Illustrious XL 1.0 - v1.0
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder


Empfohlene Prompts
night, vivid colors
Empfohlene Negative Prompts
very displeasing, displeasing, bad anatomy, artistic error, lowres, bad hands, signature, artist name, multiple views, artist sign
Empfohlene Parameter
samplers
steps
cfg
resolution
Tipps
Verwenden Sie sowohl natürliche Sprache als auch Danbooru-Tag-basierte Prompts für nuancierte Bildgenerierung.
Kompatibel mit LoRA- und ControlNet-Modulen, die Feinabstimmungen von Stil, Pose und Komposition ermöglichen.
Illustrious XL v1.0 dient als rohes vortrainiertes Basismodell, ideal für weitere Feinabstimmung oder LoRA-Training.
Ersteller-Sponsoren
Besuchen Sie unsere Webseite, um zu sehen, woran wir gearbeitet haben, und erkunden Sie unser neuestes Modell!
→https://www.illustrious-xl.ai/
Wir freuen uns, Ihnen mitteilen zu können, dass Sie jetzt direkt auf unserer offiziellen Seite Bilder mit unseren Illustrious XL-Modellen generieren können: illustrious-xl.ai. Wir haben eine vollständige Bildgenerierungsplattform mit hochauflösenden Ausgaben, natürlicher Spracheingabe und benutzerdefinierten Voreinstellungen gestartet – sowie mehrere exklusive Modelle, die Sie nirgendwo anders finden. Entdecken Sie unsere aktualisierten Modellstufen und Benennungen hier: Model Series. Brauchen Sie Hilfe beim Einstieg? Sehen Sie sich unseren Nutzerleitfaden zur Bildgenerierung an: ILXL Image Generation User Guide.
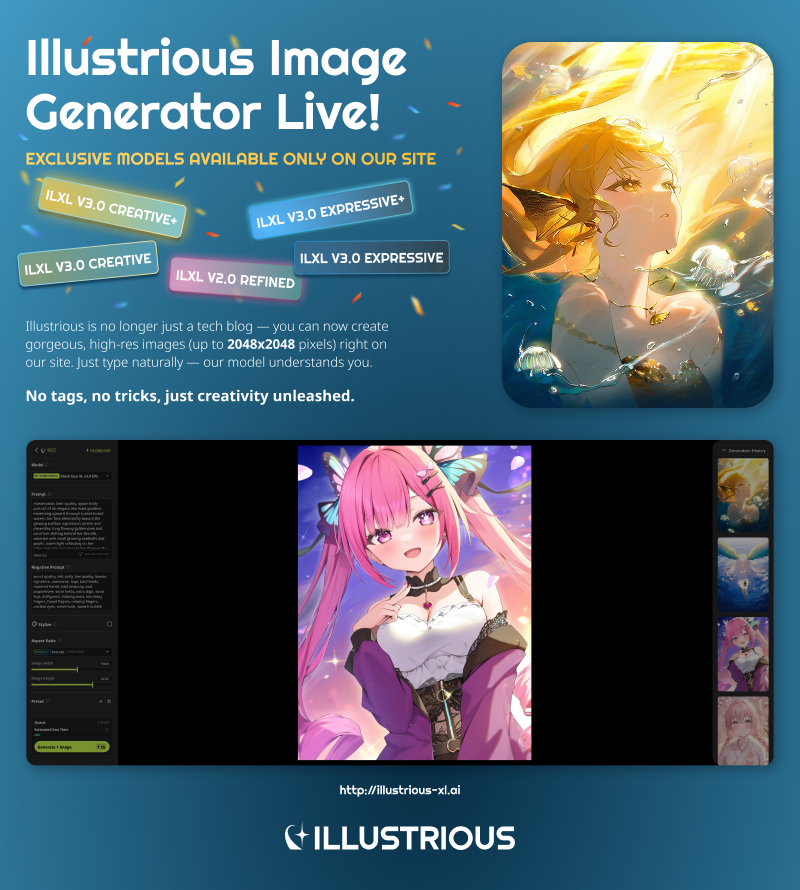 Besuchen Sie unsere Webseite, um zu sehen, woran wir gearbeitet haben, und erkunden Sie unser neuestes Modell!
Besuchen Sie unsere Webseite, um zu sehen, woran wir gearbeitet haben, und erkunden Sie unser neuestes Modell!
→https://www.illustrious-xl.ai/
Wir freuen uns, Ihnen mitteilen zu können, dass Sie jetzt direkt auf unserer offiziellen Seite Bilder mit unseren Illustrious XL-Modellen generieren können: [illustrious-xl.ai]. Wir haben eine vollständige Bildgenerierungsplattform mit hochauflösenden Ausgaben, natürlicher Spracheingabe und benutzerdefinierten Voreinstellungen gestartet – sowie mehrere exklusive Modelle, die Sie nirgendwo anders finden. Entdecken Sie unsere aktualisierten Modellstufen und Benennungen hier: [Model Series]. Brauchen Sie Hilfe beim Einstieg? Sehen Sie sich unseren Nutzerleitfaden zur Bildgenerierung an: [ILXL Image Generation User Guide].
Illustrious XL v1.0 – hochauflösendes, fokussiertes Illustrationsgenerationsmodell
Überblick
Illustrious XL v1.0 ist ein hochmodernes generatives Modell, entwickelt von OnomaAI, aufgebaut auf der Stable Diffusion XL-Architektur, trainiert basierend auf unserem vorherigen Checkpoint, Illustrious XL v0.1, und darauf ausgelegt, atemberaubende hochauflösende Bilder zu erzeugen. Es erreicht eine beispiellose native Auflösung von 1536×1536 im SDXL-Framework, wodurch zuvor unerreichte Detailtiefe und Klarheit ermöglicht werden. Das Modell kombiniert nahtlos das Verständnis natürlicher Sprache mit tag-basierter Eingabe (Danbooru-Stil), sodass sowohl beschreibende Sätze als auch spezifische Tags für flexible, robuste Eingaben genutzt werden können. Dadurch ist Illustrious XL v1.0 eine leistungsstarke Grundlage für Kreative, die Vielseitigkeit bei der Inhaltserstellung ohne Kompromisse bei der Qualität suchen.
Wissensstand
Illustrious XL v1.0 wurde im Juli 2024 trainiert, mit Wissensstand bis Juni 2024.
Dank seiner nativen Unterstützung von v0.1 LoRA müssen Sie sich jedoch möglicherweise keine Sorgen über Wissensgrenzen machen!
Hauptmerkmale
1536×1536 native Auflösung:
Erstes Stable Diffusion XL-Modell seiner Art, das native 1536px-Auflösung unterstützt. Erzeugt Bilder mit außergewöhnlichen Details, Schärfe und Klarheit in hohen Auflösungen, die zuvor im SDXL nicht möglich waren. Unterstützt eine breite Auflösungsspanne von 512x512 bis 1536x1536 – Auflösungen wie 1248x1824 sind ohne Modifikationen für hohe Auflösung möglich.
NLP- + tag-basierte Eingabe:
Integriert fortschrittliche Verarbeitung natürlicher Sprache mit Danbooru-Tag-basierten Prompts. Obwohl tag-basierte Ansätze prägnanter und genauer sind, ermöglicht dieses hybride Prompt-System, beschreibende englische Sätze oder präzise Tags (oder beides) zu verwenden – das Modell versteht und nutzt beide, was Ihnen mehr Kontrolle und Nuancen bei der Bildgenerierung gibt.
Umfangreiche Kompatibilität:
Vollständig kompatibel mit einer Vielzahl von Erweiterungen und Add-ons. LoRA, ControlNet-Module und andere Anpassungsmethoden, die für Illustrious v0.1 trainiert wurden, funktionieren nahtlos mit v1.0. Sie können Verbesserungen kombinieren, um Stil, Pose oder Komposition fein abzustimmen, ohne die Kompatibilität zu beeinträchtigen.
Vortrainiertes Basismodell:
Illustrious XL v1.0 wird als vortrainierter Basis-Checkpoint ohne Feinabstimmung auf spezielle Ästhetiken oder Biases bereitgestellt. Dieses „rohe“ Modell bietet eine robuste Grundlage für weiteres Training – ideal für Kreative, die eigene Feinabstimmungen (z. B. LoRA-Training) anwenden möchten, um bestimmte Kunststile oder spezialisierte Ergebnisse zu erzielen. Es ist ein flexibler Startpunkt für neue Innovationen.
Zukunftspläne
Höhere Auflösungen in v2/v3:
Für kommende Versionen (Illustrious XL v2 und v3) ist die Veröffentlichung geplant, die noch größere Auflösungen unterstützt und bis zu 2k und darüber hinaus zielt. Erwarten Sie noch mehr Details und Skalierbarkeit für ultra-klare Großformatbilder.
v-Parametrisierung & Farbkontrolle:
Eine spezialisierte v-Parametrisierungsversion ist bereits fertig, die frühere Grenzen von SD XL sowohl akademisch als auch praktisch durchbricht. Außerdem werden zukünftige Versionen verstärkt Farbkontrolle bieten, um Nutzern eine feinere Anpassung von Farbbalance und Konsistenz bei generierten Bildern zu ermöglichen.
Stetige Verbesserungen:
Die Illustrious-Roadmap ist ehrgeizig – jede Iteration wird Community-Feedback und den neuesten Stand der Forschung integrieren. Wir werden die Forschung zu hohen Auflösungen mit sorgfältigen und durchdachten Ansätzen fortsetzen, dabei bisher als Grenzen betrachtete Maßnahmen durchbrechen.
Illustrious v0.1 (huggingface) | OnomaAI TooToon | Nutzungsbedingungen

Modell-Details
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - Illustrious XL 1.0
Bilder von Illustrious XL 1.0 - v1.0
Bilder mit Basismodell

Bilder mit illustrious


