[PVC風格模型]可動手辦模型 - v2.0(無vae)
精選圖片

推薦提示詞
best quality,masterpiece,realistic,HDR,UHD,8K,highly detailed
1girl,pink hair,solo
推薦反向提示詞
low quality,simple background,worst quality:1.4,bad anatomy,inaccurate limb:1.2,head out of frame,bad composition,inaccurate eyes,extra digit,fewer digits,extra arms,grey background:1.2,watermark,text,logo,username,multiple moles,mole on body:1.2
(deformed,distorted,disfigured:1.3),poorly drawn,bad anatomy,wrong anatomy,extra limb,missing limb,floating limbs,(mutated hands and fingers:1.4),disconnected limbs,mutation,mutated,ugly,disgusting,blurry,amputation,flowers,human,man,woman (low quality:1.3),(worst quality:1.3)
推薦參數
samplers
steps
cfg
clip skip
resolution
vae
other models
推薦高解析度參數
upscaler
upscale
steps
denoising strength
提示
選擇正規渠道:盡量選擇知名廠商或口碑良好的商家購買。
查看產品信息:仔細核對產品材質、尺寸、製作工藝等資訊,並查看高清圖片。
索要發票:要求商家提供正式發票,以便日後維權。
保留聊天記錄:與商家溝通時建議保存聊天記錄,備不時之需。
使用AI技術判斷:可使用網址https://hivemoderation.com/ai-generated-content-detection鑑定圖片。
版本亮點
此版本無內置VAE,需要自行添加VAE使用
此版本未內嵌VAE,需自行添加VAE方可使用
創作者贊助
感謝您對我AI生成PVC手辦模型的關注。為避免不法分子利用本模型AI技術生成PVC手辦,通過虛假宣傳、欺騙等手段騙取用戶定金,請提高警惕,謹防受騙。
關於AI生成PVC手辦的風險提示
尊敬的用戶:
感謝您對我AI生成PVC手辦模型的關注。為避免不法分子利用本模型AI技術生成PVC手辦,通過虛假宣傳、欺騙等手段騙取用戶定金,特此鄭重聲明如下:
本模型僅用於AI生成技術學術交流:我手辦模型的AI技術僅用於生成PVC手辦設計圖稿,不涉及實物生產及銷售。
請勿相信任何未經授權的銷售:任何聲稱銷售由本模型AI生成技術製作的PVC手辦行為均未獲授權,請用戶提高警惕,謹防受騙。
風險提示:PVC手辦製作涉及多個環節,包括3D建模、材質選擇、模具製作、注塑成型、上色等,每環節均可能存在質量問題。請用戶購買時務必選擇正規渠道,仔細核對產品信息,並保留相關憑證。
維權建議:若發現商家利用本模型AI技術進行欺詐,請及時向相關部門舉報並保留證據,以追究法律責任。可通過AI-Generated Content Detection | Hive (hivemoderation.com) 這個網站鑑定圖片是否為AI生成。
溫馨提示
為保障您的權益,建議購買PVC手辦時注意以下幾點:
選擇正規渠道:盡量選擇知名廠商或口碑良好的商家購買。
查看產品信息:仔細核對產品材質、尺寸、製作工藝等資訊,並查看高清圖片。
索要發票:要求商家提供正式發票,以便日後維權。
保留聊天記錄:與商家溝通時建議保存聊天記錄,備不時之需。
使用AI技術判斷:遇到可疑手辦,最好通過AI-Generated Content Detection | Hive (hivemoderation.com)這個網站上傳圖片進行鑑定。
免責聲明
對於本模型被任何未經授權第三方利用AI技術進行商業活動,本人不承擔任何責任。用戶請自行甄別,謹慎購買。
4.0版本對中近距場景質感效果最佳,在中近距可不用開面部修復插件,對手指手部略微優化
4.0版本在中近距場景擁有最佳的質感效果,無需開啟面部修復插件,對手部和手指略作優化。
注意‼️一定要使用我推薦參數
注意 ‼️ 請務必使用我推薦的參數
新版本推薦使用參數(The new version of the recommended use parameters)
推薦參數(Recommended parameter):
採樣方法(Sampler):
Euler :20~30步
Euler a: 20~30步
提示詞引導係數(CFG Scale):3-7
人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修復(Hires.fix):
放大演算法(Amplification algorithm):Latent,4x-UltraSharp,
負面提示推薦(Negative):(低質量,簡單背景,最差質量:1.4),(解剖錯誤),(四肢不準確:1.2),頭部超出框架,構圖不佳,眼睛不準確,多餘手指,手指較少,(多餘手臂,灰色背景:1.2),(水印,文字,標誌,用戶名,多處痣,身體上的痣:1.2),
使用Latent設定(Using Latent Settings)

使用4x-UltraSharp設定(Use the 4x-UltraSharp setting)
高分迭代步數(High number of iteration steps):10~15
推薦參數設置(Recommended parameter setting)
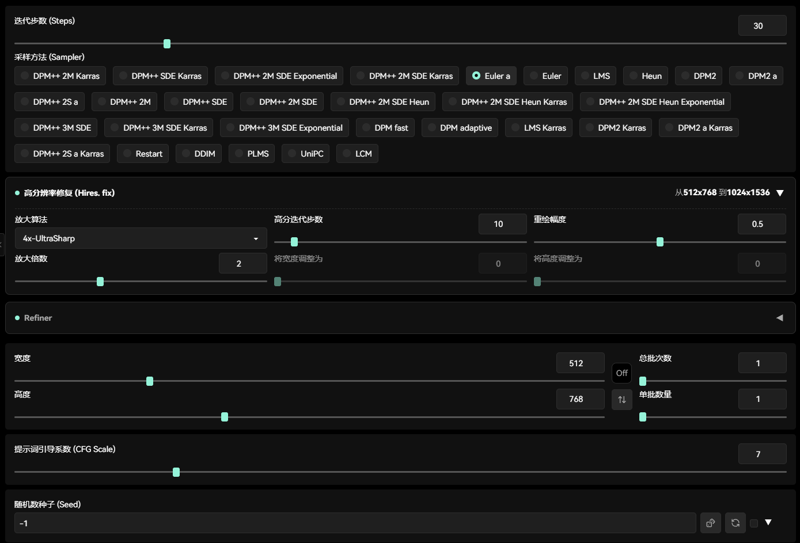
重繪幅度(Redraw amplitude):0.3~ 0.5
Clip Skip:2。
以上未提及參數沿用上一版本(The above mentioned parameters are used in a previous version)
-----------------------------------------------------------------------------------------
模型應用場景 Model application scenario
1.可搭配2d,2.5d,3d,風格lora直出PVC材質風格的人物、物品(使用方式與其他模型相同)
此模型可與2d、2.5d、3d及風格lora直接輸出PVC材質風格的人物與物品搭配使用(與其他模型相同)。
2.特定場景風格轉換
本模型可將2d,2.5d,3d圖片轉換成PVC材質風格,可應用於特定風格品牌設計及產品設計視覺設計的圖片轉換PVC材質畫風。
特定場景的風格轉換
此模型可將2d、2.5d、3d圖片轉換為PVC材質風格,可應用於特定風格品牌設計及產品設計視覺設計領域,以將圖片轉換為PVC材質畫風。
2.0版本推薦使用參數(This parameter is recommended for version 2.0)
推薦參數(Recommended parameter):
採樣方法(Sampler):
Euler :20~30步
Euler a: 20~30步
Restart:15~20步
DDIM:30步及以上
提示詞引導係數(CFG Scale):3-7
人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修復(Hires.fix):
放大演算法(Amplification algorithm):R-ESRGAN 4x+Anime6b,4x-UltraSharp,4x_SmolFace_200k
高分迭代步數(High number of iteration steps):10~15
重繪幅度(Redraw amplitude):0.3~ 0.5
Clip Skip:2。
負面提示推薦(Negative):(低質量,最差質量:1.4),(解剖錯誤),(四肢不準確:1.2),構圖不佳,眼睛不準確,多餘手指,手指較少,(多餘手臂:1.2),(水印,文字,標誌,用戶名,多處痣,身體痣,:1.2),
以下為特定場景墊圖轉換圖片方法
這是場景轉換圖片的方法
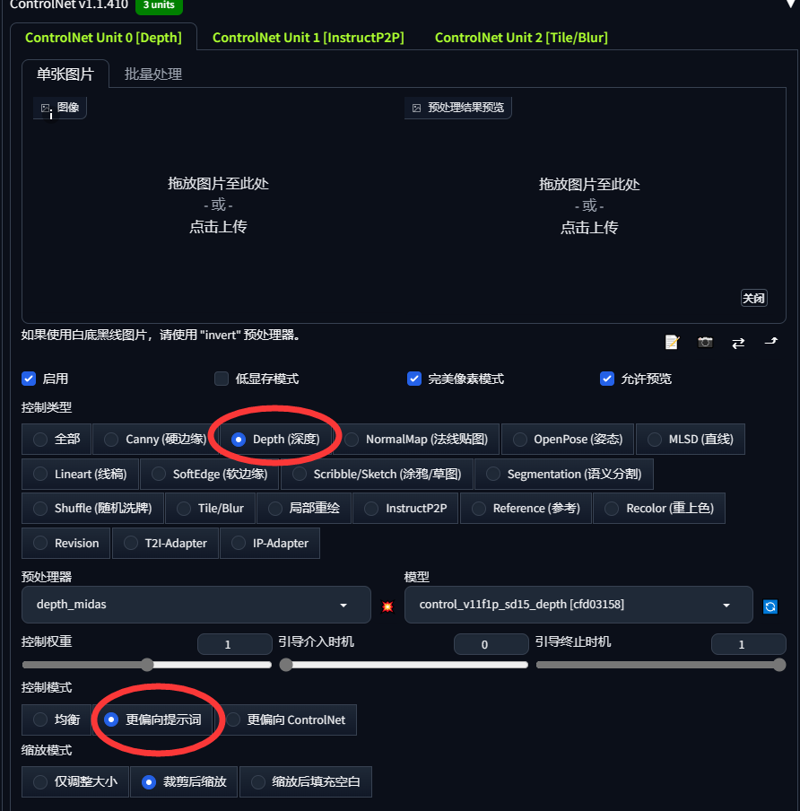
把需要轉換風格的圖片放到ControlNet插件第1頁,例如
將想要更換風格的圖片放在ControlNet插件第1頁,例如unit0選擇深度圖。
第一步,例如這個人物,這是別的模型製作的圖,我沒有此人物的lora模型,只通過圖片轉換為手辦風格,將圖片放入ControlNet插件第1頁,也就是unit0選擇深度圖。
第一步,如此人物為其他模型生成,我沒有此人物的lora模型,僅透過圖片轉手辦風格,我們將圖片放至ControlNet插件第一頁unit0,選擇深度圖。

勾選完美像素,點擊爆炸圖標並運行
勾選完美像素,點擊爆炸圖標執行
第二步分兩種方法,先說第一種,這張圖為SD直出圖的原圖
第二步有兩種方法,先講第一種,這張圖是SD直出圖的原圖。

若有原圖,只需將圖片放入PNG信息提取工具,提取圖片提示詞,只需提取正面提示詞
若有原圖,只需將圖片放入PNG信息提取中,提取圖片提示詞,僅需提取正面提示詞。

僅需選中框定的區域,將提取的提示詞放入文生圖中
只需框選該區域,將提取的提示詞放入文生圖中。
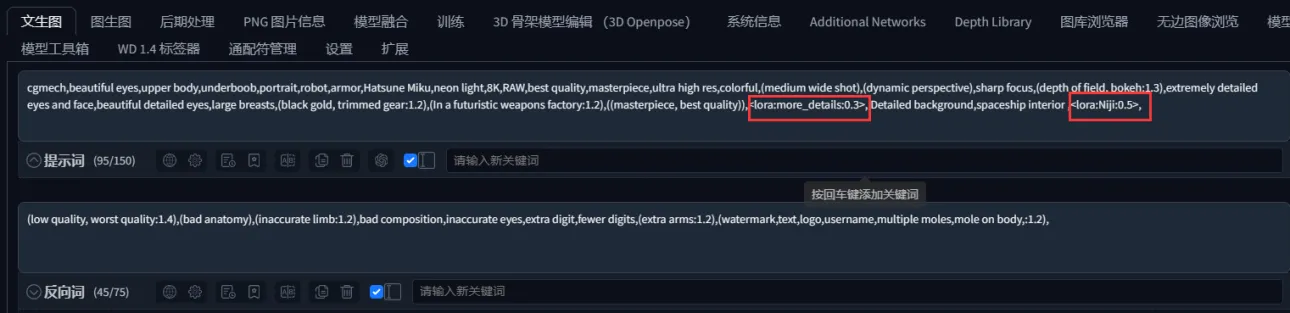
由於沒有此lora模型,建議刪除,然後點擊生成
因無此lora模型,建議刪除,再點擊生成。

第二種方法與前述類似,圖片非SD直出且模型無保留圖像信息,則將圖片放入圖生圖中,例如我找到一張圖片無tag,將該圖片放入圖生圖。
第二種方法與第一種類似,圖片非SD直出且無保留圖片信息的模型,將圖片放入圖生圖中,如我找到一張無tag圖片,將其放入圖生圖。
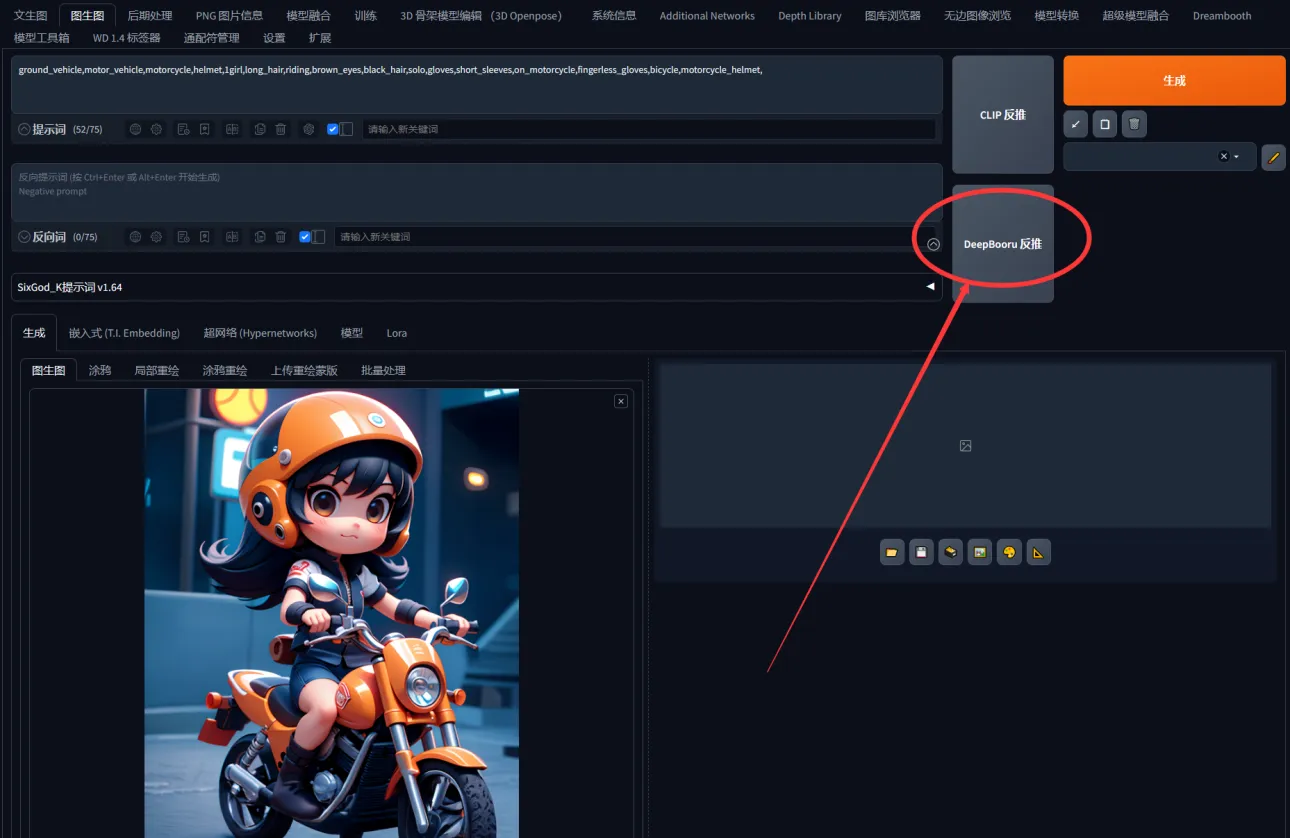
點擊DeepBooru反推,將返推的tag複製並提取到文生圖中
點擊DeepBooru反推,獲得反推tag後,複製提取到文生圖中。

重複之前步驟,將圖片放入ControlNet插件第1頁unit0選擇深度圖
重複先前步驟,將圖片放入ControlNet插件第1頁unit0,選擇深度圖。
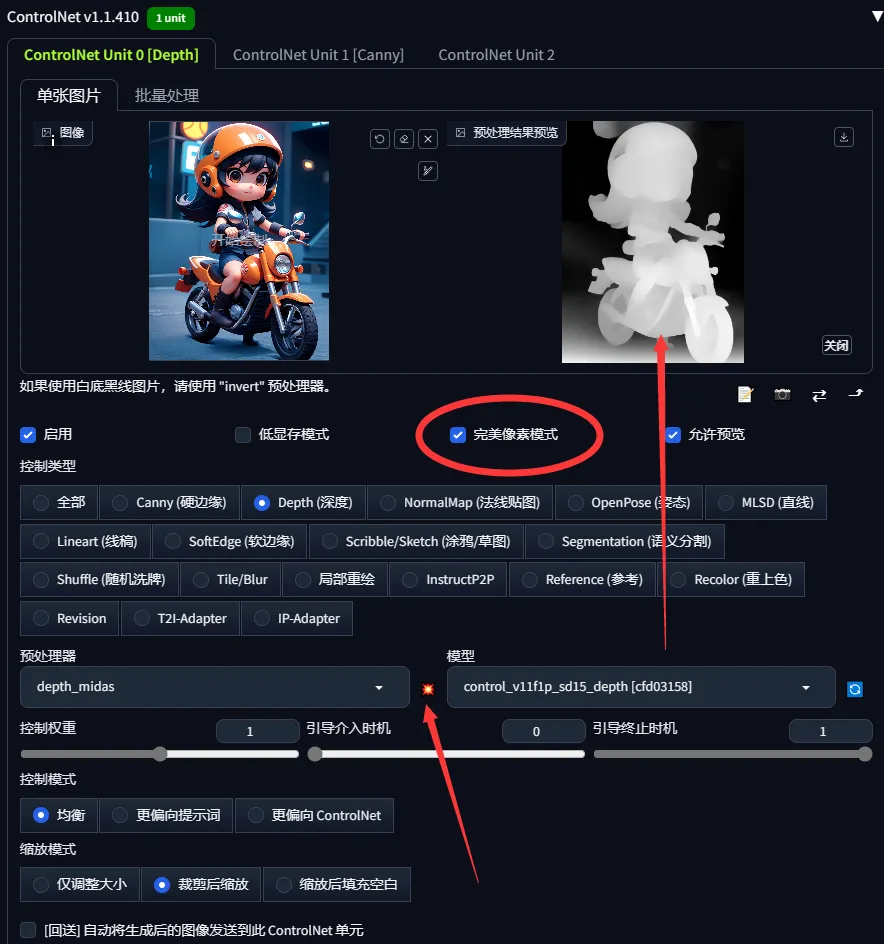
勾選完美像素,點擊爆炸圖標並運行,待深度圖生成後點擊生圖,下方為效果
勾選完美像素,點擊爆炸圖標運行深度圖,生成後點擊生圖以查看效果。

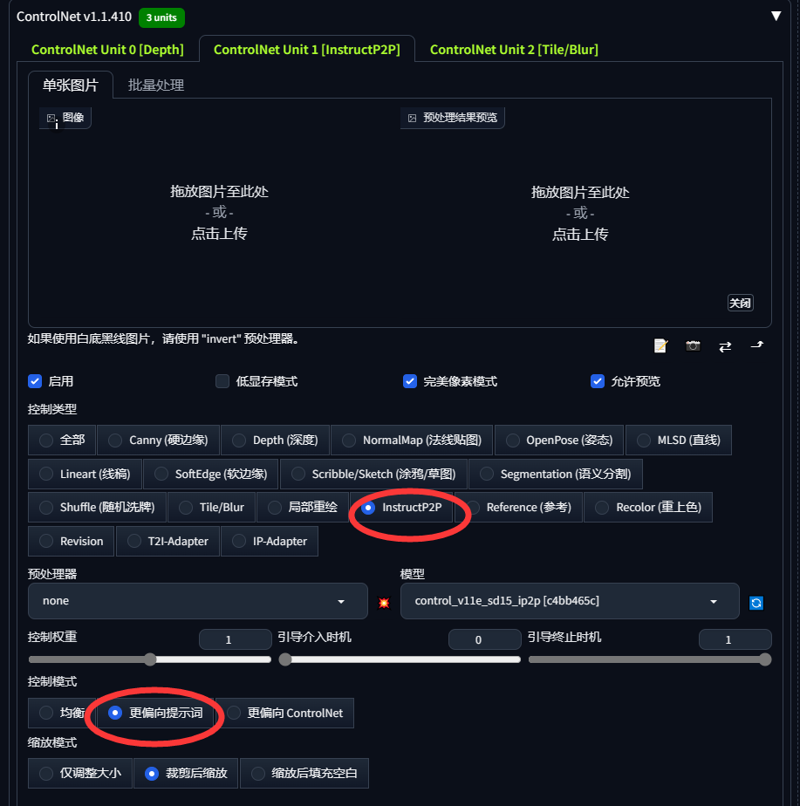
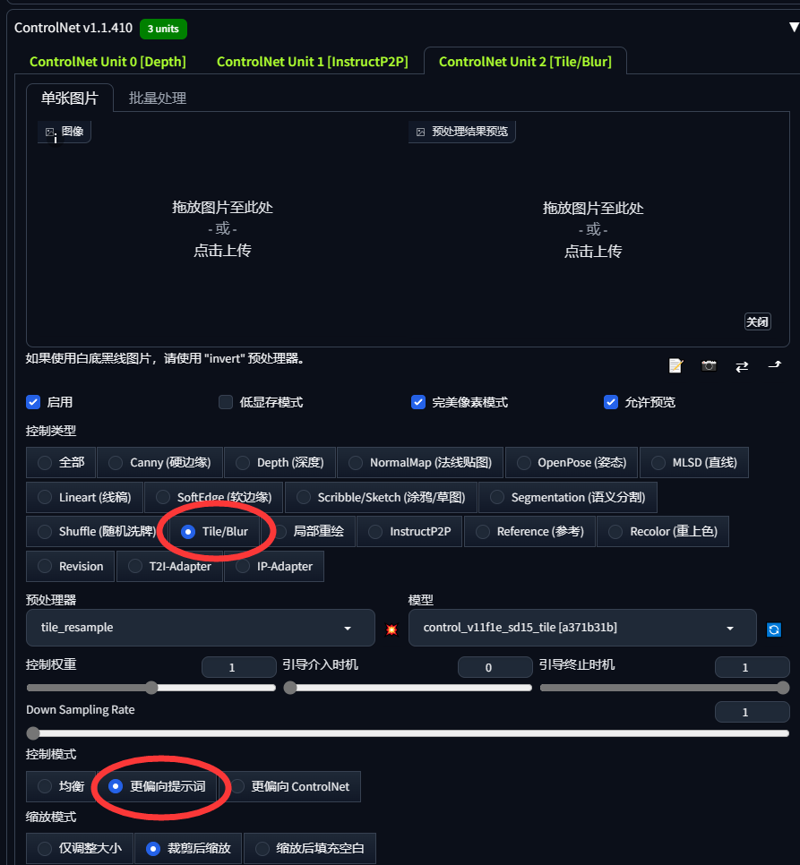
大部分場景只需使用ControlNet深度圖,部分場景若需還原細節,可在ControlNet unit1、unit2額外加入插件如Canny(硬邊緣)、Lineart(線稿)、SoftEdge(軟邊緣)等輔助出圖效果
大多數場景只需使用ControlNet深度圖,有些場景若需還原細節,可在ControlNet unit1,unit2加上Canny(硬邊緣)、Lineart(線稿)、SoftEdge(軟邊緣)等插件來輔助出圖效果。
這是我個人使用的ControlNet插件參數
這是我個人使用的ControlNet插件參數。
我使用的prompt
我使用的prompt
(masterpiece, best quality, unity 8k wallpaper, highres, absurdres, background)
中間插入反推的prompt
中間加入反推提示詞
(NSFW:0.8),
圖像來源及訓練代碼均來源於互聯網,模型僅用於科研交流。如有侵權,請聯繫刪除,謝謝。
圖像來源及訓練代碼均來自互聯網,模型僅用於科研興趣交流。如有侵權,請聯繫刪除,謝謝。------------------------------------------------------------------------------------------
v1.0使用建議(v1.0 Recommendations of use):
建議搭配其他lora使用,lora權重建議約0.8左右,若人物尚無PVC材質,請將lora權重調低一些。
建議使用其他LORAs搭配本模型時,lora權重約為0.8,如人物無PVC材質,請適當降低權重。
建議起手提示詞(Suggest a hand):
best quality, masterpiece, realistic, HDR, UHD, 8K, best quality, masterpiece, highly detailed, ultra-fine painting, physically-based rendering, extreme detail description, professional, 1girl,
若輸出畫面模糊,建議使用Ultimate SD upscale進行放大。
若輸出畫面不清晰,建議使用Ultimate SD upscale放大處理。
------------------------------------------------------------------------------------------
推薦參數(Recommended parameters):
採樣方法(Sampler:):
Euler a: 20~30步。
DPM++ 2S a Karras:25~30步。
DPM++ SDE Karras:20~30步。
DPM++ 2M SDE Karras:20~40步。
提示詞引導係數(CFG Scale):7
人物分辨率(Character resolution):512x768, 768x768,512x1024
高清修復(Hires.fix):
放大演算法:R-ESRGAN 4x+Anime6b,4x-UltraSharp,4x_SmolFace_200k
高分迭代步數:10~15
重繪幅度:0.3~ 0.5
Clip Skip:2。
負面(Negatives): (最差質量, 低質量:2), 單色, 殭屍, (手指交叉:1.2),
------------------------------------------------------------------------------------------
模型反饋請站內私訊
圖像來源及訓練代碼均來自互聯網,模型僅用於科研興趣交流。如有侵權,請聯繫刪除,謝謝。
The image source and training code are from the Internet, and the model is only used for scientific interest exchange. If there is infringement, please contact to delete, thank you.

模型合集 - PVC Style ModelMovable figure model

[PVC風格模型]可動手辦模型 - v2.0(無vae) 的圖片
基礎模型 圖片
