Stable Cascade - base
Palabras Clave y Etiquetas Relacionadas
Imágenes destacadas


Parámetros Recomendados
steps
resolution
Consejos
Usa la versión de 3.6 mil millones de parámetros de la Etapa C para obtener los mejores resultados, ya que el ajuste fino principal se hizo en ella.
Usa la variante de 1.5 mil millones de parámetros para la Etapa B para destacar en la reconstrucción de detalles pequeños y finos.
El modelo es muy adecuado para entrenamientos e inferencias eficientes debido al espacio latente más pequeño y soporta extensiones como finetuning, LoRA, ControlNet, IP-Adapter y LCM.
El modelo está destinado únicamente a fines de investigación y no debe usarse para generar representaciones fácticas ni violar la Política de Uso Aceptable de Stability AI.
Los rostros y personas pueden no generarse correctamente ya que la auto codificación del modelo es con pérdida.
Patrocinadores del Creador
Demostraciones:
- multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Demostraciones:
multimodalart: https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu: https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
Este modelo se basa en la arquitectura Würstchen y su principal
diferencia con otros modelos como Stable Diffusion es que funciona en un espacio latente mucho más pequeño. ¿Por qué es esto
importante? Cuanto más pequeño es el espacio latente, más rápido se puede ejecutar la inferencia y más barato se vuelve el entrenamiento.
¿Qué tan pequeño es el espacio latente? Stable Diffusion usa un factor de compresión de 8, resultando en que una imagen de 1024x1024 se
codifica a 128x128. Stable Cascade logra un factor de compresión de 42, lo que significa que es posible codificar una
imagen de 1024x1024 a 24x24, manteniendo reconstrucciones nítidas. Luego, el modelo condicionado por texto se entrena en el
espacio latente altamente comprimido. Versiones anteriores de esta arquitectura lograron una reducción del costo de 16 veces respecto a Stable
Diffusion 1.5. <br> <br>
Por lo tanto, este tipo de modelo es muy adecuado para usos donde la eficiencia es importante. Además, todas las extensiones conocidas
como finetuning, LoRA, ControlNet, IP-Adapter, LCM, etc., también son posibles con este método.
Detalles del Modelo
Descripción del Modelo
Stable Cascade es un modelo de difusión entrenado para generar imágenes a partir de un prompt de texto.
Desarrollado por: Stability AI
Financiado por: Stability AI
Tipo de modelo: Modelo generativo de texto a imagen
Fuentes del Modelo
Para fines de investigación, recomendamos nuestro repositorio en StableCascade en Github (https://github.com/Stability-AI/StableCascade).
Repositorio: https://github.com/Stability-AI/StableCascade
Resumen del Modelo
Stable Cascade consta de tres modelos: Etapa A, Etapa B y Etapa C, representando una cascada para generar imágenes,
de ahí el nombre "Stable Cascade".
Las Etapas A y B se usan para comprimir imágenes, similar a lo que hace el VAE en Stable Diffusion.
Sin embargo, con esta configuración, se puede lograr una compresión mucho mayor de imágenes. Mientras que los modelos de Stable Diffusion usan un
factor de compresión espacial de 8, codificando una imagen con resolución de 1024 x 1024 a 128 x 128, Stable Cascade logra
un factor de compresión de 42. Esto codifica una imagen de 1024 x 1024 a 24 x 24, pudiendo decodificar la
imagen con precisión. Esto conlleva la gran ventaja de entrenamientos e inferencias más económicos. Además, la Etapa C es responsable
de generar los pequeños latentes 24 x 24 dado un texto prompt. La siguiente imagen muestra esto visualmente.
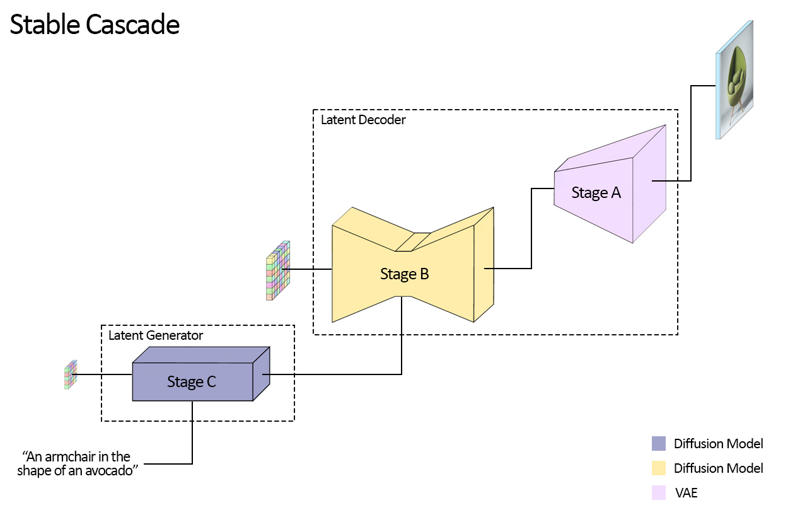
Para este lanzamiento, ofrecemos dos puntos de control para la Etapa C, dos para la Etapa B y uno para la Etapa A. La Etapa C viene con
una versión de 1 mil millones y otra de 3.6 mil millones de parámetros, pero recomendamos encarecidamente usar la versión de 3.6 mil millones, ya que la mayor parte del trabajo fue
realizado en su ajuste fino. Las dos versiones para la Etapa B tienen 700 millones y 1.5 mil millones de parámetros. Ambas logran
excelentes resultados, sin embargo, la de 1.5 mil millones destaca en reconstruir detalles pequeños y finos. Por lo tanto, se obtienen
mejores resultados si se usa la variante más grande de cada una. Finalmente, la Etapa A contiene 20 millones de parámetros y es fija debido a
su pequeño tamaño.
Evaluación
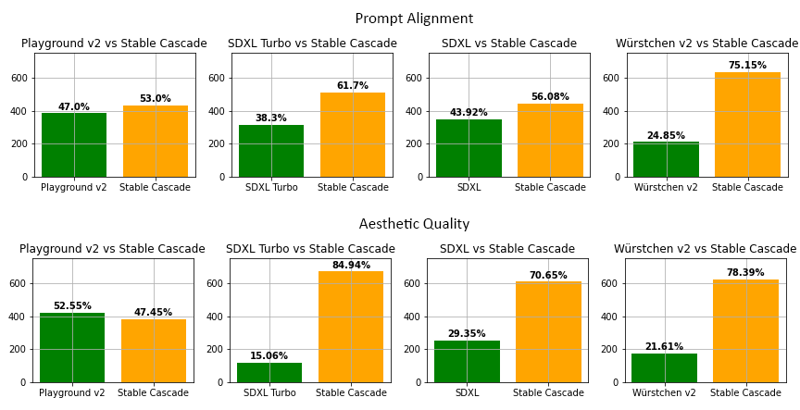
Según nuestra evaluación, Stable Cascade tiene el mejor desempeño tanto en alineación con el prompt como en calidad estética en casi todas
las comparaciones. La imagen superior muestra los resultados de una evaluación humana usando una mezcla de parti-prompts (enlace) y prompts estéticos. Específicamente, Stable Cascade (30 pasos de inferencia) se comparó contra Playground v2 (50 pasos de inferencia), SDXL (50 pasos de inferencia), SDXL Turbo (1 paso de inferencia) y Würstchen v2 (30 pasos de inferencia).
Ejemplo de Código
⚠️ Importante: Para que el código a continuación funcione, debe instalar diffusers desde esta rama mientras la PR está en desarrollo.
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Gato antropomórfico vestido como piloto"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#Ahora decoder_output es una lista con tus imágenes PILUsos
Uso Directo
El modelo está destinado por ahora a fines de investigación. Áreas y tareas posibles de investigación incluyen
Investigación sobre modelos generativos.
Despliegue seguro de modelos que tienen el potencial de generar contenido dañino.
Exploración y comprensión de las limitaciones y sesgos de los modelos generativos.
Generación de obras de arte y uso en diseño y otros procesos artísticos.
Aplicaciones en herramientas educativas o creativas.
Usos excluidos se describen a continuación.
Uso Fuera del Alcance
El modelo no fue entrenado para representar fiel o verdaderamente a personas o eventos,
por lo tanto, usar el modelo para generar dicho contenido está fuera del alcance de las capacidades de este modelo.
El modelo no debe usarse de ninguna manera que viole la Política de Uso Aceptable de Stability AI.
Limitaciones y Sesgos
Limitaciones
Los rostros y personas en general pueden no generarse correctamente.
La parte de auto codificación del modelo es con pérdida.
Recomendaciones
El modelo está destinado únicamente para fines de investigación.
Cómo Comenzar con el Modelo

Detalles del Modelo
Tipo de modelo
Modelo base
Versión del modelo
Hash del modelo
Creador
Discusión
Por favor log in para dejar un comentario.
Colección de Modelos - Stable Cascade
Imágenes por Stable Cascade - base
Imágenes con anime










Imágenes con arte










Imágenes con modelo base

Imágenes con logo










