Colossus Project Flux - v10_int4_SVDQ
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder

Empfohlene Negative Prompts
blurry
Empfohlene Parameter
samplers
steps
cfg
resolution
vae
Tipps
Verwende negative Prompts mit dem Wort 'blurry', um die Ausgabequalität zu verbessern.
Für FP4-Versionen nur Nvidia 50xx Grafikkarten verwenden; int4 Versionen unterstützen 40xx und darunter (mindestens 20xx Serie).
Die "All in One" Modelle enthalten eingebettete Clip_l, T5xxl und VAE zur Vereinfachung der Nutzung.
Probiere verschiedene Sampler wie Euler, Heun, DPM++2M, deis, DDIM; "Simple" Scheduler empfohlen.
Experimentiere mit der Guidance-Skala (cfg) von 1,5 bis 3, Standard sind etwa 2,2 bis 2,3 für beste Ergebnisse.
Die FP8 Version bietet ein gutes Gleichgewicht zwischen Qualität und Leistung.
Für spezielle ‚de-distilled‘ Versionen deaktivier Flux Guidance und nutze stattdessen cfg.
Wenn Artefakte erscheinen, versuche ein kleines Upscaling (z.B. 1,14x statt 1,2x), um Probleme zu mildern.
Workflows und detaillierte Anleitungen sind über Links zu Civitai Artikeln verfügbar.
Versions-Highlights
Version V10_int4_SVDQ „Nunchaku“
Installation: Bitte besuche meine Workflow/Installationsanleitung: https://civitai.com/articles/15610
Erstmal Danke an theunlikely https://huggingface.co/theunlikely, der das FP16_Unet in int4_SVDQ konvertiert hat. Schaut auf seiner Seite vorbei und lasst ein Like da.
Diese Version entspricht mehr oder weniger der FP8 Version. Selbst im normalen Modus meines Workflows ist dieses Modell ca. 2-3 mal schneller als das reguläre Modell. Im "Schnellmodus" kann ich mit meiner 3090ti ein 2MP Bild in etwa 19 Sekunden rendern.
Was ist SVDQ „Nunchaku“?
Diese neue Quantifizierungsmethode erlaubt es, Flux Modelle (hier ein natives FP16 Modell) von 24GB auf ca. 6,7GB zu schrumpfen. Aber das ist nicht alles: Generationen laufen schneller als je zuvor, ohne große Qualitätsverluste. Natürlich sieht man einen kleinen Unterschied zum 32GB_Behemoth, aber für diesen ist wesentlich mehr VRam/RAM nötig.
Mehr Infos unter: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Ersteller-Sponsoren
Unterstütze den Ersteller auf Ko-Fi: https://ko-fi.com/afroman4peace
Lade quantisierte Modelle von Muyang Li von Nunchakutech herunter: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
Workflow-Anleitungen auf Civitai:
https://civitai.com/articles/17313
https://civitai.com/articles/17358
https://civitai.com/articles/17163
https://civitai.com/articles/15610
https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
https://civitai.com/articles/8419
https://civitai.com/articles/7946
GitHub für Nunchaku SVDQ Quantifizierung: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Tief unter einem Berg lebt ein schlafender Riese, der entweder der Menschheit helfen oder Zerstörung anrichten kann...
Ein Koloss erhebt sich...
Nach meiner SDXL Serie ist es Zeit für die FLUX Serie dieses Projekts... Dieses Mal habe ich das Modell von Grund auf trainiert. Für das Training habe ich eigene Bilder verwendet. Ich habe sie mit meinem schnellen Flux Modell DemonFlux/Colossus Project schnell + meinem SDXL Colossus Project 12 als Verfeinerer erstellt.
Dieses SD Flux-Checkpoint kann fast alles erzeugen.. Colossus erstellt extrem realistische Bilder, Anime und Kunst.
Wenn es dir gefällt, gib mir gerne Feedback. Wenn du mich unterstützen möchtest, kannst du das hier tun. Ich habe einiges an Geld in den Bau eines Computers investiert, der überhaupt in der Lage ist, Flux-Modelle zu trainieren. Training und Tests benötigen auch viel Zeit und Strom..
https://ko-fi.com/afroman4peace
Version V12 „Hephaistos“
Es macht mich gleichzeitig glücklich und traurig, diesen Checkpoint zu veröffentlichen.. V12 wird der letzte Checkpoint dieser Serie sein.. Der Hauptgrund sind die kommenden EU-KI-Gesetze... Ein weiterer Grund ist die Lizenz von Flux .1 DEV selbst. Danke für die Unterstützung! Ich habe im letzten Jahr viel Zeit in dieses Projekt investiert. Jetzt ist es Zeit, zu einem anderen Projekt überzugehen.
Wie auch immer.. Ich werde diese Serie mit einem Höhepunkt beenden...
V12 basiert auf V10B „BOB“, enthält aber grundsätzlich die besten Teile dieser Serie, blockmerged in einem Checkpoint. (Ergebnis einer neuen Merge-Methode, die etwa 1:30h dauerte und meinen gesamten 128GB RAM beanspruchte). Ich habe Gesicht und Hauttexturen im Vergleich zu V10 verbessert. Die Augen sind viel realistischer und lebendiger als zuvor.
Teste es selbst und gib mir Feedback zu V12. "Dank" meiner langsamen Internetverbindung werde ich zuerst das FP8_UNET hochladen, danach die FP8 "All in One"-Version und dann FP16_unet und FP16_BEHEMOTH. Ich werde auch versuchen, es in int4 und fp4 konvertieren zu lassen (wünscht mir Glück).
Wie immer gebt mir Feedback zu V12..
Version V12 „Behemoth“ (All-in-One)
Dieses "All-in-One" Modell ist das beste meiner V12 Serie... und natürlich das größte :-)
Der Behemoth hat ein custom T5xxl und Clip_l im Modell eingebettet. Wenn du Qualität der Quantität vorziehst, ist das dein Checkpoint!
Version V12 FP4/int4
Danke an Muyang Li von Nunchakutech für die Quantifizierung von V12. https://huggingface.co/nunchaku-tech und ihr großartiges Nunchaku!
Diese Version ist wirklich beeindruckend. Kombination aus Qualität und Geschwindigkeit wie nie zuvor.
ACHTUNG!
Es gibt zwei Versionen: FP4 und int4. FP4 ist nur für Nvidia 50xx Grafikkarten! Int4 funktioniert mit 40xx und darunter (mindestens 20xx Serie erforderlich)
Beide Versionen können hier direkt heruntergeladen werden: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
INSTALLATIONSANLEITUNG und WORKFLOW
Hier eine schnelle Installationsanleitung und ein Work-in-Progress Workflow.
https://civitai.com/articles/17313
AUSFÜHRLICHE ANLEITUNG für den Workflow
https://civitai.com/articles/17358
Ich arbeite noch an meinen neuen Workflows für Nunchaku.. daher ist der folgende Workflow noch sehr im Aufbau (WIP). Am Wochenende werde ich einen ausführlichen Artikel ergänzen.
Version V12 FP16_B_variant
Durch einen kleinen Fehler spät in der Nacht (2 Uhr) habe ich den "falschen" Checkpoint umbenannt und hochgeladen. Ein sehr experimenteller Checkpoint, der nicht für die Veröffentlichung gedacht war. Er ist nicht umfangreich getestet, zeigte aber gute Leistung bei der Showcase-Erstellung. Möglicherweise besser als die Standardversion.
Er tendiert mehr in Richtung asiatischer Gesichter.. Das liegt daran, dass ich etwas testen wollte, das ich in einem Nebenprojekt mische, an dem ich noch arbeite. Berichte mir deine Erfahrung mit diesem Checkpoint :-)
Version V12 AIO FP8
Diese Version ist eine All-in-One Variante von V12. Das bedeutet, alle Clips sind integriert. Gibt das gleiche Ergebnis wie die FP8_unet mit meinem custom clip_l.
Version V12 GGUF Q5_1
Diese Version wurde angefragt. Qualität ist nicht schlecht..
Version V10B „BOB“
Eine alternative Version zu V10. Ich habe sie erstellt, um die FP8 Version von V10 zu verbessern. Generell ist die FP8 Version präziser mit besseren Farben. Leider hatte ich zuletzt wenig Zeit (RL geht vor). Daher hat es lange gedauert.. Sag mir, ob du diese Version bevorzugst. Ich habe auch eine FP16 Version von „BOB“. Je nach Feedback erwäge ich auch eine Int4 Version zu veröffentlichen.
WORKFLOW:
Hier ist der Workflow für V12 und V10: https://civitai.com/articles/17163
Version V10_int4_SVDQ „Nunchaku“
Erstmal Danke an theunlikely https://huggingface.co/theunlikely, der das FP16_Unet in int4_SVDQ konvertiert hat. Schaut auf seiner Seite vorbei und lasst ein Like da.
Diese Version entspricht mehr oder weniger der FP8 Version. Selbst im normalen Modus meines Workflows ist dieses Modell ca. 2-3 mal schneller als das reguläre Modell. Im "Schnellmodus" kann ich mit meiner 3090ti ein 2MP Bild in etwa 19 Sekunden rendern.
Was ist SVDQ „Nunchaku“?
Diese neue Quantifizierungsmethode erlaubt es, Flux Modelle (hier ein natives FP16 Modell) von 24GB auf ca. 6,7GB zu schrumpfen. Aber das ist nicht alles: Generationen laufen schneller als je zuvor, ohne große Qualitätsverluste. Natürlich sieht man einen kleinen Unterschied zum 32GB_Behemoth, aber für diesen ist wesentlich mehr VRam/RAM nötig.
Mehr Infos unter: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Installation: Bitte besuche meine Workflow/Installationsanleitung: https://civitai.com/articles/15610
Version V10 „Behemoth“ (FP16_AIO)
Diese Version ist noch experimentell. Hauptziel war es, realistischere Resultate zu erzielen. Außerdem konnte ich einige „Flux Lines“ reduzieren. Basierend auf Colossus Project V5.0_Behemoth, V9.0 und einem weiteren Projekt namens „Ouroborus Project“.
Die FP16 Version ist sehr stabil. Eine FP8 Version wird bald veröffentlicht. Diese ist auch gut, aber nicht so stabil..
Probiert sie gerne aus und sagt mir eure Meinung.
Viel Spaß beim Erstellen :-)
Version V9.0:
Ich muss einiges erklären.. Warum überhaupt V9.0?
Kürzlich bin ich in eine neue Wohnung gezogen und wegen Problemen mit dem Internetanbieter hatte ich keine richtige Internetverbindung. Während des Umzugs lief mein Computer weiter. Das Ergebnis sind viele (meist fehlerhafte) Checkpoints. Sehr gute V8 Versionen habe ich auch, die ich eventuell veröffentliche..
Was hat sich geändert?
Ich habe neue Gesichter- und Hauttexturen trainiert, basierend auf den besten Ergebnissen von V5.0. Außerdem wurde die Anatomie von Füßen/Beinen verbessert. Bei V5.0 wurden manchmal Kopf und Füße abgeschnitten.. Einige dieser Probleme konnte ich beheben..
Zusätzlich trainierte ich mit mehr eigenen Landschaftsbildern.. Und ja, das alles während des Umzugs. Die Trainingszeit betrug insgesamt ca. 2 Wochen Rechenzeit, was nicht günstig ist (jede Stunde kostet ca. 25 Cent Strom).
Ich hoffe, euch gefällt diese Version.. Wenn ihr mich unterstützen wollt: Postet schöne Bilder oder spendet mir etwas bei Buzz oder Ko-fi..
Gebt mir Feedback :-)
Version 5.0:
V5.0 basiert auf V4.2 und V4.4 (wird bald veröffentlicht). Es enthält zusätzliches Training zu Hautdetails und Anatomie, was vor allem Hände und Nippel verbesserte. Gesichtdetails sind deutlich besser. Ich habe auch versucht, einige kleinere Flux-Linien zu korrigieren..
Diese Version ist allgemein realistischer als V4.2 und besser bei kleinen Details. Wie Version 4.2 ist es ein hybrid de-distilled Modell. Es kann mit denselben Einstellungen wie V4.2 verwendet werden.
Hier ist auch ein neuer Workflow zum Ausprobieren: https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Wie findest du diese Version im Vergleich zu 4.2 oder V2.1?
Version 4.4 „Research“:
Zur Vervollständigung hinzugefügt.. Etwas realistischer als V4.2 und Basis für Version 5.0. Kann auch mit den Workflows von V5.0 und V4.2 genutzt werden..
Version 4.2:
Diese Version ist eine Weiterentwicklung von Demoncore Flux und Colossus Project Flux. Ziel war ein stabileres Ergebnis mit besseren Hauttexturen, Händen und einer größeren Vielfalt an Gesichtern. Dafür trainierte ich ein Hybridmodell, das teilweise Demoncore Flux enthält. Ich verbesserte auch Nippel und NSFW leicht. Gib mir Feedback, ob du V4.2 der Version 2.1 vorziehst :-)
Für die Showcases verwendete ich nur native Bilder mit SDXL-Auflösung oder 2MP (z.B. 1216x1632). Das Modell kann sogar höhere Auflösungen verarbeiten.. Bis zu 2500x2500 getestet, empfohlen werden etwa 2000x2000.
Empfohlene Einstellungen: ca. 30 Schritte und 2-2,5 cfg. Ich nutze in meinem Workflow meist 2,2 oder 2,3. Für die Showcases verwendete ich DPM++ 2M mit Simple Scheduler.
Weitere Versionen folgen, derzeit wenig Zeit bis Weihnachten..
Einstellungen
Ich werde bald einen neuen dedizierten Comfy-Workflow hinzufügen. Solange kannst du die Showcase-Bilder herunterladen und öffnen..
Die "All in One"-Version funktioniert auch gut mit Forge..
Grundsätzlich gelten die gleichen Einstellungen wie bei Version 2.1 (siehe unten)
Verwende 20-30 Schritte mit ca. 2,2 cfg..
Version 2.1_de-distilled_experimental (MERGE)
Diese Version ist komplett anders und funktioniert tatsächlich anders als ein normales Flux-Modell!
Es ist ein experimentelles Merge zwischen meiner Version 2.0 und einer de-distilled Version https://huggingface.co/nyanko7/flux-dev-de-distill. Entstanden eher zufällig, aber die Ergebnisse sind beeindruckend. Es entstehen beeindruckende Details und folgt den Prompts sehr gut... Als nächstes werde ich direkt auf dem de-distilled Modell trainieren. Ich habe bereits einige Test-Loras damit gemacht. Sehr experimentell – meldet Fehler, wenn ihr welche findet, auch schlechte Bilder helfen zur Verbesserung :-) Probiert auch Version 2.0 aus und sagt mir, welche Checkpoint-Art dir besser gefällt.
!Achtung!
Der normale Flux-Workflow funktioniert mit dieser Version nicht. DU MUSST meinen Workflow herunterladen!
Du kannst auch selbst etwas rumprobieren, aber bitte beschwere dich nicht über schlechte Bilder. Das Modell ist sehr experimentell – siehe Nachteile unten..
Vorteile und Nachteile dieses Checkpoints:
Dieser Checkpoint erzeugt extrem detailreiche Bilder. Das hat seinen Preis – er ist langsamer als normale Flux-Checkpoints. Vorteil: Meist wird kein zusätzliches Upscaling benötigt. Statt Flux Guidance nutzt dieses Modell die cfg-Skala, was mit Standardworkflows nicht funktioniert.
Du kannst negative Prompts verwenden! Hilft, unerwünschte Elemente aus dem Bild zu entfernen.
Manchmal können Artefakte erscheinen. Löst sich durch kleines Upscaling (z.B. 1,14 statt 1,2) – daran arbeite ich. Beispielbilder:

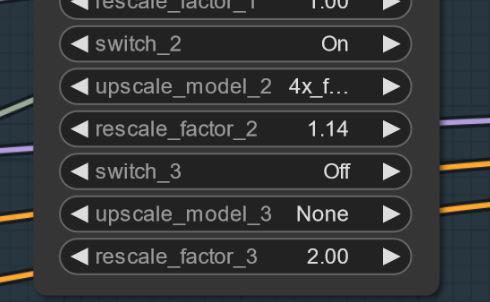
Einstellungen und Workflow V2.1:
Workflow hier: https://civitai.com/articles/8419
Einstellungen: Anders als normales Flux wird die Flux Guidance-Skala nicht benötigt. Stattdessen cfg verwenden, meist 3 cfg in meinem Workflow. Manche Bilder erfordern weniger cfg.
Wichtig: Flux Guidance deaktivieren.
Ohne Workflow habe ich 30 Schritte und 2-3 cfg getestet. Das passt auch für Forge. Probier es aus.
Das Negative Prompts-Wort "blurry" empfiehlt sich.
Sampler und Scheduler:
Verwendbar sind: Euler, Heun, DPM++2m, deis, DDIM – funktionieren gut.
Ich benutze meist "Simple" als Scheduler.
Wenn du bessere Einstellungen findest, sag Bescheid.. :-)
Für Forge empfehle ich das AIO-Modell. Beispiel-Einstellung:
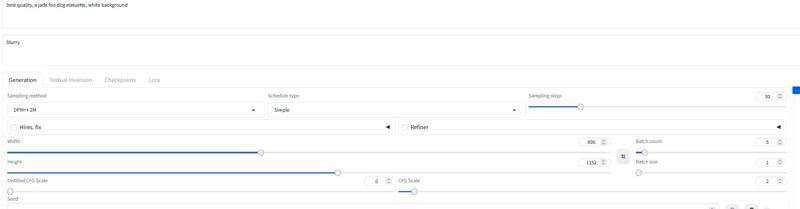
Version 2.0_dev_experimental
Dies ist eine experimentelle Version. Ziel war ein kohärenteres und schnelleres Modell. Ich habe zusätzliche eigene Loras trainiert und die Modelle anschließend speziell (Tensor Merge) zusammengeführt. Enthält ein custom T5xxl, modifiziert mit "Attention Seeker". Zur Steigerung von Geschwindigkeit und Qualität wurde Hyper Flux Lora von ByteDance eingebunden. Das verschob den Arbeitsbereich. Hier ein Haupttitelbild.
16 Schritte V 2.0
 30 Schritte V 1.0
30 Schritte V 1.0
 Nachteile:
Nachteile:
Erstens ist diese Version etwas größer als die letzte. Zweitens fehlt noch die Unet-only Version. Diese werde ich bei Fertigstellung hinzufügen.
Einstellungen und Workflow V2.0:
Das Modell läuft jetzt mit weniger Schritten. 16 Schritte entsprechen 30 Schritten des alten Modells.
Ich empfehle trotzdem 20-30 Schritte für bessere Qualität.
Sampler: Ich bevorzuge Euler mit Simple Scheduler. Guidance meistens 1,5-3 (außerhalb des Bereichs kann getestet werden). Guidance 1,8 funktioniert gut für realistische Bilder. Auch DPM++2M und Heun funktionieren gut.
Workflow 2.0:
Neuer Workflow für V2.0 und V1.0 mit Flux Prompt Generator und zweiter Upscaler-Stufe: https://civitai.com/articles/7946
Forge:
Getestet mit Forge, funktioniert sehr gut. Bilder können zwischen Comfy UI und Forge variieren.
Version 1.0_dev_beta:
Mein Serien-Einstiegsmodell. Bitte gebt Feedback und postet Bilder, um das Projekt zu verbessern. Verschiedene Versionen verfügbar. Die qualitativ beste Variante ist die FP16 Version, welche aber große Grafikkarte und viel RAM benötigt. Die FP8 Version ist ein guter Kompromiss zwischen Qualität und Performance. Für GGUF bitte die Q8_0 Version laden. Die GGUF Q4_0/4.1 Version wurde angefragt, ist klein, aber mit Qualitätsverlusten.
Grundsätzlich gibt es "All in One" Modelle, bei denen nur eine Datei nötig ist. Diese enthalten Clip_l, T5xxl fp8 und VAE (siehe unten). In den Checkpoints-Ordner legen.
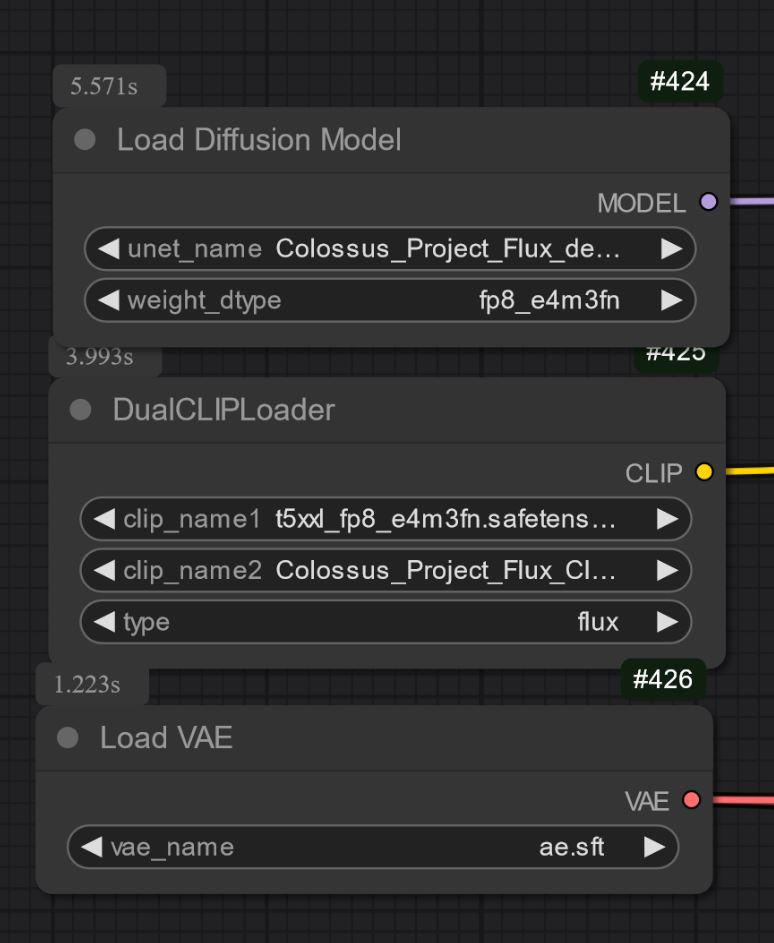
Die anderen Versionen sind UNET-only, bei denen alle Dateien separat geladen werden müssen.
Für alle Fälle: Clip_L herunterladen, damit es richtig funktioniert..
Auswahl des richtigen T5xxl Clips ist wichtig. Für FP8 fp8_e4m3fn T5xxl Clip, für FP16 der FP16 Clip. Standardgewichtstyp auswählen (unten Beispielbild für FP8 Version)
GGUF Version benötigt GGUF Loader!
Bekannte Punkte zu V1.0:
Erste Modellversion, kann mit manchen Prompts oder Kunststilen Probleme haben. Folge-Versionen erhalten mehr Training. Meldet Probleme.
Einstellungen und Workflow:
Getestet mit ca. 30 Schritten, Euler mit Simple Scheduler. Guidance 1,5-3 (außerhalb des Bereichs zum Testen). 1,8 eignet sich gut für realistische Bilder.
Probiert die Einstellungen aus und postet gute Ergebnisse.
Showcase-Bilder als Trainingsdaten hinzugefügt. Workflow für Comfy: https://civitai.com/articles/7946
"All-in-One" Modell:
UNET_only:
 Du musst auch Clip_L herunterladen. Es ist die 240MB Datei.
Du musst auch Clip_L herunterladen. Es ist die 240MB Datei.
GGUF: Workflow hier hinzugefügt: https://civitai.com/articles/7946
Wichtig:
Das Dev-Modell ist nicht für kommerzielle Nutzung gedacht. Dafür werde ich das "schnell"-Modell an einem anderen Ort veröffentlichen. Es ist eher für persönliche oder wissenschaftliche Nutzung.
LIZENZ:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
Credits:
theunlikely https://huggingface.co/theunlikel (nochmal Danke)
Version 2.1/V4.2/5.0: Flux_dev_de-distill von nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
Ab V2.0: Hyper Lora von ByteDance https://huggingface.co/ByteDance/Hyper-SD
Black Forrest für ihr großartiges Flux Modell https://huggingface.co/black-forest-labs

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8

Colossus Project Flux - v10_int4_SVDQ
















































