NEW ERA (New Esthetic Retro Anime) - Retro_v7.0R(VAE)
Mots-clés et tags associés
Images en vedette


Prompts recommandés
masterpiece,best quality,newest,official art,absurdres,highres,retro artstyle,1990s (style),1980s (style),2000s (style),anime screenshot,anime coloring,photo background
1girl
Prompts négatifs recommandés
worst quality,low quality,(censored, bar censor, mosaic censoring, 4koma),multiple views,blurry,artistic error,bad anatomy,bad feet,wrong foot,bad hands,bad proportions,bad perspective,bad leg,bad arm,bad neck,bad vulva,bad reflection,bad ass,bad face,english text,chinese text,watermark,simple background
(worst quality, low quality, extra digits:1.4)
Paramètres recommandés
samplers
steps
cfg
resolution
Paramètres haute résolution recommandés
upscaler
upscale
denoising strength
Conseils
Utilisez la mise à l’échelle/upscale Latent (nearest-exact) pour réduire les artefacts et préserver l’anatomie surtout à haute résolution.
Appliquez le taux de dropout de légende et le dropout de réseau 0,05 pour augmenter la cohérence anatomique à des résolutions extrêmes.
Utilisez des tags détaillés booru du site danbooru dans les prompts pour améliorer les détails et réduire la simplification.
Le prompt négatif 'simple background' aide à réduire la simplification de l’image et améliore le détail pour les modèles v-pred.
Il n’est pas nécessaire d’utiliser RescaleCFG avec les versions actuelles du modèle — compatible avec ComfyUI, Forge, Reforge, et Automatic1111.
Installez l’extension sd-webui-tagcomplete pour l’autocomplétion des tags provenant de Danbooru afin d’aider à rédiger de meilleurs prompts.
Pour de meilleurs résultats, commencez les prompts par 'masterpiece, best quality'.
Points forts de la version
Une version expérimentale avec un fort accent sur le style rétro
Réduction de l’importance des prompts 1990s (style), 1980s \(style\), retro artstyle (Utilisez ces prompts uniquement si vous n’avez pas assez de rétro)
Les personnages des anciens animes sont devenus plus précis
Sponsors du créateur
Modèle combiné des années 90, 80 et maintenant 2000
J’ai restauré mon PATREON (ou plutôt créé un nouveau avec l’autorisation de Patreon), si quelqu’un souhaite soutenir, j’y ai posté tous mes nouveaux modèles et LORAs, qui étaient payants sur BOOSTY dans une archive unique. Je serai ravi si vous vous abonnez gratuitement à Patreon, cela me montrera que mon travail vous importe et que vous souhaitez voir des mises à jour.
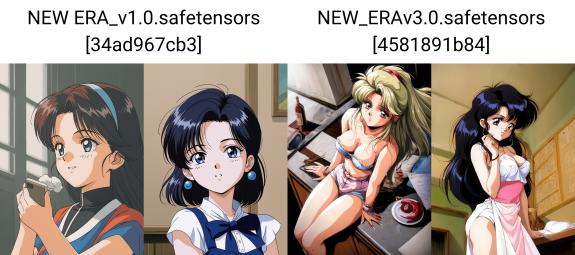
À propos de la version 5.0 :
Il a été décidé d’implémenter le modèle basé sur NAI-XL, un saut énorme en qualité comparé aux derniers LORA. Comme le modèle est facile à affiner, il bénéficie d’un meilleur détail de l’environnement, des yeux, d’une anatomie améliorée, des doigts, de la variété dans les vêtements, et surtout, d’une réduction du contraste, c’est-à-dire que si dans la version 3.0 le contraste était très élevé et qu’il était difficile d’utiliser un LORA supplémentaire, nécessitant une échelle cfg de 2.5, maintenant la même échelle cfg avec le même contraste est d’environ 4, ce qui donne une marge pour l’utilisation de LORA additionnels.
Lors de l’utilisation de la mise à l’échelle Latent (nearest-exact), il y a beaucoup moins d’artefacts (parfois ils sont absents), ce qui indique une amélioration significative de la qualité et de l’anatomie (la mise à l’échelle conserve beaucoup plus souvent l’anatomie dans des limites correctes).
workflow (copiez simplement les paramètres, tout sauf les prompts négatifs, le meilleur choix est indiqué ci-dessous) :
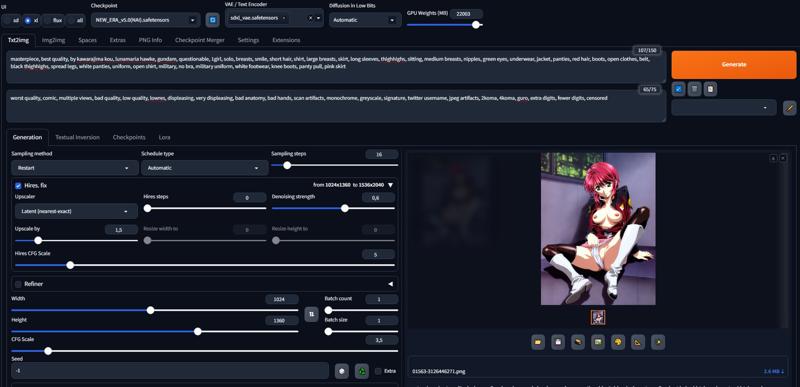 lien vers l’image
lien vers l’image
À propos de v6.3 & 6.69 :
Enfin, ça a pris un peu plus de temps car je refaisais le fine tuning et entraînais le lora pour améliorer ce modèle (et en plus tout mon webui a été cassé après la réinstallation de Python et j’ai dû tout réparer)
Je tiens à dire tout de suite que ce modèle n’est pas basé sur epsilon, mais sur v-pred. V-pred (prédiction de vitesse) et epsilon (prédiction ε) sont des approches mathématiques différentes pour paramétrer le bruit dans les modèles de diffusion. Sans entrer dans les détails, pour l’anime, avec les bons paramètres, vpred est meilleur. Mais il présente de gros problèmes avec la dégradation de l’image et une convergence légèrement moins bonne à un SNR nul (et vpred devrait être utilisé à 0 SNR). J’ai résolu les problèmes de fort contraste et perte de couleurs avec des réglages appropriés pour la paramétrisation v, désactivant complètement le SNR, ajustant automatiquement le bruit au lieu des valeurs fixes utilisées dans SDXL, etc. Ce ne fut pas facile, car il n’y a pas de données concrètes sur Internet, j’ai compris certaines subtilités grâce à des essais-erreurs et à une lecture attentive d’articles scientifiques sur v-pred. En fait, le NOOBAI original avec civitai est formé incorrectement, ce qui est assez drôle, vu le nombre de personnes ayant aidé à la configuration et à l’entraînement.
En fait, v-pred est très exigeant et imparfait, j’espère que le développement d’approches hybrides éliminera les limitations actuelles, mais nécessitera des changements fondamentaux dans l’architecture des modèles de diffusion.
Pour revenir aux modèles, pourquoi deux versions ? J’ai remarqué une légère dégradation du détail des visages et des yeux (pas énorme, mais tout de même important), donc j’ai décidé de créer la version 6.69, en entraînant initialement des lore spécialisés pour améliorer les visages et ajuster davantage l’anatomie, qui a déjà atteint un nouveau niveau. Mais la version 6.3 fonctionne visuellement mieux pour les ombres d’environ 5 % dans 70-75 % des cas, ce qui n’est pas significatif pour beaucoup, mais pour moi ça compte, donc je vous laisse choisir. La version 6.69 est meilleure en anatomie, la 6.3 est légèrement meilleure avec les ombres. (je posterai la 6.3 en premier)
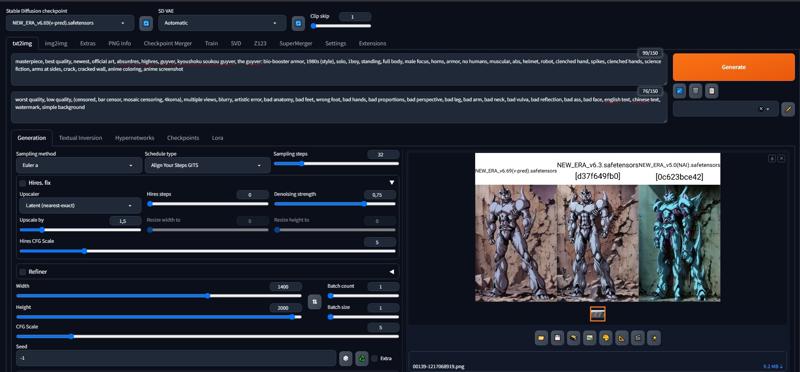
quelques comparaisons des versions et de la version 5.0 (toutes les œuvres sont réalisées sans upscaling à une résolution de 1024x1056) :




 comparaison des samplers :
comparaison des samplers :

Parlons maintenant de la gestion par ce modèle de la cohérence anatomique à des résolutions extrêmes, comparé aux modèles plus anciens. J’ai atteint cela en ajoutant Taux de dropout de légende et Dropout de réseau 0,05, ce qui a multiplié la cohérence plusieurs fois. Résolution 1400x2000 (malgré ces résultats, cette résolution est extrême et n’est pas recommandée, il vaut mieux utiliser l’upscale Latent (nearest-exact))



Mon workflow
 Prompts en tête : masterpiece, best quality, newest, official art, absurdres, highres
Prompts en tête : masterpiece, best quality, newest, official art, absurdres, highres
Prompts négatifs : worst quality, low quality, (censored, bar censor, mosaic censoring, 4koma), multiple views, blurry, artistic error, bad anatomy, bad feet, wrong foot, bad hands, bad proportions, bad perspective, bad leg, bad arm, bad neck, bad vulva, bad reflection, bad ass, bad face, english text, chinese text, watermark, simple background
Les prompts négatifs sont standards, utilisant tous les mauvais éléments anatomiques du site danbooru, sauf un - simple background, j’ai remarqué que les modèles vpred ont tendance à simplifier, ce prompt négatif aide et améliore le détail global.
RescaleCFG n’est plus nécessaire. Maintenant, vous pouvez travailler paisiblement avec comfi, forge, reforge et même le automatic1111 standard.
Souvenez-vous, les modèles vpred aiment beaucoup les descriptions détaillées, utilisez les tags booru du site danbooru, les prompts simples 1girls fonctionnent, mais l’image est simplifiée et standardisée autant que possible, ce qui est inévitable avec ces modèles. Les modèles epsilon sont plus variés à cet égard, mais perdent sur tout le reste (absolument tout).
Si ce n’est pas encore fait, installez l’extension "sd-webui-tagcomplete". Elle affiche les suggestions d’autocomplétion pour les tags reconnus depuis des boards "image booru" tels que Danbooru, principalement utilisés pour parcourir les illustrations de style anime.
CFG Scale - n’importe quelle valeur, plus de problème de contraste excessif. Vous pouvez définir 5-7 (valeurs standards)
Ah oui, j’ai presque oublié, j’ai ajouté pas mal d’images Full HD des animés studio ghibli des années 80 et 90 ainsi que des 2000, vous pouvez maintenant créer des œuvres dans le style de ce studio. Les images au format large ont commencé à avoir une anatomie bien meilleure.
Animés ajoutés :
hotaru no haka
tonari no totoro
sen to chihiro no kamikakushi
howl no ugoku shiro
tenkuu no shiro laputa
NEW_ERA_v7.1 (NAI V-PRED) ou PATREON (nouveau niveau d’art rétro, bien meilleur que les versions 6.3 et 6.69, plus stable, plus beau, plus facile à utiliser)
















NEW ERA 4.0 (ILLUSTRIOUS-XL) / SDXL / LORA




 NEW ERA v1.0 (version SDXL / PONY DIFFUSION combinant presque tous mes modèles populaires avec un accent sur l’anime rétro)
NEW ERA v1.0 (version SDXL / PONY DIFFUSION combinant presque tous mes modèles populaires avec un accent sur l’anime rétro)
P.P.S. nouveau modèle Anime Screencap / LORA / PONY DIFFUSION sur Boosty


J’ai réalisé une vidéo sur comment atteindre la même qualité ou juste reproduire mon art
prompts négatifs parfaits (j’ai juste utilisé tous les prompts négatifs de danbooru) :
Prompt négatif : worst quality, low quality, (censored, bar censor, mosaic censoring, 4koma), multiple views, blurry, artistic error, bad anatomy, bad feet, wrong foot, bad hands, bad proportions, bad perspective, bad leg, bad arm, bad neck, bad vulva, bad reflection, bad ass, bad face, english text, chinese text, watermark, simple background
retro artstyle - le principal token rétro, présent dans presque toutes les images entraînées et donnant des résultats différents dans les années 80-90
1990s \(style\) - un marqueur très fort qui change significativement le style du modèle
1980s \(style\) - a enfin un impact fort sur le résultat final
2000s \(style\) - bien meilleur qu’avant
anime screenshot, anime coloring - deux tokens forts, fonctionnent très bien, donnent l’apparence d’extraits d’anime, peuvent être utilisés ensemble pour améliorer ou séparément
photo background - rend l’environnement réaliste, en conservant les personnages en style anime (modifié pour ce modèle)
n’oubliez pas d’écrire au début des prompts : masterpiece, best quality
artistes :
par urushihara satoshi
par danmakuman
par kitazume hiroyuki
par kawarajima kou
par kotobuki tsukasa
par hirano toshihiro
nouveaux
par mikimoto haruhiko
par kajishima masaki
par saotome nanda
par hakumai gen
P.S. 7.9V (basé sur 1.5)
Utilisation du service de génération Civitai - la case est cochée, pour une raison quelconque ça ne fonctionne pas
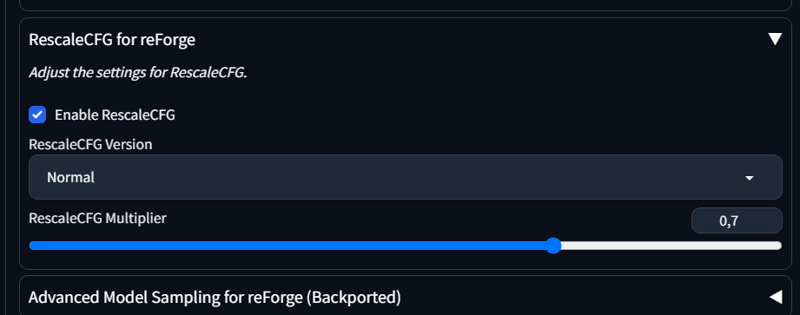
vous pouvez utiliser RescaleCFG avec reForge pour réduire le contraste
Merci de poster vos œuvres avec ou sans commentaires, cela m’aidera à m’améliorer. Merci !
Si mon travail vous plaît, cliquez sur le cœur ci-dessus, j’en serai ravi :3

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.















































