Animagine XL 4.0 - v4 Opt
Palavras-chave e Tags Relacionadas
Imagens em destaque





Prompts Recomendados
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
Prompts Negativos Recomendados
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
Parâmetros Recomendados
samplers
steps
cfg
resolution
Dicas
Use legendas baseadas em tags com o método de ordenação de tags para melhores resultados: 1girl/1boy/1other, nome do personagem, série, classificação, outras tags, depois aprimoramento de qualidade.
Adicione tags de aprimoramento de qualidade no final do prompt: masterpiece, high score, great score, absurdres.
Use prompts negativos recomendados para evitar artefatos e erros indesejados.
A escala CFG ótima está entre 4 e 7, 5 é recomendado.
Passos de amostragem ideais entre 25 e 28, com 28 recomendado.
Sampler preferido é Euler Ancestral (Euler a).
Observe limitações do modelo como dificuldade com anatomia complexa e renderização de texto.
Personagens recentes podem ter menor precisão devido a dados limitados de treinamento.
Destaques da Versão
Com o lançamento do Animagine XL 4.0 Opt (Otimizado), o modelo foi ainda mais refinado com um conjunto de dados adicional, melhorando seu desempenho para uso geral. Esta atualização traz várias melhorias:
Melhor estabilidade para saídas mais consistentes
Anatomia aprimorada com proporções mais precisas
Redução de ruído e artefatos nas gerações
Correção de problemas de baixa saturação, resultando em cores mais ricas
Melhoria na precisão das cores para resultados visualmente mais atraentes
Patrocinadores do Criador
Apoie o desenvolvimento do Animagine XL
- Doe ETH/USDT para
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - GitHub Sponsors: https://github.com/sponsors/cagliostrolab/
- Junte-se à comunidade Discord: https://discord.gg/cqh9tZgbGc
Por favor, leia nosso Guia detalhado para prompts no Blog Cagliostrolab
Visão geral
Animagine XL 4.0, também estilizado como Anim4gine, é o modelo finalizado definitivo do SDXL temático de anime e a edição mais recente da série Animagine XL. Embora seja uma continuação, o modelo foi re-treinado a partir do Stable Diffusion XL 1.0 com um imenso conjunto de dados de 8,4 milhões de imagens em estilo anime diversificadas de várias fontes, com corte de conhecimento em 7 de janeiro de 2025, e afinado por aproximadamente 2650 horas de GPU. Semelhante à versão anterior, este modelo foi treinado utilizando o método de ordenação de tags para o treinamento de identidade e estilo.
Com o lançamento do Animagine XL 4.0 Opt (Otimizado), o modelo foi ainda mais refinado com um conjunto de dados adicional, melhorando a estabilidade, precisão anatômica, redução de ruído, saturação de cor e precisão geral das cores. Essas melhorias tornam o Animagine XL 4.0 Opt mais consistente e visualmente atraente mantendo a qualidade característica da série.
Registro de alterações
- 2025-02-13 – Adicionados Animagine XL 4.0 Opt e Animagine XL 4.0 Zero
Melhor estabilidade para saídas mais consistentes
Anatomia aprimorada com proporções mais precisas
Redução de ruído e artefatos nas gerações
Correção de problemas de baixa saturação, resultando em cores mais ricas
Melhoria na precisão das cores para resultados visualmente mais atraentes
- 2025-01-24 – Lançamento inicial
Detalhes do modelo
Desenvolvido por: Cagliostro Research Lab
Tipo de modelo: Modelo generativo de texto para imagem baseado em difusão
Licença: CreativeML Open RAIL++-M
Descrição do modelo: Modelo que pode ser usado para gerar e modificar imagens especificamente temáticas de anime baseadas em prompt de texto
Afinado a partir de: Stable Diffusion XL 1.0
Diretrizes de uso
O resumo pode ser visto na imagem para a diretriz de prompts.

1. Estrutura do Prompt
O modelo foi treinado com legendas baseadas em tags e o método de ordenação de tags. Use este template estruturado:
1girl/1boy/1other, nome do personagem, de qual série, classificação, tudo o mais em qualquer ordem e termine com aprimoramento de qualidade
2. Tags para Aprimoramento de Qualidade
Adicione estas tags ao final do seu prompt:
masterpiece, high score, great score, absurdres
3. Prompt Negativo Recomendado
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Configurações Ótimas
CFG Scale: 4-7 (5 recomendado)
Passos de Amostragem: 25-28 (28 recomendado)
Sampler Preferido: Euler Ancestral (Euler a)
5. Resoluções Recomendadas
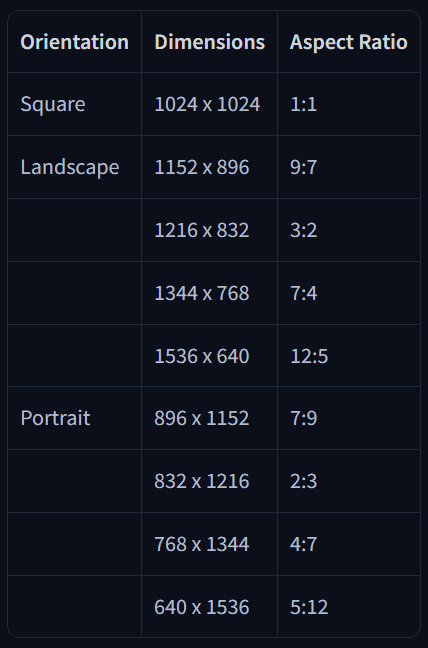
6. Exemplo de Estrutura Final do Prompt
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, seguro, casual, solo, olhando para o espectador, ao ar livre, sorriso, estendendo a mão para o espectador, noite, masterpiece, high score, great score, absurdres
Tags Especiais
O modelo suporta diversas tags especiais que podem ser usadas para controlar diferentes aspectos do processo de geração de imagens. Essas tags são cuidadosamente ponderadas e testadas para fornecer resultados consistentes em diferentes prompts.
Tags de Qualidade
Tags de qualidade são controles fundamentais que influenciam diretamente a qualidade geral da imagem e o nível de detalhes. Tags de qualidade disponíveis:
masterpiecebest qualitylow qualityworst quality
Tags de Pontuação
Tags de pontuação oferecem um controle mais sutil sobre a qualidade da imagem comparado às tags básicas de qualidade. Elas têm um impacto mais forte na direção da qualidade de saída neste modelo. Tags de pontuação disponíveis:
high scoregreat scoregood scoreaverage scorebad scorelow score
Tags Temporais
As tags temporais permitem influenciar o estilo artístico baseado em períodos específicos ou anos. Isso pode ser útil para gerar imagens com características artísticas específicas de uma era. Tags de ano suportadas:
year 2005year {n}year 2025
Tags de Classificação
Tags de classificação ajudam a controlar o nível de segurança do conteúdo das imagens geradas. Essas tags devem ser usadas de forma responsável e em conformidade com as leis aplicáveis e políticas das plataformas. Classificações suportadas:
safesensitivensfwexplicit
Informações de Treinamento
O modelo foi treinado utilizando hardware de ponta e hiperparâmetros otimizados para garantir a mais alta qualidade de saída. Abaixo estão as especificações técnicas detalhadas e parâmetros usados durante o processo de treinamento:

Agradecimentos
Este projeto de longo prazo não teria sido possível sem o trabalho inovador, contribuições pioneiras e documentação abrangente fornecidos pela Stability AI, Novel AI e Waifu Diffusion Team. Somos especialmente gratos pela bolsa kickstarter da Main que nos permitiu avançar além da V2. Nesta iteração, gostaríamos de expressar nossa sincera gratidão a todos na comunidade pelo apoio contínuo, especialmente:
Moescape AI: Nosso parceiro de colaboração inestimável na distribuição e teste do modelo
Lesser Rabbit: Por fornecer bolsas essenciais para computação e pesquisa
Kohya SS: Por desenvolver o abrangente framework de treinamento open-source
discus0434: Por criar o Aesthetic Predictor 2.5 open-source líder na indústria
Testadores iniciais: Pelo compromisso em fornecer feedback crítico e garantia rigorosa de qualidade
Contribuidores
Estendemos nosso sincero agradecimento aos membros dedicados da equipe que contribuíram significativamente para este projeto, incluindo, mas não se limitando a:
Modelo
Gradio
Relações, finanças e garantia de qualidade
Dados
Arrecadação de fundos está aberta novamente!
Estamos animados para apresentar novos métodos de arrecadação através do GitHub Sponsors para apoiar o treinamento, pesquisa e desenvolvimento do modelo. Seu apoio nos ajuda a ultrapassar os limites do que é possível com IA.
Você pode nos ajudar com:
Doar: Contribua via ETH ou USDT para o endereço abaixo.
Compartilhar: Divulgue nossos modelos e compartilhe suas criações!
Feedback: Nos informe como podemos melhorar.
Endereço para Doação:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
Github Sponsor: https://github.com/sponsors/cagliostrolab/
Por que usamos criptomoedas?:
Quando inicialmente abrimos arrecadação via Ko-fi e usando PayPal como método de retirada, nossa conta PayPal foi sinalizada e acabou banida, apesar de nossos esforços para explicar o propósito do projeto. Infelizmente, isso nos forçou a reembolsar todas as doações e nos deixou sem maneira confiável de receber apoio. Para evitar esses problemas e garantir transparência, agora usamos criptomoedas para arrecadação de fundos.
Quer doar em moeda não criptográfica?
Embora tenhamos tido uma experiência ruim com PayPal e você queira nos apoiar mas prefira não usar criptomoedas, sinta-se à vontade para entrar em contato conosco via Servidor Discord para métodos alternativos de doação.
Junte-se ao nosso Servidor Discord
Sinta-se à vontade para participar do nosso servidor discord: https://discord.gg/cqh9tZgbGc
Limitações
Formato do Prompt: Limitado a prompts textuais baseados em tags; entrada em linguagem natural pode não ser eficaz
Anatomia: Pode apresentar dificuldades com detalhes anatômicos complexos, particularmente poses das mãos e contagem de dedos
Geração de Texto: Renderização de texto em imagens não é suportada atualmente e não é recomendada
Novos Personagens: Personagens recentes podem ter menor precisão devido à disponibilidade limitada de dados de treinamento
Múltiplos Personagens: Cenas com múltiplos personagens podem exigir engenharia cuidadosa dos prompts
Resolução: Resoluções mais altas (ex.: 1536x1536) podem apresentar degradação já que o treinamento usou resolução original do SDXL
Consistência de Estilo: Pode exigir tags de estilo específicas pois o treinamento focou mais na preservação da identidade do que na consistência do estilo
Licença
Este modelo adota a original CreativeML Open RAIL++-M License da Stability AI sem modificações ou restrições adicionais. Os termos da licença permanecem exatamente como especificados na licença original do SDXL, que incluem:
✅ Permitido: Uso comercial, modificações, distribuições, uso privado
❌ Proibido: Atividades ilegais, geração de conteúdo nocivo, discriminação, exploração
⚠️ Requisitos: Incluir cópia da licença, declarar alterações, preservar avisos
📝 Garantia: Fornecida "NO ESTADO EM QUE SE ENCONTRA" sem garantias
Consulte a licença original do SDXL para os termos e condições completos e oficiais.

Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Criador
Discussão
Por favor, faça log in para deixar um comentário.
Coleção de Modelos - Animagine XL 4.0
Imagens por Animagine XL 4.0 - v4 Opt
Imagens com anime










Imagens com modelo base

Imagens com sdxl


