Colossus Project Flux - v10_Behemoth_AIO_FP16
Palavras-chave e Tags Relacionadas
Imagens em destaque

Prompts Recomendados
photography of a young woman as an (goth) with (razor cut haircut), a sports car, soft lighting, spray painted with a intricate comic style robot theme and "COLOSSUS X" cyberpunk theme, projection lighting, its night and its raining, biopunk, the road is reflecting shot on Pentax K-1 Mark II with Pentax FA 43mm f-1.9 Limited, Neutral color palette heterochromia (blue and brown) Mixed race, shot on Pentax K-1 Mark II with Pentax FA 43mm f-1.9 Limited, photo by Tami Bone
Prompts Negativos Recomendados
blurry
blurry, low res
Parâmetros Recomendados
samplers
steps
cfg
resolution
vae
Dicas
Use o termo negativo 'blurry' para melhorar a qualidade da imagem.
Para melhor realismo, use orientação cfg entre 1.5 e 3, com 1.8 como bom equilíbrio para imagens realistas.
Samplers preferidos incluem Euler, Heun, DPM++ 2M, deis e DDIM, com o agendador Simple funcionando bem.
Para alguns checkpoints, desligar a escala Flux guidance e usar a escala cfg é necessário.
Use modelos all-in-one para facilidade, pois eles têm Clip_L, T5xxl e VAE integrados.
Para instalação e fluxo de trabalho, consulte os guias oficiais nos links civitai.com na descrição.
Existem duas versões quantizadas FP4 e int4: FP4 para GPUs Nvidia 50xx, int4 para GPUs 40xx e inferiores (mínimo da série 20xx).
A quantificação SVDQ Nunchaku reduz drasticamente o tamanho do modelo enquanto acelera a geração com pequena perda de qualidade.
Destaques da Versão
Esta versão ainda é experimental. O foco principal foi obter resultados mais realistas. Também consegui reduzir algumas "Linhas Flux". Esta coisa é baseada no Colossus Project V5.0_Behemoth, V9.0 e outro projeto que chamo de "Ouroborus Project"
A versão FP16 é muito estável. Também estou lançando uma versão FP8 em breve. Esta versão também é muito boa, mas não tão estável...
Deixo você experimentar... Me diga o que acha desta versão.
Divirta-se criando :-)
Patrocinadores do Criador
Se você gosta deste modelo e quer apoiar o trabalho do criador, considere fazer uma doação via Ko-fi.
Confira a quantificação feita por Muyang Li da Nunchakutech para as versões FP4/int4.
Guias de fluxo e instalação estão disponíveis em civitai.com/articles/17313 e civitai.com/articles/17358.
Visite o repositório de conversão e quantificação: GitHub ComfyUI-nunchaku.
Nas profundezas de uma montanha vive um gigante adormecido, capaz tanto de ajudar a humanidade quanto de criar destruição...
Um Colosso surge...
Após minha série SDXL, é hora da série FLUX deste Projeto... Desta vez treinei isso do zero. Para o treinamento usei minhas próprias imagens. Criei-as com meu modelo schnell Flux DemonFlux/Colossus Project schnell + meu SDXL Colossus Project 12 como refinador.
Este checkpoint SD Flux é capaz de produzir quase tudo... Colossus é muito bom em criar imagens extremamente realistas, anime e artísticas.
Se gostar, fique à vontade para me dar algum feedback. Também, se quiser me apoiar, pode fazer isso aqui. Gastei um bom dinheiro para montar um computador capaz de realmente treinar modelos Flux... Além disso, treinamento e testes consomem muito tempo e eletricidade...
https://ko-fi.com/afroman4peace
Versão V12 "Hephaistos"
Publicar este checkpoint me deixa feliz e triste ao mesmo tempo... V12 será o último checkpoint desta série... O principal motivo são as futuras leis europeias de IA... Outro motivo é a licença do próprio Flux .1 DEV. Obrigado a todos pelo suporte! Dediquei muito tempo a este projeto ao longo do último ano. Agora é hora de seguir para outro projeto.
De qualquer forma... vou terminar esta série em alto nível...
V12 é baseado no V10B "BOB", mas recebeu basicamente as melhores partes desta série integradas neste único checkpoint. (Foi resultado de um novo método de merge que levou cerca de 1h30 para ser feito e consumiu toda a minha RAM de 128GB). Também melhorei as texturas de rosto e pele em comparação ao V10. Os olhos estão muito mais realistas e vivos do que antes.
Teste você mesmo e me dê feedback sobre o V12. "Obrigado" à minha conexão lenta de internet, primeiramente irei fazer upload do FP8_UNET. Depois virá a versão FP8 "all in one" e então o FP16_unet e FP16_BEHEMOTH. Também tentarei convertê-lo para int4 e fp4 (desejem-me sorte).
Como sempre, me dê algum feedback sobre o V12...
Versão V12 "Behemoth" (AIO)
Este modelo "all in one" é o melhor da minha série V12... e o maior em tamanho, claro :-)
O Behemoth possui um T5xxl e Clip_l customizados integrados no modelo. Se você prefere qualidade a quantidade, este é o checkpoint para você!
Versão V12 FP4/int4
Obrigado a Muyang Li da Nunchakutech, que fez a quantificação do V12. https://huggingface.co/nunchaku-tech e seus incríveis nunchaku!
Esta versão é verdadeiramente impressionante. Combina qualidade com velocidade inédita.
ATENÇÃO!
Existem duas versões FP4 e int4. FP4 é apenas para placas gráficas Nvidia 50xx! Enquanto int4 funciona com 40xx e inferiores. (é necessário pelo menos uma placa de vídeo série 20xx)
Você também pode baixar ambas as versões diretamente aqui: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
GUIA DE INSTALAÇÃO e FLUXO DE TRABALHO
Aqui está um guia rápido de instalação e um fluxo de trabalho em andamento.
https://civitai.com/articles/17313
GUIA DETALHADO para o fluxo de trabalho
https://civitai.com/articles/17358
Ainda estou trabalhando nos meus novos fluxos de trabalho para Nunchaku... então o fluxo a seguir ainda está em andamento (work in progress). Vou adicionar um artigo detalhado no fim de semana.
Versão V12 FP16_B_variant
Devido a um pequeno erro que cometi tarde da noite (2h da manhã), renomeei e fiz upload do checkpoint "errado". É um checkpoint muito experimental, nunca pensado para ser publicado. Não foi muito testado, mas teve um desempenho muito bom quando criei a demonstração. Pode ser até melhor do que a versão padrão.
Ele tende a favorecer mais rostos asiáticos... Isso porque quis testar algo para misturar em um projeto paralelo que ainda estou desenvolvendo. Conte-me sua experiência com este checkpoint :-)
Versão V12 AIO FP8
Esta versão é uma versão all in one do V12. Isso significa que todos os clips estão integrados. Ela dará a mesma saída que o FP8_unet com meu clip_l customizado.
Versão V12 GGUF Q5_1
Esta versão foi um pedido. Não é ruim em qualidade...
Versão V10B "BOB"
Esta é uma versão alternativa do V10. Criei ela para melhorar a versão FP8 do V10. Em geral, a versão FP8 é mais precisa e as cores são melhores. Infelizmente, não tenho tido muito tempo recentemente... (a vida real vem primeiro). Por isso demorou tanto... Me avise se preferir esta versão. Também tenho uma versão FP16 do "BOB". Dependendo do feedback, considerarei publicar uma versão int4.
FLUXO DE TRABALHO:
Aqui está o fluxo de trabalho para V12 e V10: https://civitai.com/articles/17163
Versão V10_int4_SVDQ "Nunchaku"
Primeiro quero agradecer ao theunlikely https://huggingface.co/theunlikely que converteu o FP16_Unet para int4_SVDQ. Visite a página dele e deixe um like.
Esta versão é mais ou menos igual à versão FP8. Mesmo no modo normal dentro do meu fluxo, ela é cerca de 2X-3X mais rápida que o modelo regular. Com o "modo rápido" do fluxo posso renderizar uma imagem 2MP em aproximadamente 19 segundos com minha 3090ti.
O que é SVDQ "Nunchaku"?
Este novo método de quantificação permite reduzir modelos Flux (neste caso um modelo FP16 nativo) de 24GB para cerca de 6,7GB. Mas não é só isso: pode gerar imagens mais rápido do que nunca sem perder muita qualidade. Claro que você verá uma pequena diferença comparado ao meu 32GB_Behemoth, mas para este modelo você precisará de muito mais VRAM/RAM para rodar.
Para mais informações visite: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Instalação: Por favor visite meu guia de instalação/fluxo: https://civitai.com/articles/15610
Versão V10 "Behemoth" (FP16_AIO)
Esta versão ainda é experimental. O foco principal foi obter resultados mais realistas. Também consegui reduzir algumas "Linhas Flux". Esta coisa é baseada no Colossus Project V5.0_Behemoth, V9.0 e outro projeto que chamo de "Ouroborus Project"
A versão FP16 é muito estável. Também estou lançando em breve uma versão FP8. Esta versão também é muito boa, mas não tão estável...
Deixo você experimentar... Me diga o que acha desta versão.
Divirta-se criando :-)
Versão V9.0:
Bem, preciso explicar muito... Primeiro, por que é V9.0?
Recentemente me mudei para um apartamento novo e, devido a erros do provedor de internet, não tinha conexão real... Então, enquanto fazia mudança... deixei meu computador ligado. O resultado foi a criação de muitos checkpoints (a maioria com problemas). Tenho versões V8 muito boas que talvez publique também...
O que mudou?
Treinei novos rostos e texturas de pele no modelo, basicamente pegando os melhores resultados do V5.0. Também treinou pés/pernas para melhor anatomia. As versões V5.0 às vezes cortavam a cabeça e os pés... Acho que consegui corrigir alguns desses problemas...
Além disso, treinei com mais imagens próprias de paisagens... E sim, fiz tudo isso enquanto me mudava de apartamento... Acho que o tempo total de treinamento foi cerca de 2 semanas de computação, o que não é barato... (cada hora basicamente custa uns 25 centavos em eletricidade)
De qualquer forma, espero que gostem desta versão... Se quiser me apoiar: Poste algumas imagens legais ou talvez faça uma doação no buzz ou no Ko-fi...
Conte-me o que acha :-)
Versão 5.0:
O V5.0 é baseado nas versões V4.2 e V4.4 (que também serão lançadas em breve). Recebeu treinamento adicional em detalhes de pele e anatomia em geral, corrigindo principalmente mãos e mamilos. Os detalhes do rosto estão muito melhores. Também tentei corrigir algumas linhas flux menores...
Em geral, esta versão é mais realista que o V4.2 e melhor nos detalhes menores... Como a versão 4.2, esta também é um modelo híbrido de de-distillation. Você pode usá-lo basicamente com as mesmas configurações do V4.2.
Aqui também está um novo fluxo de trabalho para experimentar: https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Conte-me sua opinião comparando com a versão 4.2 ou V2.1...
Versão 4.4 "Research":
Adicionei esta versão apenas para completar... É ligeiramente mais realista que o V4.2 e a base da versão 5.0. Você pode testá-la à vontade. Também pode usar o fluxo de trabalho do V5.0 e V4.2...
Versão 4.2:
Esta versão é basicamente um desenvolvimento do Demoncore Flux e Colossus Project Flux. O objetivo foi obter um resultado mais estável com melhor textura de pele, mãos melhores e mais variedade de rostos. Treinei um modelo híbrido que é parcialmente Demoncore Flux. Também melhorei um pouco os mamilos e NSFW. Me diga se prefere o V4.2 ao invés da versão 2.1 :-)
Para as imagens da demonstração: usei apenas imagens nativas com resolução SDXL ou 2MP (por exemplo 1216x1632). Este modelo suporta resoluções ainda maiores... Testei este checkpoint até 2500x2500 mas recomendo cerca de 2000x2000.
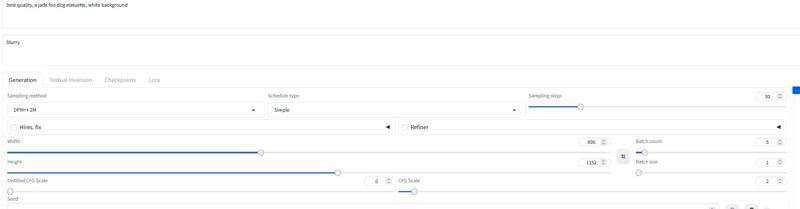
Para configurações recomendo cerca de 30 passos e cfg entre 2-2.5. Costumo usar 2.2 ou 2.3 no meu fluxo de trabalho. Para a demonstração usei DPM++ 2M com agendador Simple.
Em breve adicionarei mais versões, mas não tenho muito tempo antes do Natal...
Configurações
Em breve adicionarei um fluxo de trabalho dedicado para Comfy. Por enquanto pode baixar e abrir as imagens de demonstração...
A versão "All in One" também funciona bem com Forge...
Basicamente, funciona com as mesmas configurações da versão 2.1 (veja abaixo)
Use 20-30 passos com cfg em torno de 2.2...
Versão 2.1_de-distilled_experimental (MERGE)
Esta versão é completamente diferente e funciona de forma diferente de um modelo Flux normal!
É uma fusão experimental entre minha versão 2.0 e uma versão de-distilled https://huggingface.co/nyanko7/flux-dev-de-distill. Foi um acidente, mas os resultados são impressionantes. Produz detalhes incríveis. Segue perfeitamente as instruções... Próximo passo será treinar diretamente no modelo de-distilled. Já fiz alguns testes de Loras com ele. É altamente experimental, portanto por favor me avise se encontrar erros que não estão listados abaixo. Se tiver boas imagens, poste-as, poste também as ruins, isto ajuda a melhorar :-). Talvez tente também a versão 2.0 e me diga qual tipo de checkpoint você prefere.
!Atenção!
O fluxo Flux normal não funciona com esta versão. VOCÊ PRECISA baixar meu fluxo de trabalho para ela!
Também pode tentar descobrir algo você mesmo, mas por favor não me culpe por imagens ruins. Este é um modelo altamente experimental... veja as desvantagens abaixo...
Vantagens e desvantagens deste checkpoint:
Este checkpoint pode criar detalhes extremos... Isso tem um preço... É lento comparado aos checkpoints Flux normais. A vantagem é que muitas vezes você não precisará aumentar a resolução adicionalmente. Em vez de usar Flux Guidance, este modelo usa a escala cfg. O que também significa que não funciona com fluxos de trabalho padrão.
Você pode usar prompts negativos! Isso ajuda a remover elementos indesejados da imagem.
Às vezes podem aparecer artefatos... Pode resolver fazendo um pequeno upscale simples (estou trabalhando nisso). Aqui está um exemplo... Estranhamente não acontece com todas as seeds... ATUALIZAÇÃO: Não é um problema do modelo, mas do fluxo. Estou trabalhando para corrigir. Se acontecer, tente definir o primeiro upscale para 1.14 em vez de 1.2.

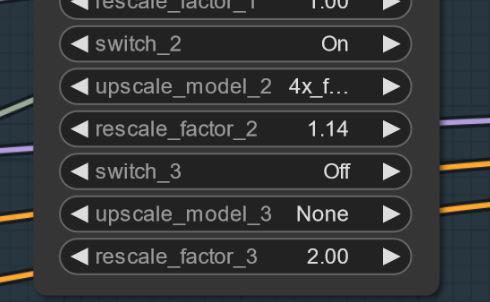
Configurações e fluxo V2.1:
Aqui você encontra o fluxo de trabalho: https://civitai.com/articles/8419
Configurações: diferente do Flux normal, não precisa da escala Flux Guidance. Use a cfg. Uso geralmente 3 cfg no fluxo... Algumas imagens podem exigir escalas cfg menores
O mais importante provavelmente é desligar a escala Flux Guidance...
Sem o fluxo, testei com 30 passos e 2-3 cfg. Essas também podem ser configurações para Forge. Experimente aí.
Recomendo usar a palavra "blurry" no negativo
Samplers e agendadores:
Você pode escolher entre vários samplers compatíveis:
Euler, Heun, DPM++2m, deis, DDIM funcionam muito bem.
Eu uso principalmente "simple" como agendador
Se encontrar configurações melhores, me avise.. :-)
Para Forge recomendo o modelo AIO.. aqui está um exemplo de configuração para Forge
Versão 2.0_dev_experimental
Bem... esta é uma versão experimental... O objetivo era criar um modelo mais coerente e rápido. Treinei algumas loras próprias adicionais e então uni os modelos resultantes de uma forma especial (merging tensorial). Ele tem um T5xxl customizado que modifiquei com "Attention Seeker". Para ganhar velocidade e qualidade adicional, uni a lora Hyper Flux do ByteDance. Isso mudou a área de trabalho... Vou mostrar o que isso significa... Aqui está a imagem principal do título...
16 passos V 2.0
 30 passos V 1.0
30 passos V 1.0
 Desvantagens:
Desvantagens:
Primeiro... esta versão é um pouco maior que a anterior... segundo, ainda preciso criar a versão apenas Unet. Atualizarei quando estiver pronta...
Configurações e fluxo V2.0:
Você pode rodar o modelo agora com menos passos... 16 passos equivalem a 30 passos do modelo antigo.
Recomendo usar entre 20 e 30 passos para mais qualidade na maioria dos casos.
Sampler: prefiro Euler com Simple como agendador. A orientação pode ser ajustada entre 1.5 e 3 (sinta-se livre para testar fora dessa faixa). Uma orientação de 1.8 funciona bem para imagens realistas. Pode testar outros samplers também. DPM++2M e Heun funcionam muito bem.
Fluxo 2.0:
Criei um novo fluxo para V2.0 e V1.0. Ele tem um novo Flux Prompt Generator. Além disso, ativei o segundo estágio de upscaler. https://civitai.com/articles/7946
Forge:
Também testei este modelo com Forge e funcionou muito bem... As imagens podem variar entre Comfy UI e Forge...
Versão 1.0_dev_beta:
Este modelo é minha primeira entrada da série. Então por favor me dê algum feedback e poste imagens. Isso me ajuda a melhorar este projeto. Existem várias versões para escolher. O melhor modelo em qualidade é a versão FP16. Bem, a versão FP16 é grande e precisa de uma placa de vídeo potente e muita RAM. A versão FP8 é a que considero um bom equilíbrio entre qualidade e desempenho. Se quiser a versão GGUF, baixe a Q8_0. A versão GGUF Q4_0/4.1 foi um pedido. São pequenas, mas perdem um pouco de qualidade.
Basicamente, existem dois tipos de meus modelos: os "All in one", que precisam baixar apenas um arquivo. Ele contém Clip_l, T5xxl fp8 e VAE integrados. (veja abaixo). Coloque estes na pasta checkpoints.
As outras versões são apenas UNET-ONLY. Aqui você precisa carregar todos os arquivos separadamente.
Em qualquer caso, você precisa baixar meu Clip_L para que funcionem corretamente...
Também é importante escolher o T5xxl clip correto. Para a versão FP8 é o fp8_e4m3fn t5xxl clip. Para o FP16 é o clip FP16. Certifique-se de selecionar o peso padrão. (imagem de exemplo da versão fp8 abaixo)
Para a versão GGUF você precisa do loader GGUF!
Algumas coisas conhecidas por enquanto sobre a V1.0:
Este é apenas o primeiro modelo da série, então no momento pode ter dificuldades com alguns prompts ou estilos como arte. A próxima versão terá mais treinamento. Me conte o que o modelo não consegue fazer...
Configurações e fluxo:
Testei com cerca de 30 passos, Euler com Simple como agendador. A orientação pode variar entre 1.5 e 3 (sinta-se livre para testar fora dessa faixa)
Uma orientação de 1.8 funciona bem para imagens realistas.
Sinta-se livre para experimentar essas configurações... Se conseguir bons resultados, poste-os.
Incluí as imagens da demonstração como dados de treinamento... Aqui está o fluxo para Comfy. Baixe o fluxo em: https://civitai.com/articles/7946
Modelo "All in one":
UNET_only:
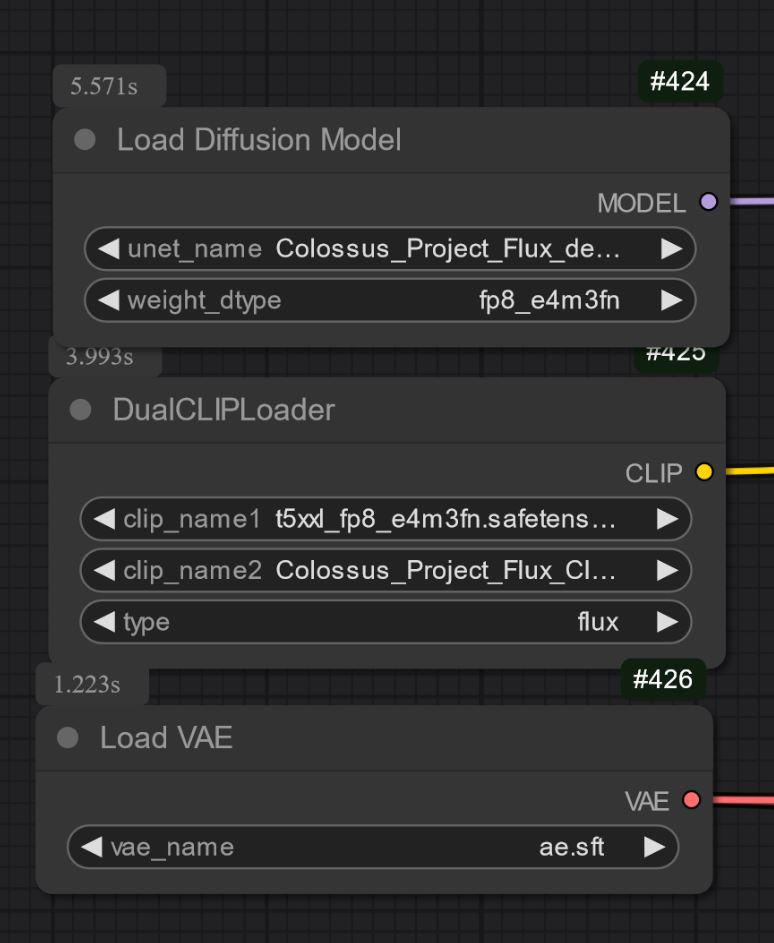 Você precisa baixar também o clip_L. É o arquivo de 240MB.
Você precisa baixar também o clip_L. É o arquivo de 240MB.
GGUF: Adicionei o fluxo de trabalho para GGUF aqui: https://civitai.com/articles/7946
Importante:
O modelo dev não é destinado ao uso comercial. Para isso publicarei o modelo "schnell" em outro lugar. É mais para uso pessoal ou científico.
LICENÇA:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
Créditos:
theunlikely https://huggingface.co/theunlikel (mais uma vez, obrigado)
Versões 2.1/V4.2/5.0: Flux_dev_de-distill do nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
Desde V2.0: Hyper Lora da ByteDance https://huggingface.co/ByteDance/Hyper-SD
Black Forrest pelo incrível modelo Flux https://huggingface.co/black-forest-labs

Detalhes do Modelo
Tipo de modelo
Modelo base
Versão do modelo
Hash do modelo
Criador
Discussão
Por favor, faça log in para deixar um comentário.
Coleção de Modelos - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8

Colossus Project Flux - v10_int4_SVDQ
















































