Stable Cascade - 基礎版
精選圖片


推薦參數
steps
resolution
提示
使用階段 C 的 36 億參數版本以獲得最佳效果,因主要微調工作基於該版本完成。
階段 B 建議使用 15 億參數版本,能更好地重建細小且精細的細節。
模型因潛在空間較小,適合高效訓練與推理,且支持微調、LoRA、ControlNet、IP-Adapter 和 LCM 等擴展。
該模型僅限於研究用途,禁止用於生成事實性內容或違反 Stability AI 可接受使用政策。
由於模型的自動編碼有損失,面孔和人物生成可能不夠準確。
創作者贊助
演示:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
演示:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
此模型基於 Würstchen 架構,與 Stable Diffusion 等其他模型的主要區別在於它在更小的潛在空間中運作。
這點為何重要?潛在空間越小,推理速度越快,且訓練成本越低。
潛在空間有多小?Stable Diffusion 使用 8 倍壓縮因子,將 1024x1024 的圖像編碼為 128x128。Stable Cascade 則達到 42 倍壓縮,能將 1024x1024 圖像編碼成 24x24,同時保持清晰的重建效果。該文本條件模型在高度壓縮的潛在空間中進行訓練。該架構的先前版本相較 Stable Diffusion 1.5 實現 16 倍的成本降低。<br> <br>
因此,此類模型非常適合重視效率的使用場景。此外,所有已知擴展如微調、LoRA、ControlNet、IP-Adapter、LCM 等也皆可透過此方法實現。
模型細節
模型描述
Stable Cascade 是一款訓練用以根據文本提示生成圖像的擴散模型。
開發者: Stability AI
資助者: Stability AI
模型類型: 生成文本到圖像模型
模型來源
研究用途推薦訪問我們的 StableCascade Github 倉庫 (https://github.com/Stability-AI/StableCascade)。
模型概述
Stable Cascade 由三個模型組成:階段 A、階段 B 和階段 C,組成生成圖像的級聯,故名“Stable Cascade”。
階段 A 和 B 用於圖像壓縮,類似 Stable Diffusion 中 VAE 的作用。
但該設置能實現更高比例的圖像壓縮。Stable Diffusion 使用 8 倍空間壓縮,將解析度為 1024 x 1024 的圖像編碼為 128 x 128,Stable Cascade 則達到 42 倍壓縮,將 1024 x 1024 編碼為 24 x 24,且能精確解碼圖像。這帶來了訓練和推理成本更低的巨大好處。此外,階段 C 負責根據文本提示生成小尺寸的 24 x 24 潛在向量。以下圖片為該流程的視覺展示。
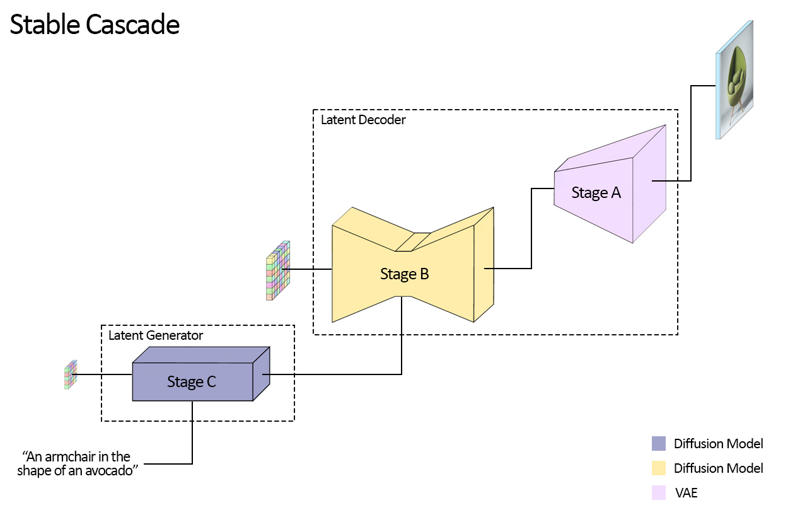
此次發布提供階段 C 兩個檢查點,階段 B 兩個檢查點和階段 A 一個檢查點。階段 C 有 10 億和 36 億參數版本,強烈建議使用 36 億版本,因大部分微調工作在此版本完成。階段 B 的兩個版本分別為 7 億和 15 億參數,兩者均有優秀表現,但 15 億版本更擅長重建細小細節。因此,使用較大版本可獲得最佳效果。階段 A 由於規模小(2000 萬參數)故為固定模型。
評估
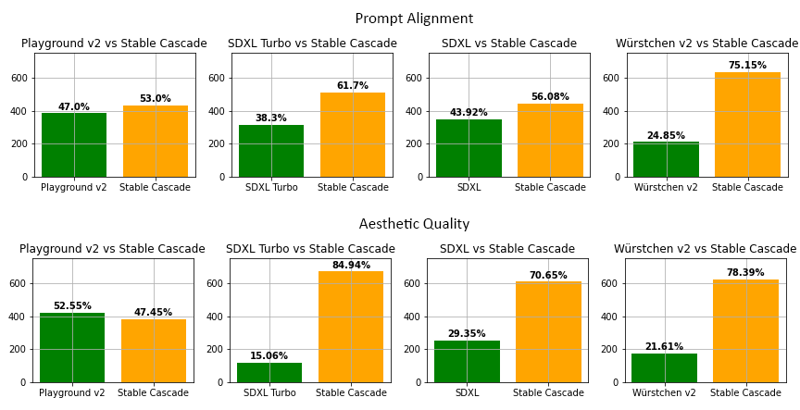
根據我們的評估,Stable Cascade 幾乎在所有比較中,在提示對齊和美學質量方面表現最佳。上述圖片展示了使用混合部分提示(連結)和美學提示的人類評估結果。具體而言,Stable Cascade(30 推理步驟)對比 Playground v2(50 推理步驟)、SDXL(50 推理步驟)、SDXL Turbo(1 推理步驟)以及 Würstchen v2(30 推理步驟)。
代碼示例
⚠️ 注意:為使以下代碼正常運行,你需要安裝當前 PR 正在進行中的 diffusers 分支。
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Anthropomorphic cat dressed as a pilot"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#現在 decoder_output 是包含你的 PIL 圖像的列表用途
直接使用
該模型目前主要服務於研究用途。可能的研究領域和任務包括:
生成模型研究。
安全部署具有生成有害內容潛力的模型。
探查並理解生成模型的限制與偏差。
藝術創作生成及設計等藝術過程應用。
教育或創意工具中的應用。
以下描述的用途不在模型適用範圍內。
超出適用範圍的用途
該模型未經訓練用以生成人物或事件的事實性或真實表徵,
因此將其用於生成此類內容不屬於模型能力範圍內。
模型不得用於任何違反 Stability AI 可接受使用政策的方式。
限制與偏差
限制
人物與面孔生成可能不夠準確。
模型的自動編碼部分存在資料損失。
建議
該模型僅用於研究目的。
如何開始使用該模型

模型合集 - Stable Cascade

Stable Cascade - 基礎版 的圖片
動畫 圖片










藝術 圖片










基礎模型 圖片

logo 圖片










