Colossus Project Flux - v12_int4_SVDQ_nunchaku
相關關鍵字和標籤
精選圖片



推薦反向提示詞
blurry
推薦參數
samplers
steps
cfg
resolution
提示
使用負提示詞“模糊”(blurry)來提升圖像清晰度。
對 FP4/int4 版本:FP4 僅限 Nvidia 50xx 顯卡,int4 支持 40xx 及以下(需至少 20xx 系列 GPU)。
V2.0 版本使用 Euler 采樣器搭配 Simple 調度器,效果最佳。
建議採用 20-30 步驟、約 2.2 cfg 值以獲得穩定品質。
“一體化”版本包含已烘焙 Clip_L、T5xxl fp8 與 VAE,使用更便捷。
SVDQ 量化可減少模型大小並加快生成速度,僅帶來最小質量損失。
版本亮點
注意!有兩個版本 FP4 與 int4。此 int4 版本支持 40xx 及以下,不支援 50xx!
感謝 Nunchakutech 的 Muyang Li 對 V12 的量化。https://huggingface.co/nunchaku-tech 及其驚人 nunchaku!
此版本令人震撼,質量與速度兼具,前所未見。
你也可直接在此下載兩版本:https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
安裝指南與工作流程
這裡有快速安裝指南及進行中的工作流程。
https://civitai.com/articles/17313
我仍在為 Nunchaku 開發新流程,以下流程仍在持續改進中(WIP),週末會補充詳細文章。
創作者贊助
如果你想支持 FLUX 模型創作者,歡迎在此捐助:https://ko-fi.com/afroman4peace
查看由 Nunchakutech 的 Muyang Li 轉換的 FP4/int4 版本:https://huggingface.co/nunchaku-tech
了解更詳盡的工作流程與安裝指引,請訪問 CivitAI:https://civitai.com/articles/17313, https://civitai.com/articles/17358
在深山之下,有一位沉睡的巨人,能助人類,也能帶來毀滅...
一尊巨像崛起...
繼我的 SDXL 系列後,是時候推出此項目的 FLUX 系列... 這次我從零開始訓練它。訓練資料來自我自己的圖像,這些圖像由我快速的 Flux 模型 DemonFlux/Colossus Project schnell 加上 SDXL Colossus Project 12 作為精煉器製成。
此 SD Flux-Checkpoint 幾乎能生成任何圖像......Colossus 在創造極為真實的照片、動漫及藝術風格上表現優異。
如果你喜歡它,歡迎給我反饋。如果想支持我,也可以在此支持。我花了不少錢打造能實際訓練 Flux 模型的電腦… 同時訓練與測試也消耗大量時間與電力…
https://ko-fi.com/afroman4peace
版本 V12 "Hephaistos"
發布此檢查點令我既開心又難過……V12 將是此系列的最後檢查點,主要原因是即將到來的歐盟人工智能法規……另一原因是 Flux .1 DEV 本身的授權。感謝大家支持!過去一年我投入大量時間於此專案,現在是時候轉向另一專案。
總之……我會為此系列劃下漂亮句點……
V12 建立於 V10B "BOB",但基本上是將該系列最佳部分以區塊合併方式整合入此檢查點。(這是新合併方法的成果,花費約1小時30分,耗盡我的 128GB 記憶體。)相比 V10,我也提升了面部及皮膚細節。眼睛比之前更真實、更有生命力。
親自試試並給我對 V12 的反饋。因我的網速慢,我會先上傳 FP8_UNET,再上傳 FP8 "all in one" 版本,然後是 FP16_unet 與 FP16_BEHEMOTH。也會嘗試轉換成 int4 與 fp4(請為我加油)。
一如既往,請給我 V12 反饋……
版本 V12 "Behemoth"(一體化)
這個“一體化”模型是我 V12 系列中最佳的……當然也是體積最大的 :-)
Behemoth 內建自訂 T5xxl 及 Clip_l。如果你偏好質量勝於數量,這就是你的檢查點!
版本 V12 FP4/int4
感謝 Nunchakutech 的 Muyang Li 對 V12 做出量化。https://huggingface.co/nunchaku-tech 以及他們驚人的 nunchaku!
此版本的震撼力十足,質量與速度兼具,前所未見。
注意!
有兩個版本:FP4 與 int4。FP4 僅支援 Nvidia 50xx 顯卡!而 int4 可用於 40xx 及以下系列。(你至少需要 20xx 系列顯卡)
你也可以直接在此下載兩個版本:https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
安裝指南與工作流程
這裡有快速安裝指南及進行中的工作流程。
https://civitai.com/articles/17313
我仍在為 Nunchaku 開發新流程,以下流程仍在持續改進中(WIP),週末會添加詳細文章。
版本 V12 FP16_B_variant
因我深夜(凌晨 2 点)犯小錯誤,錯誤命名並上傳了此檢查點。這是一個非常實驗性的檢查點、從未打算公開。測試不多,但展示時表現很棒。可能比標準版更優。
它傾向於亞洲面孔,因為我想測試融入我正在進行的副專案。告訴我你對此檢查點的感受 :-)
版本 V12 一體化 FP8
此版本為 V12 的一體化版。意味著所有 clip 均已烘焙在內。輸出與搭載我自訂 clip_l 的 FP8_unet 相同。
版本 V12 GGUF Q5_1
此版本按需求製作,質量也不錯。
版本 V10B "BOB"
這是 V10 的另一個版本。我創建它是為改善 V10 的 FP8 版本。整體而言,FP8 版本更精確,色彩更佳。可惜我最近沒太多時間(現實生活優先),因此此版本花了較久時間完成。告訴我你是否偏好此版本。我也有 "BOB" 的 FP16 版本。根據回饋,我會考慮發布 int4 版本。
工作流程:
以下是 V12 與 V10 的工作流程:https://civitai.com/articles/17163
版本 V10_int4_SVDQ "Nunchaku"
首先感謝 theunlikely https://huggingface.co/theunlikely 將 FP16_Unet 轉成 int4_SVDQ。請訪問他的頁面並點贊。
此版本或多或少與 FP8 版本相同。即使在我工作流程的普通模式下,此款速度約為常規模型的 2 至 3 倍……使用流程的“快速模式”,3090ti 約可在 19 秒內渲染一幅 2MP 圖像。
什麼是 SVDQ "Nunchaku"?
此全新量化方法可將 Flux 模型(本例為原生 FP16 模型)從 24GB 縮小至約 6.7GB。但不止於此:你能比以往更快生成圖像,且質量損失甚微。當然,與我的 32GB_Behemoth 會有小差異,但 Behemoth 需更大 VRAM/記憶體才能運行。
詳細資訊請訪問:https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
安裝:請查看我的工作流程/安裝指南:https://civitai.com/articles/15610
版本 V10 "Behemoth"(FP16_AIO)
此版本仍屬實驗性。主要目標是提升真實感。此外我減少了一些“Flux 線”。此作品基於 Colossus Project V5.0_Behemoth、V9.0 及另一專案「Ouroborus Project」。
FP16 版本非常穩定。我稍後也會發布 FP8 版本。FP8 版本也不錯,但穩定性較差。
歡迎你自行測試此版本,告訴我你的想法。
祝你創作愉快 :-)
版本 V9.0:
我得多說一些話……首先,為什麼是 V9.0?
我最近搬新公寓,因網路供應商的問題,我一度沒有真正連上網……搬家期間我讓電腦持續運行,結果製造了許多(大多破損)檢查點。不過我有些很好的 V8 版本,也可能會發布……
改進了什麼?
我將 V5.0 最佳結果重新訓練進模型,加入臉部與皮膚細節。模型還接受了腳部/腿部解剖訓練,提升結構。V5.0 有時候會截斷頭部與腳部,我想我修復了部分這類問題……
此外,我還用更多自身拍攝的風景圖片訓練它……是的,這全程我正搬新公寓……整體訓練約累積兩週計算時間,非常昂貴……(每小時電費約 0.25 美元)
無論如何,希望你喜歡此版本。如果願意支持我:分享美圖或在 Buzz、Ko-fi 給我小費……
請告訴我你的看法 :-)
版本 5.0:
V5.0 其實基於 V4.2 和即將發布的 V4.4,進行了皮膚細節和整體解剖學訓練,主要修正了手部和乳頭等問題。臉部細節表現大幅提升。我也試著修復一些細微的 Flux 線。
整體來說,此版本比 V4.2 更寫實,且細節更豐富……與 V4.2 類似,此版本也是混合去蒸餾模型,可採用與 V4.2 類似的設置。
這裡還有新工作流程可體驗:https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
告訴我你對比 V4.2 或 V2.1 版本的看法……
版本 4.4 "Research":
加此版本僅為補全……比 V4.2 稍寫實,也是 5.0 的基礎。你可以試試。亦可用於 V5.0 與 V4.2 的工作流程。
版本 4.2:
此版本基本是 Demoncore Flux 和 Colossus Project Flux 的進階版。目標是提升穩定性及皮膚質感,改良手部和面孔多樣性。訓練採用混合模型,部分為 Demoncore Flux。對乳頭和 NSFW 也稍作強化。告訴我你是否偏好 V4.2 而非 2.1 :-)
對於展示圖,我只用 SDXL 解析度或 2MP 解析度(如 1216x1632)之原生圖片。此模型能處理更高解析度,我曾測試最高至 2500x2500,但建議約以 2000x2000 為宜。
設定方面我推薦約 30 步驟與 2-2.5 cfg,多數時使用 2.2 或 2.3 作為默認。展示時我使用 DPM++ 2M 搭配 Simple 調度器。
我會盡快增添更多版本,但聖誕節前時間不多……
設定
我將稍後增添專門的 Comfy 工作流程。現階段,隨時可下載並開啟展示用圖像。
“一體化”版本對 Forge 也很適用。
基本設定與版本 2.1 相同(見下文)
給它 20-30 步驟,2.2 左右的 cfg...
版本 2.1_去蒸餾_實驗性(合併)
此版本完全不同,甚至工作原理有別於一般 Flux 模型!
它是我 2.0 版本與去蒸餾版本https://huggingface.co/nyanko7/flux-dev-de-distill 的實驗性合併。雖偶然促成,卻產生驚人效果。細節驚人,且響應提示極佳。接下來我會直接在去蒸餾模型上訓練。我已有部分測試用的 Lora。屬高度實驗,若發現未列缺陷,請告訴我。若有好圖片也請發出,壞圖片亦可助改進 :-)。亦可能嘗試 2.0 版,幫我比較何種檢查點更適合你。
!注意!
普通 Flux 工作流程無法適應此版本。需另行下載我的工作流程!
你也可自行摸索,但別因不佳圖像責怪我。此為高度實驗性模型……詳見缺點下方。
此檢查點的優缺點:
此檢查點可產生極致細節,代價是比起通常 Flux 檢查點慢很多。其優點是通常不需額外放大圖像。本模型使用 cfg 尺度替代 Flux Guidance,這意味著它不適用標準工作流程。
可使用負提示詞!有助排除不想要的圖像元素。
有時會出現偽影,透過簡單小幅放大可解決(我正在改進中)。此現象並非所有種子均會出現。更新:這非模型本身問題,而是工作流程問題,我正在修復。若遇此狀況,可將初次放大設定由 1.2 改為 1.14。

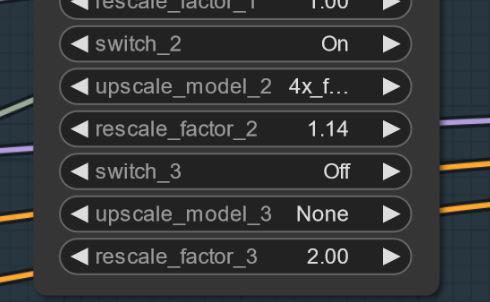
設定與工作流程 V2.1:
工作流程見此:https://civitai.com/articles/8419
設定:與普通 Flux 不同,此版本不需 Flux Guidance,改用 cfg。我的工作流程中多數採用 cfg 3。某些圖可能需較低 cfg。
最重要的是關閉 Flux Guidance 尺度。
未搭配工作流程時,我測試為 30 步驟與 2-3 cfg。Forge 可能用同樣設定,歡迎嘗試調整。
建議負提示詞加入 "blurry"。
采樣器與調度器:
可選擇多種采樣器:
Euler、Heun、DPM++2m、deis、DDIM 均表現良好。
我多用 "simple" 作為調度器。
若你找到更佳設定,告訴我 :-)
Forge 推薦用一體化模型,示範設定如下:
版本 2.0_dev_實驗性
此為實驗版。目標是創造更一致且更快速的模型。我融入額外自行訓練的 Lora,並以特別方式(Tensor 合併)合併結果模型。內置自訂 T5xxl 與 "Attention Seeker"。為提升速度及品質,融合了 ByteDance 的 Hyper Flux Lora。這改變了模型工作範圍。主圖如下展示……
16 步驟 V 2.0
 30 步驟 V 1.0
30 步驟 V 1.0
 缺點:
缺點:
首先,此版本體積比前代略大。其次,我尚未製作僅 Unet 版本,完成後會更新。
設定與工作流程 V2.0:
此模型可用較少步數運行……16 步驟相當於舊模型 30 步驟。
但我仍建議使用約 20-30 步驟,通常可獲得較好質量。
采樣器:我偏好 Euler、Simple 調度器。指導度可設定 1.5 至 3(當然可自由試驗範圍外的設定)。1.8 指導度對真實圖像效果良好。可嘗試其他采樣器,如 DPM++2M 與 Heun 也表現優秀。
工作流程 2.0:
我為 V2.0 與 V1.0 建立了新工作流程,含新 Flux 提示生成器。此外加入第二次放大階段。https://civitai.com/articles/7946
Forge:
我也在 Forge 上測試此模型,效果很好,但圖像結果可能與 Comfy UI 有所不同。
版本 1.0_dev_beta:
此模型是本系列的首發版本。請提供反饋及分享圖片,幫助我持續改進。版本眾多,質量最高是 FP16 版本。FP16 版本體積龐大,需高階顯卡及大量記憶體。FP8 版本在質量與效率間取得平衡。我也有 Q8_0 的 GGUF 版本應需下載。GGUF Q4_0/4.1 版本是應用請求製作,體積較小,但質量會有些損失。
基本上,我的模型分有兩種:“一體化”版,僅需一個檔案下載,包含 Clip_l、T5xxl fp8、VAE(見下方)。請放入檢查點資料夾。
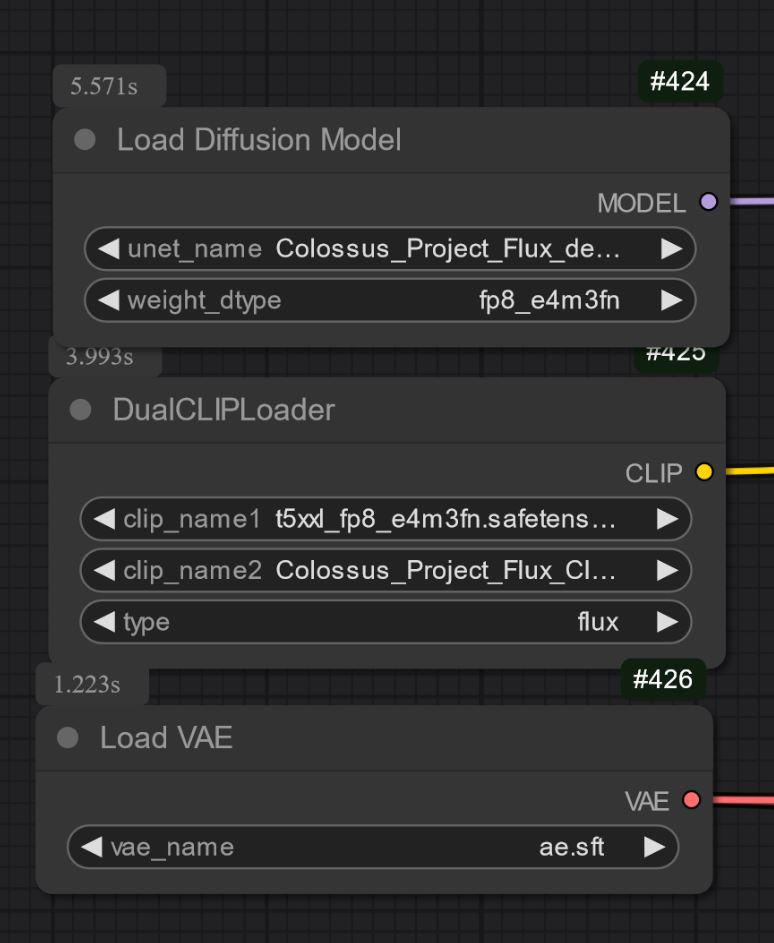
另一種為僅 UNET 版本,需分別載入所有檔案。
不論何種情況,你都要下載我的 Clip_L 以確保其正常運作。
重要的是選擇正確的 T5xxl clip。FP8 版本用 fp8_e4m3fn t5xxl clip,FP16 版本用 FP16 clip。務必選擇預設權重類型。(下方有 FP8 版本示意圖)
GGUF 版本則需 GGUF 載入器!
有關 V1.0 的已知問題:
這只是首個模型版本,可能在某些風格或提示詞(如藝術風)上表現不佳,後續版本會持續訓練。請告訴我模型無法達成的內容……
設定與工作流程:
我測試過約 30 步驟,Euler 采樣,Simple 調度器。指導範圍 1.5-3(當然你可以自己嘗試範圍外的設定)
1.8 指導值對寫實圖像效果良好。
歡迎自由嘗試設定。若成果良好,請分享出來。
展示圖像也作為訓練資料。這是 Comfy 工作流程,下載鏈接: https://civitai.com/articles/7946
「一體化」模型:
僅 UNET 版本:
 你需下載 clip_L,約 240MB。
你需下載 clip_L,約 240MB。
GGUF:我亦為 GGUF 添加了工作流程,見此: https://civitai.com/articles/7946
重要:
開發模型不適用於商業用途。對此我會在其他地方發布 "schnell" 模型,較適合個人或科研用途。
授權:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
致謝:
theunlikely https://huggingface.co/theunlikel(再次感謝)
版本 2.1/V4.2/5.0:來自 nyanko7 的 Flux_dev_de-distill
https://huggingface.co/nyanko7/flux-dev-de-distill
自 V2.0 起:ByteDance 出品的 Hyper Lora https://huggingface.co/ByteDance/Hyper-SD
Black Forrest 感謝其驚人 Flux 模型 https://huggingface.co/black-forest-labs

模型詳情
討論
請log in以發表評論。



















































