Animagine XL 4.0 - v4 Opt
Mots-clés et tags associés
Images en vedette





Prompts recommandés
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
Prompts négatifs recommandés
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
Paramètres recommandés
samplers
steps
cfg
resolution
Conseils
Utilisez des légendes basées sur des tags avec la méthode de classement des tags pour de meilleurs résultats : 1girl/1boy/1other, nom du personnage, série, classification, autres tags, puis amélioration de la qualité.
Ajoutez les tags d'amélioration de la qualité à la fin du prompt : masterpiece, high score, great score, absurdres.
Utilisez les prompts négatifs recommandés pour éviter les artefacts et erreurs indésirables.
L'échelle CFG optimale est entre 4 et 7, recommandée à 5.
Les étapes d'échantillonnage optimales sont entre 25 et 28, avec 28 recommandé.
L'échantillonneur préféré est Euler Ancestral (Euler a).
Notez les limitations du modèle comme la difficulté avec l'anatomie complexe et le rendu de texte.
Les personnages récents pourraient avoir une précision moindre en raison de données d'entraînement limitées.
Points forts de la version
Avec la sortie de Animagine XL 4.0 Opt (Optimisé), le modèle a été affiné davantage avec un jeu de données supplémentaire, améliorant ses performances pour un usage général. Cette mise à jour apporte plusieurs améliorations :
Meilleure stabilité pour des sorties plus cohérentes
Amélioration de l'anatomie avec des proportions plus précises
Réduction du bruit et des artefacts dans les générations
Correction des problèmes de faible saturation, résultant en des couleurs plus riches
Amélioration de la précision des couleurs pour des résultats plus attrayants visuellement
Sponsors du créateur
Soutenez le développement d'Animagine XL
- Faites un don en ETH/USDT à
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - GitHub Sponsors : https://github.com/sponsors/cagliostrolab/
- Rejoignez la communauté Discord : https://discord.gg/cqh9tZgbGc
Veuillez lire notre guide approfondi pour la création de prompts sur le Blog Cagliostrolab
Présentation
Animagine XL 4.0, aussi stylisé sous le nom de Anim4gine, est le modèle SDXL finement ajusté ultime à thème anime et le dernier opus de la série Animagine XL. Bien que ce soit une continuité, le modèle a été réentraîné à partir de Stable Diffusion XL 1.0 avec un immense ensemble de données de 8,4 millions d'images en style anime diversifiées provenant de diverses sources avec une coupure des connaissances au 7 janvier 2025 et affiné pendant environ 2650 heures GPU. Comme la version précédente, ce modèle a été entraîné en utilisant la méthode de classement des tags pour l'identité et la formation du style.
Avec la sortie de Animagine XL 4.0 Opt (Optimisé), le modèle a été affiné davantage avec un jeu de données supplémentaire, améliorant la stabilité, la précision anatomique, la réduction du bruit, la saturation des couleurs et la précision globale des couleurs. Ces améliorations rendent Animagine XL 4.0 Opt plus cohérent et visuellement attrayant tout en maintenant la qualité signature de la série.
Journal des modifications
- 2025-02-13 – Ajout d'Animagine XL 4.0 Opt et Animagine XL 4.0 Zero
Meilleure stabilité pour des sorties plus cohérentes
Amélioration de l'anatomie avec des proportions plus précises
Réduction du bruit et des artefacts dans les générations
Correction des problèmes de faible saturation, résultant en des couleurs plus riches
Amélioration de la précision des couleurs pour des résultats plus attrayants visuellement
- 2025-01-24 – Première publication
Détails du modèle
Développé par : Cagliostro Research Lab
Type de modèle : Modèle génératif text-to-image basé sur la diffusion
Licence : CreativeML Open RAIL++-M
Description du modèle : Ce modèle peut être utilisé pour générer et modifier spécifiquement des images à thème anime à partir d'un prompt textuel
Affiné à partir de : Stable Diffusion XL 1.0
Consignes d'utilisation
Le résumé est visible dans l’image pour le guide des prompts.

1. Structure du prompt
Le modèle a été entraîné avec des légendes basées sur des tags et la méthode de classement des tags. Utilisez ce modèle structuré :
1girl/1boy/1other, nom du personnage, de quelle série, classification, tout le reste dans n’importe quel ordre et terminez par une amélioration de qualité
2. Tags d'amélioration de qualité
Ajoutez ces tags à la fin de votre prompt :
masterpiece, high score, great score, absurdres
3. Prompt négatif recommandé
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Paramètres optimaux
CFG Scale : 4-7 (5 recommandé)
Étapes d'échantillonnage : 25-28 (28 recommandé)
Échantillonneur préféré : Euler Ancestral (Euler a)
5. Résolutions recommandées
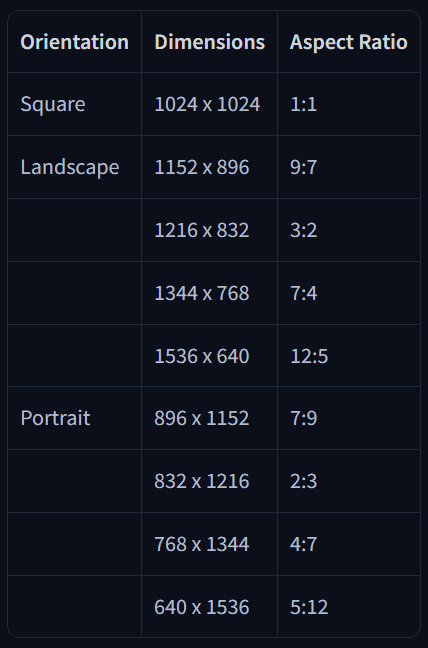
6. Exemple de structure finale de prompt
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, regardant le spectateur, extérieur, sourire, tendant la main vers le spectateur, nuit, masterpiece, high score, great score, absurdres
Tags spéciaux
Le modèle prend en charge divers tags spéciaux qui peuvent être utilisés pour contrôler différents aspects du processus de génération d'images. Ces tags sont soigneusement pondérés et testés pour fournir des résultats cohérents selon les prompts.
Tags de qualité
Les tags de qualité sont des contrôles fondamentaux qui influencent directement la qualité globale de l'image et le niveau de détail. Tags de qualité disponibles :
masterpiecebest qualitylow qualityworst quality
Tags de score
Les tags de score offrent un contrôle plus nuancé sur la qualité de l'image par rapport aux tags de qualité de base. Ils ont un impact plus fort sur la qualité de sortie dans ce modèle. Tags de score disponibles :
high scoregreat scoregood scoreaverage scorebad scorelow score
Tags temporels
Les tags temporels vous permettent d'influencer le style artistique basé sur des périodes spécifiques ou des années. Cela peut être utile pour générer des images avec des caractéristiques artistiques propres à une époque. Tags d'années supportés :
year 2005year {n}year 2025
Tags de classification
Les tags de classification aident à contrôler le niveau de sécurité du contenu des images générées. Ces tags doivent être utilisés de manière responsable et conformément aux lois et politiques de la plateforme applicables. Classifications supportées :
safesensitivensfwexplicit
Informations sur l'entraînement
Le modèle a été entraîné en utilisant du matériel de pointe et des hyperparamètres optimisés pour garantir une sortie de la plus haute qualité. Voici les spécifications techniques détaillées et les paramètres utilisés lors du processus d'entraînement :

Remerciements
Ce projet à long terme n'aurait pas été possible sans le travail révolutionnaire, les contributions innovantes et la documentation exhaustive fournies par Stability AI, Novel AI et Waifu Diffusion Team. Nous sommes particulièrement reconnaissants pour la subvention de démarrage de Main qui nous a permis de progresser au-delà de la V2. Pour cette itération, nous souhaitons exprimer notre sincère gratitude à toute la communauté pour leur soutien continu, en particulier :
Moescape AI : notre précieux partenaire de collaboration pour la distribution et les tests du modèle
Lesser Rabbit : pour avoir fourni les subventions essentielles en calcul et en recherche
Kohya SS : pour le développement du cadre d'entraînement open-source complet
discus0434 : pour la création du prédicteur esthétique open-source 2.5 leader dans l'industrie
Testeurs précoces : pour leur dévouement à fournir des retours critiques et une assurance qualité approfondie
Contributeurs
Nous exprimons notre profonde gratitude à nos membres d'équipe dévoués qui ont contribué significativement à ce projet, incluant mais sans s'y limiter :
Modèle
Gradio
Relations, finance et assurance qualité
Données
Les collectes de fonds sont de nouveau ouvertes !
Nous sommes ravis d'introduire de nouvelles méthodes de collecte de fonds via GitHub Sponsors pour soutenir l'entraînement, la recherche et le développement de modèles. Votre soutien nous aide à repousser les limites de ce qui est possible avec l'IA.
Vous pouvez nous aider en :
Donnant : Contribuez via ETH ou USDT à l'adresse ci-dessous.
Partageant : Faites connaître nos modèles et partagez vos créations !
Feedback : Dites-nous comment nous pouvons nous améliorer.
Adresse de donation :
ETH/USDT/USDC(e) : 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
GitHub Sponsor : https://github.com/sponsors/cagliostrolab/
Pourquoi utilisons-nous la cryptomonnaie ? :
Lorsque nous avons initialement lancé la collecte de fonds via Ko-fi et utilisé PayPal comme méthode de retrait, notre compte PayPal a été signalé puis finalement banni, malgré nos efforts pour expliquer l'objectif de notre projet. Malheureusement, cela nous a forcés à rembourser toutes les donations et nous a laissé sans moyen fiable de recevoir du soutien. Pour éviter ce genre de problème et garantir la transparence, nous avons maintenant opté pour la cryptomonnaie comme méthode de collecte.
Vous souhaitez donner en monnaie non cryptographique ?
Bien que nous ayons eu une mauvaise expérience avec PayPal, si vous souhaitez nous soutenir mais préférez ne pas utiliser la cryptomonnaie, n'hésitez pas à nous contacter via le serveur Discord pour des méthodes alternatives de donation.
Rejoignez notre serveur Discord
N'hésitez pas à rejoindre notre serveur discord : https://discord.gg/cqh9tZgbGc
Limitations
Format du prompt : Limité aux prompts textuels basés sur des tags ; l'entrée en langage naturel peut ne pas être efficace
Anatomie : Peut rencontrer des difficultés avec des détails anatomiques complexes, en particulier les poses des mains et le comptage des doigts
Génération de texte : Le rendu de texte dans les images n'est actuellement pas pris en charge et n'est pas recommandé
Nouveaux personnages : Les personnages récents peuvent avoir une précision moindre en raison de la disponibilité limitée des données d'entraînement
Plusieurs personnages : Les scènes avec plusieurs personnages peuvent nécessiter un ingénierie de prompt soigneuse
Résolution : Les résolutions plus élevées (par ex. 1536x1536) peuvent montrer une dégradation car l'entraînement a utilisé la résolution originale SDXL
Consistance de style : Peut nécessiter des tags de style spécifiques car l'entraînement s'est davantage concentré sur la préservation de l'identité que sur la cohérence du style
Licence
Ce modèle adopte la licence CreativeML Open RAIL++-M originale de Stability AI sans aucune modification ni restriction supplémentaire. Les termes de la licence restent exactement ceux spécifiés dans la licence SDXL originale, qui inclut :
✅ Permis : usage commercial, modifications, distributions, usage privé
❌ Interdit : activités illégales, génération de contenu nuisible, discrimination, exploitation
⚠️ Exigences : inclure la copie de la licence, indiquer les changements, préserver les avis
📝 Garantie : fournie "TELLE QUELLE" sans garanties
Veuillez consulter la licence SDXL originale pour les termes et conditions complets et officiels.

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.
Collection de modèles - Animagine XL 4.0
Images par Animagine XL 4.0 - v4 Opt
Images avec anime










Images avec modèle de base

Images avec sdxl


