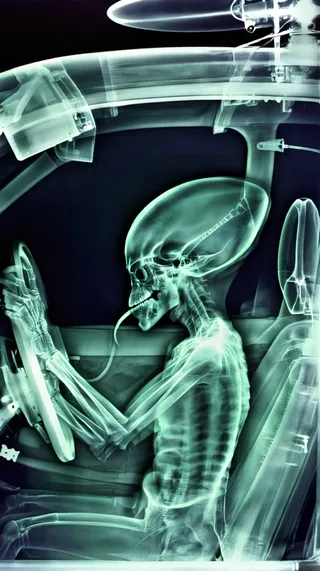
透視身體 | 實驗性 - v1.0 - 正常
精選圖片

推薦提示詞
1girl, masterpiece, best quality, amazing detail, high definition
推薦反向提示詞
see-through clothes,tattoo
bad quality, worst quality, worst detail, text, patreon, signature, steam, young
推薦參數
samplers
steps
cfg
resolution
vae
other models
提示
降低提示權重,如"(smile:0.7)",可在強烈面部表情與透視效果間插值。
在使用"see-through body"的同時添加"see-through head",能改善頭部透明度。
加入否定提示如"see-through clothes"或"tattoo"有助於減少不需要的風格效果並提升隱形感。
版本亮點
優化數據集,成果提升。如不需要角色周圍的光暈,請在否定提示加入'glowing'。
v2.4
感謝@Foredev的提示,為多次試驗提供了資金支持。此版本最終產出結果比v1更符合我的喜好,但我也很想聽聽你們使用後的感受比較。
對特定特徵如面部表情使用全強度提示時,可能會壓倒透視效果。降低提示權重,例如"(smile:0.7)",可以獲得成功在兩個概念之間插值的結果。
v2.3
我嘗試過但未成功改進該模型。此版本缺少部分舊版本的瑕疵,但產生透視效果的一致性較差。如果我要花這麼多精力訓練不佳的模型,不如釋出其中之一讓你試試。也許你會找到用途。
v1 - Large
與v1 - Normal使用相同數據集,但lora大小是其兩倍。結果看似有潛力,期待你的反饋。
v1 - Normal(推薦)
使用增強數據集,結果有所提升。風格影響仍然很強,偏向動漫風格,背景存在過擬合現象。當背景為重複圖案(如石牆、混凝土地面)或包含橫跨主體的元素(窗戶、邊緣等)時效果最佳。雖然未專門標記,但在添加"see-through head"配合"see-through body"使用時,可能提升頭部透明度。
在否定提示中添加"see-through clothes"可獲得更像隱形女孩的效果。有時添加"tattoo"於否定提示也能解決一些問題。
v0
概念驗證:這是一個基於合成及修改圖像訓練概念的驗證。初始數據集非常小,模型過度擬合,但展現了對概念的理解跡象。
方法說明
v0及v1完全使用合成數據訓練,方法為獨立生成主體及背景,然後用圖像編輯軟件將半透明主體合成到背景上。

這種方法有明顯缺點,兩部分結合不佳。那麼如何創建一個全身主體並使其正確面向背景的視角呢?我的解決方案是使用我最喜愛的工具,線稿ControlNet。 最初的提示是:
最初的提示是:
1girl, standing, full body, turning around, looking back, long blonde hair, red jacket, blue jeans, park, grass, bench, concrete path, masterpiece, best quality, amazing detail, high definition接著進行孤立主體提示的修改:
1girl, standing, full body, turning around, looking back, long blonde hair, red jacket, blue jeans, simple background, masterpiece, best quality, amazing detail, high definition還有背景提示:
no humans, park, grass, bench, concrete path, masterpiece, best quality, amazing detail, high definition有簡單背景時,更容易遮罩主體,再把它以透明主體覆蓋在完整細節背景上。即使使用不理解"see-through body"的模型,我們仍能創建合成訓練數據使其學習。非常棒!

在此之前,我也不確定這方法是否可行。結果雖非驚人,但比預期更好。

模型詳情
討論
請log in以發表評論。
模型合集 - See-through body | Experimental
透視身體 | 實驗性 - v1.0 - 正常 的圖片
概念 圖片


透視的 圖片










透明 圖片