AlbedoBase XL - v1.1
Images en vedette



Prompts négatifs recommandés
strabismus
inconsiderate details
Paramètres recommandés
samplers
steps
cfg
resolution
vae
Paramètres haute résolution recommandés
upscaler
upscale
steps
denoising strength
Conseils
Si la génération d'image ne produit aucun résultat, essayez de passer à CLIP SKIP 2 ou modifiez légèrement le prompt en changeant l'ordre ou les mots.
L'utilisation de prompts en forme de phrases tend à améliorer la qualité d'image plus que les listes de tags.
Laisser le champ du prompt négatif vide produit souvent de meilleurs résultats.
Consultez la grille spec pour les réglages optimaux avant utilisation.
Expérimentez avec quelques prompts négatifs spécifiques comme 'strabisme' pour résoudre les problèmes d'yeux asymétriques ou de pixellisation.
Points forts de la version
v1.1
Stabilisé.
Plus détaillé.
Si vous vous considérez comme un utilisateur avancé, je recommande la version 1.0. Si la version 1.0 trouve les bons réglages, elle peut produire des œuvres beaucoup plus vivantes.
La grille spec (349.7 MB) : télécharger
Sponsors du créateur
Si vous avez trouvé de la valeur dans le modèle, veuillez envisager d'offrir votre soutien. Votre contribution sera entièrement dédiée à l'avancement de la communauté SDXL.
Si vous avez trouvé de la valeur dans le modèle, veuillez envisager d'offrir votre soutien. Votre contribution sera entièrement dédiée à l'avancement de la communauté SDXL.
🙋🏼♂️ rejoignez-nous (discord) ㅤ|ㅤ 🛒 achatㅤ |ㅤ 🌱 don
AlbedoBase XL (SFW&NSFW)
Le refiner est inutile, et le VAE est inclus.
OBJECTIF
Stable Diffusion XL compte 3,5 milliards de paramètres (hors Refiner), soit environ 3,6 fois plus que la version SD v1.5. Je crois que ce n'est pas qu'un simple chiffre, mais un nombre qui peut conduire à une amélioration significative des performances.
Il y a quelque temps, nous avons réalisé que les performances globales de SD v1.5 s'étaient améliorées bien au-delà de toute imagination grâce aux contributions explosives de notre communauté. Par conséquent, je travaille à compléter ce modèle AlbedoBase XL afin de reproduire de manière optimale l'amélioration des performances survenue dans v1.5 dans cette version XL également.
Mon objectif est de tester directement les performances de tous les Checkpoints et LoRAs publiquement mis en ligne sur Civitai, et de fusionner uniquement les ressources jugées optimales après plusieurs filtres. Cela surpassera les performances des IA de génération d'images d'entreprises telles que Midjourney.
À ce jour, AlbedoBase XL v3.1 Large a fusionné environ 200 checkpoints sélectionnés et 251 LoRAs.
JOURNAL
v3.1-Large
• Fusion de plus de 50 dernières versions sélectionnées de modèles SDXL utilisant le script récursif employé dans la V3.
La grille spec (370.7 MB) : télécharger


v3-mini
Je m'excuse sincèrement de vous avoir fait attendre aussi longtemps.
J'ai dû gérer des affaires personnelles, et pendant que je travaillais sur la nouvelle version, j'ai également affronté des problèmes de santé. Même en écrivant ceci, je lutte encore contre ces difficultés.
J’ai senti qu’un bref résumé ne suffirait pas, alors je vous demande de bien vouloir comprendre ce message plus détaillé.
Depuis la sortie de la version 2.0, je me consacre à l'étude autonome du deep learning. Je n'ai pas de diplôme formel, et à part une aptitude modeste en programmation, je viens uniquement du domaine des arts. Par conséquent, il me manque la base mathématique et scientifique pour faire des percées majeures, vu le temps et les efforts investis. Malgré cela, cette expérience d'étude et de recherche autodirigée a été un trésor inestimable dans ma vie.
Récemment, j'ai eu une idée pouvant potentiellement être une avancée importante. Après avoir retravaillé des centaines de formules et méthodes depuis la version 2.0, j’ai développé un algorithme assez intriguant et réussi. Le processus de fusion du modèle s’est basé sur SDXL1.0 et SD1.5, ainsi que d’autres modèles soigneusement sélectionnés. Ceux-ci ont été classés en cinq catégories principales : « ANIME », « RÉALISME », « ARTISTIQUE », « NSFW » et « BASE », et introduits dans l’algorithme de fusion comme jeux de données. Cette approche a donné des résultats fascinants.
Cependant, aussi difficile que fut le développement de l’algorithme, rien n’a été aussi éprouvant que la phase de test des performances. Ma santé physique et mentale s’est nettement dégradée durant cette période, au point de réaliser que je ne pouvais plus continuer seul. C’est cette situation qui m’a finalement décidé à publier cette version.
Et maintenant, je suis heureux d’annoncer la sortie très attendue de la version AlbedoBaseXL V3 Mini. Bien que ce modèle soit une fusion à plus petite échelle, il n’est limité à aucun domaine spécifique et fonctionne remarquablement bien dans divers domaines. Il a le potentiel de servir de nouveau modèle de base pour SDXL1.0. (Pour référence, mon algorithme de fusion n’est pas une « fusion linéaire », donc il peut essentiellement être considéré comme un nouveau modèle affiné.)
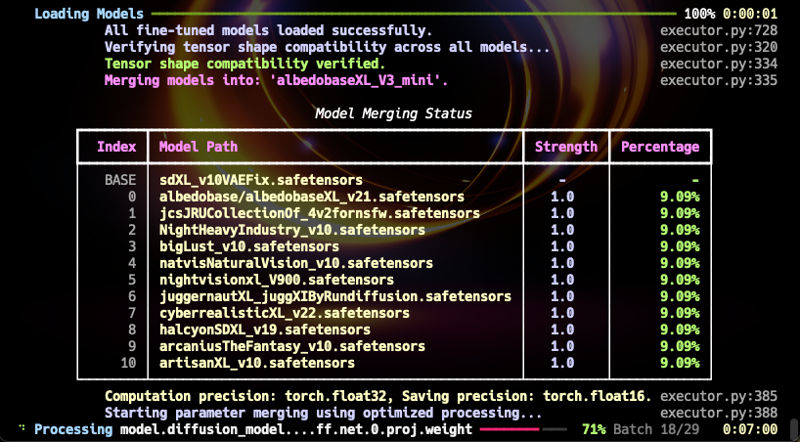
Ce modèle, ainsi que les modèles AlbedoBase existants, est polyvalent et dépasse toutes les versions précédentes sur tous les plans. (Le contenu NSFW, bien qu'il ne soit pas extrême, offre une gamme d'expression plus large comparée aux versions antérieures comme la v2.1. Un modèle de fusion NSFW dédié sera publié à l’avenir.)
Par ailleurs, j’ai remarqué que de nombreux modèles partagés ont récemment adopté des licences interdisant la fusion ou la commercialisation externe. Cela a été décevant, car cela m’a empêché d’utiliser certains modèles vraiment excellents pour la fusion.
Je tiens à exprimer toute ma gratitude aux développeurs de modèles ayant offert des licences gratuites, permettant que leurs modèles de haute qualité — produits d’un travail considérable — soient utilisés pour la fusion.
Je serai de retour bientôt.
J’attends impatiemment vos tests de performances dans de nombreux domaines, y compris ANIME, RÉALISME, ARTISTIQUE, 2.5D, 3D, et NSFW.
En tant que développeurs de modèles, nous ne faisons que planter les graines. C’est finalement vous, utilisateurs et artistes, qui les cultivez et faites fleurir les fruits.
Merci, comme toujours.
Pour ceux qui souhaitent soutenir mon travail par une petite contribution financière, veuillez envisager d’utiliser les liens ci-dessous. Je suis actuellement dans l'incapacité de trouver un emploi et je fais face à un avenir incertain quant à ma subsistance.
La grille spec (380.5 MB) : télécharger


v2.1
Refusion et ajustement de v0.1 à 2.0 en utilisant le nouvel algorithme et formule de fusion.
La grille spec (424.5 MB) : télécharger

v2.0
Je tiens à remercier tous ceux qui m'ont aidé sur la page AlbedoBase XL Pre. Sans vous, la date de sortie aurait probablement été beaucoup plus tard. Merci beaucoup !
J'ai écrit un script personnalisé pour fusionner les modèles existants AlbedoBase XL en un seul. Alignant finement les poids des lignes et colonnes de tous les blocs U-NET et CLIP selon ma formule unique.
Si vous rencontrez un bug dans la génération d'image (aucun résultat), essayez de passer à CLIP SKIP 2 ou modifiez légèrement le prompt ! Il peut y avoir des combinaisons de prompts que CLIP ne reconnaît pas. Dans ce cas, vous pouvez changer l'ordre des mots, utiliser des mots différents ou, plus simplement, changer le CLIP SKIP. Je travaillerai progressivement à résoudre ces problèmes à l'avenir comme pour la v1.3.
La grille spec (403.5 MB) : télécharger
v1.3
Pour illustrer la qualité associée à l'aléatoire du modèle, j'ai standardisé la valeur du seed à '9' pour toutes les images de démonstration destinées à l'échantillonnage et procédé à leur génération immédiate.
Particulièrement pour cette version, en raison de l'impact important des prompts négatifs, laisser le champ du prompt négatif vide produit généralement une bonne qualité.
La grille spec (438.7 MB) : télécharger

Comme vous pouvez le voir, lorsque le nombre de Steps augmente, il devient utilisable avec tous les samplers, et la qualité s'améliore également.
Grâce à l'effet des LoRA que j'ai développés et fusionnés, comme décrit ci-dessous, l'utilisation de prompts en forme de phrases plutôt que de listes de tags est directement liée à l'amélioration de la qualité.
J'ai fusionné 45 checkpoints et 7 LoRAs. Ensuite, j'ai fusionné AlbedoBase v0.4 et v0.3 dans l'ordre, moins de 0~5 %, pour réactiver les modèles fusionnés dilués qui étaient devenus obsolètes.
Parmi les 7 LoRAs, une a été créée par moi. Elle consiste à analyser et annoter des légendes pour un total de 174 photos picturales de haute qualité utilisant GPT4-V. La fusion de cette LoRA a donné des images étonnamment nettes et une compréhension des prompts impressionnante.
Mes LoRAs auto-créées sont exclusivement disponibles à l'achat pour mes supporters Ko-fi au niveau Creative ou supérieur.
v1.2
Fusion des 22 derniers checkpoints.
La grille spec (565.6 MB) : télécharger
v1.1
Stabilisé.
Plus détaillé.
Si vous vous considérez comme un utilisateur avancé, je recommande la version 1.0. Si la version 1.0 trouve les bons réglages, elle peut produire des œuvres beaucoup plus vivantes.
La grille spec (349.7 MB) : télécharger
v1.0
Fusion de 106 LoRAs.
Fusion de 19 Checkpoints.
Le modèle peut produire des résultats différents selon les paramètres choisis, il est donc important de consulter la grille spec avant de l'utiliser.
J’ai constaté que l’utilisation de quelques prompts négatifs spécifiques peut aider à résoudre les problèmes d’yeux asymétriques ou d’images pixélisées. La grille Spec peut varier selon votre CPU ou GPU, donc utilisez-la comme référence générale. Expérimentez avec quelques prompts négatifs pour améliorer la qualité (ex : strabisme). Je trouve qu’il est difficile de satisfaire tous les réglages également en augmentant le nombre de LoRA fusionnées. Cependant, je souhaite que vous vous concentriez sur cet avantage dans la version 1.0, car elle peut produire des œuvres de qualité étonnante dans divers aspects avec les bons réglages. Je reviendrai avec une version plus stable à l’avenir.
Vous pouvez trouver des valeurs de réglage utiles dans la vitrine ou en recherchant d’autres utilisateurs.
Comme toujours, il est préférable de laisser le prompt négatif vide pour de meilleurs résultats.
Cette v1.0 a demandé beaucoup de travail, donc je prends une pause pour un moment. J’espère que vous apprécierez l’utilisation du modèle, et si vous le fusionnez, merci de le partager gratuitement sur Civitai. Ainsi, nous pourrons l’améliorer ensemble.
La grille spec (479.4 MB) : télécharger
v0.4
Fusion de 132 LoRAs.
Fusion de 4 Checkpoints.
La grille spec : télécharger
v0.3
Amélioration dans tous les samplers.
Réalisme saisissant.
Stabilisé.
La grille spec : télécharger
v0.2
Améliorations significatives de la clarté et des détails.
Amélioration de la représentation des mains et pieds.
Améliorations esthétiques majeures ; composition, abstraction, dynamique, lumière et couleur, etc.
v0.1
Après un affinage approprié sur le modèle SDXL1.0, fusion méticuleuse et ciblée de plus de 40 modèles de haute qualité
principalement disponibles sur Civitai.
Les tests se sont concentrés principalement sur garantir une qualité maximale avec un nombre minimal de tokens dans les prompts, et il n’a pas été confirmé jusqu’à quel point la qualité pourrait s’améliorer en utilisant un grand nombre de tokens. (Veuillez réaliser vos propres tests et partager les résultats)
En général, les plus beaux résultats se situent à mi-chemin entre réalisme et animation.
Néanmoins, avec un prompt approprié, il n’y a généralement rien qu’il ne puisse exprimer. (J’affirme qu’il possède une valeur abondante en tant que modèle de base surpassant les autres en fusion. Cependant, gardez à l’esprit qu’il s’agit actuellement de la v0.1)

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Mots entraînés
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.






































