Colossus Project Flux - v10_int4_SVDQ
Palabras Clave y Etiquetas Relacionadas
Imágenes destacadas

Prompts Negativos Recomendados
blurry
Parámetros Recomendados
samplers
steps
cfg
resolution
vae
Consejos
Usa prompts negativos con la palabra 'blurry' para mejorar la calidad de salida.
Para versiones FP4, usa solo tarjetas gráficas Nvidia serie 50xx; las versiones int4 soportan 40xx e inferiores (mínimo serie 20xx).
Los modelos 'Todo en uno' contienen incorporados Clip_l, T5xxl y VAE para simplificar su uso.
Prueba varios samplers como Euler, Heun, DPM++2M, deis, DDIM; se recomienda el scheduler 'Simple'.
Experimenta con la escala de guía (cfg) entre 1.5 y 3, por defecto alrededor de 2.2 a 2.3 para mejores resultados.
La versión FP8 ofrece un buen equilibrio entre calidad y rendimiento.
Para versiones especiales ‘de-distilled’, desactiva la escala Flux Guidance y usa cfg en su lugar.
Si aparecen artefactos, intenta un pequeño escalado (por ejemplo, 1.14x en lugar de 1.2x) para mitigarlos.
Se proveen flujos de trabajo y guías detalladas vía enlaces a artículos de Civitai.
Aspectos Destacados de la Versión
Versión V10_int4_SVDQ "Nunchaku"
Instalación: Por favor visita mi guía de instalación/flujo: https://civitai.com/articles/15610
Primero quiero agradecer a theunlikely https://huggingface.co/theunlikely que convirtió FP16_Unet en int4_SVDQ. Visita su página y déjale un like.
Esta versión es más o menos igual que la versión FP8. Incluso en modo normal dentro de mi flujo esta cosa es aproximadamente 2X-3X más rápida que el modelo regular.. Con el "modo rápido" del flujo puedo generar una imagen 2MP en unos 19 segundos con mi 3090ti.
¿Qué es SVDQ "Nunchaku"?
Este nuevo método de cuantificación permite reducir los modelos Flux (en este caso un modelo nativo FP16) de 24GB a cerca de 6.7GB. Pero no es todo: puedes generar más rápido que nunca sin perder tanta calidad. Seguro notarás una pequeña diferencia con mi 32GB_Behemoth pero para ese necesitarás mucho más VRAM/RAM para siquiera ejecutarlo.
Para más información visita: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Patrocinadores del Creador
Apoya al creador en Ko-Fi: https://ko-fi.com/afroman4peace
Descarga modelos cuantificados por Muyang Li de Nunchakutech: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
Guías de flujo de trabajo en Civitai:
https://civitai.com/articles/17313
https://civitai.com/articles/17358
https://civitai.com/articles/17163
https://civitai.com/articles/15610
https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
https://civitai.com/articles/8419
https://civitai.com/articles/7946
GitHub para la cuantificación Nunchaku SVDQ: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Profundamente bajo una montaña vive un gigante dormido, capaz de ayudar a la humanidad o causar destrucción...
Un Coloso surge...
Después de mi serie SDXL es tiempo de la serie FLUX de este Proyecto... Esta vez entrené esto desde cero. Para el entrenamiento utilicé mis propias imágenes. Las creé con mi modelo schnell Flux DemonFlux/Colossus Project schnell + mi SDXL Colossus Project 12 como refinador.
Este punto de control SD Flux es capaz de producir casi todo... Colossus es muy bueno creando imágenes extremadamente realistas, anime y arte.
Si te gusta, siéntete libre de darme tu opinión. También, si quieres apoyarme puedes hacerlo aquí. He gastado bastante dinero para construir un ordenador capaz de entrenar modelos Flux.. Además, entrenar y probar consume mucho tiempo y electricidad..
https://ko-fi.com/afroman4peace
Versión V12 "Hephaistos"
Publicar este punto de control me hace feliz y triste al mismo tiempo... V12 será el último checkpoint de esta serie... La razón principal son las próximas leyes de IA de la UE... Otra razón es la licencia de Flux .1 DEV en sí. ¡Gracias a todos por el apoyo! He dedicado mucho tiempo a este Proyecto durante el último año. Ahora es tiempo de avanzar a otro Proyecto.
De todos modos... terminaré esta serie con una nota alta...
V12 está construido sobre V10B "BOB" pero básicamente fusiona las mejores partes de esta serie en este único checkpoint. (Fue el resultado de un nuevo método de fusión que tomó aproximadamente 1:30h y usó toda mi RAM de 128GB). También mejoré las texturas de cara y piel en comparación con V10. Los ojos son mucho más realistas y "vivos" que antes.
Pruébalo tú mismo y dame tu opinión sobre V12. "Gracias" a mi lenta conexión de internet primero subiré el FP8_UNET. Después la versión FP8 "todo en uno" y luego el FP16_unet y FP16_BEHEMOTH. También intentaré convertirlo a int4 y fp4 (deséame suerte en eso)
Como siempre, dame tu opinión sobre V12..
Versión V12 "Behemoth" (AIO)
Este modelo "todo en uno" es lo mejor de mi serie V12... y el más grande en tamaño por supuesto :-)
Behemoth tiene un T5xxl personalizado y Clip_l incorporados dentro del modelo. Si prefieres calidad en lugar de cantidad ¡este es el checkpoint para ti!
Versión V12 FP4/int4
Gracias a Muyang Li de Nunchakutech que hizo la cuantificación de V12. https://huggingface.co/nunchaku-tech y su increíble nunchaku!
Esta versión es verdaderamente asombrosa. Combina calidad con velocidad nunca vista antes.
¡ATENCIÓN!
Hay dos versiones FP4 e int4. FP4 es solo para tarjetas gráficas Nvidia serie 50xx! Mientras que int4 funciona con 40xx y inferiores. (necesitas al menos una tarjeta gráfica serie 20xx)
También puedes descargar ambas versiones directamente aquí: https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
GUÍA DE INSTALACIÓN y FLUJO DE TRABAJO
Aquí tienes una guía rápida de instalación y un flujo de trabajo en progreso.
https://civitai.com/articles/17313
GUÍA DETALLADA para el flujo de trabajo
https://civitai.com/articles/17358
Sigo trabajando en mis nuevos flujos para Nunchaku... así que el siguiente flujo sigue siendo muy en progreso (WIP). Añadiré un artículo detallado el fin de semana.
Versión V12 FP16_B_variant
Por un pequeño error que cometí tarde en la noche (2 AM) renombré y subí el punto de control "incorrecto". Es un checkpoint muy experimental nunca pensado para ser publicado. No está muy probado pero funcionó realmente bien cuando creé la muestra. Podría ser mejor que la versión estándar.
Prefiere rostros más asiáticos... Eso es porque quería probar algo para mezclar en un proyecto paralelo en el que aún trabajo. Cuéntame tu experiencia con este checkpoint :-)
Versión V12 AIO FP8
Esta versión es una versión todo en uno de V12. Esto significa que todos los clips están incorporados. Ofrece la misma salida que el FP8_unet con mi clip_l personalizado.
Versión V12 GGUF Q5_1
Esta versión fue solicitada. No es mala en calidad...
Versión V10B "BOB"
Esta es una versión alternativa de V10. La creé para mejorar la versión FP8 de V10. En general la versión FP8 es más precisa y los colores son mejores. Tristemente no tengo mucho tiempo últimamente.. (la vida real primero). Por eso tardó tanto... Déjame saber si prefieres esta versión. También tengo una versión FP16 de "BOB". Dependiendo de la opinión también consideraré publicar una versión int4.
FLUJO DE TRABAJO:
Aquí está el flujo de trabajo para V12 y V10: https://civitai.com/articles/17163
Versión V10_int4_SVDQ "Nunchaku"
Primero quiero agradecer a theunlikely https://huggingface.co/theunlikely que convirtió el FP16_Unet en int4_SVDQ. Visita su página y déjale un like.
Esta versión es más o menos igual que la versión FP8. Incluso en modo normal dentro de mi flujo esta cosa es aproximadamente 2X-3X más rápida que el modelo regular.. Con el "modo rápido" del flujo puedo generar una imagen 2MP en unos 19 segundos con mi 3090ti.
¿Qué es SVDQ "Nunchaku"?
Este nuevo método de cuantificación permite reducir los modelos Flux (en este caso un modelo nativo FP16) de 24GB a cerca de 6.7GB. Pero no es todo: puedes generar más rápido que nunca sin perder tanta calidad. Seguro notarás una pequeña diferencia con mi 32GB_Behemoth pero para ese necesitarás mucho más VRAM/RAM para siquiera ejecutarlo.
Para más información visita: https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Instalación: Por favor visita mi guía de instalación/flujo: https://civitai.com/articles/15610
Versión V10 "Behemoth" (FP16_AIO)
Esta versión sigue siendo experimental. El foco principal fue obtener resultados más realistas. También logré reducir algunas "líneas Flux". Esta versión se basa en Colossus Project V5.0_Behemoth, V9.0 y otro Proyecto llamado "Ouroborus Project"
La versión FP16 es muy estable. También pronto liberaré una versión FP8. Esta es muy buena también pero no tan estable..
Te dejo experimentar con ella... Cuéntame qué piensas de esta versión.
Diviértete creando :-)
Versión V9.0:
Bueno, voy a tener que explicar mucho... Primero, ¿por qué es V9.0?
Recientemente me mudé a un piso nuevo y debido a errores del proveedor de internet no tenía conexión real... Así que mientras hacía toda la mudanza... dejé mi ordenador encendido. El resultado fue que creé muchos checkpoints (la mayoría defectuosos). Sin embargo, tengo algunas muy buenas versiones V8 que podría publicar también...
¿Qué cambió?
Entrené nuevos rostros y texturas de piel usando básicamente los mejores resultados de V5.0. También el modelo recibió entrenamiento para pies/piernas para mejor anatomía. Las versiones V5.0 a veces recortaban cabeza y pies... Creo que logré arreglar algunos de esos problemas..
Además lo entrené con más de mis propias imágenes de paisajes... Y sí, hice todo esto mientras me mudaba a un nuevo piso... Calculé que fue un tiempo total de entrenamiento de unas 2 semanas computando, lo cual no es barato... (cada hora me cuesta alrededor de 25 centavos en electricidad)
En fin, espero que te guste esta versión... Si quieres apoyarme: publica imágenes bonitas o quizás invítame con Buzz o en Ko-fi..
Dime qué te parece :-)
Versión 5.0:
V5.0 se basa en V4.2 y V4.4 (que también será lanzada pronto). Recibió entrenamiento adicional en detalles de piel y anatomía en general, arreglando en su mayoría cosas como manos y pezones. Los detalles del rostro son mucho mejores. También intenté arreglar algunas líneas de Flux menores..
En general esta versión es más realista que V4.2 y mejor en detalles pequeños.. Al igual que la versión 4.2, esta es también un modelo híbrido de-distilled. Puedes usarlo básicamente con las mismas configuraciones que V4.2.
Aquí también tienes un nuevo flujo de trabajo para probar: https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Dime qué te parece esta versión comparada con 4.2 o V2.1..
Versión 4.4 "Research":
He añadido esta versión solo para completitud... Es ligeramente más realista que V4.2 y la base para la Versión 5.0. Puedes probarla si quieres. También puedes usar el flujo para V5.0 y V4.2..
Versión 4.2:
Esta versión es básicamente una evolución de Demoncore Flux y Colossus Project Flux. El objetivo era obtener un resultado más estable con mejores texturas de piel, mejores manos y más variedad de rostros. Así que la entrené con un modelo híbrido que es parcialmente Demoncore Flux. También mejoré pezones y contenido NSFW un poco. Dime si prefieres V4.2 sobre la versión 2.1 :-)
Para las imágenes de muestra: solo usé imágenes nativas con resolución SDXL o 2MP (por ejemplo 1216x1632). Este modelo puede manejar resoluciones aún mayores.. He probado este checkpoint hasta 2500x2500 pero recomiendo usar alrededor de 2000x2000.
Para las configuraciones recomiendo usar unos 30 pasos y 2-2.5cfg. Usualmente uso 2.2 o 2.3 en mi flujo. Para las muestras usé DPM++ 2M con scheduler Simple.
Pronto añadiré más versiones pero no tengo mucho tiempo antes de Navidad..
Configuraciones
Pronto añadiré un nuevo flujo dedicado para Comfy. Por ahora puedes descargar y abrir las imágenes de muestra..
La versión "Todo en uno" también funciona bien con Forge..
Básicamente funciona con las mismas configuraciones que la Versión 2.1 (ver abajo)
Usa 20-30 pasos con alrededor de 2.2cfg..
Versión 2.1_de-distilled_experimental (FUSIÓN)
Esta versión es completamente diferente y funciona realmente distinto a un modelo Flux normal!
Es una fusión experimental entre mi versión 2.0 y una versión de-distilled https://huggingface.co/nyanko7/flux-dev-de-distill. Ocurrió un poco por accidente pero los resultados son impresionantes. Obtendrás detalles impresionantes. Además sigue muy bien los prompts... Así que lo próximo que haré es entrenar directamente con el modelo de-distilled. Ya hice algunos test de Loras con él. Es muy experimental así que por favor avísame si encuentras errores que no estén listados más abajo. Si tienes buenas imágenes publícalas.. también las malas, esto puede ayudar a mejorar las cosas :-). Tal vez también pruebe la versión 2.0 y dime cuál tipo de checkpoint te funciona mejor.
¡Atención!
El flujo Flux normal no funciona con esta versión. ¡NECESITAS descargar mi flujo de trabajo para usarlo!
También puedes probar algo por ti mismo pero por favor no me culpes por malas imágenes. Además este es un modelo muy experimental... revisa las desventajas abajo..
Ventajas y desventajas de este checkpoint:
Este checkpoint puede crear detalles extremos... Esto tiene un precio... Es lento comparado con los checkpoints Flux normales. Lo bueno es que a menudo no necesitas un escalado adicional. En lugar de usar la Guía Flux este modelo usa la escala cfg. Lo que también significa que no funcionará con flujos de trabajo estándar.
¡Puedes usar Prompts negativos! Esto ayuda a sacar cosas de la imagen que no deseas.
A veces pueden aparecer artefactos... Puedes solucionarlo con un pequeño escalado (estoy trabajando en ello). Aquí hay un ejemplo.. esto pasa extrañamente no con todas las semillas.. ACTUALIZACIÓN: Esto no es un problema del modelo, sino del flujo de trabajo.. Estoy trabajando en una solución. Si ocurre, puedes probar un primer escalado de 1.14 en lugar de 1.2.

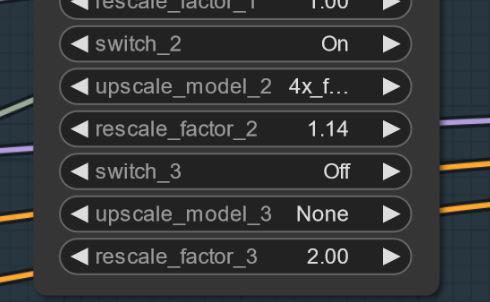
Configuraciones y flujo V2.1:
Aquí puedes encontrar el flujo para ello: https://civitai.com/articles/8419
Configuraciones: A diferencia del Flux normal no necesita la escala de Guía Flux. Usa cfg en su lugar. Usualmente uso 3 de cfg para el flujo.. Algunas imágenes pueden necesitar escalas cfg más bajas
Lo más importante puede ser apagar la escala de Guía Flux..
Sin el flujo, lo probé con 30 pasos y 2-3cfg. Esto puede ser también la configuración para Forge. Intenta experimentar aquí.
Recomiendo usar la palabra "blurry" en los negativos
Sampler y scheduler:
Puedes elegir entre varios samplers que funcionan:
Euler, Heun, DPM++2m, deis, DDIM funcionan muy bien.
Mayormente uso "simple" como scheduler
Si encuentras mejores configuraciones dímelo.. :-)
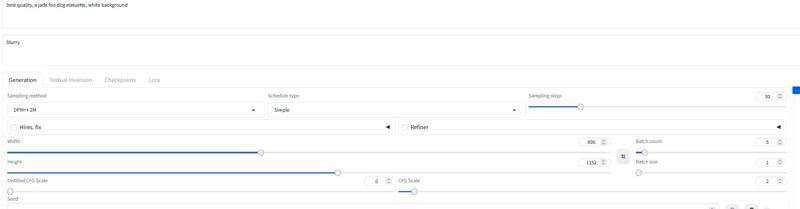
Para Forge recomiendo usar el modelo AIO.. aquí un ejemplo de configuración para Forge
Versión 2.0_dev_experimental
Bueno.. esta es una versión experimental.. El objetivo fue crear un modelo más coherente y rápido. Entrené algunos loras propios adicionales y luego fusioné los modelos resultantes de una manera especial (Tensor merge). Tiene un T5xxl personalizado que modifiqué con "Attention Seeker". Para ganar velocidad y calidad adicional integré el lora Hyper Flux de ByteDance. Esto significa que desplazó el área de trabajo.. Te muestro qué significa esto.. Aquí está la imagen principal del título..
16 pasos V 2.0
 30 pasos V 1.0
30 pasos V 1.0
 Desventajas:
Desventajas:
Primero, esta versión es un poco más grande que la anterior.. segundo, aún tengo que crear la versión solo Unet. Actualizaré cuando esté lista..
Configuraciones y flujo V2.0:
Ahora puedes ejecutar el modelo con menos pasos.. 16 pasos equivalen a 30 pasos del modelo antiguo.
Sigo recomendando usar entre 20-30 pasos porque normalmente obtienes mejor calidad.
Sampler: Prefiero Euler con Simple como scheduler. La guía puede configurarse entre 1.5-3 (por supuesto, siéntete libre de probar fuera de este rango). La guía de 1.8 aún funciona bien para imágenes realistas. También puedes probar otros samplers. DPM++2M y Heun funcionan muy bien.
Flujo 2.0:
He creado un nuevo flujo para V2.0 y V1.0. Este incluye el nuevo generador de prompts Flux. Además, agregué la segunda etapa del escalado. https://civitai.com/articles/7946
Forge:
También probé este modelo con Forge y funcionó muy bien.. Las imágenes pueden diferir entre Comfy UI y Forge..
Versión 1.0_dev_beta:
Este modelo es mi primera entrega de la serie. Por favor, dame opiniones y publica imágenes. Esto me ayuda a mejorar el proyecto. Hay varias versiones para elegir. El mejor modelo en calidad es la versión FP16. La versión FP16 es grande y necesitarás una tarjeta gráfica potente y mucha RAM. La versión FP8 es la que considero buena solución entre calidad y rendimiento. Si quieres una versión GGUF descarga la Q8_0. Las versiones GGUF Q4_0/4.1 fueron solicitadas. Son pequeñas, pero perderás algo de calidad.
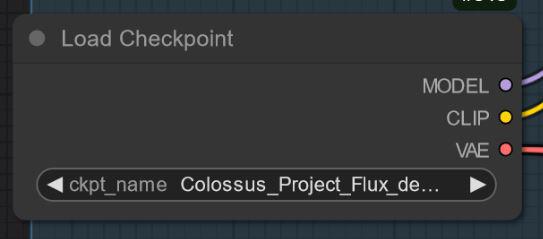
Básicamente hay dos tipos de mis modelos: los "todo en uno" que solo necesitan un archivo para descargar. Incluyen Clip_l, T5xxl fp8 y VAE incorporados. (ver más abajo). Coloca esto en tu carpeta checkpoints.
Las otras versiones son solo UNET. Ahí necesitas cargar todos los archivos por separado.
En cualquier caso necesitas descargar mi Clip_L para que funcionen bien..
También es importante elegir el clip T5xxl correcto. Para la versión FP8 es el clip fp8_e4m3fn t5xxl. Para FP16 es el clip FP16. Asegúrate de seleccionar el tipo de peso predeterminado. (Abajo hay una imagen de ejemplo para la versión fp8)
Para la versión GGUF necesitas el cargador GGUF!
Algunas cosas conocidas por ahora respecto a V1.0:
Este es solo el primer modelo de la serie así que puede tener problemas con algunos prompts o estilos como arte. La próxima versión recibirá más entrenamientos. Avísame de cosas que el modelo no pueda hacer..
Configuraciones y flujo:
Lo probé con unos 30 pasos, Euler con Simple como scheduler. La guía puede configurarse entre 1.5-3 (siéntete libre de probar fuera de ese rango)
La guía de 1.8 funciona bien para imágenes realistas.
Siéntete libre de experimentar con estas configuraciones.. Si obtienes buenos resultados publícalos.
He añadido las imágenes de muestra como datos de entrenamiento.. Dentro está el flujo para Comfy. Aquí el flujo para descargar: https://civitai.com/articles/7946
Modelo "Todo en uno":
Solo UNET:
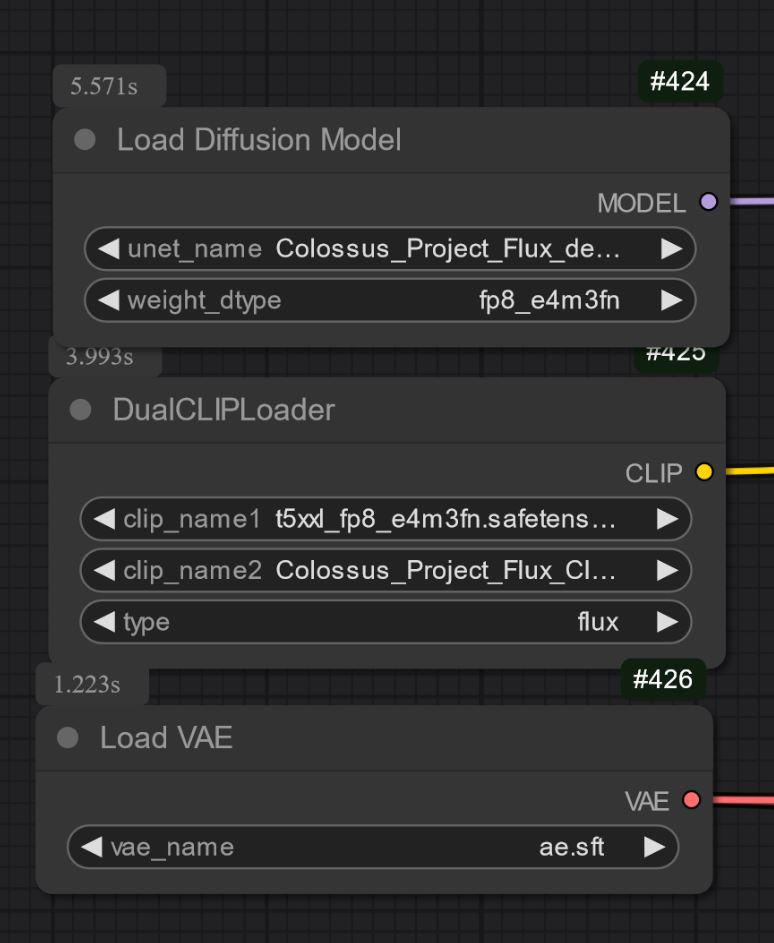 Necesitas descargar también el clip_L. Es un archivo de 240MB.
Necesitas descargar también el clip_L. Es un archivo de 240MB.
GGUF: He añadido el flujo para GGUF aquí: https://civitai.com/articles/7946
Importante:
El modelo dev no está pensado para uso comercial. Para eso publicaré el modelo "schnell" en otro lugar. Está pensado más para uso personal o científico.
LICENCIA:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
Créditos:
theunlikely https://huggingface.co/theunlikel (gracias de nuevo)
Versión 2.1/V4.2/5.0: Flux_dev_de-distill de nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
Desde V2.0: Hyper Lora de ByteDance https://huggingface.co/ByteDance/Hyper-SD
Black Forrest por su increíble modelo Flux https://huggingface.co/black-forest-labs

Detalles del Modelo
Tipo de modelo
Modelo base
Versión del modelo
Hash del modelo
Creador
Discusión
Por favor log in para dejar un comentario.
Colección de Modelos - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8
















































