Colossus Project Flux - v10_Behemoth_AIO_FP16
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder

Empfohlene Prompts
photography of a young woman as an (goth) with (razor cut haircut), a sports car, soft lighting, spray painted with a intricate comic style robot theme and "COLOSSUS X" cyberpunk theme, projection lighting, its night and its raining, biopunk, the road is reflecting shot on Pentax K-1 Mark II with Pentax FA 43mm f-1.9 Limited, Neutral color palette heterochromia (blue and brown) Mixed race, shot on Pentax K-1 Mark II with Pentax FA 43mm f-1.9 Limited, photo by Tami Bone
Empfohlene Negative Prompts
blurry
blurry, low res
Empfohlene Parameter
samplers
steps
cfg
resolution
vae
Tipps
Verwende negative Prompt-Begriffe wie 'blurry', um die Bildqualität zu verbessern.
Für beste Realitätsnähe nutze cfg Guidance zwischen 1,5 und 3, mit 1,8 als guter Balance für realistische Bilder.
Bevorzugte Sampler sind Euler, Heun, DPM++ 2M, deis und DDIM, mit Simple Scheduler als guter Wahl.
Bei einigen Checkpoints ist es notwendig, die Flux Guidance Scale abzuschalten und stattdessen die cfg Scale zu verwenden.
Nutze All-in-One-Modelle für einfache Verwendung, da sie Clip_L, T5xxl und VAE integriert haben.
Für Installation und Workflow siehe offizielle Anleitungen auf civitai.com in der Beschreibung.
Es existieren zwei quantisierte Versionen FP4 und int4: FP4 für Nvidia 50xx GPUs, int4 für 40xx und ältere GPUs (mindestens 20xx GPU erforderlich).
SVDQ Nunchaku Quantifizierung reduziert die Modellgröße drastisch und beschleunigt die Generierung mit geringfügigem Qualitätsverlust.
Versions-Highlights
Diese Version ist noch experimentell. Der Hauptfokus lag darauf, realistischere Ergebnisse zu erzielen. Ich habe es auch geschafft, einige "Flux Lines" zu reduzieren. Dieses Modell basiert auf Colossus Project V5.0_Behemoth, V9.0 und einem weiteren Projekt namens "Ouroborus Project".
Die FP16-Version ist sehr stabil. Bald veröffentliche ich auch eine FP8-Version. Diese Version ist ebenfalls sehr gut, aber nicht so stabil..
Ich lasse dich experimentieren.. Sag mir, was du von dieser Version hältst.
Viel Spaß beim Erstellen :-)
Ersteller-Sponsoren
Wenn dir dieses Modell gefällt und du die Arbeit des Erstellers unterstützen möchtest, überlege eine Spende via Ko-fi.
Schau dir die Quantifizierung von Muyang Li von Nunchakutech für FP4/int4 Versionen an.
Workflow- und Installationsanleitungen findest du unter civitai.com/articles/17313 und civitai.com/articles/17358.
Besuche das Repository für Konvertierung und Quantifizierung: GitHub ComfyUI-nunchaku.
Tief unter einem Berg lebt ein schlafender Riese, fähig entweder der Menschheit zu helfen oder Zerstörung zu schaffen...
Ein Koloss erhebt sich...
Nach meiner SDXL-Serie ist jetzt die FLUX-Serie dieses Projekts an der Reihe... Dieses Mal habe ich das Ganze von Grund auf neu trainiert. Für das Training habe ich meine eigenen Bilder verwendet. Ich habe sie mit meinem schnellen Flux-Modell DemonFlux/Colossus Project schnell + meinem SDXL Colossus Project 12 als Verfeinerer erstellt.
Dieses SD Flux-Checkpoint kann nahezu alles erzeugen. Colossus ist sehr gut darin, extrem realistische Bilder, Anime und Kunst zu erschaffen.
Wenn es dir gefällt, gib mir gerne Feedback. Wenn du mich unterstützen möchtest, kannst du das hier tun. Ich habe einiges Geld investiert, um einen Computer zu bauen, der in der Lage ist, Flux-Modelle zu trainieren. Das Training und Testen braucht auch viel Zeit und Strom.
https://ko-fi.com/afroman4peace
Version V12 "Hephaistos"
Dieses Checkpoint zu veröffentlichen macht mich gleichzeitig glücklich und traurig. V12 wird der letzte Checkpoint dieser Serie sein. Der Hauptgrund sind die kommenden EU-KI-Gesetze. Ein weiterer Grund ist die Lizenz von Flux .1 DEV selbst. Vielen Dank für die Unterstützung! Ich habe im letzten Jahr viel Zeit in dieses Projekt investiert. Nun ist es Zeit, zu einem anderen Projekt überzugehen.
Wie auch immer, ich werde diese Serie auf einem Höhepunkt beenden...
V12 basiert auf V10B "BOB", enthält aber im Wesentlichen die besten Teile dieser Serie, die zu einem Checkpoint zusammengeführt wurden. (Es war das Ergebnis einer neuen Merge-Methode, die etwa 1:30 Stunden dauerte und meinen gesamten 128GB RAM beanspruchte). Ich habe auch die Gesichts- und Hauttexturen im Vergleich zu V10 verbessert. Die Augen sind viel realistischer und "lebendiger" als zuvor.
Teste es selbst und gib mir Feedback zu V12. Dank meiner langsamen Internetverbindung werde ich zuerst das FP8_UNET hochladen. Danach die FP8 "All in One" Version und anschließend FP16_unet und FP16_BEHEMOTH. Ich werde auch versuchen, es in int4 und fp4 zu konvertieren (wünscht mir Glück dabei).
Wie immer gib mir Feedback zu V12.
Version V12 "Behemoth" (AIO)
Dieses "All in One" Modell ist das Beste meiner V12-Serie... und natürlich das Größte :-)
Der Behemoth hat einen individuell angepassten T5xxl und Clip_l im Modell eingebaut. Wenn du Qualität der Quantität vorziehst, ist dies der richtige Checkpoint für dich!
Version V12 FP4/int4
Dank Muyang Li von Nunchakutech, der die Quantifizierung von V12 durchgeführt hat. https://huggingface.co/nunchaku-tech und ihr erstaunliches Nunchaku!
Diese Version ist wirklich beeindruckend. Sie kombiniert Qualität mit Geschwindigkeit wie nie zuvor.
ACHTUNG!
Es gibt zwei Versionen: FP4 und int4. FP4 ist nur für Nvidia 50xx Grafikkarten! Int4 funktioniert mit 40xx und älteren (mindestens eine 20xx Serie Grafikkarte wird benötigt).
Du kannst beide Versionen auch direkt hier herunterladen: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
INSTALLATIONSANLEITUNG und WORKFLOW
Hier ist eine schnelle Installationsanleitung und ein WIP-Workflow.
https://civitai.com/articles/17313
Detaillierte Anleitung für den Workflow
https://civitai.com/articles/17358
Ich arbeite noch an meinen neuen Workflows für Nunchaku... daher ist der folgende Workflow noch sehr WIP (Work in Progress). Ich werde am Wochenende einen ausführlichen Artikel hinzufügen.
Version V12 FP16_B_variant
Dank eines kleinen Fehlers, den ich spät in der Nacht (2 Uhr) gemacht habe, habe ich den "falschen" Checkpoint umbenannt und hochgeladen. Es ist ein sehr experimenteller Checkpoint, der nie veröffentlicht werden sollte. Er ist nicht viel getestet, hat aber bei der Showcase-Erstellung sehr gut abgeschnitten. Er könnte besser sein als die Standardversion.
Er tendiert stärker zu asiatischen Gesichtern. Das liegt daran, dass ich etwas testen wollte, das ich in ein Nebenprojekt, an dem ich noch arbeite, einfließen lassen möchte. Sag mir deine Erfahrungen mit diesem Checkpoint :-)
Version V12 AIO FP8
Diese Version ist eine All-in-One-Version von V12. Das bedeutet, dass alle Clips integriert sind. Sie liefert dieselben Ergebnisse wie die FP8_unet-Version mit meinem individuellen Clip_l.
Version V12 GGUF Q5_1
Diese Version wurde auf Anfrage erstellt. Die Qualität ist nicht schlecht..
Version V10B "BOB"
Dies ist eine alternative Version von V10. Ich habe sie erstellt, um die FP8-Version von V10 zu verbessern. Im Allgemeinen ist die FP8-Version präziser und die Farben besser. Leider habe ich momentan wenig Zeit (RL geht vor). Deshalb hat es so lange gedauert. Lass mich wissen, ob du diese Version bevorzugst. Ich habe auch eine FP16 Version von "BOB". Je nach Feedback ziehe ich auch eine int4 Version in Betracht.
WORKFLOW:
Hier ist der Workflow für V12 und V10: https://civitai.com/articles/17163
Version V10_int4_SVDQ "Nunchaku"
Zuerst möchte ich theunlikely https://huggingface.co/theunlikely danken, der das FP16_Unet in int4_SVDQ konvertiert hat. Besucht seine Seite und hinterlasst ein Like.
Diese Version entspricht mehr oder weniger der FP8-Version. Selbst im normalen Modus meines Workflows ist dieses Ding etwa 2-3-mal schneller als das reguläre Modell. Mit dem "Schnellmodus" im Workflow kann ich ein 2MP-Bild in ca. 19 Sekunden mit meiner 3090ti rendern.
Was ist SVDQ "Nunchaku"?
Diese neue Quantifizierungsmethode schrumpft Flux-Modelle (hier ein natives FP16-Modell) von 24GB auf etwa 6,7GB. Aber das ist nicht alles: Du kannst schneller generieren als je zuvor, ohne zu viel Qualitätsverlust. Sicherlich siehst du einen kleinen Unterschied zu meinem 32GB_Behemoth, aber für dieses Ding brauchst du viel mehr VRAM/RAM um es überhaupt laufen zu lassen.
Weitere Informationen findest du unter: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Installation: Bitte besuche meine Workflow-/Installationsanleitung: https://civitai.com/articles/15610
Version V10 "Behemoth" (FP16_AIO)
Diese Version ist noch experimentell. Der Hauptfokus lag darauf, realistischere Ergebnisse zu erzielen. Ich habe es auch geschafft, einige "Flux Lines" zu reduzieren. Dieses Modell basiert auf Colossus Project V5.0_Behemoth, V9.0 und einem weiteren Projekt namens "Ouroborus Project".
Die FP16-Version ist sehr stabil. Bald veröffentliche ich auch eine FP8-Version. Diese Version ist auch sehr gut, aber nicht so stabil..
Ich lasse dich experimentieren.. Sag mir, was du von dieser Version hältst.
Viel Spaß beim Erstellen :-)
Version V9.0:
Ich muss viel erklären.. Warum ist es überhaupt V9.0?
Ich bin vor kurzem in eine neue Wohnung gezogen, und wegen einiger Fehler des Internetanbieters hatte ich keine richtige Internetverbindung. Während des Umzugs lief mein Computer weiter. Das Ergebnis war, dass ich viele (meist fehlerhafte) Checkpoints erzeugt habe. Ich habe aber auch einige sehr gute V8-Versionen, die ich vielleicht veröffentlichen werde..
Was hat sich geändert?
Ich habe neue Gesichter und Hauttexturen trainiert, indem ich im Wesentlichen die besten Ergebnisse von V5.0 genommen habe. Außerdem wurde das Modell auf Füße/Beine trainiert für bessere Anatomie. Die V5.0-Versionen haben manchmal Kopf und Füße abgeschnitten. Ich denke, ich konnte einige dieser Probleme beheben..
Zusätzlich habe ich es mit mehr eigenen Landschaftsbildern trainiert.. Und ja, das alles während des Umzugs. Die gesamte Trainingszeit betrug etwa 2 Wochen, was nicht billig ist (jede Stunde kostet mich etwa 25 Cent Strom).
Ich hoffe, dir gefällt diese Version. Wenn du mich unterstützen möchtest: Poste schöne Bilder oder gib mir vielleicht auch einen Tipp über Buzz oder Ko-fi..
Sag mir, was du denkst :-)
Version 5.0:
V5.0 basiert eigentlich auf V4.2 und V4.4 (die bald auch veröffentlicht wird). Es wurde zusätzlich auf Hautdetails und Anatomie trainiert, was größtenteils Probleme wie Hände und Nippel gelöst hat. Die Gesichtsdetailles sind deutlich besser. Ich habe auch versucht, einige kleinere Flux Lines zu beheben..
Im Allgemeinen ist diese Version realistischer als V4.2 und besser bei kleineren Details. Wie Version 4.2 ist diese Version auch ein hybrides de-distilled Modell. Du kannst es grundsätzlich mit denselben Einstellungen wie V4.2 verwenden.
Hier gibt es auch einen neuen Workflow zum Ausprobieren: https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Sag mir, wie du diese Version im Vergleich zu 4.2 oder V2.1 findest..
Version 4.4 "Research":
Ich habe diese Version nur der Vollständigkeit halber hinzugefügt. Sie ist etwas realistischer als V4.2 und die Basis für Version 5.0. Du kannst sie gerne ausprobieren. Du kannst auch den Workflow für V5.0 und V4.2 nutzen..
Version 4.2:
Diese Version ist im Grunde eine Weiterentwicklung von Demoncore Flux und Colossus Project Flux. Ziel war es, stabilere Ergebnisse mit besseren Hauttexturen, besseren Händen und mehr Vielfalt bei Gesichtern zu erzielen. Daher habe ich es auf einem Hybridmodell trainiert, das teilweise Demoncore Flux ist. Ich habe auch Nippel und NSFW etwas verbessert. Sag mir, ob du V4.2 gegenüber Version 2.1 bevorzugst :-)
Für die Showcase-Bilder habe ich ausschließlich native Bilder mit SDXL-Auflösung oder 2MP-Auflösung (z.B. 1216x1632) verwendet. Dieses Modell kann sogar höhere Auflösungen verarbeiten. Ich habe diesen Checkpoint bis zu 2500x2500 getestet, empfehle aber ca. 2000x2000 als Ziel.
Für die Einstellungen empfehle ich etwa 30 Schritte und 2-2,5 cfg. Ich nutze meist 2,2 oder 2,3 in meinem Workflow. Für die Showcases habe ich DPM++ 2M mit Simple Scheduler verwendet.
Ich werde bald mehr Versionen hinzufügen, habe aber vor Weihnachten wenig Zeit..
Einstellungen
Ich werde bald einen neuen dedizierten Comfy-Workflow hinzufügen. Du kannst jetzt schon die Showcase-Bilder herunterladen und öffnen..
Die "All in One" Version funktioniert auch gut mit Forge..
Im Grunde funktionieren die gleichen Einstellungen wie bei Version 2.1 (siehe unten).
Nimm 20-30 Schritte mit etwa 2,2 cfg..
Version 2.1_de-distilled_experimental (MERGE)
Diese Version ist komplett anders und funktioniert tatsächlich anders als ein normales Flux-Modell!
Es ist ein experimenteller Merge zwischen meiner Version 2.0 und einer de-distilled Version https://huggingface.co/nyanko7/flux-dev-de-distill. Das geschah etwas zufällig, aber die Ergebnisse sind beeindruckend. Du bekommst atemberaubende Details. Außerdem folgen die Prompts extrem gut... Als nächstes werde ich direkt auf dem de-distilled Modell trainieren. Ich habe bereits einige Test-Loras damit gemacht. Das ist hochgradig experimentell, also gib mir bitte Bescheid, wenn du Fehler findest, die unten nicht aufgelistet sind. Wenn du gute Bilder hast, poste sie.. poste auch schlechte, das hilft zur Verbesserung :-). Versuch auch mal Version 2.0 und sag mir, welcher Checkpoint-Typ dir besser gefällt.
Achtung!
Der normale Flux-Workflow funktioniert nicht mit dieser Version. DU MUSST meinen Workflow herunterladen!
Du kannst auch selbst etwas herausfinden, aber bitte beschwere dich nicht bei schlechten Bildern. Außerdem ist dies ein hoch experimentelles Modell... siehe Nachteile unten.
Vor- und Nachteile dieses Checkpoints:
Dieser Checkpoint kann extrem detaillierte Bilder erzeugen. Das hat seinen Preis. Er ist langsamer als normale Flux-Checkpoints. Vorteil: Oft braucht man kein zusätzliches Upscale mehr. Statt Flux Guidance nutzt dieses Modell die cfg scale, was bedeutet, dass es mit Standard-Workflows nicht funktioniert.
Du kannst negative Prompts verwenden! Das hilft, unerwünschte Dinge aus dem Bild zu entfernen.
Manchmal können Artefakte auftreten. Das kannst du durch eine kleine und einfache Skalierung beheben (ich arbeite daran). Hier ein Beispiel: Das passiert merkwürdigerweise nicht bei jedem Seed. UPDATE: Dies ist kein Problem des Modells selbst, sondern ein Workflow-Problem. Ich arbeite an einer Lösung. Falls es passiert, kannst du versuchen, die erste Skalierung auf 1,14 statt 1,2 zu setzen.

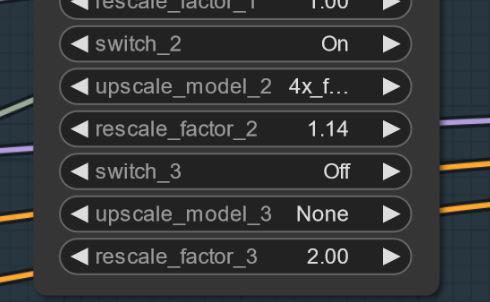
Einstellungen und Workflow V2.1:
Hier ist der Workflow dazu: https://civitai.com/articles/8419
Einstellungen: Anders als beim normalen Flux braucht es nicht die Flux Guidance Scale. Nutze stattdessen den cfg. Ich verwende meistens 3 cfg im Workflow. Manche Bilder kommen mit niedrigeren cfg-Werten besser klar.
Wichtig ist, die Flux Guidance Scale abzuschalten..
Ohne Workflow habe ich 30 Schritte und 2-3 cfg getestet. Das könnten auch die Einstellungen für Forge sein. Experimentiere ruhig.
Ich empfehle, "blurry" als negatives Stichwort zu verwenden.
Sampler und Scheduler:
Du kannst aus verschiedenen funktionierenden Samplern auswählen:
Euler, Heun, DPM++2M, deises, DDIM funktionieren gut.
Ich habe meist „simple“ als Scheduler verwendet.
Wenn du bessere Einstellungen findest, sag mir Bescheid.. :-)
Für Forge empfehle ich das AIO-Modell. Hier ein Beispiel für eine Forge-Einstellung:
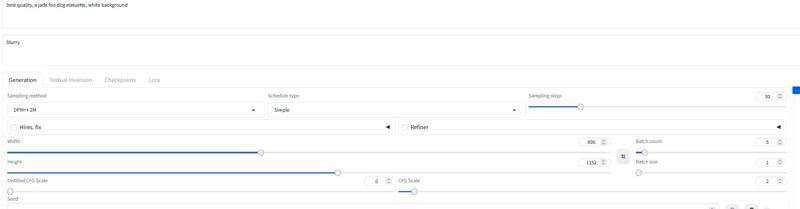
Version 2.0_dev_experimental
Nun.. dies ist eine experimentelle Version.. Ziel war es, ein kohärenteres und schnelleres Modell zu erstellen. Ich habe einige zusätzliche eigene trainierte Loras eingebaut und dann die resultierenden Modelle auf spezielle Weise zusammengeführt (Tensor Merge). Es hat einen passt angepassten T5xxl, den ich mit "Attention Seeker" modifiziert habe. Um Geschwindigkeit und Qualität zu gewinnen, habe ich die Hyper Flux Lora von ByteDance integriert. Das bedeutet, dass der Arbeitsbereich verschoben wurde.. Hier ist das Haupttitelbild..
16 Schritte V 2.0
 30 Schritte V 1.0
30 Schritte V 1.0
 Nachteile:
Nachteile:
Erstens ist diese Version etwas größer als die letzte. Zweitens muss ich noch die reine Unet-Version erstellen. Ich werde das aktualisieren, wenn es fertig ist..
Einstellungen und Workflow V2.0:
Du kannst das Modell jetzt mit weniger Schritten laufen lassen. 16 Schritte entsprechen 30 Schritten des alten Modells.
Ich empfehle trotzdem etwa 20-30 Schritte, da du damit in den meisten Fällen bessere Qualität bekommst.
Sampler: Ich bevorzuge Euler mit Simple als Scheduler. Die Guidance kannst du zwischen 1.5 und 3 einstellen (du kannst gerne auch außerhalb dieses Bereichs testen). Eine Guidance von 1.8 funktioniert gut für realistische Bilder. Probiere auch andere Sampler aus. DPM++2M und Heun funktionieren ebenfalls sehr gut.
Workflow 2.0:
Ich habe einen neuen Workflow für V2.0 und V1.0 erstellt. Dieser enthält den neuen Flux Prompt Generator. Außerdem läuft die zweite Upscaler-Stufe. https://civitai.com/articles/7946
Forge:
Ich habe dieses Modell auch mit Forge getestet, und es funktioniert sehr gut. Die Bilder können zwischen Comfy UI und Forge jedoch leicht variieren..
Version 1.0_dev_beta:
Dieses Modell ist mein erster Eintrag der Serie. Bitte gib mir Feedback und poste Bilder. Das hilft mir, das Projekt weiter zu verbessern. Es gibt mehrere Versionen zur Auswahl. Das beste Modell bezüglich Qualität ist die FP16 Version. Sie ist groß und benötigt eine starke Grafikkarte und viel RAM. Die FP8 Version ist meiner Meinung nach ein guter Kompromiss zwischen Qualität und Performance. Wenn du eine GGUF-Version möchtest, lade die Q8_0 herunter. Die GGUF Q4_0/4.1 Version wurde auf Anfrage erstellt. Sie ist klein, aber du verlierst etwas Qualität.
Grundsätzlich gibt es zwei Modelltypen: "All in One" Modelle, die nur eine Datei zum Download benötigen. Diese enthalten Clip_l, T5xxl fp8 und VAE integriert. (siehe unten). Platziere diese in deinem Checkpoints-Ordner.
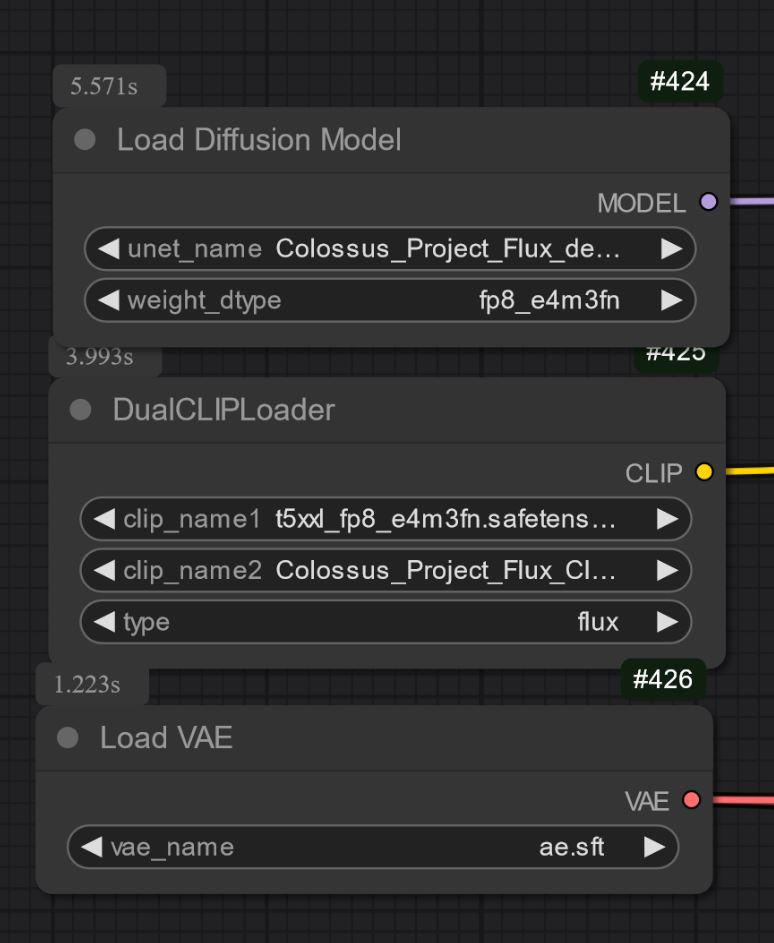
Die anderen Versionen sind die reinen UNET-Versionen. Hier musst du alle Dateien separat laden.
Du musst auf jeden Fall meinen Clip_L herunterladen, damit sie richtig funktionieren..
Wichtig ist auch, den richtigen T5xxl Clip auszuwählen. Für FP8 ist es der fp8_e4m3fn t5xxl Clip. Für FP16 ist es der FP16 Clip. Achte darauf, den Standard Gewichtungstyp auszuwählen. (Unten ein Beispielbild für die fp8 Version)
Für die GGUF Version benötigst du den GGUF Loader!
Einige bekannte Punkte zu V1.0:
Dies ist nur das erste Modell der Serie, weshalb es mit manchen Prompts oder Stilen wie Kunst noch Probleme haben kann. Die nächste Version bekommt mehr Training. Sag mir, was das Modell nicht kann..
Einstellungen und Workflow:
Ich habe es mit etwa 30 Schritten getestet, Euler mit Simple Scheduler. Guidance kann von 1.5 bis 3 eingestellt werden (testen außerhalb geht natürlich auch).
1.8 Guidance funktioniert gut für realistische Bilder.
Experimentiere gerne mit den Einstellungen. Wenn du gute Ergebnisse erzielst, poste sie bitte.
Ich habe die Showcase-Bilder als Trainingsdaten hinzugefügt.. Darin ist der Workflow für Comfy enthalten. Hier der Workflow zum herunterladen: https://civitai.com/articles/7946
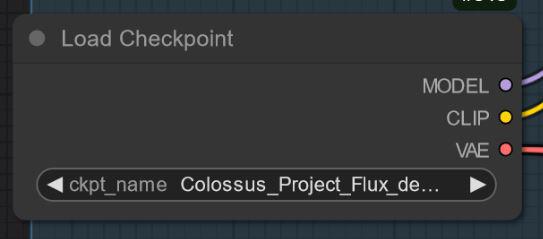
"All in One" Modell:
UNET only:
 Du musst auch den Clip_L herunterladen. Er ist etwa 240MB groß.
Du musst auch den Clip_L herunterladen. Er ist etwa 240MB groß.
GGUF: Den Workflow für GGUF habe ich hier hinzugefügt: https://civitai.com/articles/7946
Wichtig:
Das Dev-Modell ist nicht für kommerzielle Nutzung gedacht. Dafür werde ich das "schnell" Modell an anderer Stelle veröffentlichen. Es ist eher für persönlichen oder wissenschaftlichen Gebrauch gedacht.
LIZENZ:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
Credits:
theunlikely https://huggingface.co/theunlikel (nochmals danke)
Version 2.1/V4.2/5.0: Flux_dev_de-distill von nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
Ab V2.0: Hyper Lora von ByteDance https://huggingface.co/ByteDance/Hyper-SD
Black Forrest für ihr großartiges Flux-Modell https://huggingface.co/black-forest-labs

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8

Colossus Project Flux - v10_int4_SVDQ
















































