Old Consistency V32 Lora [FLUX1.D/PDXL] - Feminine v1.1 - e500 PDXL
하이라이트된 이미지


추천 프롬프트
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
추천 네거티브 프롬프트
greyscale, monochrome, multiple views
추천 매개변수
samplers
steps
cfg
clip skip
resolution
vae
other models
추천 고해상도 매개변수
upscaler
upscale
denoising strength
팁
다중 루프백을 사용해 이미지 충실도와 일관성을 향상하세요.
표준 프롬프트와 논리적 순서를 지켜 괴기한 결과를 피하세요.
'from front', 'from side', 'from above' 등의 핵심 포즈와 시점 태그를 사용해 포즈 정확도를 높이세요.
성적 포즈는 제대로 정제될 때까지 사용을 피하세요.
머리, 눈, 의상 색상 및 재질에 대한 특성 태그를 실험해 보세요.
다른 모델이나 로라와 병합 시 로드 순서가 결과에 영향을 미칩니다.
기본적으로 안전 모드가 활성화되어 있으며, 의심스러운 콘텐츠 및 노골적 콘텐츠 해제가 가능합니다.
캐릭터 배치와 카메라 각도 제어를 위해 포즈 및 지시 태그 시스템을 활용하세요.
버전 하이라이트
안정성 점검;
개념 - 이미지/테스트된 이미지
전신 - 48/48
카우보이샷 - 48/48
인물사진 - 48/48
클로즈업 - 48/48
**************************************
다음 반복은 포즈 각도와 눈 이미지 변이를 포함하는 단일층 눈 포즈 하위집합으로, 번 현상을 확고히 할 예정입니다. 눈 색상은 필수가 아닐 듯하고, 눈 모양이 연구 결과 결정적 요인으로 보입니다.
빨간 눈 - 39/48
전신 - 6/12
카우보이샷 - 9/12
인물사진 - 12/12
클로즈업 - 12/12
파란 눈 - 48/48
모든 포즈 - 12/12
초록 눈 - 48/48
모든 포즈 - 12/12
노란 눈 - 42/48
전신 - 6/12 - 불안정 원인은 미확인.
아쿠아 눈 - 48/48
모든 포즈
보라 눈 - 48/48
모든 포즈
라텍스 - 36/48
클로즈업 - 5/12
인물사진 - 7/12 - 인물사진과 클로즈업 이미지 필요
카우보이샷 - 12/12
전신 - 12/12
란제리 - 36/48
클로즈업 - 7/12
인물사진 - 4/12 ? 이유 미상 - 인물사진과 클로즈업 얼굴 필요
카우보이샷 - 11/12
전신 - 12/12
평상복 - 48/48
모든 포즈 - 12/12
비키니 - 48/48
모든 포즈 - 12/12
드레스 - 16/48
추가 태그 없이는 포즈가 적절한 드레스와 매칭되지 않음 -> 드레스 태그 세분화 필요
출력 안정성은 pony에 이미 내장된 다수 유용 태그 덕분에 기대 이상이며, 예시 포함;
<색상> 머리
<색상> 의상
가슴 <크기>
<성숙한> 여성
<색상> 귀걸이
<색상> 눈
<흐림> 물체
<영역> <배경>
많은 유용한 태그 조합이 있으니 자유롭게 실험하세요.
레이어링 성공 사례;
빨간 눈 -> 파란 눈;
[red eyes:0.5], [blue eyes:0.5] -> 간헐적 중첩 존재, 불안정.
red eyes, blue eyes -> 덜 일관된 중첩
red eyes AND blue eyes -> 더 일관된 중첩, 추가 연구 필요
눈 모양에 색상이 과중 도입되는 현상은 대부분 눈에 공통되어, 블롯 실험 기반이 아닌 후속 처리 방식 도입 권장.
드레스 -> 라텍스
드레스, 사이드 슬릿, 칵테일 드레스, 라텍스, 라텍스 보디수트 -> 다중 레이어로 의상 형성. 일관성은 불안정하나 유망한 결과.
라텍스 -> 드레스
라텍스, 라텍스 보디수트, 드레스, 사이드 슬릿 -> 의상 피부 틈새를 드레스보다 더 많이 포함함. 이는 드레스 훈련의 과적합 가능성을 시사하며 재평가 필요.
라텍스 -> 비키니
라텍스, 라텍스 보디수트, 비키니 -> 라텍스 레깅스와 혼합된 비키니, 역시 과적합 가능성.
레이어링 의상 겹침 문제와 눈, 피부색 문제 해결책이 있습니다. 대부분 일관성은 블롯팅에서 나옵니다.
크리에이터 스폰서
Illustrious 모델과 함께 사용해 보세요.
더 나은 이미지 생성을 위해 ComfyUI 워크플로우와 루프 실험을 사용하세요.
강력한 기반 AI 프레임워크인 Flux 모델을 탐험해 보세요.
최고의 스토리 및 이미지 생성 시너지를 위해 NovelAI를 지원하세요.
Flux 모델 설계에 기여한 Black Forest Labs에 감사를 표합니다.
태그 작업 흐름을 개선하려면 TagGUI를 사용하세요.
훈련 설정은 AIToolkit으로 완료했습니다.
PonyDiffusion와 함께한 영감과 경쟁을 경험하세요.

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious는 PDXL 계열이 아니며, 다르면서도 매우 훌륭합니다. 기회가 된다면 꼭 사용해 보세요.
이를 위해 특별히 Simulacrum 버전을 훈련시켰습니다.
V3-2 대신 V3.22:
v3.22 목표가 변하면서 flux 테스트와 새로운 메커니즘 탐색에 빠졌습니다. 충분히 배우고 주제 고정, 태깅과 FLUX 태깅 이해를 익힌 후 제대로 된 버전 3를 만들 수 있게 되었습니다.
학습과 실험 과정을 견뎌 준 모든 분께 감사드립니다. 여러 실패와 성공을 경험하며 무엇이 가능한지, 어떻게 해야 하는지, 그리고 이를 통해 배우고 반복할 방법을 찾았습니다. 과정은 완벽하지 않으며 앞으로 계속 개선해 나갈 예정입니다. 실험 후 실제 유용한 정보를 배우고 가르칠 준비가 되었다고 자신합니다.
V4를 향한 초기 접근법은 유효하지만 반복 학습 과정에서 사용한 방식은 잘못된 것이 있었습니다. 더 많은 학습과 실패를 통해 성공 기반을 다지는 중입니다.
지침 기반 버전 관리:
버전마다 세 가지 핵심 지침 훈련과 하나의 기본 ‘nd’ 버전을 도입할 계획입니다.
시스템 전체와 핵심 테마 이미지에 폭넓은 일반 지침 훈련을 적용해 의도된 테마를 시스템 전반에 흘려보낼 예정입니다.
기술적인 태깅 부분은 이유를 모르면 이해하기 어려울 것이며, 구체적 내용을 기대하면 혼란스러울 수 있습니다.
간단한 태깅 시스템은 그대로 유지되어 필요한 결과를 낼 수 있습니다.
‘nd’ 또는 ‘no directive’ 버전은 각 릴리스마다 테스트 차이를 확인하고, 형제 모델 간 병합 및 정상화 가능성을 염두에 둡니다.
이 모델의 최우선 목표는 개별 캐릭터 고정입니다. 한 번에 한 캐릭터에만 집중하며, 해상도는 FLUX 훈련 포맷에 맞춰 적절한 비율로 조정됩니다.
V3.2 문제는 예상보다 덜 심각했습니다:
대부분 우려된 결과는 누락된 정보에 기반한 것으로, 시간이 지나며 점진적으로 개선될 예정입니다.
3.21 훈련 버전이 테스트 중이며 곧 공개될 예정입니다. 포즈 제어가 개선되고 카메라 기반 긴 지침에 초점을 옮겼습니다.
대부분 테스트한 로라들과 호환성이 좋으며, 현재 v32에서는 조작 어려웠던 일부 완고한 로라도 작동합니다.
Flux Unchained, 다양한 캐릭터 모델, 얼굴 모델, 사람 모델 등과도 좋은 호환성을 보여주고 있습니다. 시스템 간 간섭이 적어 좋습니다.
V3.2 해결할 문제:
일부 포즈와 각도에서 일관성 문제가 있습니다. 또한 ‘from side’, ‘from behind’, ‘from above’, ‘from below’ 태그 사용 시 여러 로라 간 교차 오염이 발생합니다. 카메라 제어 정확도를 위해 별도의 로라를 훈련시키며 확실한 검증 태그를 도입할 예정입니다.
주로 애니메이션에서는 잘 작동하지만, 로라가 개입되면 문제가 발생합니다.
버전 3.21의 조합 태그 테스트:
카메라 위치에 따른 올바른 작동을 위해 몇 가지 기본 태그 테스트 필요:
앞에서 본 주제, 위쪽 각도
앞에서 본 측면 각도, 위쪽
앞에서 보이는 뒤쪽 각도, 앞에 위치
뒤에서 본 측면 각도, 뒤에 위치
기본 flux_dev에서 이와 유사한 태그들을 테스트하며 카메라 위치와 이미지 충실도를 확보합니다.
일반적인 옵션 사용 시 시스템이 깊이를 크게 훈련하는 것으로 보입니다. 추가 테스트가 필요합니다.
‘grabbing from behind’, ‘sex from behind’ 등의 태그는 ‘behind’ 태그와 충돌 가능성이 있어 후방 태그를 사용할 예정입니다.
‘from side’, ‘from behind’, ‘straight-on’, ‘facing the viewer’ 등의 캐릭터 특정 안전 부루(danbooru, gelbooru 등)와 관련된 회전 태그는 훈련에서 제외됩니다. 캐릭터를 ‘관찰’하는 것을 기반으로 하며 ‘상호작용’하는 것은 아님을 의미합니다.
POV 팔은 거의 포함하지 않으려 하며, 태그가 팔, 다리, 상체가 갑작스럽게 생성되거나 개별 주제에 고착되지 않도록 다수 테스트가 필요합니다.
어떤 포즈들은 사실상 작동하지 않았습니다:
조합 태그 시스템이 제대로 작동하지 않아 캐릭터 제어를 위해 새로운 조합 태그 구조가 필요합니다.
다리가 변형되었거나 아예 존재하지 않음.
팔이 변형되거나 잘못 배치됨.
발이 누락됨.
상체가 과도하게 강조됨. <<< 과적합 현상
하체가 의상을 올바르게 보여주지 않음.
목이 목도리, 수건, 초커, 칼라 등 의상을 올바르게 표현하지 않음.
유두와 성기는 엉망입니다. 적절한 NSFW 컨트롤러용 변형 파일이 필요합니다.
NAI는 스타일별로 특화하여 미세 조정해야 합니다.
의상 옵션이 체형을 과도하게 생성하는 경향.
explicit 등급이 때로 접근 불가능하거나 매우 과도하게 표현됨.
의심스러운 이미지가 충분하지 않으며, explicit 태그 시스템도 의심스러운 태그와 함께 작동해 정보 접근을 보장해야 합니다.
몇몇 애니 캐릭터가 원근법이 잘못 표현되어, 적절한 연관 원근법 목표에 부합하지 않음.
네 발 포즈는 비교적 안정적이나 원근법 문제가 있음. 애니 캐릭터를 3D로 자주 처리하지 않아 주변 환경의 충실도가 더 필요함.
라인업 상태에서 네 발 포즈는 많은 조정 없이는 작동하지 않음.
라인업 상태에서 무릎 꿇기 포즈도 많은 조정 없이는 작동하지 않음.
라인업과 그룹은 flux에서 독특한 방식으로 포맷되며, 내부 루프 활성화 같은 추가 조사가 필요함.
몇 가지 성공 사례:
대부분 이미지에서 기본 충실도는 손상되지 않았습니다.
많은 새로운 포즈가 작동합니다. 다소 이상할 때도 있지만.
애니메 스타일은 현실감이 더해진 독특한 NAI 방식으로 변경되었습니다.
복수 캐릭터 포즈 지정이 가능하지만 때때로 매우 이상한 형태입니다.
어떤 각도에서든 서 있는 모습은 NAI 스타일로 충실하고 뛰어난 품질을 보여줍니다.
V3.3은 대기 중입니다.
V3.3 로드맵:
문서 하단의 리소스를 업데이트하고 이전 문서들은 별도 아카이브 게시물로 분리했습니다.
결과가 제 비전을 더 잘 반영하게 되어 다음 목표인 오버레이에 집중할 수 있습니다.
V3.3에서는 제가 '고알파 버닝 오프셋 태그'라 부르는 것을 도입해 만화, 게임 UI, 오버레이, 체력바, 디스플레이 등 작업을 간소화할 예정입니다.
이론적으로 올바른 버닝과 오버레이로 consistency 안에서 가짜 게임을 만들 수 있습니다.
이는 장면 깊이의 어떤 위치든 캐릭터 배치의 기반을 마련하지만, 그 내용은 이후 단계입니다.
이미 스프라이트 시트를 꽤 잘 만들 수 있어 내장 태그 시스템을 곧 시험해 다양한 하위 시스템을 프롬프트와 계산력으로 테스트할 계획입니다. 이미 존재할 가능성도 높습니다.
V4 목표:
이 과정을 잘 완수하면, 이미지 수정, 비디오 편집, 3D 편집 등 상당히 복잡한 작업을 포함한 완전한 생산 환경을 준비할 수 있을 겁니다.
v33 오버레이
다음 구조를 위한 씬 정의 프레임워크로, 가장 적은 시간과 가장 많은 시간이 동시에 필요한 작업입니다. 알파 테스트를 여러 실험할 예정이며, 메시지 표시 뿐 아니라 씬 조절에 깊이가 중요해 옵션으로 자리 잡을 것입니다.
v34 캐릭터 배치, 회전값 계획, viewpoint 오프셋
특정 캐릭터 존재 여부와 지침 준수를 확보하는 것이 핵심입니다. 때로는 캐릭터가 아예 없을 때도 있습니다.
피치/요/롤로 각도 기반 회전치를 도입합니다. 완벽하진 않겠지만, FLUX와 연계하는 시작점이 될 것입니다.
v35 씬 컨트롤러
씬 내 복합 상호작용 포인트, 카메라 컨트롤, 포커스, 깊이 제어 등 캐릭터 배치와 함께 씬 빌딩을 지원합니다.
3D 오버레이 컨트롤러의 확장판으로 생각할 수 있습니다.
v36 조명 컨트롤러
씬 전체 조명 변경을 분할 및 제어하며 모든 캐릭터, 오브젝트, 창작물에 영향을 줍니다.
언리얼에서 정의한 규칙에 따라 다양한 조명 타입, 소스, 색상을 배치·생성합니다.
이론적으로 FLUX가 빈 공간을 채워줄 것입니다.
v37 체형과 커스터마이징
기본 체형 도입과 함께 다음과 같은 복잡한 요소 도입 예정:
실패하는 포즈 보정
다양한 추가 포즈
복잡한 헤어:
오브젝트와 상호작용, 잘린 머리카락, 손상, 변색, 다색, 묶은 머리, 가발 등
복잡한 눈:
다양한 유형, 열림, 감음, 가늘게 뜸 등
여러 표정:
행복, 슬픔, 놀람, 눈 없음, 단순 얼굴, 무표정 등
귀 유형:
뾰족함, 둥글음, 없음 등
피부 색상 다양화:
밝은색, 빨간색, 파란색, 녹색, 흰색, 회색, 은색, 검은색, 제트블랙, 연갈색, 갈색, 진갈색 등
민감한 주제는 피하며, 옷과 같이 다양한 색상을 원합니다.
팔, 다리, 상체, 허리, 엉덩이, 목, 머리 크기 컨트롤:
이두근, 어깨, 팔꿈치, 손목, 손가락 등 길이, 너비, 둘레 크기 조절 가능
쇄골 및 상체 관련 태그
허리 태그
1~10 단계의 그라데이션 기반 일반적인 체형 분류 (booru 시스템과는 다름)
v38 의상 및 커스터마이징
약 200벌의 의상 각각 커스텀 파라미터 포함
v39 500개의 게임, 애니, 만화 캐릭터 샘플링 (고품질 데이터 기반)
500명의 캐릭터(담배 아님), 다양한 캐릭터 포함(밈 기반은 아님)
이후 원하는 캐릭터 학습과 생성 가능
대규모 충실도 및 품질 향상
수만 장의 고품질 애니, 3D 모델, 사진 기반 반실사 이미지 포함, finetuned flux 학습에 사용
각 이미지 충실도는 pony와 비슷한 score_1~score_10 비율로 평가·태깅되며, 고유 시스템도 적용
V3.2 출시 - 4천 스텝:
아이용이 아니며, SFW/QUESTIONABLE/NSFW를 아우르는 기본 모델로 학습 가능합니다.
윤리적인 smut 제작기는 아니며, 프롬프트에 따른 결과입니다. AI 교육 시 부작용처럼 따라오는 부분이며, 현재 이미지 분포는 약 안전 33%, 의심스러운 33%, NSFW 33% 정도이며, 안전 쪽에 가중치가 있습니다 (NAI처럼).
통제되고 세심한 교육을 통해 검열 없는 AI가 건강하게 발전하며, AI로부터 생성된 이미지를 보는 이들은 과도한 악몽 이미지에 노출되지 않도록 했습니다.
이 모델은 지금껏 본 어떤 것보다도 큰 가능성을 보여줍니다.
아래 모든 이미지에 ComfyUI 워크로드가 첨부되어 있습니다.
기본적으로 안전 모드 활성화:
questionable < 더 많은 의심 요소 무작위 활성화
explicit < 재미있는 요소 무작위 등장
원근법 활성화 태그: 'from front', 'side view' 등 혼합 실험 가능
앞, 앞 보기
측면, 측면 보기
뒤, 뒤 보기
위, 위 보기
아래, 아래 보기
주요 추가 및 향상된 포즈:
네 발
무릎 꿇기
쪼그리기
서기
허리 굽히기
기대기
눕기
거꾸로
엎드리기
누워서
팔 위치
다리 위치
머리 기울기
머리 방향
눈 방향
눈 위치
눈 색상 선명도
머리카락 색상 선명도
가슴 크기
엉덩이 크기
허리 크기
다양한 의상 옵션
다양한 캐릭터 옵션
다양한 표정
성적 포즈는 작업 중이며, 제대로 정제될 때까지 시도하지 않는 것을 권장합니다. 현재 제 역량을 넘는 부분입니다.
포즈 메이커, 각도 메이커, 상황 설정기, 개념 부여기, 보간 구조가 구축되었으며 더 많은 버전을 훈련할 예정입니다.
즐기세요.
V3.2 로드맵:
2024-08-25 05:16 - 프로세스가 잘 작동하며 기대 이상으로 시스템 기능이 높음을 확인했습니다. AI가 예상보다 훨씬 강력하게 캐릭터를 포즈 시키는 emergent 행동을 보였습니다. 테스트가 시작되었고 결과가 매우 훌륭합니다.
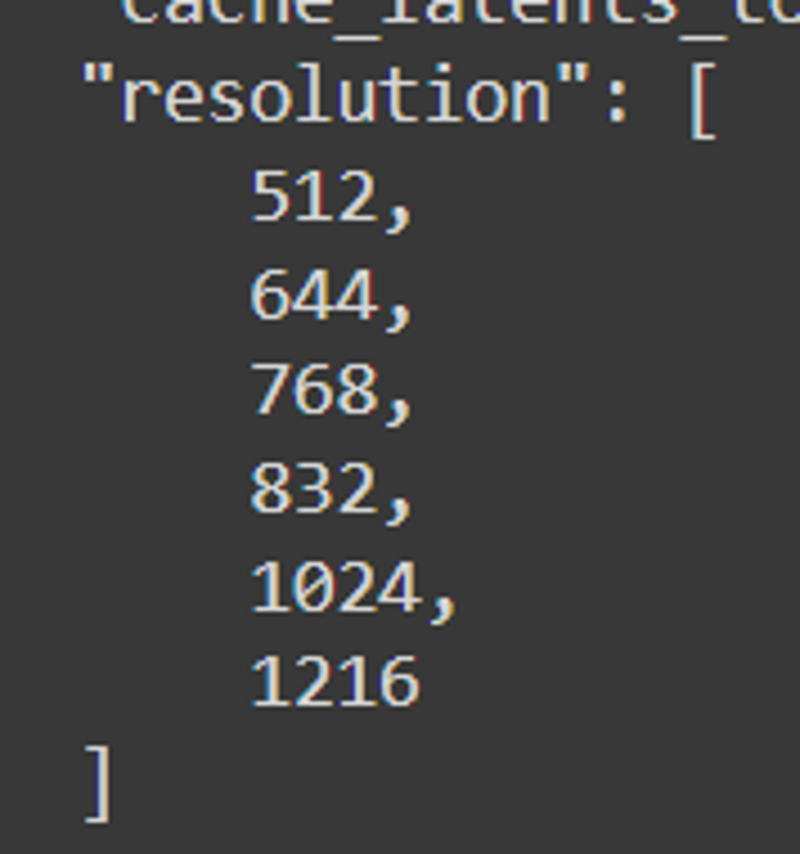
최종 해상도: 512, 640, 768, 832, 1024, 1216
2024-08-25 15:00 - 모든 태그가 정리되고 포즈가 준비되었습니다. 본격 훈련은 이제부터 시작되며, 다차원 테스트, 학습률 검사, 스텝 검사 등으로 적절한 v32 후보를 평가합니다.
2024-08-25 04:00 - v32 첫 버전에서 1400 스텝 근처 미미한 변형, 2200 스텝 근처 고도 변형이 나타났습니다. lazy WD14 태깅이 작동하지 않아 수동 태깅을 진행 중입니다. 즐거운 아침이 될 것입니다.
2024-08-24 저녁 - 현재 훈련 중입니다.
 이 버전은 아마 작동하지 않을 겁니다. 모든 것에 자동 태그를 걸고 포즈 각도를 제외시켰습니다. WD14가 자체적으로 무엇을 할 수 있는지 테스트할 예정입니다. 훈련 결과에 따라 원본 포즈 각도와 태그 순서를 복원할 겁니다. 의도 데이터가 모이고 케이스가 밀집돼서 어떻게 될지 지켜봅니다.
이 버전은 아마 작동하지 않을 겁니다. 모든 것에 자동 태그를 걸고 포즈 각도를 제외시켰습니다. WD14가 자체적으로 무엇을 할 수 있는지 테스트할 예정입니다. 훈련 결과에 따라 원본 포즈 각도와 태그 순서를 복원할 겁니다. 의도 데이터가 모이고 케이스가 밀집돼서 어떻게 될지 지켜봅니다.4000장 이미지로 잠재 공간 캐싱에 시간이 걸릴 것으로 예상하지만, 특정 '사용자 케이스' 인형 및 체형에 집중해 결과가 괜찮을 것입니다.
2024-08-24 정오 -
 열심히 작업 중입니다.
열심히 작업 중입니다. 모든 것이 그림자 암시 배경을 갖도록 포맷되어 flux가 표면과 위치 기반 이미지 생성 시 도움을 줍니다. flux가 처리하지 못하는 포즈가 참고되어 구축되었으며, 여러 장소에 중첩할 수 있는 주제에 고착하도록 설계되었습니다.
모든 것이 그림자 암시 배경을 갖도록 포맷되어 flux가 표면과 위치 기반 이미지 생성 시 도움을 줍니다. flux가 처리하지 못하는 포즈가 참고되어 구축되었으며, 여러 장소에 중첩할 수 있는 주제에 고착하도록 설계되었습니다.팔 위치에 집중하며, 겹치는 팔 태그가 A점에서 B점까지 팔을 생성하도록 확인 중입니다.
2024-08-24 아침 - 팔 문제도 일부 있으나 목록에 추가할 계획입니다. 지적에 감사드립니다. 교차 오염 문제도 있습니다. 웹사이트 생성과 달리 ComfyUI 루프백 시스템을 사용해, 웹사이트 생성은 비활성화할 수도 있습니다.
 2024-08-23 - 약 340장의 고해상도 애니 이미지가 거의 동일한 포즈, pitch/yaw/roll 식별자와 함께 확보되었으며 유방, 머리카락, 엉덩이 크기 차이가 있습니다. 554장 추가 예정입니다. V3.2는 애니메 전용이며, 이후 ponies에서 합성 현실감을 위한 자료를 확보할 예정입니다. 필요 시 flux도 사용합니다.
2024-08-23 - 약 340장의 고해상도 애니 이미지가 거의 동일한 포즈, pitch/yaw/roll 식별자와 함께 확보되었으며 유방, 머리카락, 엉덩이 크기 차이가 있습니다. 554장 추가 예정입니다. V3.2는 애니메 전용이며, 이후 ponies에서 합성 현실감을 위한 자료를 확보할 예정입니다. 필요 시 flux도 사용합니다. 여러분께서 보시기에 포즈 별로 충실도와 등급 분리가 잘 되도록 보장할 것입니다. “from”과 “view” 키워드 사용법을 새롭게 적용해, NovelAI의 포즈 제어와 거의 똑같은 기능을 목표로 합니다. 캐릭터 구분은 별개의 이야기입니다.
여러분께서 보시기에 포즈 별로 충실도와 등급 분리가 잘 되도록 보장할 것입니다. “from”과 “view” 키워드 사용법을 새롭게 적용해, NovelAI의 포즈 제어와 거의 똑같은 기능을 목표로 합니다. 캐릭터 구분은 별개의 이야기입니다.모든 것은 완벽히 정렬되어 순서대로 정돈되어야 하며, 그렇지 않으면 모델에 필요한 맥락을 충분히 전달하지 못하고 쓸모없게 됩니다.
기본적으로 SAFE가 디폴트이며, 시스템 전체가 안전 쪽에 가중치를 두고 NSFW 활성화 기능이 포함됩니다.
특정 LORA 버전을 반복 훈련하여 두 버전 간 명확한 구분을 유지하고, NSFW 쪽 유저도 대응할 계획입니다.
훈련 후 5만 장의 엄선된 데이터셋을 투입해 pony급의 강력함으로 원하는 것을 무엇이든 만들어낼 수 있을 것으로 기대합니다. 이후 사용자들이 원하는 자료를 마음껏 넣어도 flux의 강력한 일관성 기반 힘으로 무엇이든 생성할 수 있을 것입니다.
초기 v3.2 이미지 세트는 정리, 훈련, 테스트 후 공개할 예정이며, 주말에 v3 데이터도 공개할 계획입니다.
주요 포즈 불일치, 특히 ‘lying’ 키워드가 각도 키워드와 결합된 부분을 확인했습니다. 다음 단계로는 기본 의상 선택, 의상 변경, 작동 및 비작동 포즈 기반 파생물 등을 진행할 예정입니다. 나중에 의심스러운 및 NSFW 요소에 대한 상세 정보도 포함할 것입니다. 다음 버전 이후에 추측해 보세요.
그 전까지는 포즈가 의도대로 작동하도록 새로운 조합 키워드 만들고, 각 포즈별·각도별 이미지 수를 늘리고, 더 복잡한 상황과 이미지를 위한 자리 표시자 데이터도 생성할 예정입니다. 실패한 경우 기본 태그를 적용해 일관성을 지원할 것입니다.
V3 문서:
주로 FLUX.1 Dev e4m3fn fp8에서 테스트했습니다. 준비된 체크포인트 병합은 업로드 완료 시 이 값을 반영할 것입니다. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
기본 FLUX.1 Dev 모델에서 동작하지만, 다른 모델, 병합, 로라에서도 작동합니다. 결과는 혼합될 수 있으며, 로드 순서에 따라 값이 달라질 수 있으니 실험해 보시기 바랍니다.
FLUX에 기본으로 없는 뼈대를 완성하며, danbooru와 유사한 유용한 태그를 통해 매우 커스터마이즈 가능한 캐릭터와 상황에서 카메라 제어를 쉽게 만듭니다. 기본 상황에서는 FLUX가 많은 작업을 수행하기 어렵기 때문입니다.
이미지 충실도를 보장하기 위해 다중 루프백 시스템 실행을 강력히 추천합니다. 일관성은 여러 반복에서 품질과 충실도를 향상시킵니다.
개별 지향성이 매우 큽니다. 해상도 구조 덕분에 유사한 상황에 많은 사람을 다룰 수 있습니다. 즉각 화면 변화를 주는 로라는 대개 쓸모없고, 사람 특성 추가 또는 맥락적 상호작용 로라는 잘 작동합니다. 옷, 머리, 성별 제어는 정상 작동하며, 대부분 테스트한 로라가 작동하지만 일부는 아무 작용이 없습니다.
이건 병합이나 로라 조합이 아닙니다. NAI와 AutismPDXL에서 생성된 합성 데이터를 1년간 학습해 만들었습니다. 이미지 세트는 복잡하며, 선택 이미지 추출에 많은 시행착오가 있었습니다.
이 로라와 함께 새로운 시리즈 핵심 태그가 도입되어 FLUX에 기본 없던 뼈대를 완성했습니다. 활성화 패턴은 복잡하지만, NAI 스타일로 캐릭터를 구성하면 유사한 결과가 나타납니다.
모델의 잠재력과 힘은 과소평가할 수 없으며, 제 범위를 초월한 강력한 로라입니다.
표준 프롬프트와 논리적 순서만 지키면 괴기한 결과 없이 아름다운 아트를 만들 수 있습니다.
해상도: 512, 768, 816, 1024, 1216
추천 스텝: 16
FLUX 가이드: 4 또는 고집 셀 때 3-5, 매우 고집 셀 때 15 이상
CFG: 1
두 개의 루프백 사용: 첫 번째는 1.05배 업스케일과 0.72-0.88 노이즈 제거, 두 번째는 거의 변하지 않는 0.8 노이즈 제거 (원하는 특성 도입/제거에 따라 다름)
핵심 태그 풀:
anime - 포즈, 캐릭터, 의상, 얼굴 등을 애니메 스타일로 변환
realistic - 스타일을 현실적으로 변환
from front - 인물의 정면 시점, 어깨와 상체 중심이 시청자를 향함
from side - 인물의 측면 시점, 어깨가 수직이며 인물이 옆모습
from behind - 인물의 정면 뒤쪽 시점
straight-on - 수평 평면 각도의 수직 정면 시점
from above - 45~90도 위에서 아래로 향하는 각도
from below - 45~90도 아래에서 위로 향하는 각도
face - 얼굴 세부 묘사에 집중, 고집 센 얼굴 묘사 포함에 적합
full body - 전신 시점, 복잡한 포즈에 적합
cowboy shot - 표준 카우보이샷, 애니에서는 잘 작동하지만 현실감에는 덜 적합
looking at viewer, looking to the side, looking ahead
facing to the side, facing the viewer, facing away
looking back, looking forward
혼합 태그는 의도한 혼합 결과를 만드나 결과는 다양합니다
from side, straight-on - 인물 측면에 향한 수평 평면 카메라
from front, from above - 앞에서 위로 45도 기울어진 카메라
from side, from above - 옆에서 위로 45도 기울어진 카메라
from behind, from above - 뒤에서 위로 45도 기울어진 카메라
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front, from side, from below
from front, from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
이 태그들은 비슷해 보이나 순서에 따라 상이한 결과를 만듭니다. 예를 들어 ‘from behind’ 태그가 ‘from side’ 앞에 있으면 시스템이 뒤쪽 쪽으로 무게를 두고, 상체가 45도 방향으로 비틀리고 몸 전체가 기울어질 수 있습니다.
결과는 혼합되지만 충분히 활용 가능합니다.
특성, 색상, 의상 등도 작동합니다.
빨강머리, 파랑머리, 초록머리, 흰머리, 검은머리, 금발, 은발, 갈색머리, 보라머리, 분홍머리, 아쿠아머리
빨간 눈, 파란 눈, 초록 눈, 흰 눈, 검은 눈, 금색 눈, 은색 눈, 노란 눈, 갈색 눈, 보라 눈, 분홍 눈, 아쿠아 눈
빨간 라텍스 보디수트, 파란 라텍스 보디수트, 초록 라텍스 보디수트, 검은 라텍스 보디수트, 흰 라텍스 보디수트, 금 라텍스 보디수트, 은 라텍스 보디수트, 노란 라텍스 보디수트, 갈색 라텍스 보디수트, 보라 라텍스 보디수트
빨간 비키니, 파란 비키니, 초록 비키니, 검은 비키니, 흰 비키니, 노란 비키니, 갈색 비키니, 보라 비키니, 분홍 비키니
빨간 드레스, 파란 드레스, 초록 드레스, 검은 드레스, 흰 드레스, 노란 드레스, 갈색 드레스, 분홍 드레스, 보라 드레스
치마, 셔츠, 드레스, 목걸이, 풀 의상
다양한 재료; 라텍스, 메탈릭, 데님, 면 등
포즈가 카메라와 겹치는 상황에서는 잘 작동하지 않을 수 있으며, 조정이 필요할 수 있습니다.
네 발
무릎 꿇기
눕기
눕기, 뒤로
눕기, 옆으로
눕기, 거꾸로
무릎 꿇기, 뒤에서
무릎 꿇기, 앞에서
무릎 꿇기, 측면
쪼그리기
쪼그리기, 뒤에서
쪼그리기, 앞에서
쪼그리기, 측면
다리 제어는 까다로울 수 있으니 약간 실험해 보세요.
다리
다리 붙임
다리 벌림
다리 펼침
발 붙임
발 벌림
수백 개의 다른 태그가 사용 및 포함되며, 수백만 개의 조합 가능
몸 특성 지정 전에는 이 태그들을 우선 사용하고, flux 자체 프롬프트 다음에 배치하세요.
프롬프트 작성법:
그냥 입력하세요. 무엇이 나오는지 보세요. FLUX는 이미 많은 정보를 갖고 있으니, 포즈 등을 활용해 이미지를 보강하세요.
예시:
주방 의자에 앉은 여성, 측면, 위에서 본, 카우보이샷, 1인, 앉음, 측면, 파란 머리, 초록 눈

하늘을 날며 바위를 던지는 슈퍼히어로 여성, 강력하고 빛나는 위협적 오라, 현실적, 1인, 아래쪽 시점, 파란 라텍스 보디수트, 검은 초커, 검은 손톱, 검은 입술, 검은 눈, 보라 머리
 식당에서 식사하는 여성, 위에서, 뒤에서, 네 발, 엉덩이, 끈 팬티
식당에서 식사하는 여성, 위에서, 뒤에서, 네 발, 엉덩이, 끈 팬티 작동했습니다. 보통 작동해요.
작동했습니다. 보통 작동해요.
대부분의 난해한 경우는 감당하지만, 제 역량범위를 넘는 경우도 있습니다. 혼란을 줄이고 핵심 및 유용한 포즈 태그 위주로 사용하세요.
430번 넘는 실패 끝에 몇 가지 성공 이론을 만들었습니다. 필요한 정보를 정리해 사용한 훈련 데이터를 주말에 공개할 예정입니다. 긴 여정이었고 힘든 과정이었습니다. 즐기시길 바랍니다.
V2 문서:
지난밤 피곤하여 전체 정리 및 발견 사항을 마치지 못했습니다. 최대한 빨리, 아마 일하면서 테스트 및 값 마킹을 진행하며 공개하겠습니다.
Flux 훈련 소개:
과거 PDXL은 danbooru 태그가 붙은 소수 이미지만으로도 NAI와 비슷한 미세 조정 결과가 가능했습니다. 적은 이미지 수가 장점이었죠. 그러나 본 모델은 더 많은 이미지가 필요했습니다. 추가 동력이 필요했습니다.
모델은 많은 것을 담고 있지만, 다양한 데이터 간 구별력이 생각보다 높아 가변성이 큽니다. 왜 높은 가변성으로 작동하는지 이해하지 못했습니다.
조사 후 알게 된 점은 모델 자체가 '깊이'에 따른 '지시된' 이미지를 생성하는 강력한 능력을 갖추었다는 점입니다. 이미지를 분할하고 다른 이미지 노이즈를 가이드로 삼아 중첩하는 방식입니다. 이를 어떻게 훈련시킬지 고민했습니다. 초기에는 이미지 크기 변경에 생각이 있었으나, 버켓팅을 떠올렸습니다. 이것이 첫 번째 접근입니다.
정확한 지식 없이 추천 설정에 의존하며 결과를 관찰하는 느린 프로세스를 거쳤습니다. 논문을 읽으며 진행 속도를 높였습니다. 한 번에 다 하려 했지만 혼자며 일이 있어 불가능했습니다. 다중 모델을 동시에 돌리진 못했습니다. 돈으로 해결할 수도 있으나 설치가 어렵습니다.
SD1.5, SDXL, PDXL 로라 학습 경험에 기반해 최선이라 생각한 포맷을 적용했고, 결과는 괜찮았으나 뭔가 이상한 부분이 분명 있었습니다.
훈련 포맷:
몇 가지 테스트를 진행했습니다.
테스트 1 - 무작위 danbooru 이미지 750장:
UNET LR - 4e-4
해상도 버켓팅 주의 외에는 대부분 기본값을 유지했습니다.
1024x1024 중앙 크롭
2k~12k 스텝
무작위 danbooru 태그 풀이서 750장 선택, 태그 균일성 보장
moat 태거 실행, 태그 파일에 덧붙이고 중복 제거
결과는 희망적이지 않았으며, 인간 요소(성기 등) 도입이 빈도 낮거나 완전히 없음. 일반적 발견과 일치.
태그가 겹치지 않을 것으로 생각했지만 전체 모델이 영향 받은 점은 놀라웠음.
테스트를 두 번 진행해 각 12k 스텝의 쓸모 없는 로라 두 개 생성. 1k~8k 테스트에서 의미 있는 편차 발견 불가.
빠뜨린 요소가 있음을 감지, 인간적 요소나 클립 설명 외의 무엇인가 존재.
실패 지점 주변에서 발견한 바는, 깊이 시스템이 두 개의 전혀 다른 조합 프롬프트 기반이고 서로 협력한다고 합니다. 작동 방식을 파악하기 위해 논문을 검토할 예정.
테스트 2 - 이미지 10장:
UNET LR - 0.001 <<< 매우 강력한 LR
256x256, 512x512, 768x768, 1024x1024
초기 스텝에서 일부 편차 관찰, SD3 테스트에서 보인 번 현상 유사. 하지만 500 스텝 이후 출혈 시작, 1000 스텝에서 이미 쓸모없음.
편차가 매우 파괴적이며, 컨텍스트를 간섭하고 사람 요소를 사실상 무의미하거나 손상된 잡음으로 대체함. FLUX의 내구성과 저항성을 보여줌.
실패, 다른 설정으로 추가 테스트 필요.
테스트 3 - 포즈 이미지 500장:
UNET LR - 4e-4 <<< 4로 나누고 스텝 두 배 할 필요
완전 버켓팅 - 256x256, 256x316 등 다양한 크기 난무. 매우 의외의 결과.
이 결과가 바로 본 일관성 모델의 핵심임. 예상보다 더 큰 영향을 미쳤음.
참고: 애니메는 보통 깊이 조절 없으나, 본 모델은 피사계 심도와 흐림에 강점이 있음. 깊이 변화를 위해 depth controlnet 적용 필요성 있으나, 방금 떠오른 방법으로는 파괴 우려. 보통맵과 깊이맵 훈련 고려 중.
추가 테스트 및 훈련 데이터, 정보 필요.
테스트 4 - 5천 일관성 번들:
UNET LR - 4e-4 <<< 40으로 나누고 스텝 20배 이상 필요. 핵심 모델에 이런 훈련은 간단치 않고 빠르지 않음. 현재 프로세스에서 모델 훼손 방지 수학적 검증 부족. 초기 결과 공유.
초기 섹션을 작성 중 마우스 클릭 오류로 삭제되어 추후 재작성 예정.
큰 실패:
초기 12k 스텝 로라용 학습률이 너무 높았습니다. 시스템이 경사 학습 기반이긴 하나, 너무 빠르게 배워서 모델을 훼손했습니다. 본질적으로 소각하지 않고 모델이 원하는 바를 재훈련시켰으나, 제가 원하는 것이 불분명했습니다. 따라서 지시되지 않고 깊이 경사 없는 요소로 실패가 예정되어 있었습니다.
FLUX 스타일은 PDXL 및 SD1.5와 달리 사람들이 생각하는 스타일이 아닙니다. 경사 시스템이 스타일을 표현하지만, 너무 많은 정보를 너무 빨리 도입하려 하면 파괴적입니다. PDXL 로라들이 기존 정보 강화가 주된 반면, 본 환경의 로라는 전혀 새로운 정보 도입이므로 차이가 큽니다.
중요 발견:
알파, 알파, 그리고 더 많은 알파<<<< 이 체계는 알파 그라디언트에 매우 의존합니다. 모든 것은 사진 기반 디테일에 알파 그라디언트를 처리하도록 설계되어야 하며, 거리, 깊이, 비율, 회전, 오프셋 등이 모델 구성의 핵심입니다. 모든 세부 조합을 여러 프롬프트에 걸쳐 포함해야 합니다.
모든 것은 제대로 설명되어야 합니다. 간단한 danbooru 태깅은 스타일에 불과합니다. 시스템이 구현하고자 하는 스타일을 인식하도록 강제해야 하며, 개념 할당 태그가 포함되지 않으면 컨셉 연결 실패로 엉망진창 결과가 나옵니다.
포즈 훈련은 매우 강력하며, 대량의 포즈 정보를 사용하면 효과가 높습니다. 시스템은 이미 대부분의 태그를 인식하나 무엇을 인식하는지는 알 수 없습니다. 태그를 사용해 기존 것을 원하는 형태로 연결하고 미세 조정하는 것이 강력할 것입니다.
스텝 문서:
v2 - 5572 이미지, 92 포즈, 4000 스텝 FLUX
원래 목표인 NAI를 SDXL에 도입하는 계획이 FLUX에 적용되었습니다. 앞으로 더 많은 버전이 공개될 예정입니다.
안정성 테스트가 필요하며, 지금까지 PDXL을 크게 능가하는 성능을 보입니다. 추가 훈련 필요하지만 낮은 스텝 수에서 매우 강력합니다.
포즈 훈련 1차는 약 500장 이미지가 주로 관련됩니다. 전체 데이터셋은 정리돼 HuggingFace에 공개할 예정이며, 불량 이미지나 쓰레기는 포함하지 않겠습니다.
더 읽기:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
주요 참고자료:
저는 담배를 피우지 않지만 FLUX에는 담배가 필요합니다.
워크플로우 및 이미지 생성 도우미입니다. 주로 핵심 ComfyUI 노드를 사용하며, 다른 노드도 실험하고 저장에 활용합니다.
강력하면서 이해하기 어려운 AI 모델로 무한한 잠재력을 지닙니다.
이들이 없었다면 본 프로젝트를 결코 시작하지 못했을 겁니다. NAI 직원 모두에게 큰 감사를 드리며, 이들의 강력한 이미지 생성기와 뛰어난 작문 지원 도구에 투자해 주세요.
Flux 모델 설계자이며, 모델 유연성에서 큰 공헌을 하였습니다. 저는 거대한 대형 괴수를 목적지로 인도하는 조정자일 뿐입니다.
강력한 태그 보조 도구입니다. 직접 개발하려 했으나 이 강력한 툴을 발견했습니다.
Flux 버전 훈련 시 사용한 도구입니다. 다소 까다롭지만 다양한 시스템에서 잘 작동합니다.
경쟁 상대이자 연구 및 이해 도구로 막강한 생명체입니다. 본 진행 방향과 발전에 큰 영감을 주었습니다.

모델 세부사항
토론
댓글을 남기려면 log in하세요.
![Old Consistency V32 Lora [FLUX1.D/PDXL] Feminine v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































