Anime Illust Diffusion XL - v0.61
Mots-clés et tags associés
Images en vedette







Prompts recommandés
Trigger word (by xxx),a girl named frieren from sousou no frieren series,best quality,beautiful color,detailed,aesthetic,impasto style,cowboy shot,fantasy theme,gradient background,sitting on ground,expressionless,white hair,twintails,green eyes,parted lip,white dress,frills,a cat,grass,sunshine
best quality, 1girl, solo, looking at viewer, bangs
Prompts négatifs recommandés
(worst quality:1.3),low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxlv05_neg
Paramètres recommandés
samplers
steps
cfg
resolution
vae
Paramètres haute résolution recommandés
denoising strength
Conseils
Réduisez le poids des mots déclencheurs de style artiste, par ex., (by xxx:0.6).
Le tri des tags du prompt aide le modèle à mieux comprendre la signification ; un ordre recommandé est fourni.
Utilisez 'affiner' (image2image ou inpainting) si les sorties text2image sont floues.
Pour la fusion des styles, contrôlez le poids et l'ordre des styles et ajoutez-les plutôt qu'insérez-les.
Les mots déclencheurs de personnages n’incluent généralement pas les vêtements ; ajoutez les tags de vêtements séparément.
Pour les versions 0.61 et inférieures, utilisez les embeddings texte négatifs spécialisés au modèle pour de meilleurs résultats.
Assurez-vous que la résolution totale soit proche de 1024x1024 et que les dimensions soient multiples de 32 pour une génération optimale.
Points forts de la version
Stylisation renforcée.
J'ai également ajouté un bruit supplémentaire pendant l'entraînement. Certains samplers n’atteignent pas le pas de temps zéro à la dernière étape, ce qui peut générer une image bruitée. Donc, Euler A ou Euler sampler peut être plus adapté à votre usage.
风格化更明显。
此外,训练中添加了额外噪声。部分采样器的最终时间步不会归零,可能导致生成图像带有噪声。因此,Euler A 或 Euler 采样器可能更适合您使用。
Sponsors du créateur
Si vous appréciez notre travail, soutenez-nous via Ko-fi : https://ko-fi.com/eugeai
Merci à la communauté @NieTa (nieta.art) pour la puissance de calcul, et à @KirinTea_Aki (profil Civitai) et @Chenkin (profil Civitai) pour leur soutien en données.
Introduction du modèle (partie en anglais)
I Contenu
Dans cette introduction, vous apprendrez :
Informations sur le modèle (voir Section II);
Instructions d’utilisation (voir Section III);
Paramètres d’entraînement (voir Section IV);
Liste des mots déclencheurs (voir Annexe Partie A)
II AIDXL
Anime Illustration Diffusion XL, ou AIDXL, est un modèle dédié à la génération d’illustrations anime stylisées. Il comprend plus de 800 styles d’illustration intégrés (avec des mises à jour régulières), déclenchés par des mots spécifiques (voir Annexe A).
Avantages :
Composition flexible plutôt que poses traditionnelles IA.
Détails habiles plutôt que chaos désordonné.
Connaissance approfondie des personnages anime.
III Guide utilisateur
1 Utilisation de base
1.1 Prompt
Mots déclencheurs : Ajoutez les mots déclencheurs fournis dans Annexe A pour styliser l’image. Des mots déclencheurs adaptés amélioreront considérablement la qualité ;
Il est recommandé de réduire le poids des mots déclencheurs de style artiste, par exemple (by xxx:0.6).
Tri sémantique : Trier vos tags ou phrases du prompt aidera le modèle à mieux comprendre votre intention.
Ordre recommandé des tags : Mot déclencheur (by xxx) -> personnage (une fille nommée frieren de la série sousou no frieren) -> race (elfe) -> composition (plan cowboy) -> style (impasto ) -> thème (fantasy) -> environnement principal (dans la forêt, en jour) -> arrière-plan (arrière-plan dégradé) -> action (assis par terre) -> expression (sans expression) -> caractéristiques principales (cheveux blancs) -> caractéristiques corporelles (queues jumelles, yeux verts, lèvre fendue) -> vêtement (robe blanche) -> accessoires vestimentaires (volants) -> autres objets (un chat) -> environnement secondaire (herbe, soleil) -> esthétique (couleur belle, détaillé, esthétique) -> qualité ((meilleure qualité:1.3))
Prompts négatifs : (pire qualité:1.3), faible qualité, basse résolution, désordonné, abstrait, laid, défiguré, mauvaise anatomie, ébauche, mains déformées, doigts fusionnés, signature, texte, vues multiples
1.2 Paramètres de génération
Résolution : Assurez-vous que le nombre total de pixels (=largeur * hauteur) soit d’environ 1024*1024 et que la largeur et la hauteur soient divisibles par 32, ce qui assure le meilleur résultat pour AIDXL. Par exemple, 832x1216 (2:3), 1216x832 (3:2), et 1024x1024 (1:1), etc.
Sampler et étapes : Utilisez le sampler "Euler Ancester", appelé Euler A dans webui. Environ ~28 étapes à une échelle CFG de 7 à 9.
'Affiner' : L’image générée depuis text2image est parfois floue, auquel cas vous devez l’‘affiner’ avec image2image ou inpainting, etc.
Pour un simple agrandissement, vous pouvez consulter : Agrandir en grandes tailles et ajouter des détails avec SD Upscale, c’est facile ! : r/StableDiffusion (reddit.com)
Autres composants : Pas besoin d'utiliser un modèle raffineur. Utilisez le VAE du modèle lui-même ou le
sdxl-vae.
Q : Comment reproduire la couverture du modèle ? Pourquoi ne puis-je pas reproduire la même image que la couverture avec les mêmes paramètres de génération ?
R : Parce que les paramètres de génération affichés sur la couverture ne sont PAS les paramètres text2image, mais les paramètres image2image (pour agrandir). L’image de base est principalement générée avec le sampler Euler Ancester et non le sampler DPM.
2 Utilisation spéciale
2.1 Styles généralisés
Depuis la version 0.7, AIDXL regroupe plusieurs styles similaires et introduit des mots déclencheurs de style généralisé. Ces mots déclencheurs représentent chacun une catégorie commune de style d’illustration animée. Notez que ces mots déclencheurs de style généraux ne correspondent pas forcément au sens artistique habituel du mot, mais sont des mots déclencheurs redéfinis.
2.2 Personnages
Depuis la version 0.7, AIDXL a amélioré l’entraînement des personnages. Certains mots déclencheurs de personnage peuvent déjà atteindre l’effet d’un Lora, et peuvent bien séparer le concept de personnage de ses propres vêtements.
La méthode pour déclencher un personnage est : {character} \({copyright}\). Par exemple, pour déclencher l’héroïne Lucy de l’animation "Cyberpunk: Edgerunners", utilisez lucy \(cyberpunk\) ; pour déclencher le personnage Gan Yu dans le jeu "Genshin Impact", utilisez ganyu \(genshin impact\). Ici, "lucy" et "ganyu" sont des noms de personnages, "\(cyberpunk\)" et "\(genshin impact\)" leurs origines, les parenthèses sont échappées par "\" pour éviter leur interprétation comme tags pondérés. Pour certains personnages, la partie copyright n’est pas nécessaire.
Depuis la version v0.8, une méthode plus simple existe : une {fille/garçon} nommée {personnage} de la série {copyright}.
Pour la liste des mots déclencheurs de personnages, voir : selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Certains mots déclencheurs supplémentaires non mentionnés ici peuvent aussi être inclus.
Certains personnages demandent une étape de déclenchement supplémentaire. Si un seul mot déclencheur ne suffit pas à reproduire totalement le personnage, ajoutez ses caractéristiques principales dans le prompt.
AIDXL supporte l’habillage des personnages. Les mots déclencheurs ne contiennent généralement pas les caractéristiques des vêtements du personnage. Pour ajouter les vêtements, ajoutez les tags correspondants dans le prompt. Par exemple, silver evening gown, plunging neckline pour la robe du personnage St. Louis (Luxurious Wheels) du jeu Azur Lane. De même, vous pouvez ajouter des tags de vêtements d’un personnage sur un autre.
2.3 Tags de qualité
Qualité et tags esthétiques sont officiellement entraînés. Les inclure dans le prompt affecte la qualité de l’image générée.
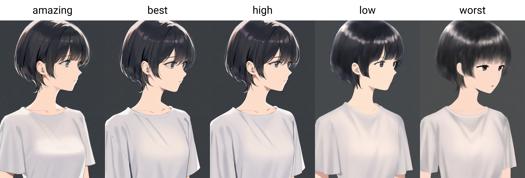
Depuis la version 0.7, AIDXL entraîne et introduit les tags de qualité. Ils sont divisés en six niveaux, du meilleur au pire : amazing quality, best quality, high quality, normal quality, low quality et worst quality.
Il est recommandé de majorer le poids de ces tags qualité, par exemple (amazing quality:1.5).
2.4 Tags esthétiques
Depuis la version 0.7, des tags esthétiques décrivent les caractéristiques esthétiques particulières des images.
2.5 Fusion de styles
Vous pouvez fusionner plusieurs styles dans votre style personnalisé. « Fusionner » signifie utiliser plusieurs mots déclencheurs de style simultanément. Par exemple, chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Quelques conseils :
Contrôlez le poids et l’ordre des styles pour ajuster le style final.
Ajoutez-les en fin de prompt plutôt qu’en début.
IV Stratégie et paramètres d’entraînement
AIDXLv0.1
Basé sur SDXL1.0, entraîné avec environ 22 000 images annotées sur environ 100 époques avec un scheduler cosinus et un taux d’apprentissage à 5e-6, nombre de cycles = 1, pour obtenir le modèle A. Puis avec un taux d’apprentissage de 2e-7 et les mêmes autres paramètres pour obtenir le modèle B. Le modèle AIDXLv0.1 est obtenu en fusionnant les modèles A et B.
AIDXLv0.51
Stratégie d’entraînement
Reprise de l’entraînement depuis AIDXLv0.5, trois phases d’entraînement sont enchaînées :
Entraînement avec légendes longues : en utilisant tout le dataset, certaines images sont annotées manuellement. Entraînement du U-Net et de l’encodeur texte avec l’optimiseur AdamW8bit, taux d’apprentissage élevé (~1.5e-6) avec scheduler cosinus. Arrêt quand le taux d’apprentissage descend sous un seuil (~5e-7).
Entraînement avec légendes courtes : reprise depuis la sortie de l’étape 1, mêmes paramètres et stratégie mais dataset avec légendes plus courtes.
Étape de raffinement : préparation d’un sous-ensemble choisi manuellement d’images de haute qualité du dataset de l’étape 1. Reprise de l’entraînement depuis la sortie de l’étape 2, taux d’apprentissage bas (~7.5e-7) avec scheduler cosinus à redémarrages 5-10 tours. Entraînement jusqu’à obtention d’un bon résultat esthétique.
Paramètres fixes d’entraînement
Pas de bruit additionnel comme un offset de bruit.
Min snr gamma = 5 : accélère l’entraînement.
Précision complète bf16.
AdamW8bit : équilibre entre efficacité et performance.
Dataset
Résolution : 1024x1024 (hauteur x largeur) avec stratégie de bucket modifiée officielle SDXL.
Légendage : généré par le modèle WD14-Swinv2 avec seuil 0.35.
Recadrage gros plan : découpage des images en plusieurs gros plans. Très utile pour de grandes ou rares images.
Mots déclencheurs : première étiquette des images conservée comme mot déclencheur.
AIDXLv0.6
Stratégie d’entraînement
Reprise de l’entraînement depuis AIDXLv0.52, avec une stratégie adaptative de répétition – Pour chaque image annotée du dataset, augmentez son nombre de répétitions d’entraînement selon ces règles :
Règle 1 : Plus la qualité de l’image est élevée, plus son nombre de répétitions est grand ;
Règle 2 : Si l’image appartient à une classe de style :
Si la classe est non entraînée ou sous-entraînée, augmentez manuellement ou automatiquement ses répétitions pour atteindre un nombre préréglé (~100).
Si la classe est entraînée ou suroptimisée, réduisez manuellement ses répétitions à 1 et supprimez si la qualité est faible.
Règle 3 : Limitez le nombre maximal de répétitions à un seuil (~10).
Cette stratégie a les avantages suivants :
Protège l’information originale du modèle face au nouvel entraînement, semblable à une image régularisée ;
Rend l’impact des données d’entraînement plus contrôlable ;
Équilibre l’entraînement entre classes en motivant les non entraînées et empêchant le surentraînement des déjà entraînées ;
Économise considérablement les ressources de calcul, facilite l’ajout de nouveaux styles au modèle.
Paramètres fixes
Identiques à AIDXLv0.51.
Dataset
Basé sur AIDXLv0.51 avec optimisations supplémentaires :
Tri sémantique des légendes : trie des tags par ordre sémantique, ex. "gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun".
Déduplication des légendes : suppression des tags dupliqués, en gardant celui qui retient le plus d’information. Les duplications correspondent à des tags proches comme "long hair" et "very long hair".
Tags supplémentaires : ajout manuel de tags supplémentaires à toutes les images, ex. "high quality", "impasto", etc. Ceci peut être fait rapidement avec certains outils.
V Remerciements spéciaux
Soutien en puissance de calcul : Merci à la communauté @NieTa (捏Ta (nieta.art)) pour leur support en puissance de calcul ;
Support des données : Merci à @KirinTea_Aki (Profil KirinTea_Aki | Civitai) et @Chenkin (Profil Chenkin | Civitai) pour leur fourniture massive de données ;
La version 0.7 n’aurait pas existé sans eux.
VI AIDXL vs AID
08/08/2023. AIDXL est entraîné sur le même dataset que AIDv2.10, mais le dépasse en performances. AIDXL est plus intelligent et peut faire beaucoup de choses que les modèles basés sur SD1.5 ne peuvent pas. Il fait aussi un excellent travail pour distinguer les concepts, apprendre les détails d’image, gérer des compositions difficiles voire impossibles pour SD1.5 et AID. Globalement, il a un potentiel absolu. Je continuerai à mettre à jour AIDXL.
VII Sponsoring
Si vous appréciez notre travail, vous êtes invités à nous soutenir via Ko-fi (https://ko-fi.com/eugeai) pour encourager notre recherche et développement. Merci de votre soutien~
Présentation du modèle (partie en chinois)
I Table des matières
Dans cette introduction, vous apprendrez :
Présentation du modèle (voir partie II) ;
Guide d’utilisation (voir partie III) ;
Paramètres d’entraînement (voir partie IV) ;
Liste des mots déclencheurs (voir annexe A)
II Présentation du modèle
Anime Illust Diffusion XL, ou AIDXL, est un modèle spécialisé dans la génération d’illustrations deux dimensions. Il comprend plus de 800 styles d’illustration intégrés (qui augmentent avec les mises à jour) et est activé par des mots déclencheurs spécifiques (voir annexe A).
Avantages : composition audacieuse sans effet figé, sujet mis en avant, peu de détails encombrants, reconnaissance étendue des personnages anime (activé par le nom en phonétique japonaise du personnage, par exemple, “ayanami rei” pour “绫波丽”, “kamado nezuko” pour “祢豆子”).
III Guide d’utilisation (en évolution)
1 Utilisation basique
1.1 Écriture du prompt
Utilisation des mots déclencheurs : utilisez les mots de l’annexe A pour styliser l’image. Les mots appropriés amélioreront grandement la qualité générée ;
Étiquetage du prompt : décrivez l’objet à générer à l’aide de tags ;
Ordre des tags dans le prompt : l’ordre des mots déclencheurs aide le modèle à comprendre ; ordre recommandé :
Mots déclencheurs (by xxx) -> personnage principal (1girl) ->personnage (frieren) -> race (elfe) ->composition (cowboy shot) -> style (impasto) -> thème (fantasy) -> environnement principal (forêt, jour) ->arrière-plan (dégradé) -> action (assis) -> expression (sans expression) ->caractéristiques principales (cheveux blancs) ->caractéristiques corporelles (queuedejumeaux, yeux verts, lèvre fendue) ->habits (robe blanche) -> accessoires d’habillement (volants) -> autres objets (baguette magique) -> environnement secondaire (herbe, soleil) ->esthétique (belle couleur, détaillé, esthétique) ->qualité (meilleure qualité)
Prompts négatifs : pire qualité, faible qualité, basse résolution, désordonné, abstrait, laid, défiguré, mauvaise anatomie, mains déformées, doigts fusionnés, signature, texte, vues multiples
1.2 Paramètres de génération
Résolution : assurez-vous que la résolution totale (hauteur x largeur) est autour de 1024*1024 et que largeur et hauteur sont multiples de 32. Par exemple, 832x1216 (3:2), 1216x832 (3:2), 1024x1024 (1:1).
Ne pas utiliser « Clip Skip », donc Clip Skip = 1.
Sampler et étapes : utilisez le sampler “euler_ancester” appelé Euler A dans webui. Sous 7 CFG Scale, 28 étapes.
Utilisez uniquement le modèle lui-même, sans affiner (Refiner).
Utilisez le VAE de base ou sdxl-vae.
2 Utilisation spéciale
2.1 Stylisation généralisée
La version 0.7 résume plusieurs styles similaires, avec des mots déclencheurs généraux représentant des catégories communes d’illustrations animées.
Notez que ces mots de style généraux ne correspondent pas forcément à leur sens artistique, mais sont des mots re-définis.
2.2 Personnages
La version 0.7 a amélioré l’entraînement des personnages. Certains mots déclencheurs atteignent déjà un effet Lora et séparent bien le personnage de ses vêtements.
Déclenchement avec NomPersonnage \(Œuvre\), par ex. l’héroïne Lucy de "Cyberpunk: Edgerunners" est lucy \(cyberpunk\); Gan Yu de "Genshin Impact" est ganyu \(genshin impact\). Le nom et l’origine sont entre parenthèses échappées pour éviter la pondération. Parfois, l’origine n’est pas obligatoire.
Voir selected_tags.csv · SmilingWolf. Certains mots non listés peuvent compiler.
Si un seul mot ne reproduit pas bien le personnage, ajoutez ses caractéristiques dans le prompt.
Les mots déclencheurs ne couvrent généralement pas les vêtements. Ajoutez-les séparément, ex. silver evening gown, plunging neckline pour le costume de St. Louis dans Azur Lane. De même pour d’autres personnages.
2.3 Tags de qualité
Depuis la version 0.7, tags qualité et esthétique sont officiellement entraînés. Leur présence dans le prompt affecte la qualité de l’image générée.
Les six niveaux de qualité sont : amazing quality, best quality, high quality, normal quality, low quality et worst quality.
2.4 Tags esthétiques
Introduits en version 0.7, ils décrivent des caractéristiques esthétiques spéciales.
2.5 Fusion des styles
Vous pouvez combiner plusieurs styles dans un style personnalisé en plaçant plusieurs mots déclencheurs ensemble. Par exemple : chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Conseils :
Contrôler le poids et l’ordre pour ajuster le style final.
Ajouter les mots à la fin du prompt, ne pas les placer au début.
3 Notes importantes
Utiliser des modèles VAE, embeddings texte et Lora supportés par SDXL. Note : sd-vae-ft-mse-original n’est pas un VAE supporté par SDXL ; EasyNegative, badhandv4 etc. négatifs embeddings aussi non supportés.
Pour les versions ≤ 0.61 : il est fortement recommandé d’utiliser les embeddings texte négatifs spécialisés pour le modèle (disponibles dans la section Suggested Resources), car ils ont un effet presque uniquement positif sur le modèle ;
Les mots déclencheurs ajoutés à chaque version sont parfois moins efficaces ou instables dans la version actuelle.
IV Paramètres d’entraînement
Basé sur SDXL1.0, avec environ 20 000 images annotées, environ 100 époques avec scheduler cosinus et taux d’apprentissage 5e-6, nombre de cycles 1 pour obtenir modèle A. Ensuite, taux d’apprentissage 2e-7 avec même autres paramètres pour modèle B. Fusion des modèles A et B pour obtenir AIDXLv0.1.
Pour d’autres paramètres, voir la version anglaise.
V Remerciements spéciaux
Soutien de la puissance de calcul : Merci à la communauté @捏Ta (捏Ta (nieta.art)) pour leur support ;
Soutien des données : Merci à @秋麒麟热茶 (Profil KirinTea_Aki | Civitai) et @风吟 (Profil Chenkin | Civitai) pour l’importante quantité de données fournies ;
La version 0.7 n’existerait pas sans eux.
VI Journal des modifications
08/08/2023 : AIDXL utilise le même dataset que AIDv2.10 mais surpasse ce dernier. AIDXL est plus intelligent, peut faire beaucoup de choses que SD1.5 ne peut pas. Il distingue bien les concepts, apprend les détails d’image, gère des compositions difficiles voire impossibles pour SD1.5 et AID anciens. Globalement, un potentiel supérieur à SD1.5, mise à jour continue prévue.
27/01/2024 : la version 0.7 ajoute beaucoup de contenu, doublant la taille du dataset par rapport à la version précédente.
Pour obtenir des annotations satisfaisantes, nombreuses nouvelles méthodes d’étiquetage testées (tri, randomisation hiérarchique, séparation des caractéristiques des personnages, etc.). Projet : Eugeoter/sd-dataset-manager (github.com) ;
Pour un entraînement contrôlé et conforme aux désirs, développement d’un script spécial basé sur Kohya-ss ;
Algorithmes heuristiques développés pour gérer les fusions des modèles des générations différentes ; pour plus de stylisation, abandonné la fusion par encodeur texte et couches OUT de UNET pour préserver le style.
Création de modèles détecteurs de watermark, classification d’images et notation esthétique pour filtrer les données.
VII Soutenez-nous
Si vous aimez notre travail, soutenez-nous via Ko-fi (https://ko-fi.com/eugeai) pour appuyer notre recherche et développement, merci !
Annexe / Appendice
A. Liste des mots déclencheurs spéciaux / 特殊触发词列表
Mots déclencheurs de style artistique : Cliquez ici
Mots déclencheurs de style de peinture : flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color : Couleurs plates, utilisant des lignes pour décrire lumière et ombre
平涂 :Couleurs plates, utilisant lignes et aplats pour lumière et couches
clean color : Style entre flat color et flat-pasto. Coloration simple et propre.
色彩简洁的平涂,介于 flat color 和 flat-pasto 之间
celluloid : Coloration anime
平涂赛璐璐 :Coloration anime
flat-pasto : Couleur presque plate, utilisant dégradés pour lumière et ombre
接近平面的色彩,使用渐变描述光影和层次
thin-pasto : Contour fin, utilisant dégradés et épaisseur de peinture pour lumière, ombre et couches
细轮廓勾线,使用渐变和颜料厚度描述光影和层次
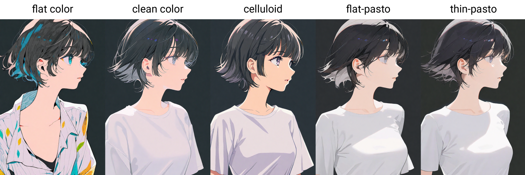
pseudo-impasto : Utilisation de dégradés et épaisseur pour lumière, ombre et couches
伪厚涂 / 半厚涂 :利用渐变和颜料厚度表现光影和层次
impasto : Utilisation de l’épaisseur de peinture pour lumière, ombre et dégradé
厚涂 :利用颜料厚度表现光影和层次
realistic
写实
photorealistic : Redéfini en style proche du réel
相片写实主义 :重定义为接近真实世界的风格
cel shading : Style modélisation 3D anime
卡通渲染 :动漫三维建模风格
3d

Mots déclencheurs esthétiques :
beautiful
美丽
aesthetic : sens artistique légèrement abstrait
唯美 :稍微抽象的艺术感
detailed
细致
beautiful color : usage subtil de la couleur
协调的色彩 :精妙的用色
lowres
messy : composition ou détails désordonnés
杂乱 :杂乱的构图或细节
Mots déclencheurs de qualité : amazing quality, best quality, high quality, low quality, worst quality




Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Mots entraînés
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.
Collection de modèles - Anime Illust Diffusion XL


Images par Anime Illust Diffusion XL - v0.61
Images avec anime







Images avec modèle de base

Images avec couleur plate










Images avec illustration







