Colossus Project Flux - v12_int4_SVDQ_nunchaku
Mots-clés et tags associés
Images en vedette



Prompts négatifs recommandés
blurry
Paramètres recommandés
samplers
steps
cfg
resolution
Conseils
Utilisez le mot négatif 'flou' pour améliorer la clarté de l'image.
Pour les versions FP4/int4 : FP4 est uniquement pour les GPUs Nvidia 50xx, int4 fonctionne avec 40xx et en dessous (minimum GPU série 20xx).
Utilisez l'échantillonneur Euler avec le scheduler Simple pour V2.0 pour de meilleurs résultats.
Essayez 20-30 étapes avec environ 2.2 cfg pour des résultats stables et de qualité.
Les versions 'Tout-en-un' contiennent Clip_L, T5xxl fp8 et VAE intégrés pour une utilisation plus facile.
La quantification SVDQ réduit la taille du modèle et accélère la génération avec une perte minimale de qualité.
Points forts de la version
ATTENTION ! Il existe deux versions FP4 et int4. La version int4 fonctionne avec les cartes 40xx et inférieures. PAS avec les cartes 50xx !
Merci à Muyang Li de Nunchakutech qui a réalisé la quantification de V12. https://huggingface.co/nunchaku-tech et leurs incroyables nunchaku !
Cette version est vraiment stupéfiante. Elle combine qualité et rapidité comme jamais vu auparavant.
Vous pouvez aussi télécharger directement les deux versions ici : https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
GUIDE D'INSTALLATION et WORKFLOW
Voici un guide rapide d'installation et un workflow en cours.
https://civitai.com/articles/17313
Je travaille encore sur mes nouveaux workflows pour Nunchaku... donc le workflow suivant est encore très WIP (travail en cours). Je publierai un article détaillé ce week-end.
Sponsors du créateur
Si vous souhaitez soutenir le créateur des modèles FLUX, vous pouvez faire un don ici : https://ko-fi.com/afroman4peace
Découvrez les versions FP4/int4 converties par Muyang Li de Nunchakutech : https://huggingface.co/nunchaku-tech
Visitez les guides détaillés workflow et l’aide à l’installation sur CivitAI : https://civitai.com/articles/17313, https://civitai.com/articles/17358
Au fond d'une montagne repose un géant endormi, capable soit d'aider l'humanité soit de créer la destruction...
Un Colossus se lève...
Après ma série SDXL, il est temps pour la série FLUX de ce projet... Cette fois, j'ai entraîné ce modèle de zéro. Pour l'entraînement, j'ai utilisé mes propres images, que j'ai créées avec mon modèle schnell Flux DemonFlux/Colossus Project schnell + mon SDXL Colossus Project 12 comme affinateur.
Ce Flux-Checkpoint SD est capable de produire presque tout... Colossus excelle dans la création d'images extrêmement réalistes, d'anime et artistiques.
Si vous l'appréciez, n'hésitez pas à me donner vos retours. Si vous souhaitez me soutenir, vous pouvez le faire ici. J'ai investi une somme importante pour construire un ordinateur capable d'entraîner réellement des modèles Flux... L'entraînement et les tests demandent aussi beaucoup de temps et d'électricité...
https://ko-fi.com/afroman4peace
Version V12 "Hephaistos"
Publier ce checkpoint me rend heureux et triste à la fois... V12 sera le dernier checkpoint de cette série... La raison principale est la future législation européenne sur l'IA... Une autre raison est la licence de Flux .1 DEV lui-même. Merci à tous pour le soutien ! J'ai consacré beaucoup de temps à ce projet durant l'année écoulée. Il est maintenant temps de passer à un autre projet.
Quoi qu'il en soit... je terminerai cette série en beauté...
V12 est basé sur V10B "BOB" mais intègre essentiellement les meilleures parties de cette série regroupées en un seul checkpoint. (C'est le résultat d'une nouvelle méthode de fusion qui a pris environ 1h30 et utilisé toute ma RAM de 128 Go). J'ai aussi amélioré les textures du visage et de la peau par rapport à V10. Les yeux sont beaucoup plus réalistes et plus "vivants" qu'auparavant.
Testez-le vous-même et donnez-moi votre avis sur V12. « Merci » à ma connexion Internet lente, je vais d'abord télécharger le FP8_UNET, puis la version FP8 "tout-en-un", puis FP16_unet et FP16_BEHEMOTH. J'essaierai aussi de le convertir en int4 et fp4 (souhaitez-moi bonne chance).
Comme toujours, donnez-moi vos retours sur V12...
Version V12 "Behemoth" (AIO)
Ce modèle "tout-en-un" est le meilleur de ma série V12... et bien sûr le plus volumineux :-)
Le Behemoth contient un T5xxl personnalisé et Clip_l intégrés dans le modèle. Si vous privilégiez la qualité à la quantité, c’est le checkpoint qu’il vous faut !
Version V12 FP4/int4
Merci à Muyang Li de Nunchakutech qui a réalisé la quantification de V12. https://huggingface.co/nunchaku-tech et leurs incroyables nunchaku !
Cette version est vraiment stupéfiante. Elle combine qualité et rapidité comme jamais vu auparavant.
ATTENTION !
Il y a deux versions : FP4 et int4. FP4 est uniquement pour les cartes graphiques Nvidia 50xx ! Tandis que int4 fonctionne avec les 40xx et en dessous (vous avez besoin d'au moins une carte graphique série 20xx).
Vous pouvez aussi télécharger directement les deux versions ici : https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
GUIDE D'INSTALLATION et WORKFLOW
Voici un guide rapide d'installation et un workflow en cours.
https://civitai.com/articles/17313
Je travaille encore sur mes nouveaux workflows pour Nunchaku... donc le workflow suivant est encore très WIP (travail en cours). Je publierai un article détaillé ce week-end.
Version V12 FP16_B_variant
Par une petite erreur faite tard dans la nuit (2h du matin), j’ai renommé et uploadé le « mauvais » checkpoint. C’est un checkpoint très expérimental, jamais destiné à être publié. Il n’a pas beaucoup été testé mais a très bien performé lors de la création de la vitrine. Il est peut-être meilleur que la version standard.
Il tend à privilégier davantage les visages asiatiques... C’est parce que je voulais tester quelque chose à intégrer dans un projet annexe sur lequel je travaille encore. Dites-moi vos retours avec ce checkpoint :-)
Version V12 AIO FP8
Cette version est une version « tout-en-un » de V12. Cela signifie que tous les clips sont intégrés. Elle donnera la même sortie que le FP8_unet avec mon clip_l personnalisé.
Version V12 GGUF Q5_1
Cette version était une demande. La qualité n'est pas mauvaise...
Version V10B "BOB"
Il s’agit d’une version alternative de V10. Je l'ai créée pour améliorer la version FP8 de V10. En général, la version FP8 est plus précise et les couleurs sont meilleures. Malheureusement, je n'ai pas eu beaucoup de temps récemment... (la vie réelle passe avant). C’est pour cela que cela a pris autant de temps... Dites-moi si vous préférez cette version. J’ai aussi une version FP16 de « BOB ». Selon les retours, je considérerai aussi de publier une version int4.
WORKFLOW :
Voici le workflow pour V12 et V10 : https://civitai.com/articles/17163
Version V10_int4_SVDQ "Nunchaku"
Je tiens d'abord à remercier theunlikely https://huggingface.co/theunlikely qui a converti le FP16_Unet en int4_SVDQ. Allez visiter sa page et laissez un like.
Cette version est à peu près équivalente à la version FP8. Même en mode normal dans mon workflow, elle est environ 2 à 3 fois plus rapide que le modèle régulier... Avec le "mode rapide" du workflow, je peux générer une image 2MP en environ 19 secondes avec ma 3090ti.
Qu’est-ce que SVDQ "Nunchaku" ?
Cette nouvelle méthode de quantification permet de réduire les modèles Flux (ici un modèle FP16 natif) de 24 Go à environ 6,7 Go. Mais ce n’est pas tout : vous pouvez générer plus rapidement que jamais sans trop perdre en qualité. Bien sûr, vous noterez une légère différence comparée à mon 32GB_Behemoth, mais pour celui-ci, vous auriez besoin de beaucoup plus de VRAM/RAM pour même le faire fonctionner.
Pour plus d’infos, visitez : https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
Installation : veuillez visiter mon guide d’installation/workflow : https://civitai.com/articles/15610
Version V10 "Behemoth" (FP16_AIO)
Cette version est encore expérimentale. L’objectif principal était d’obtenir des résultats plus réalistes. J’ai aussi réussi à réduire certaines "lignes Flux". Ce modèle est basé sur Colossus Project V5.0_Behemoth, V9.0 et un autre projet que j’appelle « Ouroborus Project »
La version FP16 est très stable. Je sortirai bientôt une version FP8. Cette version est aussi très bonne mais moins stable.
Je vous laisse l’expérimenter. Dites-moi ce que vous en pensez.
Amusez-vous à créer :-)
Version V9.0 :
Je dois beaucoup expliquer... Pourquoi est-ce déjà V9.0 ?
J’ai récemment déménagé dans un nouvel appartement et à cause d’erreurs du fournisseur Internet, je n’avais pas de connexion internet fonctionnelle... Pendant le déménagement, j’ai laissé mon ordinateur tourner. Résultat, j’ai créé beaucoup de checkpoints (majoritairement corrompus). J’ai toutefois quelques très bonnes versions V8 que je publierai peut-être...
Qu’est-ce qui a changé ?
J’ai entraîné de nouveaux visages et textures de peau en prenant essentiellement les meilleurs résultats de V5.0. Le modèle a aussi été entraîné sur les pieds/jambes pour une meilleure anatomie. Les versions V5.0 coupaient parfois la tête et les pieds... Je crois avoir corrigé certains de ces problèmes...
En plus, je l’ai entraîné avec plus de mes propres images de paysages... Et oui, j’ai fait tout ça pendant le déménagement... Le temps total d’entraînement est d’environ 2 semaines de calcul, ce n’est pas donné (chaque heure me coûte environ 0,25€ en électricité).
J’espère que cette version vous plaira... Si vous voulez me soutenir, postez de belles images ou même un pourboire sur Buzz ou Ko-fi...
Dites-moi ce que vous en pensez :-)
Version 5.0 :
V5.0 est basée sur V4.2 et V4.4 (qui sera bientôt aussi publiée). Elle a reçu un entraînement supplémentaire sur les détails de la peau et l'anatomie en général, ce qui corrige surtout les mains et les tétons. Les détails du visage sont bien meilleurs. J'ai aussi essayé de corriger certaines petites lignes de flux...
En général, cette version est plus réaliste que V4.2 et meilleure sur les petits détails. Comme V4.2, cette version est aussi un modèle hybride dédistillé. Vous pouvez l’utiliser avec des réglages similaires à V4.2.
Voici aussi un nouveau Workflow pour expérimenter : https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
Dites-moi ce que vous pensez de cette version par rapport à 4.2 ou V2.1...
Version 4.4 "Research" :
J’ai ajouté cette version pour compléter... Elle est un peu plus réaliste que V4.2 et sert de base pour la version 5.0. Vous pouvez l’essayer si vous voulez. Vous pouvez aussi utiliser le workflow de V5.0 et V4.2.
Version 4.2 :
Cette version est en gros un développement supplémentaire de Demoncore Flux et Colossus Project Flux. L’objectif était d’obtenir un rendu plus stable avec de meilleures textures de peau, de meilleures mains et une plus grande variété de visages. Je l'ai entraînée sur un modèle hybride partiellement Demoncore Flux. J’ai aussi amélioré les tétons et le NSFW un peu. Dites-moi si vous préférez V4.2 à la version 2.1 :-)
Pour les images de démonstration : je n’ai utilisé que des images natives en résolution SDXL ou 2MP (par exemple 1216x1632). Ce modèle peut gérer des résolutions encore plus élevées. J’ai testé ce checkpoint jusqu’à 2500x2500, mais je recommande plutôt autour de 2000x2000.
Pour les réglages, je recommande environ 30 steps et 2-2,5 cfg. J’utilise surtout 2.2 ou 2.3 dans mon workflow. Pour les démonstrations, j’ai utilisé DPM++ 2M avec Simple scheduler.
Je publierai plus de versions bientôt, mais je n’ai pas beaucoup de temps avant Noël...
Paramètres
Je vais bientôt ajouter un workflow Comfy dédié. Vous pouvez toujours télécharger et ouvrir les images de démonstration pour l’instant...
La version "tout-en-un" fonctionne aussi bien avec Forge...
En gros, ça fonctionne avec les mêmes réglages que la version 2.1 (voir ci-dessous).
Utilisez 20-30 steps avec environ 2.2 cfg...
Version 2.1_de-distilled_experimental (MERGE)
Cette version est complètement différente et fonctionne différemment d’un modèle Flux normal !
C’est une fusion expérimentale entre ma version 2.0 et une version dédistillée https://huggingface.co/nyanko7/flux-dev-de-distill. Cela s’est produit un peu par accident, mais les résultats sont impressionnants. Vous obtenez des détails incroyables. Le modèle suit aussi très bien les prompts... La prochaine étape sera d’entraîner directement sur le modèle dédistillé. J’ai déjà fait des tests de Loras avec. C’est très expérimental, donc signalez-moi les erreurs non listées ci-dessous. Si vous avez de bonnes images, postez-les... ainsi que les mauvaises, cela aide à améliorer :-). Essayez aussi la version 2.0 et dites-moi quel type de checkpoint vous préférez.
!Attention!
Le workflow Flux normal ne fonctionne pas avec cette version. VOUS DEVEZ télécharger mon workflow dédié !
Vous pouvez aussi essayer de trouver votre méthode, mais merci de ne pas me tenir responsable des mauvaises images. C’est aussi un modèle très expérimental... voir les inconvénients ci-dessous...
Avantages et inconvénients de ce checkpoint :
Ce checkpoint peut créer des détails extrêmes... Cela a un coût... Il est lent comparé aux checkpoints Flux normaux. L’avantage est que vous n’avez souvent plus besoin d’upscale additionnel. Au lieu d’utiliser le Flux Guidance, ce modèle utilise l’échelle cfg, ce qui signifie aussi que ce ne sera pas compatible avec les workflows standards.
Vous pouvez utiliser des prompts négatifs ! Cela aide à retirer les éléments indésirables de l’image.
Parfois, des artefacts peuvent apparaître... Vous pouvez résoudre cela par un léger upscale simple (je travaille dessus). Voici un exemple... cela arrive bizarrement pas avec toutes les graines... MISE À JOUR : Ce n’est pas un problème du modèle lui-même... c’est un problème de workflow. Je travaille à le corriger. Si cela arrive, essayez de régler le premier upscale à 1.14 au lieu de 1.2.

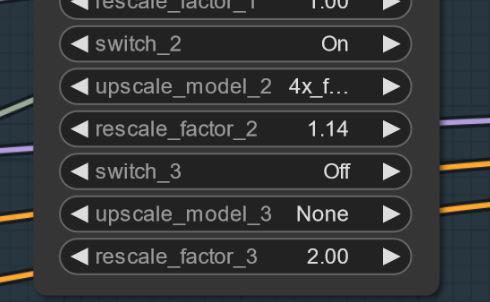
Paramètres et Workflow V2.1 :
Voici le workflow : https://civitai.com/articles/8419
Paramètres : contrairement au Flux normal, vous n’avez pas besoin de Flux Guidance scale. Utilisez le cfg à la place. J’utilise souvent 3 cfg pour le workflow. Certaines images peuvent nécessiter un cfg plus bas.
Le plus important est probablement de désactiver le flux guidance scale...
Sans workflow, je l’ai testé avec 30 étapes et 2-3 cfg. C’est peut-être aussi les réglages pour Forge. Essayez d’expérimenter.
Je recommande d’utiliser le mot "flou" (blurry) dans les négatifs.
Échantillonneur et scheduler :
Vous pouvez choisir parmi plusieurs échantillonneurs fonctionnels :
Euler, Heun, DPM++2M, DEIS, DDIM fonctionnent très bien.
J'ai surtout utilisé "simple" comme scheduler.
Si vous trouvez de meilleurs réglages, dites-le-moi... :-)
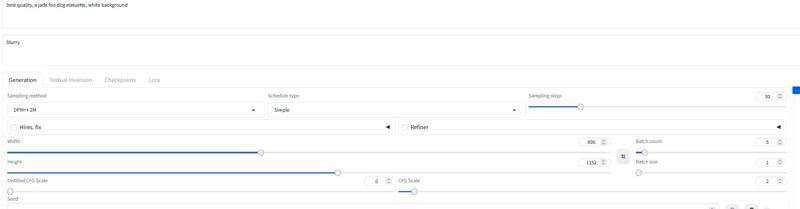
Pour Forge, je recommande d'utiliser le modèle AIO... voici un exemple de réglage pour Forge :
Version 2.0_dev_experimental
Eh bien... c’est une version expérimentale... L’objectif était de créer un modèle plus cohérent et plus rapide. J'ai intégré des loras que j'ai entraînés moi-même, puis fusionné les modèles résultants de façon spéciale (fusion Tensor). Un T5xxl personnalisé a été modifié avec "Attention Seeker". Pour gagner en vitesse et en qualité, j'ai fusionné le lora Hyper Flux de ByteDance. Cela a décalé la zone de travail... Voici l’image principale :
16 steps V 2.0
 30 steps V 1.0
30 steps V 1.0
 Inconvénients :
Inconvénients :
Premièrement, cette version est un peu plus volumineuse que la précédente... Deuxièmement, je dois encore créer la version Unet seule. Je mettrai à jour lorsqu'elle sera prête.
Paramètres et Workflow V2.0 :
Vous pouvez maintenant utiliser moins d’étapes... 16 étapes égalent 30 dans l’ancien modèle.
Je recommande toujours d’utiliser environ 20-30 étapes, car cela apporte généralement plus de qualité.
Échantillonneur : je préfère Euler avec Simple comme scheduler. Le guidance peut être réglé entre 1,5 et 3 (évidemment, testez hors de cette plage). La guidance à 1,8 fonctionne bien pour les images réalistes. DPM++2M et Heun fonctionnent aussi très bien.
Workflow 2.0 :
J’ai créé un nouveau workflow pour V2.0 et V1.0. Il intègre le nouveau générateur de prompts Flux. De plus, j’ai fait fonctionner la seconde étape de suréchantillonnage. https://civitai.com/articles/7946
Forge :
J’ai aussi testé ce modèle avec Forge et ça a très bien marché... Les images peuvent toutefois différer entre Comfy UI et Forge.
Version 1.0_dev_beta :
C’est mon premier modèle de la série. Merci de me donner des retours et de poster des images. Cela m’aide à améliorer le projet. Plusieurs versions sont disponibles. La meilleure qualité est la version FP16. Elle est très volumineuse et nécessite une carte graphique puissante et beaucoup de RAM. La version FP8 est un bon compromis qualité/performance. Si vous voulez une version GGUF, téléchargez la Q8_0. La version GGUF Q4_0/4.1 était une demande. Elles sont plus petites mais perdent un peu en qualité.
Il existe principalement deux types de modèles : les « tout-en-un » qui ne nécessitent qu’un seul fichier à télécharger. Ils intègrent Clip_l, T5xxl fp8 et VAE (voir plus bas). Placez-les dans votre dossier checkpoints.
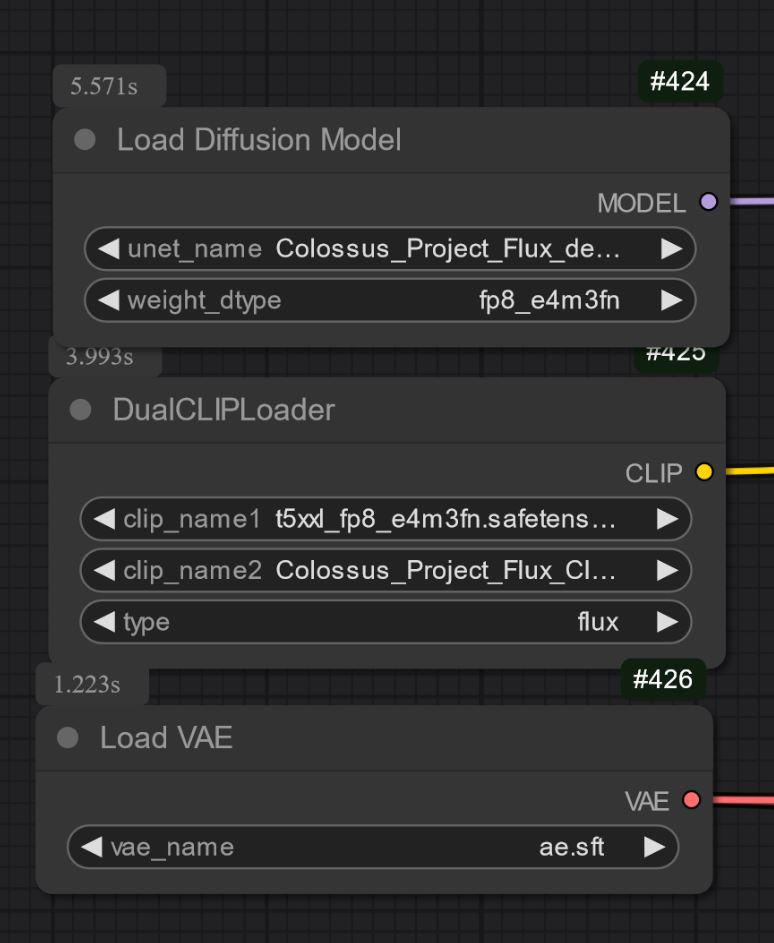
Les autres versions sont uniquement UNET. Vous devez charger tous les fichiers séparément.
Dans tous les cas, vous devez télécharger mon Clip_L pour que ça fonctionne correctement.
Il est aussi important de choisir le bon clip T5xxl. Pour la version FP8, c’est le clip fp8_e4m3fn t5xxl. Pour la FP16, c’est le clip FP16. Assurez-vous de sélectionner le type de poids par défaut. (ci-dessous, un exemple d’image pour la version fp8)
Pour la version GGUF, vous avez besoin du chargeur GGUF !
Quelques informations connues à propos de V1.0 :
C’est le premier modèle de la série, donc pour l’instant, il peut avoir du mal avec certains prompts ou styles comme l’art. La version suivante recevra plus d’entraînement. Dites-moi ce que le modèle ne sait pas faire...
Paramètres et Workflow :
Je l’ai testé avec environ 30 étapes, Euler avec Simple comme scheduler. Le guidance peut être réglé entre 1,5 et 3 (n’hésitez pas à tester hors de cette plage).
Le guidance de 1,8 fonctionne bien pour les images réalistes.
Amusez-vous avec ces réglages... Si vous obtenez de bons résultats, merci de les partager.
J’ai ajouté les images de présentation comme données d’entraînement... Le workflow pour Comfy se trouve dedans. Voici un lien pour le télécharger : https://civitai.com/articles/7946
Modèle "tout-en-un" :
Uniquement UNET :
 Vous devez aussi télécharger le clip_L. Il fait 240 Mo.
Vous devez aussi télécharger le clip_L. Il fait 240 Mo.
GGUF : J’ai ajouté le workflow GGUF ici : https://civitai.com/articles/7946
Important :
Le modèle dev n’est pas destiné à un usage commercial. Pour cela, je publierai le modèle "schnell" ailleurs. Il est plutôt destiné à un usage personnel ou scientifique.
LICENCE :
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
Crédits :
theunlikely https://huggingface.co/theunlikel (merci encore)
Version 2.1/V4.2/5.0 : Flux_dev_de-distill de nyanko7
https://huggingface.co/nyanko7/flux-dev-de-distill
Depuis V2.0 : Hyper Lora de ByteDance https://huggingface.co/ByteDance/Hyper-SD
Black Forrest pour leur incroyable modèle Flux https://huggingface.co/black-forest-labs

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.
Collection de modèles - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8
















































