Old Consistency V32 Lora [FLUX1.D/PDXL] - Feminine v1.1 - e500 PDXL
Wyróżnione obrazy


Zalecane podpowiedzi
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
Zalecane negatywne podpowiedzi
greyscale, monochrome, multiple views
Zalecane parametry
samplers
steps
cfg
clip skip
resolution
vae
other models
Zalecane parametry wysokiej rozdzielczości
upscaler
upscale
denoising strength
Wskazówki
Używaj wielu loopbacków, aby poprawić wierność i spójność obrazu.
Trzymaj się standardowego promptowania i logicznego porządku, by unikać potworów.
Używaj podstawowych tagów poz i kąta widzenia, takich jak 'from front', 'from side', 'from above' dla lepszej dokładności póz.
Unikaj póz seksualnych, dopóki nie zostaną odpowiednio dopracowane.
Eksperymentuj z różnymi tagami cech włosów, oczu, kolorów ubrań i materiałów.
Kolejność ładowania wpływa na wyniki przy łączeniu z innymi modelami i LoRAs.
Tryb bezpieczny jest domyślnie włączony z opcjami odblokowania treści kontrowersyjnych i eksplicytnych.
Używaj systemu tagów póz i dyrektyw, aby uzyskać lepszą kontrolę nad pozycjonowaniem postaci i kątami kamery.
Najważniejsze informacje o wersji
Sprawdzenia stabilności;
koncepcja - obrazy/testowane obrazy
całe ciało - 48/48
cowboy shot - 48/48
portret - 48/48
zbliżenie - 48/48
**************************************
następna iteracja będzie miała pojedynczą warstwę oczu wywołującą pozy, otagowaną katami póz oraz zawierającą więcej obrazów oczu dla każdej wariacji kąta w celu utrwalenia wypalenia. Kolory oczu prawdopodobnie nie będą potrzebne, ale kształt wydaje się być kluczowy według moich badań.
czerwone oczy - 39/48
całe ciało - 6/12
cowboy shot - 9/12
portret - 12/12
zbliżenie - 12/12
niebieskie oczy - 48/48
wszystkie pozy - 12/12
zielone oczy - 48/48
wszystkie pozy - 12/12
żółte oczy - 42/48
całe ciało - 6/12 - niepewne przyczyny niestabilności.
aqua oczy - 48/48
wszystkie pozy
fioletowe oczy - 48/48
wszystkie pozy
lateks - 36/48
zbliżenie - 5/12
portret - 7/12 - wymaga portretów i zbliżeń
cowboy shot - 12/12
całe ciało - 12/12
bielizna - 36/48
zbliżenie - 7/12
portret - 4/12 ? dlaczego? - wymaga bezpośrednich portretów i zbliżeń twarzy
cowboy shot - 11/12
całe ciało - 12/12
casual - 48/48
wszystkie pozy - 12/12
bikini - 48/48
wszystkie pozy - 12/12
dress - 16/48
żadna pozy nie pasowała do sukienki bez dodatkowych tagów -> potrzeba bardziej precyzyjnych tagów sukienek
Stabilność wyjścia była znacznie wyższa niż oczekiwano, z wieloma użytecznymi tagami już w pony, takimi jak;
<color> włosy
<color> ubrania
rozmiar piersi
dojrzała kobieta
<color> kolczyki
<color> oczy
rozmyty obiekt
obszar w tle
Jest tu wiele użytecznych potencjałów tagowania, więc warto się z nimi bawić jak ja.
Powodzenia w warstwowaniu;
czerwone oczy -> niebieskie oczy;
[czerwone oczy:0.5], [niebieskie oczy:0.5] -> sporadyczne nakładanie się, niestabilne.
czerwone oczy, niebieskie oczy -> mniej niestabilne nakładanie
czerwone i niebieskie oczy -> bardziej stabilne nakładanie, potrzebne dalsze badania
Większość oczu ma ten sam problem: model nakłada zbyt wiele koloru oczu na kształt oka, więc eksperyment z warstwami oczu zostanie zatrzymany i realizowany na bazie eksperymentu z plamą (blot) zamiast dotychczas.
sukienka -> lateks
sukienka, rozcięcie z boku, sukienka koktajlowa, lateks, lateksowy kombinezon -> tworzy strój z wielu warstw. Konsystencja niestabilna, ale efekt obiecujący.
lateks -> sukienka
lateks, lateksowy kombinezon, sukienka, rozcięcie z boku -> tworzy bardziej elegancki obiekt, który nakłada cień między fragmentami sukienki. To sugeruje, że trening sukienki jest przeuczony i wymaga reevaluacji.
lateks -> bikini
lateks, lateksowy kombinezon, bikini -> tworzy lateksowe legginsy zmieszane z bikini, co również wskazuje na przeuczenie.
Myślę, że mam rozwiązanie na nakładanie się ubrań, a razem z nim rozwiązanie dla oczu, koloru skóry i innych. Większość consistency powinna pochodzić z plamienia (blotting).
Sponsorzy twórcy
Sprawdź Model Illustrious o komplementarnych możliwościach.
Używaj workflow ComfyUI do lepszego generowania obrazów i eksperymentuj z pętlami.
Odkryj potężny Model Flux jako bazę AI.
Wsparcie dla NovelAI dla lepszej synergii generowania historii i obrazów.
Podziękowania dla Black Forest Labs za zaprojektowanie modelu Flux.
Ulepsz workflow tagowania z TagGUI.
Konfiguracja treningu wykonana z AIToolkit.
Inspiracja i rywalizacja z PonyDiffusion.

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious nie jest odgałęzieniem PDXL, jest inny i bardzo dobry. Wypróbuj go, jeśli masz okazję.
Przeszkoliłem wersję Simulacrum specjalnie dla niego.
V3-2 zamiast V3.22:
Cele v3.22 uległy zmianie i zagubiłem się w testach flux i poznawaniu nowych mechanizmów. Po zdobyciu dostatecznej wiedzy o fixacji postaci, tagowaniu i sposobie rozumienia tagów przez flux, mogę stworzyć właściwą wersję 3.
Dziękuję wszystkim, którzy wytrzymali mój cykl nauki i eksperymentów. To była prawdziwa kolejka górska testów, porażek i sukcesów. Wiem, co można osiągnąć i jak to zrobić, mam metodologię do iteracji i tworzenia tego, co chcę. Proces nie jest idealny i będzie udoskonalany, więc to będzie ciągły rozwój. Wystarczająco się rozwinąłem, by przejść pierwszy poważny etap Dunninga-Krugera i zacząć faktycznie uczyć i przekazywać wartościowe informacje dla użytkowników podstawowych i zaawansowanych.
Ustaliliśmy, że mój pierwotny plan na V4 jest wykonalny, ale proces, którego używałem, nie jest tak skuteczny, jak myślałem początkowo. Więcej nauki i porażek do wykorzystania, by rozwinąć grunt pod sukcesy.
Wersjonowanie oparte na dyrektywach.
Planuję wprowadzić TRZY główne treningi dyrektyw na wersję oraz jedną wersję vanilla nd.
Będę używać ogólnych dyrektyw nie tylko dla systemu głównego, ale również do konkretnych motywów obrazów, żeby utrwalić zamierzone tematy w systemie.
Techniczna część procesu tagowania będzie unikalna i trudna do zrozumienia dla osób nie zaznajomionych z przyczynami moich działań, więc obrazy i tagi mogą być mylące, jeśli chce się szczegółów.
Prosty system tagów pozostanie niezależny i nadal będzie w stanie produkować niezbędne efekty, gdy zajdzie taka potrzeba.
Wersja "nd" („no directive”) przy każdym wydaniu zapewni podobieństwo testów i wyników, jak ptak w kopalni - gdy przestaje śpiewać, czas odejść. Te siostrzane modele prawdopodobnie można będzie łączyć i normalizować, by łączyć koncepcje, które mogły działać lub nie w zależności od zastosowanej dyrektywy.
Fixacja na POJEDYNCZYCH postaciach jest teraz najważniejszym celem tego modelu. Będzie tylko jedna postać fixowana, a jej rozdzielczość będzie skalowana w stosunku w dół i w górę, zgodnie z parametrami formatowania treningu FLUX.
Problemy w V3.2 były mniej widoczne niż myślałem:
Większość problemów wynikała z brakujących informacji, które planuję uzupełnić w miarę rozwoju. To kwestia iteracyjnego rozwoju.
Aktualnie testuję wersję 3.21, która wkrótce zostanie wydana. Ma lepszą kontrolę poz i przesunięty fokus na model, używający dość długiej dyrektywy opartej na kamerze.
Wyniki pokazały dobrą kompatybilność z większością testowanych lór, nawet z bardzo sztywnymi, które obecny v32 ledwo ruszał lub obracał.
Dobrze współpracuje z Flux Unchained, wieloma modelami postaci, modelami twarzy, ludźmi itd. Większość systemu nie koliduje lub nie psuje innych systemów, co jest dobre.
Problemy v3.2 do rozwiązania:
Są problemy z konsekwencją niektórych póz i kątów. Dochodzi też do krzyżowego zanieczyszczenia tagami z różnych lór, gdy używają tagów takich jak z boku, z tyłu, z góry czy z dołu. Będę używał nowych tagów jako jednostek weryfikacyjnych i szkolił oddzielną LoRA do zapewnienia dokładnej kontroli kamery w przyszłości.
Wydaje się, że działa dobrze głównie dla anime, ale przy zaangażowaniu lór pojawiają się problemy.
Tagi kombinacyjne dla wersji 3.21;
Potrzebuję wykonać bazowe testy, by upewnić się, że kamera działa prawidłowo w zależności od ustawienia. Będę testował takie tagi jak:
postać widziana z przodu z góry
postać widziana z przodu z boku będąca na górze
postać widziana od tyłu z góry będąca z przodu
postać widziana z boku z góry będąca od tyłu
oraz więcej podobnych tagów w bazowym flux_dev, żeby zapewnić poprawne pozycjonowanie kamery i zachowanie wierności obrazu.
Z mojej wiedzy system trenuje głębokie warstwy przy użyciu takich ogólnych opcji. Potrzeba więcej testów, by się upewnić.
Tagi takie jak chwytanie od tyłu, seks od tyłu itp. prawdopodobnie nie będą współgrać z tagami "od tyłu", dlatego użyję tagów "rear".
Tagi "from side", "from behind", "straight-on", "facing the viewer" i wszystkie bezpośrednio powiązane z specyficznymi tagami safebooru, danbooru, gelbooru i rotacjami nie będą trenowane. Będą się opierać wyłącznie na OBSERWOWANIU postaci, a nie INTERAKCJI z nią.
Nie chcemy też, by pojawiały się ramiona POV w większości przypadków, więc potrzebne są liczne testy, aby upewnić się, że tagowanie nie generuje pomyłkowo ramion, nóg czy tułowia, i koncentruje się na fixacji konkretnej postaci w danym ujęciu.
Niektóre pozy po prostu nie działały:
System tagów kombinacyjnych, który tu działał, nie wykonał swojej pracy, więc trzeba będzie stworzyć nowy zestaw kombinacji tagów do prawidłowej kontroli postaci.
Nogi są zdeformowane lub ich brak.
Ramiona mogą być zdeformowane lub źle umieszczone.
Brak stóp.
Zbyt wyraźny górny tors, zbyt często <<< przeuczenie
Dolny tors nie pokazuje ubrań prawidłowo.
Szyja nie pokazuje poprawnie szalików, ręczników, obroży i innych.
Piersi i genitalia są kompletnym bałaganem. Potrzebny jest właściwy folder wariantów do sterowania NSFW w tym zakresie.
NAI powinien być stylem specyficznym i dopracowanym jako styl.
Opcje ubrań generują typy ciał częściej niż powinny.
Ocena eksplicytna jest czasem prawie niemożliwa do uzyskania, innym razem przebija się jak ciężki pociąg.
Brakuje wystarczającej liczby obrazów „kwestionowanych” do przydzielenia wagi, system oznaczeń eksplicytnych powinien być też oznaczany jako kwestionowany, by dane kwestionowane były dostępne.
Niektóre postacie anime pojawiają się z błędną perspektywą, co jest złe, gdy celem jest odpowiednia perspektywa skojarzeniowa.
Pozycja "na czworaka" jest całkiem solidna, ale ma problemy z perspektywą. Nie traktuje często postaci anime jako 3D, więc otoczenie wokół obrazów wymaga większej wierności.
Pozycja "na czworaka" nie działa w linii bez znacznych poprawek.
Klęczenie nie działa w linii bez znacznych poprawek.
Układy i grupy są sformatowane specyficznie dla flux i wymaga to dalszych badań. Prawie jak uruchomienie wewnętrznej pętli „for each”.
Były sukcesy:
Podstawowa wierność nie ucierpiała dla większości obrazów.
Wiele nowych pozy DZIAŁA, o ile nie są czasem dziwne.
Styl anime zmieniony w unikalny sposób NAI z dodatkiem realizmu.
Możliwe jest ustawianie wielu postaci, choć czasem w dziwny sposób.
Stanie pod dowolnym kątem ma fantastyczną wierność i jakość obrazu w stylu NAI.
V3.3 musi poczekać.
Plan działania V3.3:
Zaktualizowałem zasoby na dole tego dokumentu i wydzieliłem starszą dokumentację do oddzielnego artykułu do archiwizacji.
Z wynikiem lepiej odzwierciedlającym mój cel mogę teraz skupić się na następnych krokach; Nakładkach (Overlays).
V3.3 wprowadzi tzw. tagi offsetu wypalonego o wysokiej alfa, które usprawnią tworzenie komiksów, UI gier, nakładek, pasków zdrowia, wyświetlaczy itd.
Teoretycznie możesz stworzyć własne fałszywe gry w consistency, jeśli przygotuję poprawną nakładkę z odpowiednimi wypaleniami.
To położy fundamenty pozwalające na umieszczanie postaci w dowolnej pozycji i głębokości sceny, ale to przyjdzie później.
Już TERAZ można tworzyć sprite sheet'y w wystarczającym stopniu, więc w nadchodzących dniach przetestuję system tagów za pomocą lekkiego wspomagania promptów i mocy obliczeniowej. Jest duże prawdopodobieństwo, że coś takiego już istnieje i wystarczy to odkryć.
Cele V4:
Jeśli wszystko pójdzie dobrze, cały system będzie gotowy do pełnej produkcji, łącznie z modyfikacją obrazów, edycją wideo, edycją 3D i wieloma innymi rzeczami, których na razie nie potrafię pojąć.
v33 nakładki
To trochę mylące, bo to bardziej framework definiujący scenę dla następnej struktury.
To zajmie zarówno najmniej, jak i najwięcej czasu, mam kilka eksperymentów do wykonania z alfa, ale jestem przekonany, że nakładki będą opcją do wyświetlania komunikatów oraz kontroli sceny ze względu na działanie głębi.
v34 narzędzia narzucania postaci, planowania wartości rotacji i starannych przesunięć punktu widzenia:
Zapewnienie istnienia i przestrzegania dyrektyw przez niektóre postaci to główny cel, bo czasem tego brakuje.
Wdrożony pełny system wartości rotacji opartych na pitch/yaw/roll w stopniach. Nie będzie idealny, bo nie mam umiejętności matematycznych, zestawów obrazów ani oprogramowania 3D, ale będzie dobrym startem i mam nadzieję, że wykorzysta już istniejące możliwości FLUX.
v35 kontrolery scen
Złożone punkty interakcji w scenach, kontrola kamery, ostrość, głębia i inne, które pozwalają na tworzenie pełnych scen z postaciami w środku.
To jak 3D wersja kontrolera nakładek, ale wzmocniona, jeśli chcesz.
v36 kontrolery oświetlenia
Segmentowane i kontrolowane scenicznie zmiany oświetlenia wpływające na wszystkie postaci, obiekty i stworzenia.
Każde światło będzie umieszczane i generowane według zasad określonych w unreal z użyciem wielu typów oświetlenia, źródeł, kolorów itd.
Teoretycznie FLUX powinien uzupełnić luki.
v37 typy ciał i personalizacja ciał
Po wprowadzeniu podstawowych typów ciała chcę wprowadzić bardziej złożone tworzenie typów ciał obejmujące m.in.:
poprawianie póz, które nie działają poprawnie
dodanie wielu dodatkowych póz
bardziej złożone włosy:
interakcja włosów z obiektami, obcięte włosy, zniszczone, przebarwione, wielokolorowe, związane, peruki itd.
bardziej złożone oczy:
różne typy oczu, otwarte, zamknięte, mrużące itd.
wiele wyrazów twarzy:
szczęśliwe, smutne, :o, bez oczu, prosta twarz, bez twarzy itd.
typy uszu:
spiczaste, zaokrąglone, bez uszu itd.
różne kolory skóry:
jasny, czerwony, niebieski, zielony, biały, szary, srebrny, czarny, bardzo czarny, jasnobrązowy, brązowy, ciemnobrązowy i inne.
Postaram się unikać wrażliwych tematów, ponieważ ludzie zazwyczaj bardzo przejmują się kolorem skóry, ale chcę po prostu mieć wiele kolorów jak w ubraniach.
kontrolery rozmiarów ramion, nóg, torsu, talii, bioder, szyi i głowy:
biceps, ramię, łokieć, nadgarstek, dłonie, palce itd. z regulacją długości, szerokości i obwodu.
kość obojczyka i tagi torsu
talia i odpowiednie tagi
ogólne typy ciała na gradient od 1 do 10 zamiast ustalonego systemu typu tych z booru
v38 stroje i personalizacja strojów
Prawie 200 strojów z własnymi parametrami.
v39 500 postaci z gier wideo, anime i mangi wybrane z danych o wysokiej wierności
pięćset papierosów- ee... znaczy... Wiele postaci. Tak. Na pewno nie ogromna liczba memowych postaci bez logicznego powiązania z designem czy archetypem.
Po tym możesz tworzyć lub szkolić dowolną postać.
ogromny wzrost wierności i jakości:
w tym dziesiątki tysięcy obrazów z różnych źródeł wysokiej jakości anime, modeli 3D i półrealistycznych zdjęć, by nałożyć i przeszkolić tę szczególnie dopracowaną wersję flux w stylistyczne podanie zgodne z parametrami.
każdy obraz będzie oceniany pod względem wierności i tagowany w stosunku score_1 do score_10 podobnie jak pony, ale z własnym unikalnym podejściem w zależności od jakości wyników.
Wydanie V3.2 - 4k kroków:
Tu nie dla dzieci zdecydowanie. To baza modelu SFW/QUESTIONABLE/NSFW, którą można szkolić do wszystkiego.
Nie jest zbudowany do produkcji erotyków, ale potrafi, gdy jest odpowiednio wywołany. To część całego pakietu, gdy uczysz AI pewnych zachowań, masz konsekwencje. Obrazy teraz są mniej więcej 33% / 33% / 33%, mniej więcej. Jest nastawiony na bezpieczne treści podobnie jak NAI.
Jestem zdania, że włączanie i nauka informacji pozwala użytkownikowi decydować, co z nimi zrobić. Uczenie nieocenzurowanego AI wielu rzeczy w kontrolowany i ostrożny sposób jest zdrowe dla rozwoju AI oraz dla tych, co generują obrazy, by nie musieć oglądać koszmarów 24/7.
Model pokazuje potencjał ponad wszystko, co widziałem do tej pory.
Użyj mojego ComfyUI workload. Załączony do wszystkich obrazów poniżej.
Domyślnie uruchomiony safe:
questionable < odblokowuje więcej kontrowersyjnych cech
explicit < odblokowuje losowe, zabawne treści
Tagi aktywujące perspektywę: spróbuj miksować; from front, side view itd.
z przodu, front view,
z boku, side view,
z tyłu, rear view,
z góry, above view,
z dołu, below view,
Główne, dodane i ulepszone pozy:
na czworaka
klęcząca
przysiadająca
stojąca
pochylona
oparta
leżąca
do góry nogami
na brzuchu
na plecach
układanie rąk
układanie nóg
pochylenia głowy
kierunki głowy
kierunki oczu
położenie oczu
intensywność koloru oczu
intensywność koloru włosów
rozmiar piersi
rozmiar pośladków
rozmiar talii
wiele opcji ubioru
wiele opcji postaci
wiele wyrazów twarzy
pozy seksualne są bardzo w fazie roboczej i zdecydowanie odradzam próbować ich, dopóki nie będą odpowiednio dopracowane. Są poza moimi aktualnymi możliwościami i nie mam teraz siły, by określić dalszą drogę.
Twórca poz, kreator kąta, ustawienia sytuacji, nakładanie koncepcji i struktura interpolacji są gotowe i będę trenował kolejne wersje.
Miłej zabawy.
Plan działania V3.2:
25.08.2024 5:16 - Potwierdziłem, że proces działa i system jest funkcjonalny na wysokim poziomie powyżej oczekiwań. AI rozwinęło emergentne zachowania, które pozwoliły ustawić postaci zdecydowanie lepiej niż przewidywano. Testy trwają, a wyniki są fantastyczne.
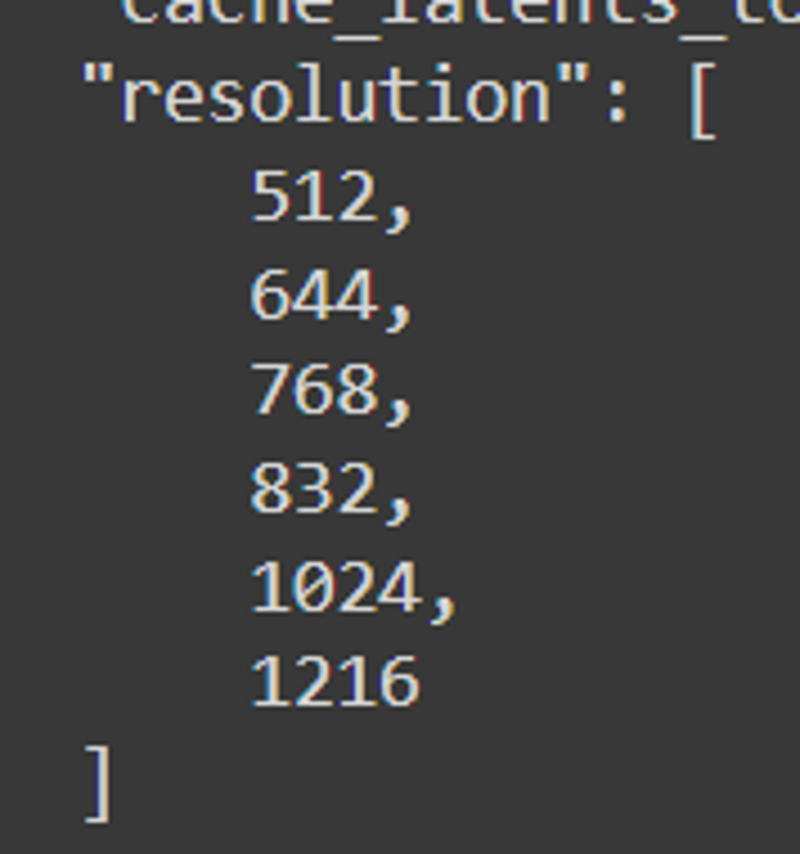
Końcowe rozdzielczości: 512, 640, 768, 832, 1024, 1216
25.08.2024 15:00 - Wszystko jest odpowiednio otagowane, pozycje przygotowane. Teraz zaczyna się prawdziwy trening, który obejmie testy wielowymiarowe, testy lr, kontroli kroków i inne, aby dobrać właściwego kandydata do wydania v32.
25.08.2024 4:00 - Pierwsza wersja v32 wykazała minimalne deformacje przy kroku 1400 i poważne przy 2200, co oznacza, że leniwe tagowanie WD14 zawiodło. Nadchodzi ręczne tagowanie. Zapowiada się ciekawy poranek.
24.08.2024 wieczór - gotowe w piecu.
 Podejrzewam, że to nie zadziała. Wszystko jest automatycznie otagowane, a kąty póz zostały chwilowo wyklipowane. Sprawdzę, co zrobi WD14 sam. W zależności od sukcesu treningu odtworzę oryginalne kąty i porządek tagów. Zobaczymy, jak działa, gdy wszystkie dane są zgromadzone i przypadki użycia zagęszczone.
Podejrzewam, że to nie zadziała. Wszystko jest automatycznie otagowane, a kąty póz zostały chwilowo wyklipowane. Sprawdzę, co zrobi WD14 sam. W zależności od sukcesu treningu odtworzę oryginalne kąty i porządek tagów. Zobaczymy, jak działa, gdy wszystkie dane są zgromadzone i przypadki użycia zagęszczone.Z 4000 obrazów podejrzewam, że chwilę zajmie cache'owanie latentów, ale z uwagą skupioną na specyficznych lalkach i ciałach powinno być ok.
24.08.2024 południe -
 Pracujemy.
Pracujemy. Wszystko jest tak sformatowane, by mieć cieniowane tła, co pomaga flux generować obrazy oparte na powierzchniach i lokalizacjach. Wszystko jest zbudowane do póz, którym flux nie potrafi sprostać. Wszystko ma fixować postaci, które można wielokrotnie nakładać w wielu miejscach.
Wszystko jest tak sformatowane, by mieć cieniowane tła, co pomaga flux generować obrazy oparte na powierzchniach i lokalizacjach. Wszystko jest zbudowane do póz, którym flux nie potrafi sprostać. Wszystko ma fixować postaci, które można wielokrotnie nakładać w wielu miejscach.Skupiłem się na poprawnym umiejscowieniu rąk i zapewnieniu, że oznakowane nakładające się ramiona utworzą ramię od punktu A do B.
24.08.2024 poranek - Są też problemy z ramionami, ale dodam je do listy. Dzięki za zwrócenie uwagi, jest tu krzyżowe zanieczyszczenie do rozwiązania. Używam specyficznego systemu loopback w ComfyUI, którego nie ma na stronie, więc może wyłączę generowanie na stronie dla tej wersji.
 23.08.2024 - Mam około 340 nowych obrazów anime wysokiej jakości z niemal równymi pozami, identyfikatorami pitch/yaw/roll, by zapewnić solidność, przesunięcia kolorów, różnice rozmiaru piersi, włosów i pośladków. Zostało jeszcze 554. V3.2 będzie mocno dedykowana anime, potem planuję wykorzystać pony do stworzenia wystarczającego realizmu syntetycznego. Chyba że flux pozwoli po treningu, wtedy użyję flux.
23.08.2024 - Mam około 340 nowych obrazów anime wysokiej jakości z niemal równymi pozami, identyfikatorami pitch/yaw/roll, by zapewnić solidność, przesunięcia kolorów, różnice rozmiaru piersi, włosów i pośladków. Zostało jeszcze 554. V3.2 będzie mocno dedykowana anime, potem planuję wykorzystać pony do stworzenia wystarczającego realizmu syntetycznego. Chyba że flux pozwoli po treningu, wtedy użyję flux. To POWINNO zapewnić wierność i separację ocen na podstawie każdej pozy, szczególnie że mam nową metodologię używania słów "from" i "view". Teoretycznie powinno działać niemal tak samo jak kontrola póz w NovelAI, co jest moim celem. Postacie i ich różnice to oczywiście inna historia.
To POWINNO zapewnić wierność i separację ocen na podstawie każdej pozy, szczególnie że mam nową metodologię używania słów "from" i "view". Teoretycznie powinno działać niemal tak samo jak kontrola póz w NovelAI, co jest moim celem. Postacie i ich różnice to oczywiście inna historia.Wszystko musi być idealnie uporządkowane, inaczej po prostu nie doda odpowiedniego kontekstu i nie wpłynie na model bazowy tak, by był użyteczny.
Z założenia SAFE będzie ustawiony domyślnie, system będzie ważony w stronę bezpiecznych treści z możliwością włączania NSFW.
Planuję szkolić wiele iteracji tej LoRA, by ściśle odróżnić dwie wersje, jednocześnie pozwalając na wersję NSFW dla tych, którzy jej chcą.
Mam nadzieję, że po wytrenowaniu będę mógł wprowadzić wybrany zestaw danych 50 000 obrazów i stworzy coś magicznego. Potencjalnie tak potężnego jak pony dla wszystkiego, czego dusza zapragnie. Potem możecie wrzucać co chcecie, a system stworzy wam cokolwiek chcecie dzięki mocy flux i fundamentom consistency.
Planuję udostępnić dane treningowe dla pełnego zestawu consistency v3.2, gdy będą uporządkowane, wytrenowane, przetestowane i gotowe. Dane v3 zostaną wydane w weekend, gdy znajdę czas.
Zidentyfikowałem szereg niespójności póz, głównie z tagiem "lying" połączonym z tagami kątów. Przetestuję każdą kombinację i uporządkuję ich spójność przed kolejną fazą; wyborem bazowych strojów, zmianami oraz pochodnymi w oparciu o działające i niedziałające pozy. Poza tym muszę później dodać szczegółowe informacje o elementach "questionable" i NSFW. Możesz się domyślić, co to będzie po następnej wersji.
Do tego czasu muszę upewnić się, że pozy faktycznie działają zgodnie z dyrektywami, więc stworzę nowe, zamierzone słowa kluczowe do kombinacji, zwiększę liczbę obrazów na pozy, zwiększę liczbę kątów na statyczną sytuację itd. Stworzę też zasoby działające jak placeholdery na bardziej złożone sytuacje i obrazy, ale flux nie potrzebuje ich wiele, więc będę je opracowywał w trakcie. Dodam też serię "base" tagów, które domyślnie będą przełączać pewne rzeczy przy punktach awarii. To powinno pomóc w spójności.
Dokumentacja V3:
Testowano przede wszystkim na FLUX.1 Dev e4m3fn przy fp8, więc przygotowany checkpoint będzie odzwierciedlał tę wartość po zakończeniu uploadu. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
To działa na bazowym modelu FLUX.1 Dev, ale będzie działać też na innych modelach, merge'ach i loarach z mieszanymi rezultatami. Eksperymentuj z kolejnością ładowania, bo wartości modelu zmieniają się w sekwencji stopniowo.
To nic innego jak kręgosłup FLUX. Dodaje użyteczne tagi podobne do danbooru, by zapewnić kontrolę kamery i wsparcie, co znacznie ułatwia tworzenie bardzo konfigurowalnych postaci w sytuacjach, do których FLUX prawdopodobnie JEST STWORZONY, ale które zazwyczaj wymagają więcej wysiłku.
Zdecydowanie polecam używać wielu loopbacków, aby poprawić jakość i wierność obrazów. Consistency poprawia jakość i spójność na wielu iteracjach.
Jest bardzo nastawiony na pojedyncze postacie. Jednak ze względu na sposób organizacji rozdzielczości może obsługiwać wielu ludzi w podobnych sytuacjach. LoRA powodujące natychmiastowe zmiany na ekranie bez kontekstu zwykle są bezużyteczne, bo nie wnoszą kontekstu. LoRA specyficzne do dodawania cech lub tworzenia interakcji między ludźmi działają całkiem dobrze. Ubrania działają, typy włosów działają, kontrola płci działa. Większość testowanych loár działa, ale są też takie, które nic nie robią.
To nie merge, to nie połączenie lór. Ta loRa została stworzona z syntetycznych danych wygenerowanych przez NAI i AutismPDXL w ciągu roku. Zestaw obrazów jest złożony, a wybór użytych obrazów był trudny. Wymagał wielu prób i błędów. Naprawdę mnóstwo.
Ta loRa wprowadza SZEREG podstawowych tagów. Dodaje cały kręgosłup do FLUX, którego domyślnie nie ma. Schemat aktywacji jest złożony, ale jeśli zbudujesz postać podobnie do NAI, będzie wyglądać podobnie do postaci NAI.
Potencjał i moc tego modelu nie mogą być niedoceniane. To potężna loRa, a jej potencjał jest poza moimi możliwościami.
Wciąż może generować potwory, jeśli nie będziesz ostrożny. Gdy trzymasz się standardowych promptów i logicznego porządku, powinieneś szybko tworzyć piękną sztukę.
Rozdzielczości: 512, 768, 816, 1024, 1216
Zalecane kroki: 16
Wskaźnik FLUX: 4 lub 3-5 jeśli oporny, 15+ jeśli bardzo oporny
CFG: 1
Uruchamiałem z 2 loopbackami. Pierwszy to upscale 1.05x i denoise 0.72-0.88, drugi denoise 0.8, prawie bez zmian, w zależności ile cech chciałem dodać lub usunąć.
ZBIÓR PODSTAWOWYCH TAGÓW:
anime - stylizacja poz, postaci, ubrań, twarzy itd. na anime
realistic - stylizacja na realizm
from front - widok z przodu osoby, barki ustawione przodem do widza, środek torsu skierowany na widza.
from side - widok z boku osoby, barki pionowo do widza, postać z boku
from behind - widok bezpośrednio z tyłu osoby
straight-on - proste, pionowe ujęcie z kątem poziomym
from above - nachylenie 45-90 stopni z góry na osobę
from below - nachylenie 45-90 stopni od dołu na osobę
face - obraz skupiony na szczegółach twarzy, dobry do trudnych detali twarzy
full body - widok całej postaci, dobry do bardziej złożonych póz
cowboy shot - standardowy tag typu cowboy shot, dobrze działa w anime, gorzej w realizmie
patrzący na widza, patrzący na bok, patrzący przed siebie
zwrócony na bok, zwrócony do widza, zwrócony plecami
patrzący w tył, patrzący przed siebie
tagowanie mieszane daje zamierzony efekt, ale z różnymi wynikami
from side, straight-on - pozioma kamera skierowana na bok osoby lub osób
from front, from above - 45 stopni nachylenie skierowane w dół z kamery z przodu
from side, from above - 45 stopni nachylenie skierowane w dół z kamery z boku
from behind, from above - 45 stopni nachylenie skierowane w dół z kamery z tyłu
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front, from side, from below
from front, from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
Te tagi mogą wyglądać podobnie, ale kolejność często daje bardzo różne efekty. Na przykład użycie "from behind" przed "from side" spowoduje priorytet dla "behind" nad "side", choć często górny tors się skręca, a ciało obraca o 45 stopni w którąkolwiek stronę.
Efekt jest mieszany, ale zdecydowanie da się to wykorzystać.
cechy, kolory i ubrania także działają
czerwone włosy, niebieskie, zielone, białe, czarne, złote, srebrne, blond, brązowe, fioletowe, różowe, aqua
czerwone oczy, niebieskie, zielone, białe, czarne, złote, srebrne, żółte, brązowe, fioletowe, różowe, aqua
czerwony lateksowy kombinezon, niebieski, zielony, czarny, biały, złoty, srebrny, żółty, brązowy, fioletowy lateksowy kombinezon
czerwony bikini, niebieski, zielony, czarny, biały, żółty, brązowy, fioletowy, różowy bikini
czerwona sukienka, niebieska, zielona, czarna, biała, żółta, brązowa, różowa, fioletowa sukienka
spódnice, koszule, suknie, naszyjniki, pełne stroje
różne materiały; lateks, metal, dżins, bawełna itd.
pozy mogą, ale nie muszą współgrać z kamerą, wymagają korekt
na czworaka
klęcząca
leżąca
leżąca na plecach
leżąca na boku
leżąca do góry nogami
klęcząca od tyłu
klęcząca z przodu
klęcząca z boku
przysiadająca
przysiadająca od tyłu
przysiadająca z przodu
przysiadająca z boku
kontrolowanie nóg jest bardzo wrażliwe, więc trochę pobaw się nimi
nogi
nogi razem
nogi rozstawione
nogi szeroko
stopy razem
stopy rozstawione
setki innych tagów, miliony możliwych kombinacji
Używaj ich przed specyfikacjami cech osoby, ale po promptach dla samego fluxa.
PROMPTOWANIE:
Po prostu rób to. Wpisz cokolwiek i zobacz, co się stanie. FLUX ma już dużo informacji, więc używaj póz i innych tagów, aby ulepszyć obrazy.
Przykład:
kobieta siedząca na krześle w kuchni, z boku, z góry, cowboy shot, 1 dziewczyna, siedząca, z boku, niebieskie włosy, zielone oczy

superbohaterka latająca na niebie rzucająca głazem, otoczona bardzo potężną, świecącą, złowrogą aurą, realistyczna, 1 dziewczyna, z dołu, niebieski lateksowy kombinezon, czarny kołnierz, czarne paznokcie, czarne usta, czarne oczy, fioletowe włosy
 kobieta jedząca w restauracji, z góry, z tyłu, na czworaka, pośladki, stringi
kobieta jedząca w restauracji, z góry, z tyłu, na czworaka, pośladki, stringi Tak, zadziałało. Zwykle działa.
Tak, zadziałało. Zwykle działa.
Naprawdę, ten model powinien poradzić sobie z większością szaleństw, choć będzie poza moim zakresem rozumienia. Starałem się ograniczyć chaos i dodać wystarczająco tagów póz, więc trzymaj się podstawowych i użytecznych.
Ponad 430 nieudanych prób doprowadziło do sukcesu. Wkrótce przygotuję pełny opis wymagań i udostępnię dane treningowe w weekend. To był długi i trudny proces. Mam nadzieję, że wam się spodoba.
Dokumentacja V2:
Wczoraj wieczorem byłem bardzo zmęczony, więc nie skończyłem kompletnego zapisu wyników. Spodziewaj się go jak najszybciej, pewnie w ciągu dnia podczas pracy będę robił testy i zaznaczał wartości.
Wprowadzenie do treningu Flux:
Wcześniej PDXL potrzebował niewielu obrazów z tagami danbooru, by dać dopracowane wyniki porównywalne do NAI. Mniej obrazów było siłą, tu mniej nie działało. Potrzebował czegoś więcej, trochę mocy.
Model ma dużo, ale różnice między danymi treningowymi są większe niż się spodziewałem. Większa wariancja to też większy potencjał, ale nie wiedziałem, jak to działa z wysoką wariancją.
Po badaniach odkryłem, że model jest potężny DZIĘKI temu. Może generować „STEROWANE” obrazy zależnie od głębi, segmentując i nakładając obraz na obraz z użyciem szumu jak drogowskazu. Zastanawiałem się jak trenować >>TO<<, nie niszcząc szczegółów modelu. Myślałem o zmianie rozmiaru, potem przypomniałem sobie o bucketingu. To był pierwszy krok.
Poszedłem na ślepo, ustawiając parametry na sugestie i oceniając efekty. To powolny proces, więc czytałem prace naukowe, by przyspieszyć. Gdybym miał więcej mocy, zrobiłbym wiele jednocześnie, ale jestem tylko jedną osobą i mam pracę. Dosłownie rzuciłem wszystko, co mam. Gdybym miał więcej czasu, odpaliłbym 50 jednocześnie, ale nie mam. Mogę zapłacić, ale nie mogę tego skonfigurować.
Wybrałem format, który wydawał mi się najlepszy na podstawie doświadczeń z SD1.5, SDXL i treningami PDXL lora. Wyszło w porządku, ale coś jest nie tak i opiszę to dalej.
Formatowanie treningu:
Zrobiłem kilka testów.
Test 1 - 750 losowych obrazów z mojego próbki danbooru:
UNET LR - 4e-4
Zauważyłem, że inne elementy nie miały znaczenia, poza uwzględnieniem bucketingu rozdzielczości.
1024x1024 tylko, wycięty środek
Między 2k a 12k kroków
Wybrałem 750 losowych obrazów z jednego z basenów tagów danbooru i zapewniłem jednolitość tagów.
Użyłem moat taggera i dodałem tagi do pliku bez nadpisywania.
Wyniki nie były obiecujące. Chaos był oczekiwany. Wprowadzenie elementów ludzkich, takich jak genitalia, było przypadkowe lub brakowało ich. To zgodne z wynikami innych.
Nie spodziewałem się degradacji całego modelu, bo tagi zwykle się nie nakładały, tak myślałem.
Test powtórzyłem dwukrotnie i mam dwa bezużyteczne lory po około 12k kroków. Test 1k-8k prawie nic nie dał pod kątem celu, nawet obserwując krzywe tag pool.
Coś tu jest. Coś przeoczyłem, nie są to cechy ludzkie ani opis clip. Jest coś więcej.
Znajdując się przy punkcie porażki odkryłem, że system głębokości jest interpolacyjny i bazuje na dwóch całkowicie różnych, przeciwnych promptach. Te dwa prompty są interpolacyjne i współpracujące. Jak ustala ich wykorzystanie, nie wiem, ale dziś będę czytał prace, by zrozumieć matematykę.
Test 2 - 10 obrazów:
UNET LR - 0.001 <<< bardzo silny LR
256x256, 512x512, 768x768, 1024x1024
Początkowe kroki wykazywały odchylenia, podobne do wypalenia w testach SD3. Nie było dobrze. Krwawe plamy zaczynały się około kroku 500. Do 1000 praktycznie bezużyteczne. Wiem, że używam repeat, ale to był dobry eksperyment i porażka.
Odchylenia bardzo szkodliwe. Wprowadza nowy kontekst, a potem zamienia go w automat z przekąskami. Zastępuje ludzkie elementy bezwartościowymi lub spalonymi artefaktami podobnie jak źle ustawione inpainty. Fascynujące, jak stabilny jest FLUX mimo prób niszczenia.
To była porażka, potrzebne dalsze testy z innymi ustawieniami.
Test 3 - 500 obrazów z pozami:
UNET LR - 4e-4 <<< powinno to być podzielone przez 4 i dać dwukrotnie więcej kroków.
Pełny bucketing - 256x256, 256x316 itd. Dałem różne rozmiary i pozwoliłem na bucketing. Wynik był zaskakujący.
To jest dosłownie rdzeń modelu consistency, tak silny efekt otrzymałem. Wydaje się, że efekt był bardziej szkodliwy niż myślałem, ale to było coś ważnego.
Anime zazwyczaj nie używa głębi ostrości. Ten model WZRASTA przy użyciu głębi ostrości i rozmycia do rozróżniania głębi. Potrzebny jest typ depth controlnet do tych obrazów, ale nie wiem dokładnie jak to zrobić. Trening map głębi wraz z mapami normalnymi może pomóc, ale może też zniszczyć model, bo nie ma negatywnego promptu.
Potrzebne są dalsze testy, więcej danych treningowych i informacji.
Test 4 - 5000 zestawów consistency:
UNET LR - 4e-4 <<< podzielone przez 40 i 20x więcej kroków. Trening tego rdzenia nie jest prosty ani szybki. Matematyka nie jest dobra przy obecnym procesie, więc zrobiłem i opublikowałem pierwsze wyniki.
Napisałem tu duży rozdział i część następną, ale kliknąłem cofnij i straciłem pracę, więc muszę pisać od nowa.
Duże porażki:
Learning rate był ZA WYSOKI dla moich początkowych lór po 12k kroków. Cały system bazuje na uczeniu gradientowym, ale prędkość nauczania była ZA WYSOKA, by zatrzymać informacje bez uszkodzenia modelu. Innymi słowy, nie spaliłem ich, tylko nauczyłem model czegoś innego niż chciałem. Problem w tym, że nie wiedziałem, czego chcę, więc cały system opierał się na rzeczach bez kierunku i bez gradientowej głębi. Był skazany na porażkę, niezależnie od kroków.
Styl dla FLUX nie jest tym, co ludziom się wydaje na podstawie PDXL i SD1.5. System gradientów stylizuje, ale cała struktura cierpi, gdy nakłada się ZA DUŻO informacji zbyt szybko. To jest BARDZO destrukcyjne, w odróżnieniu od PDXL lór, które były bardziej uzupełnieniem tego, co istnieje. One bardziej WZMACNIAJĄ to, co jest, niż uczą całkiem nowych rzeczy.
Kluczowe ustalenia:
ALFA, ALFA i JESZCZE WIĘCEJ ALFY<<<< System opiera się mocno na gradientach alfa. Wszystko MUSI być specjalnie obsługiwane pod kątem gradientów alfa na podstawie detali fotograficznych. Dystans, głębia, proporcje, rotacja, przesunięcia itd. to kluczowe elementy składowe modelu i by stworzyć poprawny stylizator kompozycji, potrzeba tych detali więcej niż w jednym promcie.
WSZYSTKO musi być dobrze opisane. Proste tagowanie danbooru to właściwie tylko styl. Zmuszasz system do rozpoznawania stylu, więc nie możesz narzucać nowych pojęć bez odpowiednich tagów powiązania konceptu. Inaczej styl i łączenie konceptów zawiodą, dając śmieciowe wyjście.
Trening póz jest BARDZO skuteczny przy dużej liczbie informacji o pozy. System już rozpoznaje większość tagów, po prostu nie znamy jeszcze ich zakresu. Trening póz do łączenia tego co JEST z tym co CHCESZ za pomocą specyficznych tagów będzie bardzo skuteczny w organizacji tagów i dopracowaniu.
Dokumentacja kroków;
v2 - 5572 obrazów -> 92 pozy -> 4000 kroków FLUX
Oryginalny cel przeniesienia NAI do SDXL został też zastosowany dla FLUX. Czekaj na kolejne wersje.
Potrzebne testy stabilności, na razie pokazuje się duża zdolność przewyższająca PDXL. Potrzebuje dodatkowego treningu, ale jest znacznie silniejszy niż oczekiwano przy tak niskiej liczbie kroków.
Uważam, że pierwsza warstwa treningu póz to około 500 obrazów, więc to ma największe znaczenie. Pełne dane treningowe będą opublikowane na HuggingFace, gdy uporządkuję zestawy i liczbę. Nie chcę publikować złych obrazów ani śmieci.
Kontynuuj czytanie tutaj:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
Ważne odnośniki:
Nie palę, ale FLUX czasem potrzebuje papierosa.
Workflow i asystent generowania obrazów. Korzystam głównie z podstawowych węzłów ComfyUI, ale ciągle eksperymentuję i zapisuję.
Bardzo potężny i trudny do zrozumienia model AI o ogromnym potencjale.
Bez nich nigdy bym tego nie zrobił. Wielkie dzięki dla całego personelu NAI za ciężką pracę, potężną maszynę do generowania obrazów i cudownego asystenta pisania. Rzuć im kasę.
Stworzyli flux i zasługują na ogromną cześć zasług za elastyczność modelu. Ja po prostu dopracowuję i kieruję ten lewiatan ku celowi.
Bardzo potężny asystent tagów. Prawie napisałem własnego, zanim znalazłem tę potęgę.
Narzędzie, którego użyłem do trenowania wersji Flux. Trochę kapryśne, ale działa na wielu systemach i spełnia zadanie.
Nie można zapomnieć rywala na polu bitwy. Potwór potężny w generowaniu obrazów z dużym gradientem, cenna pomoc badawcza i inspiracja dla tego kierunku i postępu.

Szczegóły modelu
Typ modelu
Model bazowy
Wersja modelu
Hash modelu
Twórca
Dyskusja
Proszę się log in, aby dodać komentarz.
![Old Consistency V32 Lora [FLUX1.D/PDXL] Feminine v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































