Stable Cascade - 기본
하이라이트된 이미지


추천 매개변수
steps
resolution
팁
최상의 결과를 위해 주로 파인튜닝이 이루어진 스테이지 C의 36억 파라미터 버전을 사용하세요.
스테이지 B에서는 작은 세부 묘사 복원에 강한 15억 파라미터 버전을 사용하세요.
모델은 작은 잠재 공간 덕분에 효율적인 학습 및 추론에 적합하며, 파인튜닝, LoRA, ControlNet, IP-Adapter, LCM과 같은 확장 기능을 지원합니다.
모델은 연구 목적용이며, 사실적인 표현 생성이나 Stability AI의 허용 가능한 사용 정책 위반에 사용되어서는 안 됩니다.
얼굴 및 사람 이미지가 제대로 생성되지 않을 수 있으며, 모델의 자동 인코딩은 손실이 있습니다.
크리에이터 스폰서
데모:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
데모:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
이 모델은 Würstchen 아키텍처를 기반으로 하며, 다른 Stable Diffusion과 같은 모델들과의 주요 차이점은 훨씬 더 작은 잠재 공간에서 작동한다는 점입니다.
왜 중요할까요? 잠재 공간이 작을수록 더 빠르게 추론을 실행할 수 있고, 더 저렴하게 학습이 가능합니다.
얼마나 작은 잠재 공간인가요? Stable Diffusion은 압축 계수 8을 사용하여 1024x1024 이미지를 128x128로 인코딩합니다. Stable Cascade는 압축 계수 42를 달성하여 1024x1024 이미지를 24x24로 인코딩하면서도 선명한 복원이 가능합니다. 텍스트 조건 모델은 이렇게 고도로 압축된 잠재 공간에서 학습됩니다. 이전 버전의 이 아키텍처는 Stable Diffusion 1.5 대비 16배의 비용 절감을 이뤘습니다.<br> <br>
따라서, 효율성이 중요한 용도에 매우 적합한 모델입니다. 또한, 파인튜닝, LoRA, ControlNet, IP-Adapter, LCM 등 알려진 모든 확장 기능들이 이 방법으로도 가능합니다.
모델 세부 정보
모델 설명
Stable Cascade는 텍스트 프롬프트 입력 시 이미지를 생성하도록 훈련된 확산 모델입니다.
개발자: Stability AI
자금 지원: Stability AI
모델 유형: 생성 텍스트-이미지 모델
모델 소스
연구 목적을 위해, 저희는 StableCascade 깃허브 저장소를 추천합니다 (https://github.com/Stability-AI/StableCascade).
모델 개요
Stable Cascade는 이미지 생성을 위한 세 개의 모델, 즉 스테이지 A, B, C로 구성되어 있어, 이름처럼 '안정적인 단계적' 생성을 구현합니다.
스테이지 A와 B는 이미지를 압축하는 역할을 하며, 이는 Stable Diffusion의 VAE와 유사합니다.
그러나 이 설정을 통해 더 높은 압축률을 달성할 수 있습니다. Stable Diffusion 모델이 8배 공간 압축을 사용해 1024 x 1024 이미지를 128 x 128로 인코딩하는 반면, Stable Cascade는 42배 압축을 달성하여 1024 x 1024 이미지를 24 x 24로 인코딩하면서 정확한 복원이 가능합니다.
이로 인해 학습과 추론 비용이 크게 절감됩니다. 또한, 스테이지 C는 텍스트 프롬프트를 받아 24 x 24 크기의 잠재 표현을 생성하는 역할을 합니다. 아래 이미지는 이를 시각적으로 보여줍니다.
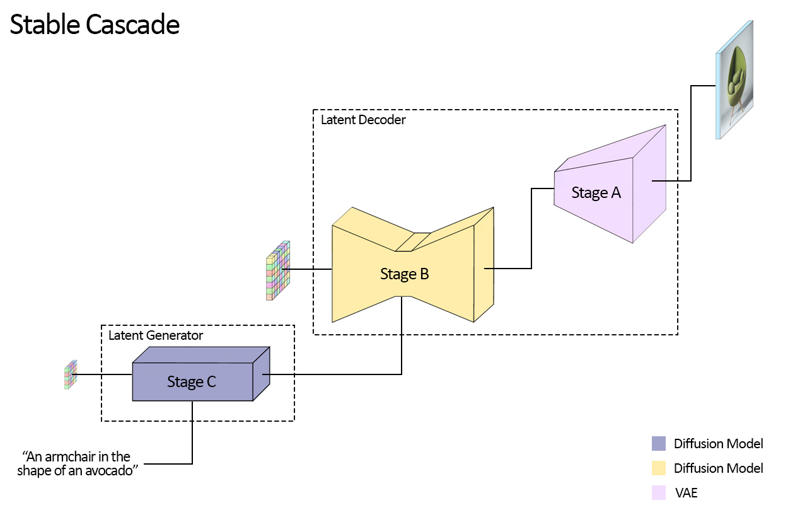
이번 릴리즈에서는 스테이지 C용 체크포인트 2개, 스테이지 B용 2개, 스테이지 A용 1개를 제공합니다. 스테이지 C는 10억과 36억 파라미터 버전을 제공하지만, 대부분의 파인튜닝이 36억 버전에 이루어져 있어 이 버전 사용을 권장합니다.
스테이지 B의 두 버전은 각각 7억과 15억 파라미터이며, 둘 다 훌륭한 결과를 내지만 15억 버전이 작은 세부 묘사 복원에 뛰어납니다. 따라서 각 단계별로 더 큰 버전을 사용할 때 최상의 결과를 얻을 수 있습니다. 마지막으로, 스테이지 A는 2000만 파라미터로 크기가 작아 고정되어 있습니다.
평가
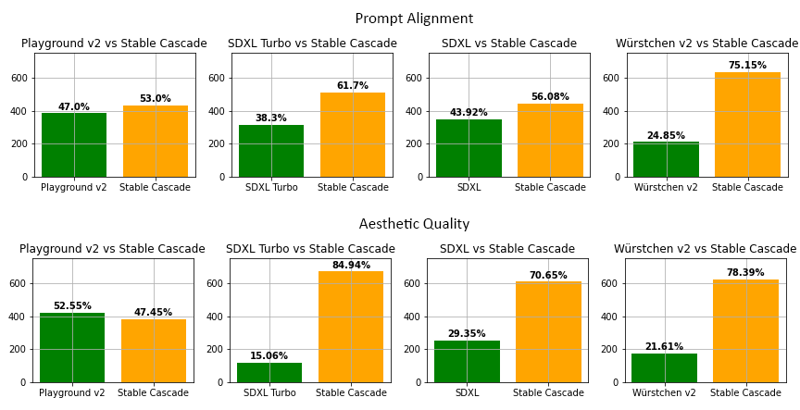
저희 평가에 따르면, Stable Cascade는 거의 모든 비교에서 프롬프트 정렬과 미적 품질 면에서 최고 성능을 보였습니다. 위 이미지는 parti-prompts(링크)와 미적 프롬프트 혼합을 사용한 인간 평가 결과를 보여줍니다. 특히 Stable Cascade(30 추론 단계)는 Playground v2(50 추론 단계), SDXL(50 추론 단계), SDXL Turbo(1 추론 단계), 그리고 Würstchen v2(30 추론 단계)와 비교되었습니다.
코드 예제
⚠️ 중요: 아래 코드를 실행하려면 diffusers의 PR이 진행 중인 이 브랜치에서 설치해야 합니다.
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Anthropomorphic cat dressed as a pilot"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#이제 decoder_output은 PIL 이미지 리스트입니다활용법
직접 사용
이 모델은 현재 연구 목적을 위해 설계되었습니다. 가능한 연구 영역 및 작업은 다음과 같습니다.
생성 모델에 대한 연구.
유해 콘텐츠 생성 가능성이 있는 모델의 안전한 배포.
생성 모델의 한계 및 편향성 조사 및 이해.
예술 작품 생성 및 디자인 등 예술적 과정에 활용.
교육적 또는 창작 도구로의 응용.
제외되는 사용 사례는 아래에 설명되어 있습니다.
적용 범위 외 사용
이 모델은 사람이나 사건에 대한 사실적 또는 진실한 표현을 위해 훈련되지 않았으므로, 그러한 콘텐츠 생성을 목적으로 하는 사용은 모델 능력의 범위를 벗어납니다.
또한 모델은 Stability AI의 허용 가능한 사용 정책를 위반하는 방식으로 사용되어서는 안 됩니다.
제한 사항 및 편향
제한 사항
얼굴과 일반적인 사람 인식이 제대로 생성되지 않을 수 있습니다.
모델의 자동 인코딩 부분은 손실이 발생합니다.
권장 사항
이 모델은 연구 용도로만 사용하도록 설계되었습니다.
모델 시작 가이드
자세한 내용은 https://github.com/Stability-AI/StableCascade 를 확인하세요.

모델 세부사항
토론
댓글을 남기려면 log in하세요.




































