安定したバージョンを提供予定です。
ショーケースや他者の検索で役立つ設定値を見つけられます。
いつも通り、最高の結果を得るにはネガティブプロンプトを空白にするのが最適です。
v1.0は大変な作業でしたので少し休みます。モデルを楽しんで使っていただき、もし統合するならCivitaiで無料共有してください。皆で改良を続けられます。
スペックグリッド(479.4 MB): ダウンロード
v0.4
132個のLoRAを統合。
4個のチェックポイントを統合。
スペックグリッド: ダウンロード
v0.3
すべてのサンプラーでの改善。
リアルな写実性の達成。
安定化。
スペックグリッド: ダウンロード
v0.2
鮮明さとディテールの大幅改善。
手足の実装改善。
美的要素の大きな向上;構図、抽象化、流れ、光と色など。
v0.1
SDXL1.0モデル上で適切にファインチューニングを施し、Civitaiで公開されている40以上の高品質モデルを丁寧かつ目的を持って統合。
テストは主に最小限のプロンプトトークン数で最大の品質を確保することに焦点を当てており、大量トークン使用時の品質向上は未確認です。(ご自身で試験し結果を共有してください)
通常、最も美しい結果は現実とアニメーションの中間点で得られます。
それでも、適切なプロンプトを用いるとほぼ何でも表現可能です。(他モデルを超える統合基盤モデルとして豊かな価値を持つと主張します。ただし現時点ではv0.1ですのでご留意ください)

モデル詳細
ディスカッション
コメントを残すには log in してください。






































