MasterCG_CN_V1.0 - v1.0
Verwandte Schlüsselwörter & Tags
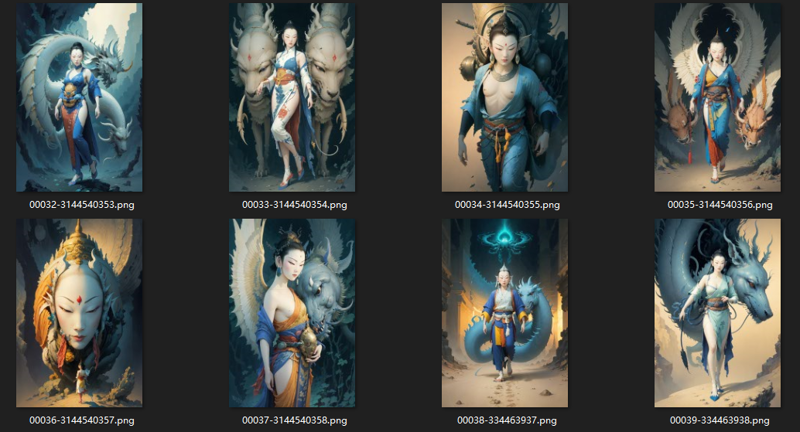
Hervorgehobene Bilder


Empfohlene Prompts
(((stunning atmosphere))), (((Real extraterrestrial gods from Chinese Buddhism:1.3)))). ((( extreme long shot:1.4))), cyborg godness, gothic, dark, intricate, elegant, symbolism, imagination, daydreams and nightmares, surreal landscape, jellyfish phoenix, Illustration from Fairy tale world, Chinese goblins, Chinese Taoism, ancient Chinese myths and legends, Tibetan Buddhist mythological beasts, Bodhisattvas, artstation. deviantart.rendered by binx.ly, by ilya kuvshinov, <lora:LoconLoraNardack_v10:0.4> <lora:LORA_CNCG_arts:0.9> <lora:LORA_mj_shinv:0.5> <lora:studioGhibliStyle_offset:0.5>, greg rutkowski and makoto shinkai, trending on artstation
Empfohlene Negative Prompts
paintings, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), skin spots, acnes, skin blemishes, sketches, age spot, (outdoor:1.6), manboobs, backlight, (ugly:1.331), (duplicate:1.331), (morbid:1.21), ((grayscale)), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.331), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (more than 2 nipples:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), bad hands, missing fingers, extra digit, (futa:1.1), bad body, NG_DeepNegative_V1_75T, pubic hair, glans (bad-artist:0.7)
Empfohlene Parameter
samplers
steps
cfg
resolution
other models
Empfohlene Hires (Hochauflösungs-) Parameter
upscaler
upscale
steps
denoising strength
Tipps
Passen Sie die Aufnahmen auf Nah- oder Halbtotale an, um die Detaildarstellung von Charakteren zu verbessern.
Verwenden Sie ControlNet tile + Ultimate SD Upscale im Bild-zu-Bild-Modus, um Details beim Hochskalieren neu zu zeichnen und zu verbessern.
Probieren Sie verschiedene Clip skip-Werte (1 oder 2) aus, um bevorzugte Stileffekte zu erzielen.
Lora-Gewichte zwischen 0,6 und 0,9 werden üblicherweise für beste Ergebnisse verwendet.
Versions-Highlights
v1.0
Dies ist ein Versuch mit chinesisch-stilisierten Themen. Derzeit beschäftigen sich viele Freunde mit Lora, die für traditionelle chinesische Malerei und andere traditionelle chinesische Stile verwendet wird. Allerdings scheint es noch kein CG-Stil mit starker Erzählkraft zu geben. Für die Bedürfnisse meines eigenen Projekts habe ich diese chinesisch-stilisierte CG-Meister-Dan entwickelt. Das Trainingsmaterial besteht hauptsächlich aus erstklassigen CG-Meisterwerken aus China. Aufgrund der derzeitigen Feindseligkeit der CG-Community gegenüber der AIGC-Community werde ich die Künstler nicht einzeln auflisten. Die Werke konzentrieren sich meist auf Themen wie östliche Fantasie und Mythologie, überwiegend Szenen, Charaktere sind auch vorhanden, aber nicht viele.
Dieses Modell eignet sich für die Verwendung mit ausdrucksstarken, ausgereiften Modellen wie revAnimated und chilloutmix, um eine gute erzählerische Wirkung mit dem Fokus auf Charaktere zu erzielen. Für Szenen eignet es sich gut in Kombination mit umfassenderen Basismodellen wie Anything_v5 und final-pruned.
Ich nenne es gerne den Dämonen-Pill.
Weil ich persönlich die Kreation chinesischer mythologischer Themen mag, habe ich oft unaufhörliche Gedanken zu Buddha, Dämonen und Bestien. Derzeit gibt es auf Midjourney eine starke Homogenisierung und es fehlt an individualisierten ästhetischen Ausdrucksmöglichkeiten. Zum Beispiel ist das wohl imaginationskräftigste und ausdrucksvollste chinesische mythologische Thema kaum unterstützt, weshalb es notwendig war, Modelle privat zu entwickeln. Dieses Modell weist noch erhebliche Mängel auf, zum Beispiel ist die Wahrscheinlichkeit hoch, dass Details wie Gesichter, Hände und Füße zusammenbrechen. Ein Grund ist, dass das Training des Modells auf die Verstärkung östlicher erzählerischer Szenen ausgerichtet ist, daher sind Charaktere sekundär. Zudem sind Charaktere in Szenen oft keine Hauptnarrationselemente, was zu einem geringen Anteil und unzureichenden Pixeln für deren Darstellung führt. Wie allgemein bekannt führt dies unweigerlich zu einem Mangel an Detailausarbeitung bei Charakteren.
Die Anpassung der Kameraperspektive auf Nahaufnahmen oder Halbtotalen kann dieses Problem erheblich verbessern. Bei narrativen Szenen lässt sich der Schwachpunkt auch im Bild-zu-Bild-Modus mit ControlNet tile + Ultimate SD Upscale durch Vergrößerung und Neuzeichnung der Details im Wesentlichen beheben.
Seine Vorteile sind ebenfalls deutlich: Es hat endlich eine starke Erzählfähigkeit bei der Darstellung chinesisch-stilisierter Themen entwickelt und berücksichtigt dabei die einzigartige Vorstellungskraft östlicher Ästhetik, wodurch ein Gleichgewicht zwischen Narration und emotionaler Erzählung gefunden wird. Zurzeit löst es viele meiner Arbeitsprobleme, zumindest ist es ein guter Ansatz für eine mittlere Optimierungsphase.
Dies ist nur eine persönliche Erfahrungsbeschreibung. Wir freuen uns auf Rückmeldungen zu weiteren Problemen und den Austausch weiterer Lösungsansätze.
Ich nenne es gerne Dämonen-Pill.
Weil ich persönlich gerne zu chinesischen mythologischen Themen arbeite, habe ich häufig fortwährende Gedanken zu Buddhas, Dämonen und Bestien. Zurzeit ist die Homogenisierung auf Midjourney stark ausgeprägt und es fehlt an persönlicher ästhetischer Ausdruckskraft. Beispielsweise ist die Unterstützung für die fantasievollsten und ausdrucksstärksten chinesischen mythologischen Themen äußerst schwach, weshalb das private Verfeinern von Modellen unausweichlich ist. Dieses Modell weist noch große Mängel auf, zum Beispiel können Details wie Gesichter, Hände und Füße oft fehlerhaft sein. Ein Grund dafür ist, dass das Training dieses Modells auf die Verstärkung östlicher erzählerischer Szenen fokussiert ist, daher sind Figuren sekundär. Außerdem sind Figuren in Szenen oft nicht die Hauptnarrationselemente, was dazu führt, dass sie nur einen kleinen Anteil ausmachen und nicht genügend Pixel für eine detaillierte Darstellung zur Verfügung stehen. Wie bekannt, führt dies unvermeidlich zu einem Mangel an Ausarbeitung der Charakterdetails.
Die Anpassung der Kameraposition auf Nah- oder Halbtotale kann dieses Problem erheblich verbessern. Für narrative Zwecke kann dieses Problem auch durch Bild-zu-Bild-Modus mit ControlNet tile + Ultimate SD Upscale, wobei Details vergrößert und nachgezeichnet werden, grundsätzlich gelöst werden.
Seine Vorteile sind auch herausragend: Es hat schließlich eine starke Erzählfähigkeit bei chinesischen Stilthemen entwickelt und berücksichtigt dabei die einzigartige Vorstellungskraft östlicher Ästhetik, wodurch ein Gleichgewicht zwischen Narration und emotionaler Darstellung gefunden wurde. Derzeit kann es viele meiner beruflichen Herausforderungen lösen und stellt zumindest einen guten Ansatz für eine mittlere Optimierungsphase dar.
Dies ist nur eine persönliche Erfahrungszusammenfassung. Wir laden alle ein, mehr Fragen zu stellen und gemeinsam weitere Lösungsmöglichkeiten zu diskutieren.






Bitte beachten Sie:
Dieses Modell ist nur für den Austausch und das Lernen bestimmt, bitte nicht für kommerzielle Zwecke verwenden.
Der von mir häufig verwendete CFG-Bereich liegt zwischen 5 und 7,5, und Lora-Gewichte liegen normalerweise zwischen 0,6 und 0,9.
Wenn Clip skip auf 1 oder 2 eingestellt ist, variiert der erzielte Effekt. Probieren Sie verschiedene Einstellungen aus, um den bevorzugten Stil zu finden.
Das Trainingsset dieses Lora-Modells basiert hauptsächlich auf Werken führender inländischer CG-Künstler, die Erzeugung von europäischen und amerikanischen Porträts sowie Gebäuden kann beeinträchtigt sein.
Bitte beachten Sie:
Dieses Modell ist nur für Kommunikations- und Lernzwecke bestimmt, bitte nicht für kommerzielle Zwecke verwenden.
Mein häufig verwendeter CFG-Bereich liegt bei 5-7,5, mit Lora-Gewichten zwischen 0,6 und 0,9.
Wenn Clip skip auf 1 oder 2 eingestellt ist, variieren die erzeugten Effekte. Probieren Sie verschiedene Einstellungen aus, um den bevorzugten Stil zu finden.
Das Trainingsset dieses Lora-Modells basiert hauptsächlich auf den Werken inländischer CG-Meister, die Erzeugung von europäischen und amerikanischen Porträts und Gebäuden kann beeinträchtigt sein.

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Trainierte Wörter
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.
Modellsammlung - MasterCG_CN_V1.0
Bilder von MasterCG_CN_V1.0 - v1.0
Bilder mit CG-Kunst










Bilder mit Charaktere





Bilder mit Stil









