Old Consistency V32 Lora [FLUX1.D/PDXL] - Feminine v1.1 - e500 PDXL
精選圖片


推薦提示詞
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
推薦反向提示詞
greyscale, monochrome, multiple views
推薦參數
samplers
steps
cfg
clip skip
resolution
vae
other models
推薦高解析度參數
upscaler
upscale
denoising strength
提示
使用多重迴圈以提升圖像真實度與一致性。
保持標準提示與合理順序,避免生成異常內容。
使用核心姿勢與視角標籤如“from front”、“from side”、“from above”提升姿勢準確度。
避免使用性交姿勢直到其完善。
嘗試各種髮型、眼睛、服裝顏色與材質標籤。
合併其他模型與 LoRA 時,載入順序影響結果。
預設開啟安全模式,並可解鎖可疑與 explicit 內容。
利用姿勢與指令標籤系統,以更佳掌控角色定位與攝影機角度。
版本亮點
穩定性檢查;
概念 - 圖像/測試圖像
全身 - 48/48
牛仔鏡頭 - 48/48
肖像 - 48/48
特寫 - 48/48
**************************************
下一次迭代將引入單層眼睛姿勢子集,標記姿勢角度並包含更多眼睛角度變化圖像,以加強效果。直接眼色可能非必要,但眼形對於成功至關重要,依我研究證實毋庸置疑。
紅眼 - 39/48
全身 - 6/12
牛仔鏡頭 - 9/12
肖像 - 12/12
特寫 - 12/12
藍眼 - 48/48
所有姿勢 - 12/12
綠眼 - 48/48
所有姿勢 -12/12
黃眼 - 42/48
全身 - 6/12 - 不明原因不穩定。
青眼 - 48/48
所有姿勢
紫眼 - 48/48
所有姿勢
乳膠 - 36/48
特寫 - 5/12
肖像 - 7/12 - 需要肖像與特寫圖像
牛仔鏡頭 - 12/12
全身 - 12/12
內衣 - 36/48
特寫 - 7/12
肖像 - 4/12?原因不明 - 需要直接肖像與特寫臉部圖像
牛仔鏡頭 - 11/12
全身 - 12/12
休閒 - 48/48
所有姿勢 - 12/12
比基尼 - 48/48
所有姿勢 - 12/12
連衣裙 - 16/48
除非附加標籤,無合適姿勢匹配連衣裙 -> 需更精準標記連衣裙
輸出穩定度比預期高許多,已有大量可用標籤導入 pony,部分包括;
<顏色> 頭髮
<顏色> 服裝
胸部 <尺寸>
<成熟> 女性
<顏色> 耳環
<顏色> 眼睛
<模糊> 物件
<區域> <背景>
這裡有大量有用標籤潛力,值得嘗試。
分層成功;
紅眼 -> 藍眼;
[紅眼:0.5], [藍眼:0.5] -> 偶爾重疊模糊,不穩定。
紅眼, 藍眼 -> 減少不穩定重疊
紅眼 AND 藍眼 -> 較穩定重疊,需更多研究
多數眼睛遇到相同問題,模組過度覆蓋眼色於眼形之上,眼睛分層實驗暫停,將基於斑點實驗實施。
連衣裙 -> 乳膠
連衣裙、側開叉、雞尾酒禮服、乳膠、乳膠緊身衣 -> 基於多層組件形成套裝。一致性不穩定,但結果好。
乳膠 -> 連衣裙
乳膠、乳膠緊身衣、連衣裙、側開叉 -> 生成更正式物件,似乎遮蓋更多裸露部位,暗示連衣裙訓練過度擬合,需要重新評估。
乳膠 -> 比基尼
乳膠、乳膠緊身衣、比基尼 -> 形成乳膠緊身裤混合比基尼,也暗示過擬合。
我相信我找到層疊服裝重疊解決方案,及眼睛和膚色解法。大部分一致性應源於斑點處理。
創作者贊助
查看Illustrious Model,獲得互補能力。
使用ComfyUI工作流,提升圖像生成並實驗迴圈。
探索功能強大的Flux Model基礎 AI 架構。
支持NovelAI,實現卓越故事與圖像生成協同。
感謝Black Forest Labs設計 Flux 模型。
使用TagGUI提升標籤工作流程。
訓練配置由AIToolkit完成。
靈感來自且競爭對手為PonyDiffusion。

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious 不是 PDXL 的分支,它是不同且非常優秀的。如果你有機會,試試看它。
我為此專門訓練了一個 Simulacrum 版本。
V3-2 替代 V3.22:
v3.22 的目標最終改變了,我在 flux 測試和探索新機制的過程中迷失了方向。當我學到足夠且确定了如何主題定格、如何標籤,以及 flux 本身如何理解標籤後,我能真正打造一個合適的版本 3。
感謝所有容忍我學習和實驗周期的人。這是一段充滿測試、失敗與真正成功的過山車。我知道能做什麼、怎麼做,且我有方法論去逐步實現及迭代我所學,創造我想創造的東西。過程還不完美,將在進展中精煉,因此不管做什麼,都會是理解與迭代開發的過程。我有足夠信心,我已跨過第一個重大的鄧寧-克魯格懸崖,並能在實驗後開始真正學習與傳授有用資訊,同時盡力以對初級與高級用戶均有幫助的方式處理與理解資訊。
我判定,我原本通向 V4 的方法是可行的,但我使用的過程不像我最初迭代學習系統時想的那樣有效。更多學習的面向與失敗,為未來成功耕耘了肥沃的土壤。
基於指令的版本管理。
我計劃每個版本引入三個核心指令訓練模型,以及一個純淨的無指令版本。
我會使用高度通用的指令基訓練,不僅針對核心系統,也針對具體核心主題圖片,使系統整體滲透預期主題元素。
若你不熟悉我對系統施加某些操作背後的理由,標籤過程的技術部分將獨特且難理解,因此圖片和標籤可能會顯得非常混亂,若想要詳盡細節。
簡化的標籤系統仍舊保留,並能在需要時完整產生必要結果。
每次發布都會有“nd”或“無指令”版本,保證測試差異和結果相似,就像礦井中的鳥:鳥停止鳴叫時該走了。這些姊妹模型可能可合併及正規化重用,融合基於指令的概念,無論該指令是否奏效。
對獨立角色的定格現為此模型首要目標。每次只會有一個定格角色,該角色分辨率會按正確的 FLUX 訓練格式參數作上下比率調整。
V3.2 問題沒我想像中嚴重:
主要的擔憂是基於缺失資訊,我計劃隨時間補齊。就是迭代發展的問題。
話雖如此,3.21 訓練版本目前正在測試,很快會發布。它在姿勢控制方面能力提升,並且對模型的焦點有用了較長攝影機指令的轉變。
結果顯示與大多數我測試過的 lora 兼容良好,甚至能與一些在當前 v32 中無法被誘導或旋轉的非常僵硬的 lora 配合使用。
它與 Flux Unchained、多種角色模組、臉部模型、人類模型等兼容性良好。迄今為止大部分系統不會重疊或破壞其他系統,這是件好事。
V3.2 需解決的問題:
部分姿勢及角度存在一致性問題。當其他 lora 使用側面、背面、俯視和仰視標籤時,也會有交叉污染。未來我將用新標籤作為驗證單元,訓練完全獨立的 LORA 以確保攝影機控制的逼真度。
主要對動漫風格表現良好,但與 lora 結合時出現問題。
3.21 版本的組合標籤:
我得做一些基線測試來確認攝影機依擺放正確工作,所以會測試類似標籤:
主體從正面上方角度
主體從正面側面角度上方
主體從背面上方角度正面
主體從側面上方角度背面
還會有更多類似於 base flux_dev 的標籤,確保我構建的能正確定位攝影機,不失真。
據我了解,如果使用這種泛用標籤,系統會訓練出很深程度。還需更多測試確認。
抓取從背後、性交從背後等標籤可能不會與背後標籤配合,所以將用後方標籤代替。
“from side”,“from behind”,“straight-on”,“facing the viewer”及與任何角色專用 safebooru、danbooru、gelbooru、方向旋轉相關標籤不會被訓練。會完全基於觀察角色,而非互動。
我們也希望大部分時間 POV 手臂不出現,需大量測試確保標籤不會意外生成手臂、腿部、軀幹,且能聚焦於討論的單一角色。
坦白說,有些姿勢沒用:
組合標籤系統未發揮作用,需新標籤組合來正確控制角色。
腿部變形或缺失。
手臂可能變形或放置不當。
腳部缺失。
上軀幹過分強調,過度擬合。
下軀幹服裝表現不佳。
脖子沒有正確展示圍巾、毛巾、項圈、領子等服飾。
乳頭和生殖器一團糟,需一個適用 NSFW 控制器的正確變體文件夾。
NAI 應特定於風格並以此細調。
服裝選項較常生成不同體型。
explicit 評分有時難以觸及,有時又如重型列車猛烈通過。
缺乏足夠的可疑圖片做權衡,explicit 標籤系統也應該以可疑標籤標記以確保訪問到相關信息。
部分動漫角色視角不佳,這對目標正確的聯想視角是件壞事。
四肢著地的固若金湯,但視角仍存在問題。似乎動漫角色不夠常被當作 3D,周遭環境需提升逼真度。
四肢著地的隊列需要大量調整才行。
跪姿隊列也同樣需要大量調整。
隊列和群組對 flux 有獨特格式,亟待更深研究。幾乎像為每個循環啟用內部迴圈。
部分成功經驗:
大部分圖像的基線真實度沒有下降。
多種新姿勢有效,雖偶有生硬。
動漫風格經由獨特 NAI 方式改變,增添些寫實感。
多角色可姿勢盡管方式有時怪異。
任意角度站立擁有極佳真實度與 NAI 風格的圖像品質。
V3.3 將稍後推出。
V3.3 路線圖:
我更新了本文檔底部資源,並將舊文檔分支為獨立文章以做存檔。
結果更貼合願景後,我可將重心移至目標列表下一步:覆蓋層。
V3.3 將引入所謂高 alpha 燒錄偏移標籤,流線化製作漫畫、遊戲介面、覆蓋層、血條、顯示器等。
理論上,如果我創建正確覆蓋層和燒錄,可在 consistency 中製作自己的假遊戲。
這將為任何場景深度中角色定位奠定基礎,但後續才會推出。
它已可公平生成精靈表,未來幾天將用些提示技巧與運算力,探索內置標籤系統,測試各子系統。高概率此功能已存在,待發掘。
V4 目標:
若一切順利,全系統將具備影像修改、影片編輯、3D 編輯等完整製作能力,及更多我尚無法想像的功能。
v33 覆蓋層
名稱誤導,實為下一結構的場景定義框架。
此項既是耗時最少,又是耗時最多,我有些 alpha 測試實驗要做以實現,但我確信覆蓋層會是選項,不僅用於訊息顯示,也因深度機制用於場景控制。
v34 角色投影、旋轉值規劃及觀點偏移:
確保特定角色存在並遵循指令是首要目標,因為有時它們根本不存在。
將實裝全數值旋轉評估,基於 pitch/yaw/roll(度數制)。雖非完美,因缺數學、圖像集與 3D 軟體技巧,但會是良好開端,也期望與 FLUX 單元結合。
v35 場景控制器
複雜場景交互點、攝影機控制、焦點、深度與更多,允許完整場景建構與置入角色。
可視為 3D 版本的覆蓋層控制器,加強強化版。
v36 照明控制器
分段與場景控制的光線變化,影響所有角色、物件及內容創作。
每盞燈將根據 Unreal 定義的規則、各種照明類型、光源、顏色等安置與生成。
理論上 FLUX 會補全缺口。
v37 體型與身體定制
在引入基本體型後,我想推進更複雜身體結構創建,包括但不限於:
修正無法正常運作姿勢
增加大量額外姿勢
更複雜髮型:
與物體互動的頭髮、剪下的頭髮、受損髮、變色髮、多色髮、綁髮、假髮等
更複雜眼睛:
各種眼型,開眼、閉眼、眯眼等
多樣臉部表情:
快樂、悲傷、驚訝、無眼、簡約臉、無臉等
耳朵類型:
尖耳、圓耳、無耳等
多種膚色:
淺色、紅色、藍色、綠色、白色、灰色、銀色、黑色、深黑色、淺棕色、棕色、深棕色等。
我會避開敏感話題,因大家普遍關注膚色,但我真的只想要像衣服一樣多種顏色。
手臂、腿部、上軀幹、腰部、臀部、脖子與頭部尺寸控制:
二頭肌、肩膀、肘部、手腕、手、手指等,配備長度、寬度與周長尺寸調整。
鎖骨及各種軀幹標籤
腰部及各種腰部標籤
基於 1 到 10 漸層而非某種 booru 使用的預定義系統的體型概括細節
v38 服裝與服裝定制
大約 200 套服裝,各自擁有自訂參數。
v39 500 個挑選自高精度資料庫的電玩、動漫及漫畫角色
五百個——抱歉,我是說……大量角色。是的。絕對不是大量無理合理關聯的 meme 角色。
之後你可以打造任何或訓練任何角色。
大幅度真實度與品質提升:
匯集數萬張高品質動畫、3D 模型與攝影寫實圖像,疊加並訓練此 Flux 精細調教版本於風格參數範圍。
每張圖像會依分數_1 至 分數_10 區間比率打標並計分,類似 Pony,但會有我獨特系統風格,視成敗而定。
V3.2 發布 - 4k 步驟:
這絕非兒童模型,一定的。這是包容 SFW/QUESTIONABLE/NSFW 的基礎模型,可訓練成任意模型。
同時它不為色情專用,但能在提示下生成。這是啟用 AI 某些行為的附帶產物,會帶來包袱。當前圖像大約三分之一三分之一三分之一,略有浮動。權重偏向安全,類似 NAI。
我的立場是啟發並教授資訊,讓個體自我決定。以相當控制與謹慎度教授無審查 AI,對 AI 成長和達成真實理解健康,且避免 AI 生出恐怖噩夢內容給生成者。
這玩意兒展現比我見過任何更有前景的成果好多。
使用我的 ComfyUI 工作負載,附於下方所有圖像。
默認啟用安全模式:
可疑 < 解鎖更多可疑隨機特徵
explicit < 解鎖更多有趣的隨機呈現
視角激活標籤:試試混合;from front, side view 等
from front, front view,
from side, side view,
from behind, rear view,
from above, above view,
from below, below view,
核心新增與加強姿勢:
四肢著地
跪姿
蹲姿
站立
彎腰
倚靠
躺臥
倒立
趴著
仰躺
手臂位置
腿部位置
頭部傾斜
頭部方向
眼睛方向
眼睛位置
眼睛顏色飽和度
頭髮顏色飽和度
胸部大小
臀部大小
腰圍大小
大量服裝選項
豐富角色設定
豐富臉部表情
性交姿勢尚為研發中,強烈建議尚未精煉前避免嘗試。遠超我現階段能力範圍,且此刻我無能量判斷最佳路線。
姿勢創建器、角度創建器、情境設定器、概念投射器和插值架構已建立,我將訓練更多版本。
祝享受。
V3.2 路線圖:
2024/8/25 5:16 - 我確定該過程有效,系統功能超預期高。AI 開發出新興行為,能以前所未有的強大方式為角色設定姿勢。測試開始,結果極佳。
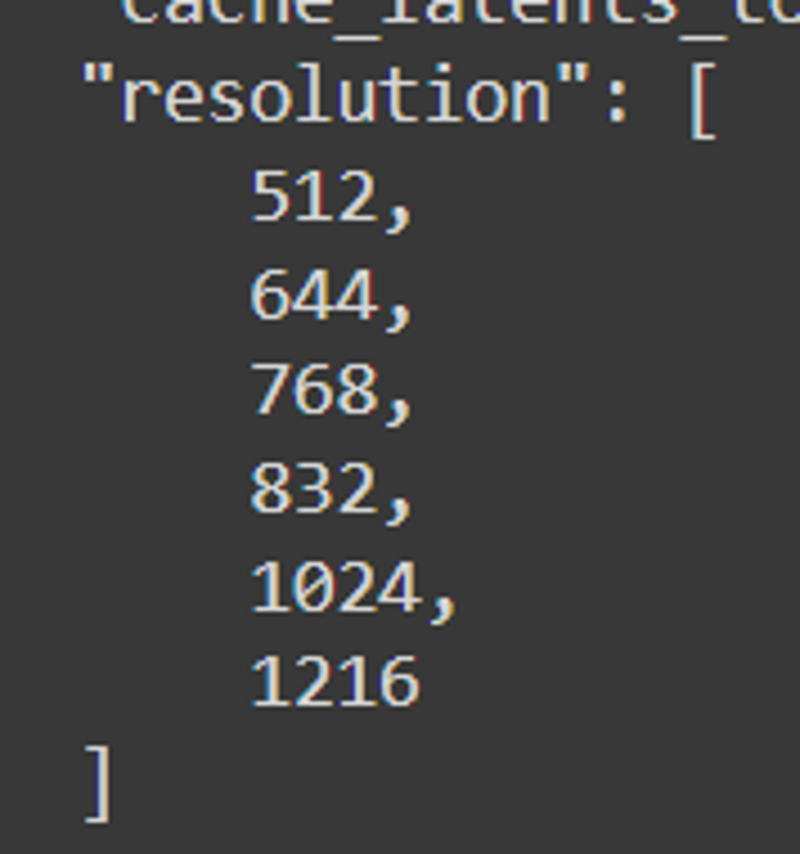
最終解析度:512、640、768、832、1024、1216
2024/8/25 下午3點 - 全部標籤已就緒,姿勢準備完畢。真正訓練開始,將進行多維度測試、學習率數目測試、步驟檢查等,評估適合 v32 的最佳候選。
2024/8/25 凌晨4點 - v32 首版本在 1400 步時輕微變形,2200 步時嚴重變形,說明懶散的 WD14 標籤不起作用。將進行手動標籤。將是個有趣的早晨。
2024/8/24 傍晚 - 正在煮熟中。
 我懷疑這個版本不會成功。我目前自動標籤所有內容並裁剪姿勢角度。打算先看看 WD14 自己能做到什麼。無論訓練成功與否,我會還原原本的姿勢角度和標籤順序。現在看將有哪些變化,所有有意義資料已聚集且使用場景密集。
我懷疑這個版本不會成功。我目前自動標籤所有內容並裁剪姿勢角度。打算先看看 WD14 自己能做到什麼。無論訓練成功與否,我會還原原本的姿勢角度和標籤順序。現在看將有哪些變化,所有有意義資料已聚集且使用場景密集。4000 張圖像需要一段時間快取潛變,但針對特定 "使用案例" 娃娃與身體的關注,至少預計結果會不錯。
2024/8/24 中午 -
 正在磨合。
正在磨合。 全格式設定使陰影暗示背景,有助流基於表面與位置生成畫面。構建所有缺失姿勢以補全 flux 無法處理部分,聚焦多重重疊主體。
全格式設定使陰影暗示背景,有助流基於表面與位置生成畫面。構建所有缺失姿勢以補全 flux 無法處理部分,聚焦多重重疊主體。專注於正確手臂位置,並確保重疊手臂標籤構建從點 A 到 B 的手臂。
2024/8/24 早晨 - 似乎有手臂問題,但我會記錄解決,感謝指出。此處確定有些交叉污染待處理。我用一特殊的 ComfyUI 循環系統,網站系統無,可能此版本需禁用站內生成。
 2024/8/23 - 我已有約 340 張高細節動漫圖,近似姿勢、pitch/yaw/roll 識別,確保堅實、色彩變化、胸部、頭髮、臀部大小分化。還有 554 張待完成。V3.2 將重點為動漫風格,后續計劃使用 Pony 產生足夠合成寫實元素,以融合所需的真實感質素。除非訓練后 flux 允許,否則直接用 flux。
2024/8/23 - 我已有約 340 張高細節動漫圖,近似姿勢、pitch/yaw/roll 識別,確保堅實、色彩變化、胸部、頭髮、臀部大小分化。還有 554 張待完成。V3.2 將重點為動漫風格,后續計劃使用 Pony 產生足夠合成寫實元素,以融合所需的真實感質素。除非訓練后 flux 允許,否則直接用 flux。 這些應確保按姿勢分辨度和評分分離,尤其我有新方法用 from 與 view 關鍵詞。理論上功能與 NovelAI 姿勢控制接近,我目標即是如此。角色及區分是另一大篇章。
這些應確保按姿勢分辨度和評分分離,尤其我有新方法用 from 與 view 關鍵詞。理論上功能與 NovelAI 姿勢控制接近,我目標即是如此。角色及區分是另一大篇章。一切需完美井然有序,否則無法以必要速度為基礎模型注入足夠上下文產生真正用途效果。
預設為安全模式,全系統將偏向安全,可啟用 NSFW。
我將訓練多個版本以確保兩者嚴格區分,同時也可滿足較偏好 NSFW 版本的需求者。
我希望訓練完成時,可將五萬張精選資料集灌入系統,產生魔法般作品。潛力或匹敵 Pony,滿足各種需求。之後你們可隨意灌入,憑藉 flux 與 consistency 脊樑,生成你的想要。
我計劃在整理、訓練、測試、準備好初始 v3.2 圖像集後,公開完整一致性訓練資料。v3 數據會在本週末發布。
我識別出一系列姿勢不一致性,主要是 lying 與角度關鍵詞組合。將測試每組合,修補底層一致性,再進入下一階段,包括基本服裝選擇、服裝變更、及基於有效與無效姿勢的派生。此外還需補足後續可疑和 NSFW 元素詳細資訊。下版本後你可猜猜是什麼。
目前,我需確保姿勢能按指令實際運作,將創建新的有意義組合關鍵詞,補齊每姿勢更多圖像、每角度更多圖像及更多角度組合。並會創建可作為佔位符的新資料,構建更複雜場景與圖像,但 flux 不太需要大量,因此會邊做邊完善。將包含一套 "base" 標籤,當遇失敗點時會默認代替,協助穩定性。
V3 文檔:
主要在 FLUX.1 Dev e4m3fn fp8 版本測試,合併檢查點完成後會反映此數值。https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
基於 FLUX.1 Dev 模型,但也能用於其他模型、合併與不同 LoRA,結果會混合。可試試不同載入順序,模型數值有序列變動。
這是 FLUX 的脊椎。它賦能有用標籤,非常類似 danbooru,確立攝影機控制與輔助,使製作非常可定制化角色於 FLUX 預設可做但尚需更多努力的場景更輕鬆。
強烈建議使用多重迴圈系統,提升圖像真實度和一致性。
此系統強烈面向個體,但按我架構的解析度,能處理多個相似場景人員。能立即改變畫面且無上下文貢獻的 lora 通常無用。較專注於賦予人特徵或建立上下文互動的 lora 工作正常,服裝、髮型、性別控制等大多測試皆有效,少部分沒用。
這不是合併也不是 lora 結合。此 lora 使用由 NAI 與 AutismPDXL 一年內生成的合成資料創建。影像集相當複雜,選圖不易,歷經大量嘗試錯誤。
此 lora 引入一系列核心標籤,為 FLUX 添補原本缺少的整體骨架。啟用模式複雜,但若角色創建類似 NAI,呈現效果會相似。
此模型潛力不容小覷,是極為強大的 lora,潛力超出我預估。
若不謹慎,仍會產生怪異結果。保持標準提示與合理順序,應能快速製作美麗作品。
解析度:512、768、816、1024、1216
建議步數:16
FLUX 指導:4 或頑固時 3-5,極頑固時 15+
CFG:1
我用了 2 重迴圈。第一輪放大 1.05x 並以 0.72-0.88 去噪,第二輪以 0.8 去噪,幾乎未變,根據我想增加或移除多少特徵而調整。
核心標籤池:
anime - 將姿勢、角色、服裝、臉部等風格轉為動漫風
realistic - 轉為寫實風格
from front - 從正面觀看,肩膀對齊且面向觀者,軀幹中心面向觀眾
from side - 側面視角,肩膀垂直面向觀者,表示角色為側視
from behind - 從角色正後方視角
straight-on - 正面平面垂直角度視圖
from above - 45 至 90 度俯視角色
from below - 45 至 90 度仰視角色
face - 臉部細節著重圖,適合強調臉部細節
full body - 個體全身視圖,適合複雜姿勢
cowboy shot - 標準牛仔鏡頭,動漫好用,寫實較差
looking at viewer, looking to the side, looking ahead
facing to the side, facing the viewer, facing away
looking back, looking forward
混合標籤創造預期混合結果,但結果不一
from side, straight-on - 水平平面攝影機對準個體側面
from front, from above - 從前方俯視 45 度傾斜
from side, from above - 從側方俯視 45 度傾斜
from behind, from above - 從後方俯視 45 度傾斜
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front from side, from below
from front from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
這些看似相似,但順序常造成截然不同的結果。例如 "from behind" 置於 "from side" 之前,系統會偏重後方視角,但常見上軀幹扭轉並身體左右轉 45 度。
結果多樣,但絕對可用。
特徵、色彩、服裝等同樣適用
紅髮、藍髮、綠髮、白髮、黑髮、金髮、銀髮、金髮、棕髮、紫髮、粉髮、青色髮
紅眼、藍眼、綠眼、白眼、黑眼、金眼、銀眼、黃眼、棕眼、紫眼、粉眼、青眼
紅色乳膠緊身衣、藍色乳膠緊身衣、綠色乳膠緊身衣、黑色乳膠緊身衣、白色乳膠緊身衣、金色乳膠緊身衣、銀色乳膠緊身衣、黃色乳膠緊身衣、棕色乳膠緊身衣、紫色乳膠緊身衣
紅色比基尼、藍色比基尼、綠色比基尼、黑色比基尼、白色比基尼、黃色比基尼、棕色比基尼、紫色比基尼、粉色比基尼
紅色裙子、藍色裙子、綠色裙子、黑色裙子、白色裙子、黃色裙子、棕色裙子、粉色裙子、紫色裙子
裙子、襯衫、連衣裙、項鍊、全套服裝
多種材質;乳膠、金屬、丹寧、棉布等
姿勢可能與攝影機共享調整,需微調
四肢著地
跪姿
躺臥
躺臥,仰躺
躺臥,側躺
躺臥,倒立
跪姿,從後方
跪姿,從前方
跪姿,側視
蹲姿
蹲姿,從後方
蹲姿,從前方
蹲姿,從側面
腿部等位置控制較挑剔,請多嘗試
腿
雙腿併攏
雙腿分開
腿部打開
雙腳併攏
雙腳分開
數百個其他標籤使用及包含,數以百萬計的可能組合
請先於 flux 提示後,於個體特徵描述前使用這些標籤。
提示:
就這麼做。隨便打,看效果。FLUX 已有大量資訊,用姿勢等標籤輔助圖像。
範例:
一名女性坐在廚房椅子上,from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes

一名超級英雄女性飛翔於天空,投擲一塊巨石,周圍有強烈發光威嚴氣場,寫實,1girl,from below,藍色乳膠緊身衣,黑色項圈,黑色指甲,黑色嘴唇,黑色眼睛,紫色頭髮
 一名女性在餐廳用餐,from above, from behind, 四肢著地, 屁股, 丁字褲
一名女性在餐廳用餐,from above, from behind, 四肢著地, 屁股, 丁字褲 成功了。通常如此。
成功了。通常如此。
理論上,這玩意能處理大多數混沌情形,但絕對超出我全面控制範圍。我盡力勸導並包含足夠姿勢標籤以支持,多用核心和有用標籤即可。
經過超過 430 次失敗嘗試才得此,終有一系列成功理論。計劃完整撰寫並於本週末公開訓練資料。歷程漫長艱辛。祝大家愉快。
V2 文檔:
昨晚很累,沒完成完整整理與發現。會盡快(工作期間)完成測試與標記。
Flux 訓練介紹:
過去 PDXL 僅需少量帶有 danbooru 標籤的圖像,便能達到相當於 NAI 的精調結果。圖像數越少是優勢,因為減少潛能;但這次不管用,需要更多、更強的東西。
模型已具備許多能力,但各類學習數據之間變異比初期預期高出許多。更高變異意味著更大潛力,我起初不明白為何高變異反倒奏效。
研究後發現,模型之所以強大,正因如此。它能基於深度「導向」產生圖像,圖像被分層與另一圖像噪聲混疊,猶如指導標記。我思考如何在不破壞核心細節下訓練這個系統。先想用重設尺寸,後想起分桶策略。這就是首個要點。
我基本盲目進行,依建議調參,再根據觀察結果調整。過程緩慢,期間也研讀論文加速。如果我有精力,一次做完,但我只有一個人且有工作需做。我幾乎傾盡所有資源。如果有更多心力,愿一次運行 50 個,但無閒暇做好設置。想付錢買,但無能建立。
我依據 SD1.5、SDXL、PDXL lora 訓練經驗,選擇自認最合適格式。結果尚可,但確實有些缺陷,細節後述。
訓練格式:
測試若干。
測試 1 - 750 張隨機 danbooru 範例圖:
UNET 學習率 - 4e-4
注意到其他參數大多無需調整,除解析度分桶閾值。
1024x1024,中心裁切
2k 至 12k 步
挑選 750 張隨機 danbooru 標籤池圖,確保標籤統一
用 moat tagger 標註並追加標籤,防止標籤覆蓋
結果不理想,混沌預期內。新增人類部位如生殖器不穩定或缺失,與他人結論相仿。
我不認為模型整體會受損,因為標籤多不重疊。
重複測試兩次,得兩個無用 lora,步數約 12k。1k 到 8k 測試很少有產生期望偏差,縱使細察標籤分布峰谷。
仍有遺漏,不是人文或 clip 描述標籤,有更深層次的東西。
此失敗點觸發發現,深度系統基於兩個完全不同且偏離的提示互插合作。具體應用未明,正研讀數學論文。
測試 2 - 10 張圖:
UNET 學習率 - 0.001 <<< 非常高的學習率
256x256、512x512、768x768、1024x1024
最初步驟呈現一定偏差,如 SD3 測試燒灼程度。但不好,高斯變形從約 500 步起,1000 步基本無用。重複測試確實失敗。
偏差傷害大,產生新上下文後卻反成噩夢,破壞原材料,猶如劣質修補。此測驗證明 FLUX 韌性極高且抗損害強。
示例失敗,需嘗試其他設置。
測試 3 - 500 張姿勢圖:
UNET 學習率 - 4e-4 <<< 這應除以 4 且訓練時間翻倍
完整分桶 - 256x256, 256x316 等等。放開走,各種尺寸多圖像自由分桶。結果令人驚喜。
這幾乎就是此一致性模型核心,強大結果帶來些微損害,但效果絕佳。
註:動漫不常用景深。此模型靠景深與模糊區分深度。或需加深度 controlnet 確保多樣景深,但不確定如何實現。可能同時訓練深度圖與法線圖,但無負向提示可能徹底毀壞模型。
需要更多測試與訓練數據及資訊。
測試 4 - 5000 一致性組合:
UNET 學習率 - 4e-4 <<< 此應除以 40 且訓練時間增加約 20 倍。此訓練並不簡單或快,基礎數學未必充足保護核心模型完整性,已釋出初步發現。
我曾撰寫整段及後續發現,但誤操作導致內容遺失,待後重寫。
重大失敗:
初期 12k 步 lora 學習率過高。整體系統基於梯度學習,但我施教速率過快令模型無法有效吸納資訊並維持穩定。簡而言之,我沒破壞它,而是重新訓練至我想要的,但我不知道我想要什麼。整體未導向且無梯度深度,注定失敗,迭代步數無所幫助。
Flux 的 STYLE 與大家基於 PDXL 與 SD1.5 的認知不同。梯度系統能為物件造型,但大量資訊過快施加會嚴重破壞結構,與 PDXL lora 更多是增強既有元素不同,後者類似給予附加層。
重要發現:
ALPHA、ALPHA、還有更多 ALPHA<<<< 系統極度依賴 alpha 梯度。圖像細節如距離、深度、比例、旋轉、偏移等,皆是此模型組成關鍵,小於單一提示。
所有事物須被詳細描述。簡單 danbooru 標籤本質是風格。你強迫系統識別你欲實施風格,故不可只強加新概念,需配合必要的概念分配標籤。否則風格與概念連結失敗,輸出結果將糟糕。
大量姿勢資訊訓練時,效果極為顯著。系統已識別大部分標籤,只是不明白內容。用特定標籤連結現有與目標元素,對標籤組織與微調具強大效果。
步驟文檔;
v2 - 5572 張圖片 -> 92 種姿勢 -> 4000 步 FLUX
原目標將 NAI 推向 SDXL,現已應用於 FLUX。敬請期待更多版本。
穩定性測試,展現出 PDXL 難以企及的能力。需補充訓練,但步數低卻有強大效果。
我相信初階姿勢訓練約需 500 張圖像左右,數據會在整理及計數完後於 HuggingFace 公布。不想公佈錯誤或混入廢料。
繼續閱讀請見:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
重要參考:
我不抽煙,但 FLUX 有時需一根。
一套工作流與圖像生成助手。我多用核心 ComfyUI 節點,不斷嘗試並保存其他節點。
一個極為強大且難懂的 AI 模型,潛力巨大。
無他,我不會想做這東西。向 NAI 全體工作人員致敬,他們辛勤工作和他們強大的圖像生成器,還有超棒的寫作助手。向他們砸錢吧。
設計 Flux 模型的團隊,絕大功勞歸於他們。我僅是精調與引導這巨獸走向目標。
強大高效的標籤助手。我差點自己寫一套,幸好撞見這套強者。
我用來訓練 Flux 版本的工具,有點脆弱挑剔,但在多系統上表現良好,能完成工作。
不可忘記戰場上的對手。這怪獸能生成大型梯度場圖像,是寶貴的研究與理解工具,也是本進展方向的靈感來源。

模型詳情
討論
請log in以發表評論。
![Old Consistency V32 Lora [FLUX1.D/PDXL] Feminine v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































