SD XL - v1.0 Corrección VAE
Palabras Clave y Etiquetas Relacionadas
Imágenes destacadas












Prompts Negativos Recomendados
(deformed iris, deformed pupils), text, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, (extra fingers), (mutated hands), poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, (fused fingers), (too many fingers), long neck, camera
Parámetros Recomendados
samplers
steps
cfg
resolution
Consejos
El modelo está destinado a fines de investigación, incluyendo generación de obras de arte, herramientas educativas y despliegue seguro.
No está destinado a generar representaciones fidedignas o verdaderas de personas o eventos.
Las limitaciones incluyen fotorrealismo imperfecto, incapacidad para renderizar texto legible, desafíos con indicaciones compositivas y posible generación incorrecta de rostros.
El modelo usa dos codificadores de texto preentrenados: OpenCLIP-ViT/G y CLIP-ViT/L.
La tubería en dos pasos incluye generación latente base seguida de refinamiento en alta resolución usando SDEdit (img2img).
Patrocinadores del Creador
Originalmente Publicado en Hugging Face y compartido aquí con permiso de Stability AI.
Originalmente Publicado en Hugging Face y compartido aquí con permiso de Stability AI.
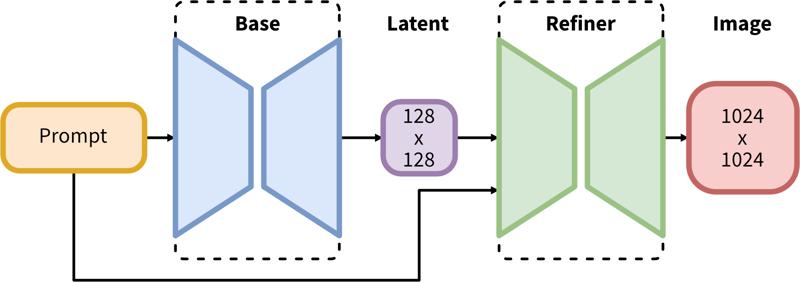
SDXL consta de una tubería en dos pasos para difusión latente: primero, usamos un modelo base para generar tensores latentes del tamaño de salida deseado. En el segundo paso, usamos un modelo especializado de alta resolución y aplicamos una técnica llamada SDEdit (https://arxiv.org/abs/2108.01073, también conocida como "img2img") a los tensores latentes generados en el primer paso, usando el mismo prompt.
Descripción del Modelo
Desarrollado por: Stability AI
Tipo de modelo: Modelo generativo texto a imagen basado en difusión
Descripción del modelo: Este es un modelo que puede usarse para generar y modificar imágenes basadas en indicaciones de texto. Es un Modelo de Difusión Latente que usa dos codificadores de texto preentrenados y fijos (OpenCLIP-ViT/G y CLIP-ViT/L).
Recursos para más información: Repositorio en GitHub.
Fuentes del Modelo
Repositorio: https://github.com/Stability-AI/generative-models
Demo [opcional]: https://clipdrop.co/stable-diffusion
Usos
Uso Directo
El modelo está destinado únicamente a fines de investigación. Las áreas y tareas posibles de investigación incluyen
Generación de obras de arte y uso en diseño y otros procesos artísticos.
Aplicaciones en herramientas educativas o creativas.
Investigación sobre modelos generativos.
Despliegue seguro de modelos que tienen el potencial de generar contenido dañino.
Explorar y comprender las limitaciones y sesgos de los modelos generativos.
Los usos excluidos se describen a continuación.
Usos Fuera de Alcance
El modelo no fue entrenado para representar fiel o verazmente personas o eventos, por lo que usarlo para generar tal contenido está fuera del alcance de las capacidades de este modelo.
Limitaciones y Sesgos
Limitaciones
El modelo no alcanza un fotorrealismo perfecto
El modelo no puede renderizar texto legible
El modelo tiene dificultades con tareas más complejas que involucran composición, como representar una imagen correspondiente a “Un cubo rojo encima de una esfera azul”
Las caras y personas en general pueden no generarse adecuadamente.
La parte de codificación automática del modelo es con pérdida.
Sesgos
Si bien las capacidades de los modelos de generación de imágenes son impresionantes, también pueden reforzar o agravar sesgos sociales.
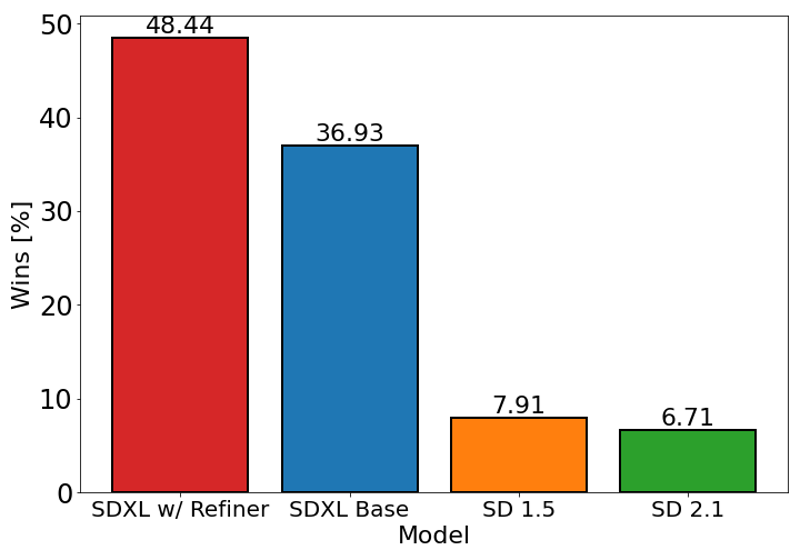
El gráfico anterior evalúa la preferencia del usuario por SDXL (con y sin refinamiento) sobre Stable Diffusion 1.5 y 2.1. El modelo base SDXL rinde significativamente mejor que las variantes anteriores, y el modelo combinado con el módulo de refinamiento logra el mejor rendimiento general.

Detalles del Modelo
Tipo de modelo
Modelo base
Versión del modelo
Hash del modelo
Discusión
Por favor log in para dejar un comentario.
Colección de Modelos - SD XL


Imágenes por SD XL - v1.0 Corrección VAE
Imágenes con modelo base

Imágenes con sdxl



Imágenes con stability ai



