Animagine XL 4.0 - v4 Opt
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder





Empfohlene Prompts
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
Empfohlene Negative Prompts
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
Empfohlene Parameter
samplers
steps
cfg
resolution
Tipps
Verwenden Sie tag-basierte Beschriftungen mit der Tag-Ordering-Methode für bessere Ergebnisse: 1girl/1boy/1other, Charaktername, Serie, Bewertung, andere Tags, dann Qualitätsverbesserung.
Fügen Sie Qualitätsverbesserungs-Tags am Ende des Prompts hinzu: masterpiece, high score, great score, absurdres.
Verwenden Sie empfohlene negative Prompts, um unerwünschte Artefakte und Fehler zu vermeiden.
Optimale CFG-Skala liegt zwischen 4 und 7, empfohlen 5.
Optimale Sampling-Schritte zwischen 25 und 28, empfohlen 28.
Bevorzugter Sampler ist Euler Ancestral (Euler a).
Beachten Sie die Modellbeschränkungen wie Schwierigkeiten bei komplexer Anatomie und Textdarstellung.
Neuere Charaktere können aufgrund begrenzter Trainingsdaten geringere Genauigkeit haben.
Versions-Highlights
Mit der Veröffentlichung von Animagine XL 4.0 Opt (Optimiert) wurde das Modell mit einem zusätzlichen Datensatz weiter verfeinert, um seine Leistung für den allgemeinen Gebrauch zu verbessern. Dieses Update bringt mehrere Verbesserungen:
Verbesserte Stabilität für konsistentere Ergebnisse
Verbesserte Anatomie mit genaueren Proportionen
Reduziertes Rauschen und Artefakte bei Generierungen
Behobene Probleme mit niedriger Farbsättigung, was zu kräftigeren Farben führt
Verbesserte Farbgenauigkeit für ansprechendere visuelle Resultate
Ersteller-Sponsoren
Unterstützen Sie die Entwicklung von Animagine XL
- Spenden Sie ETH/USDT an
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - GitHub Sponsors: https://github.com/sponsors/cagliostrolab/
- Treten Sie der Discord-Community bei: https://discord.gg/cqh9tZgbGc
Bitte lesen Sie unsere ausführlichen Richtlinien zum Prompting im Cagliostrolab Blog
Übersicht
Animagine XL 4.0, auch stilisiert als Anim4gine, ist das ultimative auf Anime-Themen feinabgestimmte SDXL-Modell und die neueste Ausgabe der Animagine XL Serie. Obwohl es eine Fortsetzung ist, wurde das Modell von Grund auf anhand von Stable Diffusion XL 1.0 mit einem umfangreichen Datensatz von 8,4 Millionen vielfältigen Anime-Stil Bildern aus verschiedenen Quellen mit Wissensstichtag 7. Januar 2025 erneut trainiert und ca. 2650 GPU-Stunden feinabgestimmt. Wie die vorherige Version wurde dieses Modell mit der Tag-Ordering-Methode für Identitäts- und Stiltraining trainiert.
Mit der Veröffentlichung der Animagine XL 4.0 Opt (Optimiert)-Version wurde das Modell mit einem zusätzlichen Datensatz weiter verfeinert, wodurch Stabilität, Anatomiegenauigkeit, Rauschreduktion, Farbsättigung und Gesamtfarbgenauigkeit verbessert wurden. Diese Verbesserungen machen Animagine XL 4.0 Opt konsistenter und visuell ansprechender bei gleichbleibender charakteristischer Qualität der Serie.
Änderungsprotokoll
- 2025-02-13 – Hinzugefügt: Animagine XL 4.0 Opt und Animagine XL 4.0 Zero
Bessere Stabilität für konsistentere Ergebnisse
Verbesserte Anatomie mit genaueren Proportionen
Reduziertes Rauschen und Artefakte in den Generierungen
Behobene Probleme mit niedriger Farbsättigung, was zu satteren Farben führt
Verbesserte Farbgenauigkeit für visuell ansprechendere Resultate
- 2025-01-24 – Erste Veröffentlichung
Modelldetails
Entwickelt von: Cagliostro Research Lab
Modelltyp: Diffusionsbasiertes Text-zu-Bild-Generierungsmodell
Lizenz: CreativeML Open RAIL++-M
Modellbeschreibung: Ein Modell, das speziell für die Erzeugung und Modifikation von Anime-Themen-Bildern auf Basis von Texteingaben verwendet werden kann
Feinabgestimmt von: Stable Diffusion XL 1.0
Nutzungsrichtlinien
Eine Zusammenfassung ist im Bild für die Prompt-Richtlinien zu sehen.

1. Prompt-Struktur
Das Modell wurde mit tagbasierten Beschriftungen und der Tag-Ordering-Methode trainiert. Nutzen Sie diese strukturierte Vorlage:
1girl/1boy/1other, Charaktername, aus welcher Serie, Bewertung, alles andere in beliebiger Reihenfolge und Abschluss mit Qualitätsverbesserung
2. Qualitätsverbesserungs-Tags
Fügen Sie diese Tags am Ende Ihres Prompts hinzu:
masterpiece, high score, great score, absurdres
3. Empfohlener negativer Prompt
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Optimale Einstellungen
CFG-Skala: 4-7 (5 empfohlen)
Sampling-Schritte: 25-28 (28 empfohlen)
Bevorzugter Sampler: Euler Ancestral (Euler a)
5. Empfohlene Auflösungen
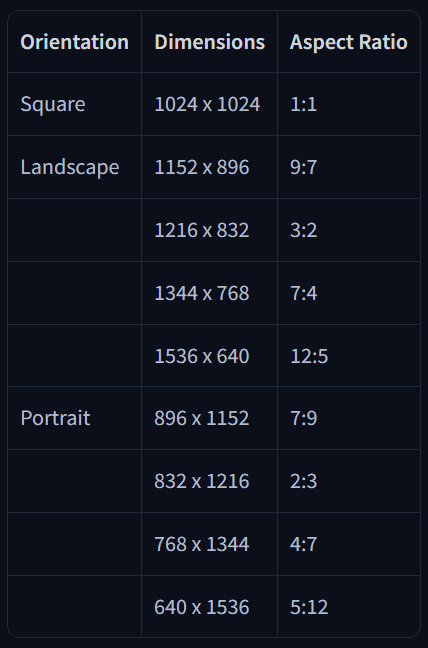
6. Beispiel für finale Prompt-Struktur
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
Spezial-Tags
Das Modell unterstützt verschiedene Spezial-Tags, die verwendet werden können, um unterschiedliche Aspekte des Bildgenerierungsprozesses zu steuern. Diese Tags sind sorgfältig gewichtet und getestet, um konsistente Ergebnisse über verschiedene Prompts hinweg zu gewährleisten.
Qualitäts-Tags
Qualitäts-Tags sind grundlegende Steuerungen, die die Gesamtbildqualität und das Detaillierungsniveau direkt beeinflussen. Verfügbare Qualitäts-Tags:
masterpiecebest qualitylow qualityworst quality
Score-Tags
Score-Tags bieten eine differenziertere Steuerung der Bildqualität als grundlegende Qualitäts-Tags. Sie haben einen stärkeren Einfluss auf die Steuerung der Ausgabequalität bei diesem Modell. Verfügbare Score-Tags:
high scoregreat scoregood scoreaverage scorebad scorelow score
Temporale Tags
Temporale Tags erlauben es, den künstlerischen Stil basierend auf bestimmten Zeiträumen oder Jahren zu beeinflussen. Dies kann nützlich sein, um Bilder mit epoche-spezifischen künstlerischen Eigenschaften zu erzeugen. Unterstützte Jahres-Tags:
year 2005year {n}year 2025
Bewertungs-Tags
Bewertungs-Tags helfen, das Sicherheit-Niveau der generierten Inhalte zu kontrollieren. Diese Tags sollten verantwortungsbewusst und gemäß den geltenden Gesetzen und Plattformrichtlinien verwendet werden. Unterstützte Bewertungen:
safesensitivensfwexplicit
Trainingsinformationen
Das Modell wurde mit modernster Hardware und optimierten Hyperparametern trainiert, um die höchste Ausgabequalität sicherzustellen. Nachfolgend finden Sie die detaillierten technischen Spezifikationen und Parameter, die während des Trainings verwendet wurden:

Danksagung
Dieses Langzeitprojekt wäre nicht ohne die bahnbrechende Arbeit, innovativen Beiträge und umfassende Dokumentation von Stability AI, Novel AI und Waifu Diffusion Team möglich gewesen. Wir sind besonders dankbar für den Kickstarter-Zuschuss von Main, der uns den Fortschritt über V2 hinaus ermöglichte. Für diese Iteration möchten wir allen in der Community unseren aufrichtigen Dank für ihre fortwährende Unterstützung aussprechen, insbesondere:
Moescape AI: Unser unschätzbarer Kooperationspartner bei Modellverteilung und Tests
Lesser Rabbit: Für die Bereitstellung essenzieller Computer- und Forschungsgelder
Kohya SS: Für die Entwicklung des umfassenden Open-Source-Trainingsframeworks
discus0434: Für die Erstellung des branchenführenden Open-Source Aesthetic Predictors 2.5
Frühe Tester: Für ihren Einsatz zur Bereitstellung kritischen Feedbacks und umfassender Qualitätssicherung
Mitwirkende
Wir sprechen unseren herzlichen Dank an unser engagiertes Team aus, das wesentlich zu diesem Projekt beigetragen hat, darunter unter anderen:
Modell
Gradio
Beziehungen, Finanzen und Qualitätssicherung
Daten
Spendenaktionen sind wieder geöffnet!
Wir freuen uns, neue Spendenmethoden über GitHub Sponsors einzuführen, um Training, Forschung und Modellentwicklung zu unterstützen. Ihre Unterstützung hilft uns, die Grenzen des mit KI Möglichen zu erweitern.
Sie können uns unterstützen durch:
Spenden: Beitrag via ETH oder USDT an die untenstehende Adresse.
Teilen: Verbreiten Sie die Informationen über unsere Modelle und teilen Sie Ihre Kreationen!
Feedback: Lassen Sie uns wissen, wie wir uns verbessern können.
Spendenadresse:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
GitHub Sponsor: https://github.com/sponsors/cagliostrolab/
Warum verwenden wir Kryptowährung?:
Als wir ursprünglich Spenden über Ko-fi öffneten und PayPal als Auszahlungsweg nutzten, wurde unser PayPal-Konto markiert und letztlich gesperrt, trotz unserer Bemühungen, den Zweck des Projekts zu erklären. Leider mussten wir alle Spenden zurückerstatten und hatten keine verlässliche Möglichkeit der Unterstützung mehr. Um solche Probleme zu vermeiden und Transparenz zu gewährleisten, haben wir nun auf Kryptowährung als Spendemethode umgestellt.
Möchten Sie in Nicht-Krypto-Währung spenden?
Obwohl wir schlechte Erfahrungen mit PayPal gemacht haben, können Sie uns unterstützen, falls Sie Krypto nicht nutzen möchten, indem Sie sich über Discord Server an uns wenden, um alternative Spendenmethoden zu besprechen.
Trete unserem Discord Server bei
Besuchen Sie gerne unseren Discord-Server: https://discord.gg/cqh9tZgbGc
Einschränkungen
Prompt-Format: Beschränkt auf tag-basierte Text-Prompts; natürliche Spracheingaben sind möglicherweise nicht effektiv
Anatomie: Kann Schwierigkeiten mit komplexen anatomischen Details haben, besonders Handposen und Fingerzählung
Textgenerierung: Textdarstellung in Bildern wird derzeit nicht unterstützt und ist nicht empfohlen
Neue Charaktere: Neuere Charaktere können aufgrund begrenzter Trainingsdaten eine geringere Genauigkeit aufweisen
Mehrere Charaktere: Szenen mit mehreren Charakteren erfordern möglicherweise sorgfältige Prompt-Gestaltung
Auflösung: Höhere Auflösungen (z.B. 1536x1536) können Verschlechterungen zeigen, da das Training auf der Original-SDXL-Auflösung basierte
Stil-Konsistenz: Kann spezifische Stil-Tags benötigen, da das Training mehr auf Identitätserhaltung als auf Stil-Konsistenz fokussierte
Lizenz
Dieses Modell verwendet die originale CreativeML Open RAIL++-M Lizenz von Stability AI ohne Modifikationen oder zusätzliche Einschränkungen. Die Lizenzbedingungen bleiben wie in der ursprünglichen SDXL-Lizenz genau festgelegt, einschließlich:
✅ Erlaubt: Kommerzielle Nutzung, Modifikationen, Verteilungen, private Nutzung
❌ Verboten: Illegale Aktivitäten, Erzeugung schädlicher Inhalte, Diskriminierung, Ausbeutung
⚠️ Anforderungen: Lizenzkopie beifügen, Änderungen angeben, Hinweise bewahren
📝 Gewährleistung: Wird "WIE BESEHEN" ohne Garantien bereitgestellt
Bitte beachten Sie die originale SDXL-Lizenz für die vollständigen und rechtsverbindlichen Bedingungen.

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - Animagine XL 4.0
Bilder von Animagine XL 4.0 - v4 Opt
Bilder mit Anime










Bilder mit Basismodell

Bilder mit sdxl


