NEW ERA (New Esthetic Retro Anime) - Retro_v7.0R(VAE)
Verwandte Schlüsselwörter & Tags
Hervorgehobene Bilder


Empfohlene Prompts
masterpiece,best quality,newest,official art,absurdres,highres,retro artstyle,1990s (style),1980s (style),2000s (style),anime screenshot,anime coloring,photo background
1girl
Empfohlene Negative Prompts
worst quality,low quality,(censored, bar censor, mosaic censoring, 4koma),multiple views,blurry,artistic error,bad anatomy,bad feet,wrong foot,bad hands,bad proportions,bad perspective,bad leg,bad arm,bad neck,bad vulva,bad reflection,bad ass,bad face,english text,chinese text,watermark,simple background
(worst quality, low quality, extra digits:1.4)
Empfohlene Parameter
samplers
steps
cfg
resolution
Empfohlene Hires (Hochauflösungs-) Parameter
upscaler
upscale
denoising strength
Tipps
Verwendet Latent (nearest-exact) Skalierung/Upscale, um Artefakte zu reduzieren und die Anatomie besonders bei hohen Auflösungen zu erhalten.
Setzt Rate of caption dropout und Network dropout 0,05 ein, um die anatomische Konsistenz bei extremen Auflösungen zu steigern.
Verwendet detaillierte booru-Tags von der danbooru-Seite in den Prompts, um Details zu verbessern und Vereinfachung zu reduzieren.
Das Negative Prompt ‚simple background‘ hilft, die Bildvereinfachung bei v-pred Modellen zu verringern und Details zu verbessern.
RescaleCFG muss bei aktuellen Modellversionen nicht genutzt werden – kompatibel mit ComfyUI, Forge, Reforge und Automatic1111.
Installiert die sd-webui-tagcomplete Erweiterung für Tag-Autovervollständigung von Danbooru, um bessere Prompts zu schreiben.
Für beste Ergebnisse Prompts mit ‚masterpiece, best quality‘ beginnen.
Versions-Highlights
Eine experimentelle Version mit starkem Fokus auf Retro-Stil
Verminderte Bedeutung der Prompts 1990s (style), 1980s (style), retro artstyle (Diese Prompts nur verwenden, wenn nicht genug Retro vorhanden ist)
Charaktere aus alten Animes wurden präziser
Ersteller-Sponsoren
Kombiniertes Modell der 90er, 80er und jetzt 00er
Ich habe meinen PATREON wiederhergestellt (oder besser gesagt einen neuen mit Erlaubnis von Patreon erstellt), falls jemand Unterstützung möchte. Ich habe dort alle meine neuen Modelle und LORAs, die auf BOOSTY bezahlt wurden, in einem Archiv gepostet. Ich freue mich, wenn ihr sogar kostenlos auf Patreon folgt, so weiß ich, dass euch meine Arbeit wichtig ist und ihr Updates sehen möchtet.
Über v5.0:
Es wurde beschlossen, das Modell basierend auf NAI-XL zu implementieren, ein gewaltiger Qualitätsprung im Vergleich zu den letzten LORA. Da das Modell einfach zu verfeinern ist, wurden Details in der Umgebung, Augen, verbesserte Anatomie, Finger, Vielfalt in der Kleidung und vor allem eine reduzierte Kontrastintensität verbessert. Das heißt, wenn in Version 3.0 der Kontrast sehr hoch war und es schwierig war, zusätzliche LORA zu verwenden (mit cfg scale 2,5), liegt die cfg scale jetzt bei gleichem Kontrast bei etwa 4, was einen Puffer für zusätzliche LORA bietet.
Beim Einsatz von Latent (nearest-exact) Skalierung sind deutlich weniger Artefakte vorhanden (manchmal gar keine), was auf eine erhebliche Qualitätssteigerung und verbesserte Anatomie hinweist (bei Skalierung bleibt die Anatomie viel häufiger innerhalb korrekter Grenzen erhalten).
Workflow (einstellungen einfach kopieren, alles außer negativen Prompts, die beste Option steht unten):
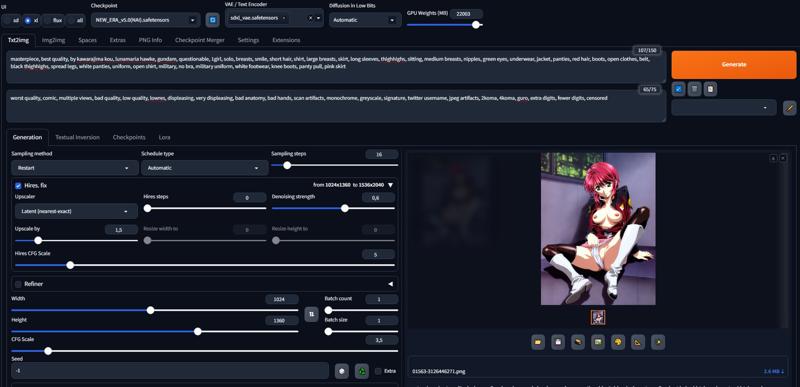 Link zum Bild
Link zum Bild
Über v6.3 & 6.69:
Es hat diesmal etwas länger gedauert, weil ich das Feintuning überarbeitet und die LoRA neu trainiert habe, um das Modell zu verbessern (und außerdem ist nach der Neuinstallation von Python meine gesamte WebUI kaputt gegangen und ich musste alles reparieren)
Ich möchte gleich sagen, dass dieses Modell nicht auf Epsilon, sondern auf v-pred. basiert. V-pred (Geschwindigkeitsvorhersage) und Epsilon (ε-Vorhersage) sind unterschiedliche mathematische Ansätze zur Parameterisierung von Rauschen in Diffusionsmodellen. Ohne zu sehr ins Detail zu gehen: Für Anime ist vpred mit den richtigen Einstellungen besser. Es gibt jedoch große Probleme mit Bildflimmern und eine etwas schlechtere Konvergenz bei Null-SNR (vpred sollte bei 0 SNR verwendet werden). Ich habe die Probleme mit starkem Kontrast und Farbverlust mit den richtigen Einstellungen für die v-Parameterisierung gelöst, indem ich SNR komplett deaktiviert und das Rauschen automatisch angepasst habe, anstatt die in SDXL verwendeten festen Werte zu verwenden. Das war nicht einfach, denn es gibt keine verlässlichen Daten im Internet. Durch Versuch und Irrtum und das genaue Lesen wissenschaftlicher Arbeiten zu v-pred konnte ich einige Feinheiten begreifen. Tatsächlich ist das originale NOOBAI mit Civitai falsch trainiert, was ziemlich lustig ist, wenn man die vielen Helfer bei Setup und Training bedenkt.
V-pred ist tatsächlich sehr anspruchsvoll und nicht perfekt; hoffentlich werden zukünftige hybride Ansätze die aktuellen Einschränkungen beseitigen, erfordern jedoch grundlegende Änderungen in der Architektur von Diffusionsmodellen.
Zurück zu den Modellen: Warum zwei Versionen? Ich habe eine leichte Verschlechterung bei der Detailgenauigkeit von Gesichtern und Augen beobachtet (nicht viel, aber dennoch wichtig). Daher habe ich Version 6.69 erstellt, die zuerst spezialisierte LoRAs trainiert, um Gesichter zu verbessern und die Anatomie weiter anzupassen, die jetzt auf einem neuen Niveau ist. Version 6.3 arbeitet visuell etwa 5 % besser mit Schatten in 70-75 % der Fälle, was für viele nicht so wichtig ist, für mich aber schon. Daher biete ich euch die Wahl. Version 6.69 ist besser in der Anatomie, 6.3 ist leicht besser bei Schatten. (Zuerst poste ich 6.3)
Vergleiche der Versionen 6.3 und 6.69 sowie Version 5.0 (Alle Werke wurden ohne Upscaling in der Auflösung 1024x1056 erstellt):




 Vergleich der Sampler:
Vergleich der Sampler:

Jetzt sprechen wir darüber, wie gut dieses Modell bei extremer Auflösung anatomisch konsistent bleibt, verglichen mit älteren Modellen. Dies habe ich erreicht durch Hinzufügen von Rate of caption dropout und Network dropout 0.05, was die Konsistenz mehrfach erhöht hat.Auflösung 1400x2000 (trotz dieser Ergebnisse ist diese Auflösung extrem und nicht empfohlen, besser Latent (nearest-exact) Upscale verwenden)



Mein Workflow
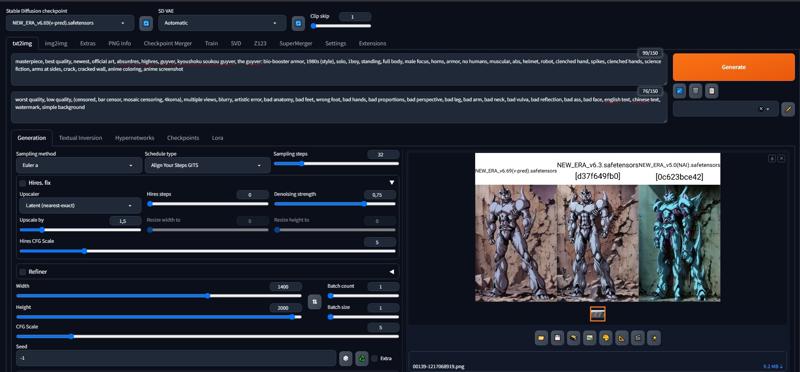 Prompts vornan: masterpiece, beste Qualität, neueste, offizielles Artwork, absurdres, highres
Prompts vornan: masterpiece, beste Qualität, neueste, offizielles Artwork, absurdres, highres
Negative Prompts: schlechteste Qualität, niedrige Qualität, (zensiert, Balkenzensur, Mosaikzensur, 4koma), Mehrfachansichten, verschwommen, künstlerischer Fehler, schlechte Anatomie, schlechte Füße, falscher Fuß, schlechte Hände, schlechte Proportionen, schlechte Perspektive, schlechtes Bein, schlechter Arm, schlechter Hals, schlechte Vulva, schlechte Reflexion, schlechter Po, schlechtes Gesicht, englischer Text, chinesischer Text, Wasserzeichen, einfacher Hintergrund
Die negativen Prompts sind Standard, enthalten alle schlechten anatomischen Dinge von der danbooru-Website, außer einem - einfacher Hintergrund. Mir ist aufgefallen, dass vpred-Modelle gerne vereinfachen; dieses Negative hilft und verbessert die Gesamtdetaillierung.
RescaleCFG wird nicht mehr benötigt. Nun kann man problemlos mit ComfyUI, Forge, Reforge und sogar dem Standard Automatic1111 arbeiten.
Denkt daran, vpred-Modelle mögen sehr detaillierte Beschreibungen. Nutzt booru-Tags von der danbooru-Website. Reguläre 1girl-Prompts funktionieren, aber das Bild wird so stark vereinfacht und standardisiert wie möglich dargestellt, was bei diesen Modellen unvermeidlich ist. Epsilon-Modelle sind in dieser Hinsicht vielfältiger, verlieren jedoch in allen anderen Bereichen (absolut in allen).
Falls noch nicht geschehen, installiert die Erweiterung "sd-webui-tagcomplete". Sie zeigt Autovervollständigungshinweise für erkannte Tags von "image booru" Boards wie Danbooru an, die vor allem für das Durchsuchen von Anime-Illustrationen genutzt werden.
CFG Scale - beliebig, keine Probleme mehr mit übermäßigem Kontrast. Ihr könnt 5-7 einstellen (Standardwerte).
Ach ja, fast vergessen, ich habe viele Full HD Bilder von Studio Ghibli Anime aus den 80ern, 90ern und 00ern hinzugefügt, so dass ihr nun Kunst im Stil dieses Studios erstellen könnt. Auch Breitbildbilder gelingen mit deutlich besserer Anatomie.
Hinzugefügte Animes:
Hotaru no Haka
Tonari no Totoro
Sen to Chihiro no Kamikakushi
Howl no Ugoku Shiro
Tenkuu no Shiro Laputa
NEW_ERA_v7.1 (NAI V-PRED) oder PATREON (neues Level Retro-Kunst, viel besser als Versionen 6.3 und 6.69, stabiler, schöner, leichter anzuwenden)
















NEW ERA 4.0 (ILLUSTRIOUS-XL) / SDXL / LORA




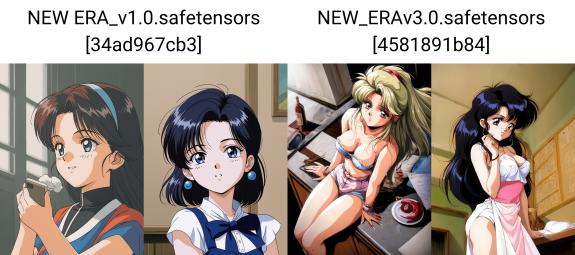
 NEW ERA v1.0 (SDXL / PONY DIFFUSION Version, die fast alle meine populären Modelle mit Schwerpunkt auf Retro Anime vereint)
NEW ERA v1.0 (SDXL / PONY DIFFUSION Version, die fast alle meine populären Modelle mit Schwerpunkt auf Retro Anime vereint)
P.P.S. neues Modell Anime Screencap / LORA / PONY DIFFUSION auf Boosty


Ich habe ein Video erstellt, wie man die gleiche Qualität erreicht oder einfach meine Kunst nachmacht
perfekte negative Prompts (ich habe einfach alle schlechten Prompts von danbooru benutzt):
Negative Prompt: schlechteste Qualität, niedrige Qualität, (zensiert, Balkenzensur, Mosaikzensur, 4koma), Mehrfachansichten, verschwommen, künstlerischer Fehler, schlechte Anatomie, schlechte Füße, falscher Fuß, schlechte Hände, schlechte Proportionen, schlechte Perspektive, schlechtes Bein, schlechter Arm, schlechter Hals, schlechte Vulva, schlechte Reflexion, schlechter Po, schlechtes Gesicht, englischer Text, chinesischer Text, Wasserzeichen, einfacher Hintergrund
Retro Artstyle - das wichtigste Retro-Token, das in fast allen trainierten Bildern enthalten ist und unterschiedliche Ergebnisse in den 80ern-90ern bewirkt
1990s (style) - ein sehr starker Marker, der den Stil des Modells merklich verändert
1980s (style) - hatte endlich einen starken Einfluss auf das Endergebnis
2000s (style) - deutlich besser als zuvor
Anime screenshot, anime coloring - zwei starke Tokens, funktionieren großartig, lassen das Bild wie Screenshots aus Anime aussehen, können zusammen oder separat verwendet werden
Photo background - macht die Umgebung realistisch, während die Charaktere im Anime-Stil bleiben (für dieses Modell angepasst)
Vergesst nicht, am Anfang der Prompts zu schreiben: masterpiece, best quality
Künstler:
von Urushihara Satoshi
von Danmakuman
von Kitazume Hiroyuki
von Kawarajima Kou
von Kotobuki Tsukasa
von Hirano Toshihiro
neu
von Mikimoto Haruhiko
von Kajishima Masaki
von Saotome Nanda
von Hakumai Gen
P.S. 7.9V (basierend auf 1.5)
Benutzung bei Civitai Generation Service – die Checkbox ist aktiviert, aus irgendeinem Grund funktioniert es nicht
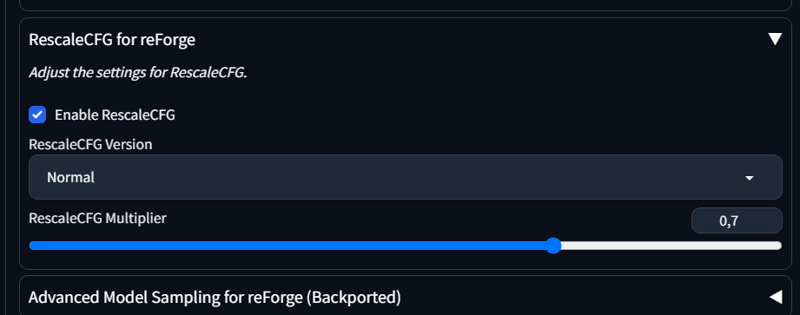
Ihr könnt RescaleCFG bei Reforge nutzen, um den Kontrast zu reduzieren
Bitte postet eure Werke mit oder ohne Kommentare, das hilft mir, mich zu verbessern. Danke!
Wenn euch meine Arbeit gefällt, klickt oben auf das Herz, ich freue mich sehr :3

Modell-Details
Modelltyp
Basismodell
Modellversion
Modell-Hash
Ersteller
Diskussion
Bitte log in um einen Kommentar zu hinterlassen.















































