Anime Illust Diffusion XL - v0.5-alpha
Powiązane słowa kluczowe i tagi
Wyróżnione obrazy





Zalecane podpowiedzi
frieren from sousou no frieren,impasto style,beautiful color, detailed, aesthetic
best quality,masterpiece,vivid color,1girl,solo,bangs
Zalecane negatywne podpowiedzi
worst quality:1.3,low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxl_neg
Zalecane parametry
samplers
steps
cfg
resolution
vae
other models
Zalecane parametry wysokiej rozdzielczości
denoising strength
Wskazówki
Zmniejsz wagę słów wyzwalających styl artysty, np. (by xxx:0.6).
Sortuj tagi w prompt dla lepszych efektów.
Używaj VAE modelu lub sdxl-vae.
Najważniejsze informacje o wersji
Dodano 143 nowe słowa wyzwalające. Ta wersja to beta AIDXLv0.5. Nowe style są niestabilne. Zalecam AIDXLv0.41 dla lepszych doświadczeń.
Added 143 new trigger words. This version is a beta version of AIDXLv0.5. The new styles are not stable. I would recommend AIDXLv0.41 for better experience.
Sponsorzy twórcy
Wsparcie obliczeniowe: Dziękujemy społeczności @NieTa (捏Ta (nieta.art)) za dostarczenie mocy obliczeniowej;
Wsparcie danych: Dziękujemy @KirinTea_Aki (Profil twórcy KirinTea_Aki | Civitai) oraz @Chenkin (Civitai | Udostępnij swoje modele) za dostarczenie dużej ilości danych;
Bez nich nie byłoby wersji 0.7.
Wprowadzenie do Modelu (część angielska)
I Spis treści
W tym wprowadzeniu poznasz:
Informacje o modelu (zobacz Sekcję II);
Instrukcje użytkowania (zobacz Sekcję III);
Parametry szkolenia (zobacz Sekcję IV);
Lista słów wyzwalających (zobacz Aneks Część A)
II AIDXL
Anime Illustration Diffusion XL, czyli AIDXL, to model dedykowany do generowania stylizowanych ilustracji anime. Posiada ponad 800 (i stale rosnącą liczbę) wbudowanych stylów ilustracji, które są aktywowane za pomocą określonych słów wyzwalających (zobacz Aneks A).
Zalety:
Elastyczna kompozycja zamiast tradycyjnych pozy AI.
Precyzyjne detale zamiast chaotycznego bałaganu.
Dobre rozpoznawanie postaci anime.
III Przewodnik Użytkownika
1 Podstawowe użycie
1.1 Prompt
Słowa wyzwalające: Dodaj słowa wyzwalające podane w Aneksie A, by wystylizować obraz. Odpowiednie słowa wyzwalające znacząco poprawią jakość;
Zaleca się obniżać wagę dla słów wyzwalających styl artysty, np. (by xxx:0.6).
Sortowanie semantyczne: Sortowanie tagów lub zdań w promptu pomoże modelowi lepiej zrozumieć znaczenie.
Zalecana kolejność tagów: Słowo wyzwalające (by xxx) -> postać (dziewczyna o imieniu frieren z serii sousou no frieren) -> rasa (elf) -> kompozycja (cowboy shot) -> styl (impasto ) -> temat (fantasy) -> główne środowisko (w lesie, w dzień) -> tło (gradient) -> akcja (siedzenie na ziemi) -> wyraz twarzy (neutralny) -> główne cechy (białe włosy) -> cechy ciała (kucyki, zielone oczy, rozchylone usta) -> ubranie (biała sukienka) -> dodatki (falbanki) -> inne elementy (kot) -> środowisko dodatkowe (trawa, słońce) -> estetyka (piękne kolory, szczegółowe, estetyczne) -> jakość ((najlepsza jakość:1.3))
Negatywne prompt: (najgorsza jakość:1.3), niska jakość, lowres, nieporządny, abstrakcyjny, brzydki, zdeformowany, zła anatomia, szkic, zdeformowane ręce, zrośnięte palce, podpis, tekst, wiele widoków
1.2 Parametry generacji
Rozdzielczość: Zadbaj, aby łączna liczba pikseli (=szerokość * wysokość) wynosiła około 1024*1024, a szerokość i wysokość były podzielne przez 32. W tym przypadku AIDXL da najlepsze wyniki. Na przykład 832x1216 (2:3), 1216x832 (3:2) oraz 1024x1024 (1:1), itp.
Sampler i kroki: Użyj samplera "Euler Ancester", w webui nazywanego Euler A . Próbkowanie około ~28 kroków przy 7 do 9 CFG Scale.
'Refine': Obraz wygenerowany z text2image czasem jest nieostry, wtedy należy go 'doprecyzować' za pomocą image2image lub inpainting itp.
Dla prostego skalowania, możesz skorzystać z: Upscale to huge sizes and add detail with SD Upscale, it's easy! : r/StableDiffusion (reddit.com)
Inne komponenty: Nie ma potrzeby używania dodatkowego modelu refiner. Użyj VAE modelu lub
sdxl-vae.
P: Jak odtworzyć okładkę modelu? Dlaczego nie mogę uzyskać takiego samego obrazu jak na okładce, używając tych samych parametrów?
O: Ponieważ parametry generacji pokazane na okładce to NIE parametry text2image, lecz image2image (skalowanie). Bazowy obraz jest głównie generowany samplerem Euler Ancester, a nie DPM samplerem.
2 Specjalne użycie
2.1 Uogólnione style
Od wersji 0.7 AIDXL agreguje kilka podobnych stylów i wprowadza uogólnione słowa wyzwalające styl. Te słowa oznaczają popularną kategorię stylu ilustracji animowanych. Należy zauważyć, że uogólnione słowa wyzwalające styl niekoniecznie odpowiadają artystycznemu znaczeniu słów, ale są specjalnie zdefiniowane na nowo.
2.2 Postacie
Od wersji 0.7 AIDXL poprawiło trening postaci. Efekt niektórych słów wyzwalających postać może osiągnąć efekt Lora i dobrze oddziela koncepcję postaci od stroju.
Metoda wyzwalania postaci to: {character} \({copyright}\). Na przykład, by wyzwolić bohaterkę Lucy z animacji "Cyberpunk: Edgerunners", użyj lucy \(cyberpunk\); by wyzwolić postać Gan Yu z gry "Genshin Impact", użyj ganyu \(genshin impact\). Tu "lucy" i "ganyu" to nazwy postaci, "\(cyberpunk\)" i "\(genshin impact\)" to pochodzenie postaci a nawiasy są escapowane "\" by nie były interpretowane jako tagi z wagą. Dla niektórych postaci część z prawami autorskimi nie jest potrzebna.
Od wersji v0.8 jest łatwiejsza metoda wyzwalania: a {girl/boy} named {character} from {copyright} series.
Listę słów wyzwalających dla postaci znajdziesz tutaj: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Możliwe, że zawiera także dodatkowe, nieujęte tu słowa wyzwalające.
Niektóre postacie wymagają dodatkowego kroku wyzwalania. Jeśli pojedyncze słowo wyzwalające postać nie przywraca jej całkowicie, należy dodać główne cechy tej postaci w prompt.
AIDXL wspiera ubieranie postaci. Słowa wyzwalające postacie zwykle nie zawierają cech ich ubioru. Aby dodać ubranie postaci, dodaj tagi ubrań do promptu. Na przykład, srebrna suknia wieczorowa, głęboki dekolt opisuje strój postaci St. Louis (Luxurious Wheels) z gry Azur Lane. Podobnie możesz dodać dowolne ubrania jakiejkolwiek postaci do innych postaci.
2.3 Tagi jakości
Tagi jakości i estetyki są formalnie trenowane. Dodanie ich w prompt wpływa na jakość generowanego obrazu.
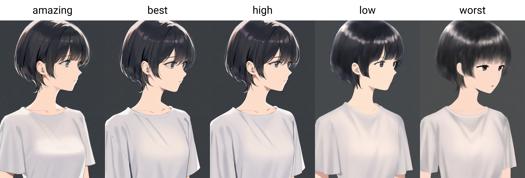
Od wersji 0.7 AIDXL oficjalnie trenuje i wprowadza tagi jakości. Jakości dzielą się na sześć poziomów, od najlepszej do najgorszej: amazing quality, best quality, high quality, normal quality, low quality oraz worst quality.
Zaleca się dodawanie większej wagi tym tagom, np. (amazing quality:1.5).
2.4 Tagi estetyczne
Od wersji 0.7 wprowadzono tagi estetyczne do określania szczególnych cech estetycznych obrazów.
2.5 Łączenie stylów
Możesz połączyć wybrane style w swój styl niestandardowy. "Łączenie" oznacza użycie w prompt’cie kilku słów wyzwalających na raz. Na przykład, chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Kilka wskazówek:
Kontroluj wagę i kolejność stylów, by dopracować ostateczny styl.
Dodawaj słowa na końcu promptu, nie na początku.
IV Strategia i parametry treningu
AIDXLv0.1
Model bazowy to SDXL1.0, trening na około 22 tysiącach obrazów z etykietami przez około 100 epok ze schedulerm cosinusowym, współczynnik uczenia 5e-6, liczba cykli = 1 do uzyskania modelu A. Następnie zmieniono współczynnik uczenia do 2e-7, pozostawiając pozostałe parametry bez zmian by uzyskać model B. Model AIDXLv0.1 powstaje przez połączenie modeli A i B.
AIDXLv0.51
Strategia szkolenia
Wznowienie treningu z AIDXLv0.5, przebiegającego w trzech kolejnych etapach:
Long caption training: Użycie całego zestawu danych, z ręcznie opisanymi niektórymi obrazami. Rozpoczęcie treningu U-Net i enkodera tekstu z optymalizatorem AdamW8bit, wysokim współczynnikiem uczenia (około 1.5e-6) i schedulerm cosinusowym. Zatrzymanie treningu, gdy współczynnik uczenia spadnie poniżej progu (około 5e-7).
Short caption training: Restart treningu z wyjścia etapu 1 z takimi samymi parametrami, ale na zestawie z krótszymi captionami.
Krok udoskonalania: Przygotowanie podzbioru danych z etapu 1 zawierającego ręcznie wybrane obrazy wysokiej jakości. Restart treningu z wyjścia etapu 2 z niskim współczynnikiem uczenia (około 7.5e-7) i schedulerm cosinusowym z 5–10 restarami. Trening do uzyskania estetycznie dobrego wyniku.
Stałe parametry treningu
Brak dodatkowego szumu jak offset szumu.
Minimalna gamma SNR = 5: przyspiesza trening.
Pełna precyzja bf16.
Optymalizator AdamW8bit: równowaga między wydajnością a efektywnością.
Zestaw danych
Rozdzielczość: 1024x1024 (wymiary x szerokość) z modyfikowaną oficjalną strategią bucketingu SDXL.
Opis: Opisy generowane przez model WD14-Swinv2 z progiem 0.35.
Przycinanie na zbliżenia: Przycinanie obrazów na części. Przydatne przy dużych lub rzadkich obrazach treningowych.
Słowa wyzwalające: Pierwszy tag obrazów jest ich słowem wyzwalającym.
AIDXLv0.6
Strategia szkolenia
Wznowienie treningu z AIDXLv0.52 ze strategią adaptacyjnego powtarzania - dla każdego opisowego obrazu zwiększenie liczby powtórzeń treningu zgodnie z następującymi zasadami:
Zasada 1: Im wyższa jakość obrazu, tym więcej powtórzeń;
Zasada 2: Jeśli obraz należy do klasy stylu:
Jeżeli klasa jest niedopasowana lub niedouczona, ręczne zwiększanie ilości powtórzeń lub automatyczne podbicie, by łączna liczba powtórzeń w klasie osiągnęła wartość około 100.
Jeśli klasa jest dopasowana lub przeuczona, ręczne zmniejszenie powtórzeń do 1 i odrzucenie, gdy jakość jest niska.
Zasada 3: Maksymalna liczba powtórzeń ograniczona do progu około 10.
Ta strategia ma następujące zalety:
Chroni oryginalne informacje modelu przed nadpisaniem nowym treningiem, podobnie jak regularizacja obrazu;
Umożliwia lepszą kontrolę nad wpływem danych treningowych;
Równoważy trening pomiędzy klasami, motywując niedouczone klasy i zapobiegając przeuczeniu klas już dopasowanych;
Znacząco oszczędza zasoby obliczeniowe i ułatwia dodawanie nowych stylów do modelu.
Stałe parametry treningu
Takie same jak w AIDXLv0.51.
Zestaw danych
Zestaw danych AIDXLv0.6 opiera się na AIDXLv0.51 i dodatkowo stosuje poniższe optymalizacje:
Sortowanie semantyczne opisów: Sortowanie tagów opisów według znaczenia, np. "gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun".
Usuwanie duplikatów tagów: Usuwanie powtarzających się tagów, pozostawiając ten zawierający najwięcej informacji. Duplikaty to tagi o podobnym znaczeniu, np. "długie włosy" i "bardzo długie włosy".
Dodatkowe tagi: Ręczne dodawanie tagów do wszystkich obrazów, np. "wysoka jakość", "impasto" itp. Można to szybko zrobić za pomocą narzędzi.
V Specjalne podziękowania
Wsparcie obliczeniowe: Podziękowania dla społeczności @NieTa (捏Ta (nieta.art)) za udostępnienie mocy obliczeniowej;
Wsparcie danych: Podziękowania dla @KirinTea_Aki (Profil twórcy KirinTea_Aki | Civitai) oraz @Chenkin (Civitai | Udostępnij swoje modele) za dostarczenie dużej ilości danych;
Bez nich nie byłoby wersji 0.7.
VI AIDXL vs AID
2023/08/08. AIDXL został wytrenowany na tym samym zbiorze danych co AIDv2.10, ale przewyższa go. AIDXL jest mądrzejszy i potrafi robić rzeczy, których modele oparte na SD1.5 nie dają rady. Dobrze rozróżnia pojęcia, uczy się detali obrazu, radzi sobie z kompozycjami trudnymi lub niemożliwymi dla SD1.5 i AID. Ogólnie ma ogromny potencjał. Będę nadal aktualizować AIDXL.
VII Sponsoring
Jeśli podoba Ci się nasza praca, możesz nas wesprzeć przez Ko-fi (https://ko-fi.com/eugeai) na badania i rozwój. Dziękujemy za wsparcie~
介绍模型 (część chińska)
I Spis treści
W tym wprowadzeniu dowiesz się o:
Informacjach o modelu (patrz część II);
Przewodniku użytkownika (patrz część III);
Parametrach treningu (patrz część IV);
Liście słów wyzwalających (patrz Aneks A)
II Wprowadzenie do Modelu
Anime Illustration Diffusion XL, lub AIDXL, to model dedykowany do generowania ilustracji anime. Posiada wbudowane ponad 800 stylów (które rosną z aktualizacjami), aktywowanych specjalnymi słowami wyzwalającymi (patrz Aneks A).
Zalety: odważne kompozycje, brak sztuczności, główny temat wyraźny, brak zbytniego natłoku detali, dobra znajomość wielu postaci anime (wyzwalanie opiera się na nazwach japońskich postaci, np. „ayanami rei” dla „绫波丽”, „kamado nezuko” dla „祢豆子”).
III Przewodnik użytkownika (aktualizowany na bieżąco)
1 Podstawy
1.1 Formułowanie promptu
Używaj słów wyzwalających: stosuj słowa z Aneksu A do stylizacji obrazu. Odpowiednie słowa znacznie poprawiają jakość;
Stosuj tagowanie promptu: używaj tagów do opisu generowanej treści;
Sortuj tagi: sortowanie tagów pomaga modelowi zrozumieć kontekst. Zalecana kolejność:
Słowo wyzwalające (by xxx)->główna postać (1girl)->postać (frieren)->rasa (elf)->kompozycja (cowboy shot)->styl (impasto)->temat (fantasy)->główne środowisko (forest, day)->tło (gradient background)->akcja (sitting)->wyraz twarzy (expressionless)->główne cechy postaci (white hair)->cechy ciała (twintails, green eyes, parted lip)->ubranie (white dress)->dodatki (frills)->inne przedmioty (magic wand)->środowisko pomocnicze (grass, sunshine)->estetyka (beautiful color, detailed, aesthetic)->jakość (best quality)
Negatywne prompt: worst quality, low quality, lowres, messy, abstrakcyjne, brzydkie, zdeformowane, zła anatomia, zdeformowane ręce, zrośnięte palce, podpis, tekst, wiele widoków
1.2 Parametry generacji
Rozdzielczość: upewnij się, że całkowita rozdzielczość (wysokość x szerokość) to około 1024x1024, a szerokość i wysokość są podzielne przez 32. Na przykład: 832x1216 (3:2), 1216x832 (3:2), 1024x1024 (1:1).
Nie stosuj „Clip Skip”, Clip Skip = 1.
Sampler i liczba kroków: używaj samplera euler_ancester (w webui nazywanego Euler A). Ustaw 28 kroków przy CFG Scale 7.
Nie ma potrzeby używania modelu Refiner.
Stosuj wariant vae modelu lub sdxl-vae.
2 Specjalne użycie
2.1 Uogólnione style
W wersji 0.7 podsumowano kilka podobnych stylów i wprowadzono uogólnione słowa wyzwalające. Reprezentują one popularne kategorie stylów ilustracji anime.
Należy pamiętać, że te słowa niekoniecznie odzwierciedlają klasyczne znaczenie artystyczne, lecz zostały specjalnie redefiniowane.
2.2 Postacie
W wersji 0.7 zwiększono trening postaci. Niektóre słowa wyzwalające postać dają efekty podobne do Lora, dobrze oddzielając koncept postaci od jej ubioru.
Sposób wyzwalania postaci: nazwa postaci \(źródło\). Np. aby wyzwolić postać Lucy z animacji "Cyberpunk: Edgerunners" użyj lucy \(cyberpunk\); dla Gan Yu z gry "Genshin Impact" ganyu \(genshin impact\). Nazwy postaci to "lucy" i "ganyu", a "\(cyberpunk\)" i "\(genshin impact\)" to ich źródła. Nawiasy są escapowane "\" by uniknąć interpretacji jako tagi z wagą. W niektórych przypadkach podanie źródła nie jest konieczne.
Lista słów wyzwalających dla postaci: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Mogą być tam też dodatkowe słowa niewymienione w tym dokumencie.
Jeśli pojedynczy tag nie wystarcza do pełnego oddania postaci, należy dodać w prompt dodatkowe cechy charakterystyczne.
AIDXL pozwala na dodawanie ubrań do postaci. Słowa wyzwalające zwykle nie przenoszą cech ubioru, dlatego aby dodać ubranie należy dodać odpowiednie tagi, np. srebrna suknia wieczorowa, głęboki dekolt dla stroju St. Louis (Luxurious Wheels) z gry Azur Lane. Możesz analogicznie mieszać ubrania różnych postaci.
2.3 Tagi jakości
Wersja 0.7 wprowadza oficjalne treningi tagów jakości i estetyki. Ich umieszczenie w prompt wpływa na jakość generowanego obrazu.
Jakość dzielona jest na sześć poziomów od najlepszej do najgorszej: amazing quality, best quality, high quality, normal quality, low quality i worst quality.
Zaleca się zwiększanie wag np. (amazing quality:1.5).
2.4 Tagi estetyczne
Od wersji 0.7 dodano tagi estetyczne, opisujące cechy estetyczne obrazów.
2.5 Łączenie stylów
Możesz łączyć style na swoją własną unikalną kompozycję. Łączenie oznacza użycie wielu słów stylów jednocześnie, np. chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Wskazówki:
Kontroluj wagę i kolejność styli, by dobrze zbalansować wygląd.
Dołączaj stylistykę na końcu promptu, a nie na początku.
3 Wskazówki
Używaj modeli VAE, embeddings i Lora wspieranych przez SDXL. Uwaga: sd-vae-ft-mse-original nie jest VAE wspierającym SDXL; EasyNegative i badhandv4 embeddings nie wspierają SDXL;
dla wersji 0.61 i starszych: przy generowaniu obrazów zaleca się użycie dedykowanych negatywnych embeddings do modelu (dostępne w Suggested Resources), ponieważ są specjalnie przygotowane dla danego modelu i mają głównie pozytywne działanie;
Nowe słowa wyzwalające w każdej wersji działają słabiej lub niestabilnie na bieżącej wersji.
IV Parametry treningu
Model AIDXLv0.1 powstał na bazie SDXL1.0, trenowany na około 20 000 oznaczonych obrazach przez 100 epok z learning rate 5e-6, cyklami = 1 w schedulerze kosinusowym by uzyskać model A. Następnie trenowano model B z learning rate 2e-7 i takimi samymi pozostałymi parametrami. Po połączeniu modeli A i B otrzymano AIDXLv0.1.
Inne parametry treningu znajdziesz w części angielskiej.
V Szczególne podziękowania
Wsparcie obliczeniowe: Dziękujemy społeczności @NieTa (捏Ta (nieta.art)) za dostarczenie mocy obliczeniowej;
Wsparcie danych: Dziękujemy @秋麒麟热茶 (Profil twórcy KirinTea_Aki | Civitai) oraz @风吟 (Profil twórcy Chenkin | Civitai) za dostarczenie dużej ilości danych;
Bez nich nie byłoby wersji 0.7.
VI Log zmian
2023/08/08: AIDXL trenowany jest na tym samym zestawie co AIDv2.10, ale przewyższa go. Jest bardziej inteligentny, potrafi robić rzeczy, których modele oparte o SD1.5 nie potrafią. Lekko radzi sobie z rozróżnianiem koncepcji, detalami obrazu i trudnymi kompozycjami. W sumie posiada wyższy potencjał niż SD1.5, kontynuuję aktualizacje.
2024/01/27: Wersja 0.7 dodaje dużo nowych danych z zestawem ponad dwukrotnie większym od poprzedniego.
Dla uzyskania lepszych anotacji testowałem różne algorytmy przetwarzania etykiet jak sortowanie etykiet, randomizacja warstwowa i oddzielanie cech postaci. Projekt znajduje się na: Eugeoter/sd-dataset-manager (github.com);
Dla kontroli treningu i lepszego dostosowania stworzyłem skrypt treningowy oparty na Kohya-ss;
Dla lepszego łączenia modeli różnych generacji opracowałem heurystyczne algorytmy łączenia; aby uzyskać stylizację zrezygnowałem z łączenia kodera tekstowego i warstw OUT UNET, które mogłoby zaszkodzić stylowi.
Do filtrowania danych przeszkolono modele do wykrywania znaków wodnych, klasyfikacji obrazów i ocen estetycznych, aby oczyszczać dane.
VII Wsparcie finansowe
Jeśli doceniasz naszą pracę, możesz wesprzeć nas finansowo przez Ko-fi (https://ko-fi.com/eugeai), by wspomóc badania i rozwój. Dziękujemy za wsparcie!
Aneks / 附录
A. Lista specjalnych słów wyzwalających / 特殊触发词列表
Słowa wyzwalające styl artystyczny: Kliknij mnie
Słowa wyzwalające styl malarski: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Płaskie kolory, użycie linii do opisania światła i cienia
平涂:płaskie kolory, linie i bloki kolorów opisujące światło i głębię
clean color: Styl pomiędzy flat color a flat-pasto. Proste i czyste kolorowanie.
Czyste kolory: kolorowanie pośrednie między flat color i flat-pasto.
celluloid: Kolorowanie anime
Kolorowanie celuloidowe: styl kolorowania anime
flat-pasto: Prawie płaski kolor, użycie gradientu do opisania światła i cienia
Bliski płaskiemu kolorowi, używanie gradientu do opisania światła i głębi
thin-pasto: Cienka kontura, użycie gradientów i grubości farby do odwzorowania światła, cienia i głębi
cienkie konturowanie z użyciem gradientów i grubości farby do opisu światła i cienia
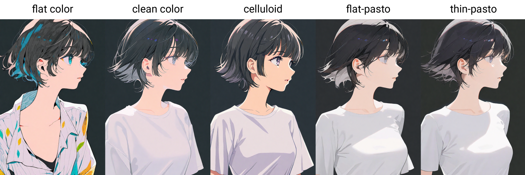
pseudo-impasto: użycie gradientów i grubości farby do opisu światła i cienia
półgruba farba, użycie gradientów i grubości farby do opisu światła i cienia
impasto: użycie grubości farby do opisu światła, cienia i gradacji
gruba farba, użycie grubości farby do przedstawienia światła, cienia i przejść tonalnych
realistic
realistyczny
photorealistic: zdefiniowano na styl bliższy rzeczywistości
fotorealistyczny, redefinicja na styl zbliżony do świata rzeczywistego
cel shading: styl modelowania 3D anime
cel shading: styl 3D anime
3d

Słowa wyzwalające estetykę:
beautiful
piękny
aesthetic: lekko abstrakcyjne odczucie artystyczne
estetyczny: lekko abstrakcyjne artystyczne poczucie
detailed
szczegółowy
beautiful color: subtelne użycie kolorów
piękne kolory: subtelne kolorowanie
lowres
messy: nieporządna kompozycja lub detale
chaos: chaotyczna kompozycja lub detale
Słowa wyzwalające jakość: amazing quality, best quality, high quality, low quality, worst quality




Szczegóły modelu
Typ modelu
Model bazowy
Wersja modelu
Hash modelu
Wytrenowane słowa
Twórca
Dyskusja
Proszę się log in, aby dodać komentarz.





















