Old Consistency V32 Lora [FLUX1.D/PDXL] - Féminin v1.1 - e500 PDXL
Images en vedette


Prompts recommandés
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
Prompts négatifs recommandés
greyscale, monochrome, multiple views
Paramètres recommandés
samplers
steps
cfg
clip skip
resolution
vae
other models
Paramètres haute résolution recommandés
upscaler
upscale
denoising strength
Conseils
Utilisez plusieurs boucles pour améliorer la fidélité et la consistance des images.
Respectez une instruction standard et un ordre logique pour éviter les abominations.
Utilisez les tags de pose et d’angle de vue principaux comme 'from front', 'from side', 'from above' pour améliorer la précision des poses.
Évitez d’utiliser les poses sexuelles tant qu’elles ne sont pas bien affinées.
Expérimentez avec divers tags de traits pour cheveux, yeux, couleurs de vêtements et matériaux.
L’ordre de chargement influence les résultats lors de la fusion avec d’autres modèles et LoRAs.
Le mode sûr est activé par défaut avec des options pour débloquer le contenu douteux et explicite.
Utilisez le système de tags de pose et directives pour un meilleur contrôle sur la position des personnages et les angles de caméra.
Points forts de la version
Contrôles de stabilité ;
concept - images/images testées
corps entier - 48/48
cowboy shot - 48/48
portrait - 48/48
gros plan - 48/48
**************************************
La prochaine itération aura une sous-catégorie de pose unique pour les yeux induisant la couche, taguée avec les angles de pose, incluant plus d’images d’yeux par variation angulaire pour solidifier la brûlure. Les couleurs d’yeux directes ne seront probablement pas nécessaires, la forme semble cruciale selon mes recherches.
yeux rouges - 39/48
corps entier - 6/12
cowboy shot - 9/12
portrait - 12/12
gros plan - 12/12
yeux bleus - 48/48
toutes poses - 12/12
yeux verts - 48/48
toutes poses -12/12
yeux jaunes - 42/48
corps entier - 6/12 - raison instable inconnue.
yeux aqua - 48/48
toutes poses
yeux violets - 48/48
toutes poses
latex - 36/48
gros plan - 5/12
portrait - 7/12 - nécessite images portrait et gros plan
cowboy shot - 12/12
corps entier - 12/12
lingerie - 36/48
gros plan - 7/12
portrait - 4/12 ? pourquoi ? - nécessite images visage portrait et gros plan directs
cowboy shot - 11/12
corps entier - 12/12
casual - 48/48
toutes poses - 12/12
bikini - 48/48
toutes poses - 12/12
robe - 16/48
aucune pose ne correspondait à la robe correcte sauf avec tags supplémentaires -> besoin de taguer les robes plus précisément
La stabilité de sortie est bien meilleure que prévu avec plein de tags utiles déjà présents dans pony, incluant ;
<couleur> cheveux
<couleur> vêtements
taille de poitrine <taille>
<mature> féminin
<couleur> boucles d’oreilles
<couleur> yeux
<flou> objet
<zone> <arrière-plan>
Beaucoup de potentiels intéressants pour les tags, donc jouez avec comme moi.
Succès de superposition ;
yeux rouges -> yeux bleus;
[yeux rouges:0.5], [yeux bleus:0.5] -> chevauchement occasionnel de fusion, instable.
yeux rouges, yeux bleus -> chevauchement moins cohérent
yeux rouges ET yeux bleus -> chevauchement plus cohérent, besoin d’investigations
la majorité des yeux font face au même problème, le modèle superpose trop la couleur d’yeux sur la forme d’yeux, donc l’expérience de couche d’yeux sera stoppée pour être implémentée via méthode blot plutôt que cela.
robe -> latex
robe, fente latérale, robe de cocktail, latex, combinaison latex -> forme une tenue basée sur plusieurs couches. La cohérence est instable mais le résultat prometteur.
latex -> robe
latex, combinaison latex, robe, fente latérale -> forme un objet plus robe, qui semble superposer les zones de peau de la robe plus que si la robe était première. Cela suggère à mes yeux que l’entraînement robe est surajusté, donc il faut reconsidérer la robe.
latex -> bikini
latex, combinaison latex, bikini -> forme leggings latex mélangés avec bikini, indication de surapprentissage.
Je crois avoir une solution pour le chevauchement de superposition des vêtements, et avec cette solution vient le remède pour les yeux, la couleur de peau, et plus. La majeure partie de la cohérence devrait venir du blotting.
Sponsors du créateur
Découvrez le modèle Illustrious pour des capacités complémentaires.
Utilisez le workflow ComfyUI pour une meilleure génération d’image et expérimentez avec les boucles.
Explorez le puissant modèle Flux comme base IA.
Soutenez NovelAI pour une synergie supérieure en génération d’histoire et d’image.
Crédits à Black Forest Labs pour la conception du modèle Flux.
Améliorez votre workflow de balisage avec TagGUI.
Configuration d’entraînement réalisée avec AIToolkit.
Inspiré par et rival de PonyDiffusion.

PDXL + ILLUSTRIOUS TRAIN V3.34 :
Illustrious n'est pas un dérivé de PDXL, c'est différent et très bon. Essayez-le si vous en avez l'occasion.
J'ai entraîné une version de Simulacrum spécifiquement pour cela.
V3-2 au lieu de V3.22 :
L'objectif de v3.22 a évolué et je me suis perdu dans le terrier du testing de flux et à comprendre de nouveaux mécanismes. Après avoir appris suffisamment et déterminé que je sais comment fixer un sujet, comment taguer, et comment flux comprend le balisage; je peux en fait construire une vraie version 3.
Merci à tous ceux qui ont supporté mon cycle d'apprentissage et d'expérimentation. Cela a été une véritable montagne russe de tests, d'échecs et de vrais succès. Je sais ce qui peut être fait, comment le faire, et j'ai une méthodologie pour aborder et itérer ce que j'ai appris afin de créer ce que je veux. Le processus n'est pas parfait et sera affiné au fur et à mesure, donc ce sera une question de compréhension et de développement itératif peu importe ce que je construis. Je suis assez confiant, ayant franchi le premier grand pic Dunning-Kruger, que je peux commencer à apprendre et enseigner des infos utiles après les expériences, tout en faisant de mon mieux pour traiter et comprendre ces infos de manière utile tant pour l'utilisateur basique qu'avancé.
J'ai déterminé que mon approche initiale pour V4 est viable, mais le processus utilisé n'est pas valide comme je le pensais initialement lors de l'apprentissage itératif des systèmes. Plus d'aspects appris et d'échecs pour apprendre et développer le terrain fertilisé pour les succès à venir.
Versionnage basé sur des directives.
Je prévois d'introduire TROIS formations directives centrales par version et une version vanilla « nd » unique.
J'utiliserai des formations basées sur des directives générales non seulement pour le système principal mais aussi pour des images thématiques spécifiques afin de diffuser tous les aspects thématiques voulus dans le système.
La partie technique du processus de balisage sera unique et difficile à comprendre si vous n'êtes pas familier avec les raisons derrière certaines actions sur le système, donc les images et les balises seront probablement très confuses si vous voulez des détails précis.
Le système de balisage simplifié restera dans son propre droit, et sera toujours pleinement capable de produire les résultats nécessaires quand il le faut.
La version « nd » ou « no directive » pour chaque sortie garantira que les différences de test et les résultats soient similaires, comme l'oiseau dans la mine ; il est temps de partir quand il cesse de gazouiller. Ces modèles sœurs pourront probablement être fusionnés et normalisés pour réutilisation et interférence de concepts qui ont ou n'ont pas fonctionné selon la directive utilisée.
La fixation sur les personnages INDIVIDUELS est maintenant l'objectif absolu de ce modèle. Il n’y aura qu’un seul personnage fixé et la résolution de ce personnage sera ajustée selon un ratio descendant et ascendant correspondant aux paramètres de formation FLUX adaptés.
Les problèmes de V3.2 étaient moins prononcés que je ne le pensais :
La majorité des préoccupations provenaient d'informations manquantes que je compte combler progressivement. Juste une question de développement itératif.
Cela dit, la version formée du 3.21 est en cours de test et sera bientôt publiée. Elle a une meilleure capacité de contrôle de pose et un focus décalé sur le modèle utilisant une directive basée caméra assez longue.
Le résultat a montré une bonne compatibilité avec la majorité des loras testées et fonctionne même avec certaines loras très rigides qui ne peuvent pas être manipulées ou tournées avec la v32 actuelle.
Elle a montré une bonne compatibilité avec Flux Unchained, de nombreux modèles de personnages, modèles de visage, modèles humains, etc. La plupart du système ne chevauche pas ou ne casse pas les autres systèmes pour l'instant, donc c'est bon.
Problèmes de V3.2 à régler :
Il y a quelques problèmes de cohérence avec certaines poses et angles. Il y a aussi une contamination croisée avec diverses autres loras lorsqu'elles utilisent les tags de côté, de derrière, de dessus et de dessous. Je vais utiliser de nouveaux tags comme unité de vérification et entraîner un LORA entièrement séparé pour garantir la fidélité du contrôle caméra dans le futur.
Ça semble bien fonctionner surtout pour l’anime, mais avec les loras impliquées, il y a des problèmes.
Combinaison de tags pour la version 3.21 ;
J'ai quelques tests de base à faire pour m'assurer que la caméra fonctionne correctement selon la position, je testerai donc des tags comme :
un sujet en vue avant angle au-dessus
un sujet en vue avant angle latéral tout en étant au-dessus
un sujet en vue arrière angle au-dessus tout en étant en avant
un sujet en vue latérale angle au-dessus tout en étant en arrière
et d'autres tags similaires dans le flux_dev de base, afin d’assurer que ce que j’ai construit positionne correctement la caméra là où elle doit être, sans perte de fidélité de l’image.
D'après ce que j'ai compris, le système entraîne des profondeurs énormes si on utilise des options génériques comme ça. Plus de tests sont nécessaires pour confirmer.
Des tags comme attraper par derrière, sexe par derrière, etc. ne coopéreront probablement pas avec les tags derrière, donc j’utiliserai les tags arrière.
« from side », « from behind », « straight-on », « facing the viewer », et tout ce qui est directement lié à un safebooru, danbooru, gelbooru spécifique au personnage, rotations de placement ne seront pas appris. Ce sera entièrement basé sur la VUE d’un personnage, et non l’INTERACTION avec lui.
On ne veut pas non plus que des bras de point de vue (POV) soient présents la plupart du temps, donc il faudra beaucoup tester pour faire en sorte que le balisage ne génère pas accidentellement bras, jambes, torses et fixe bien sur le sujet individuel en question.
Certaines poses, franchement, n'ont pas fonctionné :
Il y a un système de combinaisons de tags à l'œuvre ici qui n'a tout simplement pas fait son travail, il faudra donc un nouveau set de combinaisons de tags pour contrôler correctement le personnage.
Les jambes sont déformées ou n’existent pas.
Les bras peuvent être déformés ou mal placés.
Les pieds manquent.
Le haut du torse est trop prononcé trop souvent. <<< surapprentissage
Le bas du torse ne montre pas correctement les vêtements.
Le cou n'affiche pas les vêtements corrects avec écharpes, serviettes, colliers, colliers ras-du-cou, etc.
Les tétons et organes génitaux sont un véritable chaos. Il faut un dossier approprié de leurs variations pour un contrôleur NSFW adéquat dans ce cas.
NAI devrait être spécifique au style et finement ajusté comme style.
Les options de vêtements génèrent plus souvent que nécessaire des types de corps.
La classification explicite est parfois quasiment inaccessible, parfois elle passe comme une locomotive.
Il n’y a pas assez d’images douteuses pour pondérer, et le système de tag explicite devrait aussi être tagué comme douteux pour assurer l’accès à ces données douteuses.
Certaines personnages d’anime apparaissent avec une mauvaise perspective, ce qui est problématique car l’objectif est une perspective associative correcte.
À quatre pattes est plutôt solide, mais il y a quelques problèmes de perspective. Les personnages d’anime ne sont pas assez souvent traités en 3D, donc les environnements autour nécessitent plus de fidélité.
À quatre pattes ne fonctionne pas dans un alignement sans beaucoup d’ajustements.
S’agenouiller ne fonctionne pas dans un alignement sans beaucoup d’ajustements.
Les alignements et groupes semblent formatés de manière unique pour flux, ce qui mérite une enquête approfondie. Presque comme activer une boucle interne de type "for each".
Il y a eu quelques succès :
La fidélité de base n’a pas souffert pour la plupart des images.
Beaucoup de nouvelles poses FONCTIONNENT, même si parfois maladroitement.
Le style anime a été changé d'une manière unique propre à NAI avec un soupçon de réalisme ajouté.
Plusieurs personnages peuvent être posés, bien que de façon parfois très étrange.
Se tenir debout à n'importe quel angle a une fidélité et une qualité d’image fantastiques avec le style NAI.
V3.3 devra attendre.
Feuille de route V3.3 :
J’ai mis à jour les ressources à la fin de ce document et j’ai séparé l’ancienne documentation dans un article distinct pour archivage.
Avec le résultat reflétant mieux ma vision, je peux orienter mon focus sur l’étape suivante de la liste d’objectifs : les superpositions.
V3.3 introduira ce que j’appelle les tags offset brûlés à alpha élevé, qui faciliteront la création de comics, interfaces de jeu, superpositions, barres de vie, affichages, etc.
Théoriquement, vous pouvez créer vos propres faux jeux dans consistency si je produis une superposition correcte avec les bonnes brûlures.
Cela posera les bases pour imposer des personnages en n'importe quelle position de n'importe quelle profondeur de scène, mais cela viendra plus tard.
Il peut DÉJÀ créer des feuilles de sprites de manière équitable, je vais donc explorer le système de tag intégré dans les prochains jours pour tester ces divers sous-systèmes avec un peu d'effort dans les prompts et de puissance de calcul. Il y a une forte probabilité que cela existe déjà et qu'il faille juste le découvrir.
Objectifs V4 :
Si tout se passe bien, le système entier sera prêt pour une capacité de production complète incluant modification d’image, montage vidéo, édition 3D, et bien plus encore que je ne peux encore concevoir.
v33 superpositions
C’est un peu un abus de langage, c’est plus un cadre de définition de scène pour la structure suivante
Ce point prendra à la fois le moins et le plus de temps, j’ai plusieurs expériences à faire avec l’alpha pour que ça marche, mais je suis sûr que la superposition sera une option non seulement pour afficher des messages, mais aussi pour le contrôle de scène selon la profondeur.
v34 imposer personnages, planification rotation, et décalages point de vue précis :
S’assurer que certains personnages existent et suivent les directives est un objectif principal, car parfois ce n’est tout simplement pas le cas.
Une évaluation complète des rotations basée sur les valeurs pitch/yaw/roll en degrés sera implémentée. Ce ne sera pas parfait car je n’ai pas les compétences mathématiques, ni les ensembles d’images, ni les compétences en logiciel 3D pour cela, mais ce sera un bon début et, espérons-le, cela intégrera ce que FLUX a déjà.
v35 contrôleurs de scènes
Points d’interactions complexes dans les scènes, contrôle caméra, focus, profondeur, et plus permettant la construction complète de scènes avec les personnages que vous y placez.
Pensez à cela comme une version 3D du contrôleur de superposition, mais boostée à fond si vous le souhaitez.
v36 contrôleurs d’éclairage
Changements d’éclairage segmentés et contrôlés par scène affectant tous les personnages, objets et créations inclus.
Chaque lumière sera placée et générée selon des règles spécifiques définies dans unreal avec divers types d’éclairage, sources, couleurs, etc.
Théoriquement FLUX devrait combler les lacunes.
v37 types de corps et personnalisation
Avec l’introduction des types de corps basiques, je veux introduire une création de types de corps plus complexe incluant notamment :
correction des poses qui ne fonctionnent pas correctement
ajout de nombreuses poses supplémentaires
cheveux plus complexes :
interaction des cheveux avec objets, cheveux coupés, abîmés, décolorés, multicolores, attachés, perruques, etc.
yeux plus complexes :
différents types d'yeux, ouverts, fermés, plissés, etc.
expressions faciales diverses :
heureux, triste, :o, sans yeux, visage simple, sans visage, etc.
types d'oreilles :
pointues, rondes, sans oreilles, etc.
couleurs de peau variées :
claire, rouge, bleue, verte, blanche, grise, argentée, noire, noire de jais, marron clair, marron, marron foncé, et plus.
J’essaierai d’éviter les sujets sensibles ici car le sujet de la couleur de peau est très important pour beaucoup, mais je veux surtout plein de couleurs comme pour les vêtements.
contrôleurs de taille bras, jambes, torse supérieur, taille, hanches, cou, tête :
biceps, épaules, coudes, poignets, mains, doigts, avec des tailles pour longueur, largeur, et circonférence.
clavicule et autres tags de torse
taille et autres tags de taille
généralisation du corps basée sur un gradient de 1 à 10 plutôt qu’un système prédéfini utilisé par les boorus
v38 tenues et personnalisation
Près de 200 tenues environ, chacune avec ses paramètres personnalisés.
v39 500 personnages de jeux vidéo, anime, et manga choisis à partir de données haute fidélité
cinq cents cigarettes- euh… Plein de personnages. Oui. Définitivement pas un grand nombre de personnages basés sur des memes sans lien rationnel au design ou archétype.
Après ça, vous pouvez créer ou entraîner n'importe quel personnage.
grosse amélioration de fidélité et qualité :
incluant des dizaines de milliers d’images de sources diverses d’anime de haute qualité, modèles 3D, photo-réalisme semi-réaliste pour superposer et entraîner cette version finement réglée de flux dans un style adapté aux paramètres.
chaque image sera notée en fidélité et taguée sur une échelle de score_1 à score_10 à la manière de pony, avec une touche unique selon le succès ou non.
Sortie V3.2 - 4000 étapes :
Ce modèle n’est clairement pas pour les enfants. C’est un modèle de base SFW/QUESTIONABLE/NSFW pouvant être entraîné en tout.
Ce n’est PAS un créateur de pornographie, il le peut uniquement s’il est sollicité. Cela fait partie du package lorsque vous activez certains comportements en instruisant l’IA, vous héritez de conséquences. Les images sont actuellement réparties à peu près 33% 33% 33%, plus ou moins. Il est pondéré VERS le sûr à la manière de NAI.
Je suis partisan de l’activation et de l’enseignement d’informations pour que chaque individu puisse décider de leur usage. Enseigner à une IA non censurée beaucoup de choses non censurées de façon contrôlée et prudente, je pense que c’est sain pour la progression de l’IA vers une compréhension complète, ainsi que pour ceux générant des images depuis l’IA sans avoir à voir des horreurs sans arrêt.
Cet outil montre un potentiel bien plus grand que tout ce que j’ai vu auparavant.
Utilisez ma charge de travail ComfyUI. Elle est jointe à toutes les images ci-dessous.
Sécurité activée par défaut :
douteux < débloque plus de traits douteux aléatoires
explicite < débloque les contenus fun qui apparaissent aléatoirement
Tags d’activation de perspective : essayez de mélanger ; from front, side view, etc.
from front, front view,
from side, side view,
from behind, rear view,
from above, above view,
from below, below view,
Poses principales ajoutées et améliorées :
à quatre pattes
agenouillé
accroupi
debout
penché
s’appuyant
couché
à l’envers
sur le ventre
sur le dos
placement des bras
placement des jambes
inclinaisons de tête
directions de tête
directions des yeux
placement des yeux
solidité de la couleur des yeux
solidité de la couleur des cheveux
taille des seins
taille des fesses
taille de la taille
une multitude d’options de vêtements
une multitude d’options de personnages
une multitude d’expressions faciales
Les poses sexuelles sont en cours de développement et il est fortement conseillé de les éviter jusqu’à leur bonne maturation. Elles dépassent largement mes capacités actuelles et je n’ai pas la concentration pour définir la voie à suivre pour le moment.
Le créateur de pose, constructeur d’angle, mise en place de situation, imposeur de concepts et structure d’interpolation sont en place et je vais entraîner plus de versions.
Profitez-en.
Feuille de route V3.2 :
25/08/2024 05:16 - J'ai identifié que le processus a fonctionné, et le système est fonctionnel au-delà des attentes. L'IA a développé des comportements émergents qui ont posé les personnages de façon exponentiellement plus puissante que prévu. Les tests commencent et les résultats sont fantastiques.
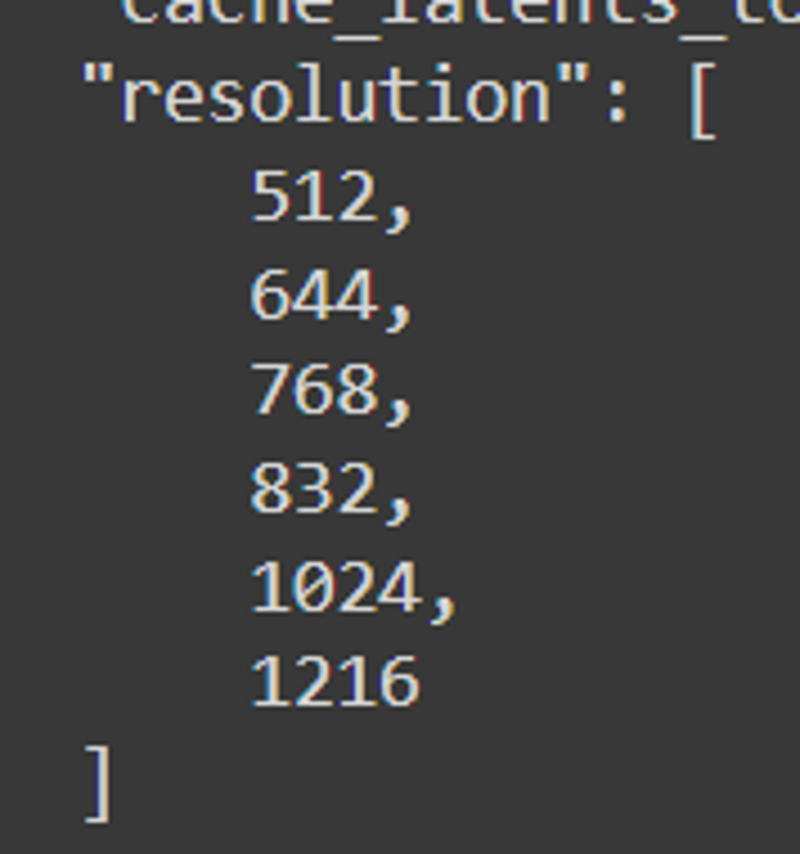
Les résolutions finales étaient : 512, 640, 768, 832, 1024, 1216
25/08/2024 15h - Tout est bien tagué et les poses sont prêtes. Le véritable entraînement commence maintenant, avec plusieurs tests dimensionnels, tests du nombre de lr, vérifications des étapes, et beaucoup plus pour évaluer le bon candidat pour la sortie v32.
25/08/2024 04h - La première version de v32 a montré des déformations minimes vers l’étape 1400 puis des déformations graves vers l’étape 2200, indiquant que le balisage lazy WD14 n’a pas marché. Un balisage manuel arrive. Ça promet une matinée fun.
24/08/2024 soir - Ça mijote maintenant.
 Je suspecte que celui-ci ne fonctionnera pas. J’ai auto-taggué tout et découpé les angles de pose pour l’instant. Je vais voir ce que wd14 peut faire tout seul. Après l’entraînement réussi ou raté, je restaurerai les angles d’origine et l’ordre établi des tags. Voyons comment ça fonctionne maintenant que toutes les données intentionnelles sont regroupées et cas d’utilisation denses.
Je suspecte que celui-ci ne fonctionnera pas. J’ai auto-taggué tout et découpé les angles de pose pour l’instant. Je vais voir ce que wd14 peut faire tout seul. Après l’entraînement réussi ou raté, je restaurerai les angles d’origine et l’ordre établi des tags. Voyons comment ça fonctionne maintenant que toutes les données intentionnelles sont regroupées et cas d’utilisation denses.Avec 4000 images, je suspecte que le cache des latents prendra du temps, mais avec l’attention portée aux poupées et corps "cas d’utilisation", ça devrait aller au moins.
24/08/2024 midi -
 On travaille dur.
On travaille dur. Tout est formaté pour avoir des arrière-plans à implication d’ombres, ce qui aidera flux à générer des images basées sur surfaces et lieux. Tout est construit pour poser sur les poses manquantes que flux ne gère pas. Tout est construit pour fixer une multiplicité de sujets superposés à divers endroits.
Tout est formaté pour avoir des arrière-plans à implication d’ombres, ce qui aidera flux à générer des images basées sur surfaces et lieux. Tout est construit pour poser sur les poses manquantes que flux ne gère pas. Tout est construit pour fixer une multiplicité de sujets superposés à divers endroits.Je me focalise sur le placement correct des bras et la garantie que les bras tagués qui se chevauchent construireont des bras du point A au point B.
24/08/2024 matin - Il y a apparemment aussi quelques problèmes de bras, mais ce n’est pas grave, je l’ajouterai à la liste. Merci d’avoir signalé cela, il y a clairement une contamination croisée à résoudre. J’utilise un système de boucle ComfyUI spécifique, absent du système du site, donc je devrais peut-être désactiver la génération sur site pour cette version.
 23/08/2024 - J’en suis à environ 340 nouvelles images anime très détaillées avec pose quasi uniforme, identifiants pitch/yaw/roll pour assurer solidité, changements de coloration, différenciation de taille avec seins, cheveux, et fesses. Il en reste 554. V3.2 sera fortement dédiée à l’anime, ensuite je compte m’approvisionner chez pony pour produire assez de réalisme synthétique pour créer les éléments nécessaires de réalisme. À moins que flux ne le permette après entraînement, auquel cas j’utiliserai juste flux.
23/08/2024 - J’en suis à environ 340 nouvelles images anime très détaillées avec pose quasi uniforme, identifiants pitch/yaw/roll pour assurer solidité, changements de coloration, différenciation de taille avec seins, cheveux, et fesses. Il en reste 554. V3.2 sera fortement dédiée à l’anime, ensuite je compte m’approvisionner chez pony pour produire assez de réalisme synthétique pour créer les éléments nécessaires de réalisme. À moins que flux ne le permette après entraînement, auquel cas j’utiliserai juste flux. Ces images DOIVENT assurer la fidélité et la séparation selon la pose, surtout que j'ai une nouvelle méthodologie utilisant les mots-clés from et view. Théoriquement, ça devrait fonctionner presque pareil que le contrôle de pose de NovelAI une fois terminé, ce qui est mon objectif. Les personnages et la différenciation entre eux sont une toute autre histoire.
Ces images DOIVENT assurer la fidélité et la séparation selon la pose, surtout que j'ai une nouvelle méthodologie utilisant les mots-clés from et view. Théoriquement, ça devrait fonctionner presque pareil que le contrôle de pose de NovelAI une fois terminé, ce qui est mon objectif. Les personnages et la différenciation entre eux sont une toute autre histoire.Tout doit être parfaitement ordonné et aligné, sinon le contexte nécessaire ne s'ajoutera pas assez pour influencer le modèle de base suffisamment pour être utile.
Par conception, SÛR sera le mode par défaut, donc l’ensemble du système sera pondéré plutôt vers le sûr, avec possibilité d’activer le NSFW.
Je vais entraîner plusieurs itérations de ce LORA particulier pour assurer une différenciation stricte entre les deux, tout en permettant au public plus NSFW de s’amuser avec la version plus NSFW.
Mon espoir est qu’à l’issue de l’entraînement, je puisse injecter un dataset choisi de 50 000 images dans le système et qu’il crée quelque chose de magique. Quelque chose potentiellement du même niveau de puissance que pony pour tout ce que l’on souhaite. Alors je pourrai me reposer en sachant que l’univers est reconnaissant. Ensuite, vous pourrez probablement y mettre ce que vous voulez et ça fera tout ce que vous voulez grâce à la puissance innée de flux et la colonne vertébrale de consistency.
Je compte publier les données d'entraînement complètes de l’ensemble initial v3.2 lorsque tout sera organisé, entraîné, testé et prêt. Je publierai les données v3 ce week-end quand j’aurai le temps.
J'ai identifié plusieurs incohérences de pose, surtout avec le mot-clé lying couplé aux mots-clés d’angle. Je testerai chaque combinaison et consoliderai leur cohérence avant de passer à la phase suivante ; choix de tenues de base, changements, et dérivés selon poses qui fonctionnent ou pas. Sans parler d’inclure plus d’informations détaillées pour les éléments douteux et NSFW plus tard. Devinez ce que ce sera après la prochaine version.
Jusqu’alors, il faut s’assurer que les poses fonctionnent vraiment comme prévu, donc je vais créer de nouveaux mots-clés de combinaisons intentionnelles, augmenter le nombre total d’images par pose, par angle, et plus d’angles par situation. Je créerai aussi des données fonctionnant comme des espaces réservés pour des situations et images plus complexes, mais flux n’en a pas vraiment besoin, donc je le ferai à la volée. J’ajouterai également une série de tags « base » qui déclencheront certaines choses en cas d’échec vers d’autres, ce qui devrait aider un peu la cohérence.
Documentation V3 :
Testé principalement sur FLUX.1 Dev e4m3fn en fp8, donc le checkpoint fusionné reflétera cette valeur à la fin du téléchargement. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
Il fonctionne sur le modèle de base FLUX.1 Dev, mais aussi sur d'autres modèles, merges, et loras. Les résultats varieront. Expérimentez avec l'ordre de chargement, car les valeurs du modèle changent de manière séquentielle et variable.
C’est rien de moins que la colonne vertébrale de FLUX. Il donne du pouvoir à des tags utiles très similaires à danbooru, pour établir un contrôle caméra et une assistance facilitant la création de personnages très personnalisables dans des situations que FLUX PEUT FAIRE, mais demandant beaucoup plus d'efforts par défaut.
Je conseille fortement d’utiliser un système de boucles multiples pour assurer la fidélité d’image. Consistency améliore qualité et fidélité avec les itérations.
C’est TRÈS orienté individuel. Cependant, grâce à la structuration des résolutions, il peut gérer BEAUCOUP de personnes dans des situations similaires. Les loras qui modifient immédiatement l’écran sans contexte sont généralement inutiles, car elles n’apportent rien au contexte. Les loras plus spécifiques à l’ajout de TRAITS ou aux interactions entre personnages fonctionnent bien. Vêtements, types de cheveux, contrôle du genre fonctionnent. La plupart des loras que j’ai testées fonctionnent, certaines rien du tout.
Ce n’est pas un merge. Ce n’est pas une combinaison de loras. Ce lora fut créé avec des données synthétiques générées par NAI et AutismPDXL sur un an. L’ensemble d’images est complexe et les images choisies pour créer ce modèle étaient difficiles à sélectionner. Beaucoup d’essais, erreurs.
Une SÉRIE de tags principaux est introduite avec ce lora. Il ajoute un véritable squelette à FLUX, inexistant par défaut. Le modèle d’activation est complexe, mais si vous construisez votre personnage comme NAI, il s’en rapprochera.
Le potentiel et la puissance de ce modèle ne doivent pas être sous-estimés. C’est un lora extrêmement puissant dont le potentiel dépasse mes compétences.
Il peut TOUJOURS produire des abominations si vous n’êtes pas prudent. En restant sur une requête standard et un ordre logique, vous devriez créer de beaux arts en un rien de temps.
Résolutions : 512, 768, 816, 1024, 1216
Étapes suggérées : 16
Guidage FLUX : 4 ou 3-5 si têtu, 15+ si très têtu
CFG : 1
Utilisé avec 2 boucles. La première avec upscale 1.05x et débruitage 0.72-0.88, la seconde débruitage 0.8 quasiment constant, selon quantité de traits à ajouter ou retirer.
BASSIN DE TAGS PRINCIPAUX :
anime - convertit le style poses, personnages, tenues, visages, etc. en style anime
realistic - convertit le style en réaliste
from front - vue de face d’une personne, épaule alignée vers l’avant face au spectateur, où le centre du torse fait face au spectateur.
from side - vue de profil d’une personne, épaule verticale face au spectateur, signifiant que le personnage est de côté.
from behind - vue directement de dos d’une personne
straight-on - vue verticale frontale, généralement pour un angle horizontal plan
from above - inclinaison de 45 à 90 degrés vers le bas sur un individu
from below - inclinaison de 45 à 90 degrés vers le haut sur un individu
face - image centrée sur le visage, bonne pour inclure les détails faciaux spécifiques si récalcitrants
full body - vue complète d’un individu, bon pour poses complexes
cowboy shot - tag cowboy shot standard, fonctionne bien avec anime, moins avec réalisme
regardant spectateur, regardant sur le côté, regardant devant
face sur le côté, face au spectateur, dos tourné
regard en arrière, regard en avant
les tags mixtes créent les résultats mixtes désirés, mais les résultats sont variables
from side, straight-on - caméra horizontale pointée sur le côté d’un individu ou plusieurs
from front, from above - inclinaison 45 degrés vers le bas de la caméra avant au-dessus
from side, from above - inclinaison 45 degrés vers le bas de la caméra côté au-dessus
from behind, from above - inclinaison 45 degrés vers le bas de la caméra arrière au-dessus
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front, from side, from below
from front, from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
Ces tags peuvent sembler similaires, mais leur ordre crée souvent des résultats très différents. Mettre le tag from behind avant from side par exemple pondère le système vers l’arrière plutôt que le côté, mais on voit souvent le haut du torse tourner et le corps s’orienter à 45 degrés dans un sens ou l’autre.
Le résultat est variable, mais fonctionne bien.
Traits, coloration, vêtements, etc. fonctionnent aussi.
cheveux rouges, cheveux bleus, cheveux verts, cheveux blancs, cheveux noirs, cheveux dorés, cheveux argentés, cheveux blonds, cheveux bruns, cheveux violets, cheveux roses, cheveux aqua
yeux rouges, yeux bleus, yeux verts, yeux blancs, yeux noirs, yeux dorés, yeux argentés, yeux jaunes, yeux marron, yeux violets, yeux roses, yeux aqua
combinaison latex rouge, combinaison latex bleue, combinaison latex verte, combinaison latex noire, combinaison latex blanche, combinaison latex dorée, combinaison latex argentée, combinaison latex jaune, combinaison latex marron, combinaison latex violette
bikini rouge, bikini bleu, bikini vert, bikini noir, bikini blanc, bikini jaune, bikini marron, bikini violet, bikini rose
robe rouge, robe bleue, robe verte, robe noire, robe blanche, robe jaune, robe marron, robe rose, robe violette
jupes, chemises, robes, colliers, tenues complètes
matériaux multiples ; latex, métallique, denim, coton, etc.
Les poses peuvent ou non fonctionner avec la caméra, nécessitent des ajustements
à quatre pattes
agenouillé
couché
couché, sur le dos
couché, de côté
couché, à l’envers
agenouillé, de dos
agenouillé, de face
agenouillé, de côté
accroupi
accroupi, de dos
accroupi, de face
accroupi, de côté
Contrôler les jambes et autres peut être délicat, donc jouez un peu avec.
jambes
jambes jointes
jambes écartées
jambes écartées largement
pieds joints
pieds écartés
Des centaines d’autres tags utilisés et inclus, des millions de combinaisons possibles.
Utilisez-les avant toute spécification des traits d’une personne, mais après le prompt pour flux lui-même.
INSTRUCTION :
Simplement, faites-le. Tapez ce que vous voulez et voyez ce qui arrive. FLUX dispose déjà d’énormément d’informations, alors utilisez les poses et autres pour amplifier vos images.
Exemple :
une femme assise sur une chaise dans une cuisine, from side, from above, cowboy shot, 1girl, assise, from side, cheveux bleus, yeux verts

une super héroïne volant dans le ciel lançant un rocher, avec une aura menaçante et puissante autour d’elle, réaliste, 1girl, from below, combinaison latex bleue, collier noir, ongles noirs, lèvres noires, yeux noirs, cheveux violets
 une femme mangeant au restaurant, from above, from behind, à quatre pattes, fesses, string
une femme mangeant au restaurant, from above, from behind, à quatre pattes, fesses, string Oui ça a marché. Ça marche généralement.
Oui ça a marché. Ça marche généralement.
En vérité, ce modèle doit gérer la plupart des scénarios fous, mais c’est clairement hors de ma portée complète. J’ai essayé de limiter le chaos et inclure assez de tags de pose pour que ça marche, alors essayez de rester sur les tags les plus essentiels et utiles.
Plus de 430 tentatives échouées pour créer ceci ont finalement mené à une série de théories réussies. Je ferai un rapport complet des infos nécessaires et publierai les données d’entraînement utilisées probablement ce week-end. Ce fut long et difficile. J’espère que cela vous plaira à tous.
Documentation V2 :
La nuit dernière j’étais très fatigué, donc je n’ai pas fini de compiler le rapport complet et les conclusions. Attendez-le au plus vite, probablement en journée pendant que je travaille, je ferai des tests et noterai des valeurs.
Introduction à l’entraînement Flux :
Avant, PDXL ne nécessitait qu’un petit nombre d’images avec tags danbooru pour des résultats finement ajustés comparables à NAI. Moins d’images était un avantage car cela réduisait le potentiel, ici moins d’images ne marche pas. Il faut quelque chose, plus. De la puissance avec du cran.
Le modèle contient beaucoup mais la variance entre données apprises est plus élevée que prévu au début. Plus de variance signifie plus de potentiels, je ne comprenais pas pourquoi ça marcherait avec trop de variance.
Après quelques recherches, j’ai constaté que le modèle est si puissant GRÂCE à cela. Il peut produire des images « ORIENTÉES » selon la profondeur, où l’image est segmentée et superposée sur une autre image en utilisant le bruit d’une autre comme guide. Ça m’a fait réfléchir : comment entraîner >>ÇA<< sans détruire les détails essentiels du modèle. J’avais pensé à redimensionner, puis au bucketting. Ce qui amène à la première partie ici.
J’y suis allé un peu à l’aveugle, réglant selon suggestions, évaluant les résultats. Lent processus, donc j’ai fait quelques recherches et lu des articles à côté pour accélérer. Si j’avais plus de capacité mentale je ferais tout en même temps, mais je suis une personne seule avec un travail. J’y ai mis le paquet. Si j’avais plus de temps, j’aurais fait tourner 50 entraînements à la fois, mais je n’ai pas le temps. Je paierais, mais ne pourrais pas configurer.
J’ai choisi ce que je pensais être le meilleur format selon mon expérience avec SD1.5, SDXL, et formations PDXL lora. Ça a été correct, mais il y a clairement quelque chose de mal avec ces résultats, je détaillerai.
Formatage d’entraînement :
J’ai fait plusieurs tests.
Test 1 - 750 images aléatoires de mon échantillon danbooru :
UNET LR - 4e-4
J’ai noté que la plupart des autres éléments importaient peu et pouvaient rester par défaut, sauf l’attention au bucketting des résolutions.
1024x1024 seulement, recadré au centre
Entre 2k et 12k étapes
J’ai choisi 750 images aléatoires parmi un pool de tags danbooru et j’ai uniformisé les tags.
J’ai utilisé moat tagger et ajouté les tags au fichier de tags, en évitant les écrasements.
Le résultat n’était pas prometteur. Le chaos est attendu. Introduction d’éléments humains nouveaux comme génitaux souvent aléatoires ou absents. Conforme aux observations générales.
Je n’attendais pas que le modèle global pâtisse autant, vu que les tags ne se chevauchaient pas souvent je pensais.
J’ai fait ce test deux fois, avec deux loras inutiles à environ 12k étapes chacun. Test de 1k à 8k montre presque aucun écart utile vers un objectif même en regardant bien la distribution des tags.
Il y a autre chose. Quelque chose que j’ai raté, ce n’est ni humain ni une description clip. C’est autre chose…
À ce point d’échec, j’ai découvert que ce système de profondeur est interpolatif et basé sur deux prompts complètement différents mais cooperatifs. Comment il détermine leur usage m’est inconnu, j’étudierai la mathématique aujourd’hui.
Test 2 - 10 images :
UNET LR - 0.001 <<< LR très élevé
256x256, 512x512, 768x768, 1024x1024
Les premières étapes montraient déjà des déviations, comme la brûlure dans les tests SD3. Pas bon. Le saignement a commencé vers l’étape 500. Inutile à 1000. J’utilise bonnement "repeat", ça semblait un bon échec.
Les déviations causent beaucoup de dégâts. Introduit un nouvel élément de contexte, puis devient une machine à snacks. Remplace les éléments humains par presque rien d’utile ou des artefacts brûlés comme en inpainting raté. C’est fascinant combien FLUX résiste et fonctionne encore. Ce test montre la résilience impressionnante de FLUX, résistant à mes efforts.
Échec, besoin de plus de tests avec des réglages différents.
Test 3 - 500 images de poses :
UNET LR - 4e-4 <<< Devrait être divisé par 4 et avoir le double d’étapes.
Bucketting COMPLET - diverses tailles d’images données librement. Résultat inattendu.
Le résultat est littéralement le noyau de ce modèle de consistance, tellement puissant. Ça a causé un peu plus de dégâts que pensé mais ça reste puissant.
Note : l’anime n’utilise généralement pas de profondeur de champ. Ce modèle semble PROSPÉRER sur la profondeur de champ et le flou pour différencier la profondeur. Il faut un type de depth controlnet à appliquer sur ces images pour garantir la variance de profondeur, mais je sais pas comment encore. Entraînement cartes de profondeur avec normales ? Ou ça détruit le modèle faute de negative prompt.
Davantage de tests, données, infos nécessaires.
Test 4 - paquet de commande 5000 consistance :
UNET LR - 4e-4 <<< Devrait être divisé par 40, avec 20x le nombre d’étapes. Entraîner ça dans le modèle principal n’est ni simple ni rapide. Mathématiques mauvaises avec la méthode actuelle pour ne pas casser le modèle. J’ai lancé et publié découvertes initiales.
J’avais écrit toute une section plus une suite puis j’ai cliqué en arrière et tout perdu, je réécrirai.
Les grands échecs :
Le taux d’apprentissage était TROP ÉLEVÉ pour mes loras à 12k étapes. Le système entier repose sur l’apprentissage par gradient, mais le rythme d’enseignement était TROP ÉLEVÉ pour que le modèle retienne sans se casser. En gros, je ne les ai pas brûlés, j’ai ré-entrainé le modèle pour faire ce que je voulais. Le problème est que je ne savais pas vraiment ce que je voulais, donc le système était basé sur une série de choses non dirigées et sans gradient de profondeur. Donc voué à l’échec, plus d’étapes ou non.
Le STYLE pour FLUX n’est pas ce que les gens pensent du style pour PDXL et SD1.5. Le système gradient stylise oui, mais toute la structure souffre beaucoup quand on tente d’imposer TROP d’informations trop rapidement. C’est TRÈS destructeur, comparé aux loras PDXL qui imposaient plutôt qu’entraînaient totalement. Ils AUGMENTAIENT ce qui existait plutôt que d’entrer de nouvelles données.
Constatations critiques :
ALPHA, ALPHA, et ENCORE ALPHA<<<< Ce système fonctionne énormément via gradients alpha. Tout DOIT prendre en compte alpha selon détails photo. Distance, profondeur, ratio, rotation, décalage sont des pièces clé pour composer ce modèle et créer un styliseur correct demandant ces détails dans plus d’un prompt.
TOUT doit être décrit correctement. Simple balisage danbooru est essentiellement du style. On force le modèle à reconnaître le style qu’on souhaite appliquer, donc on ne peut pas imposer de nouveaux concepts sans allocution nécessaire des tags. Sinon, fautes entraînent résultats nuls. Garbage in, garbage out.
Le training de pose est TRÈS puissant quand on utilise BEAUCOUP d’infos de pose. Le système reconnaît déjà la plupart des tags, on sait pas tout ce qu’il capte encore. Entraîner les poses pour connecter ce qui EXISTE à ce que VOUS VOULEZ avec des tags spécifiques sera très puissant pour organiser tags et affiner.
Documentation des étapes ;
v2 - 5572 images -> 92 poses -> 4000 étapes FLUX
L’objectif initial d’amener NAI à SDXL est maintenant aussi appliqué à FLUX. Restez connectés pour plus de versions.
Test de stabilité nécessaire, montre déjà une capacité distincte bien au-delà de PDXL. Il nécessite un entraînement supplémentaire, mais est bien plus puissant que prévu à un nombre d’étapes aussi bas.
Je crois que la première couche d’entraînement de pose ne contient qu’environ 500 images, c’est ce qui compte le plus. Je publierai l’ensemble complet sur HuggingFace lorsque j’aurai un set organisé et le compte. Je ne veux pas sortir d’images incorrectes ou du contenu indésirable que j’aurais pris par erreur.
Poursuivez la lecture ici :
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
Références importantes :
Je ne fume pas, mais FLUX a besoin d’une pause parfois.
Un assistant de workflow et génération d’images. J’ai surtout utilisé les nœuds de base ComfyUI, mais j’en expérimente d’autres régulièrement.
Un modèle IA très puissant et difficile à comprendre avec un potentiel énorme.
Sans eux, je n’aurais jamais voulu faire ça. Un grand merci au staff de NAI pour leur travail et la bête de génération d’images, avec leur assistant d’écriture redoutable. Filmez de l’argent chez eux.
Ils ont créé flux et méritent une très grande part, si pas la majorité du crédit pour la flexibilité de ce modèle. Je me limite à la mise au point et direction de ce qui ressemble à un léviathan vers sa destination.
Un assistant de tag puissant. Je voulais presque créer le mien jusqu’à découvrir cette puissance.
Outil que j’utilise pour entraîner mes versions Flux. Un peu capricieux mais fonctionne très bien sur plusieurs systèmes.
Immanquable rival de terrain. Une bête monstrueuse pour générer des images d’un large gradient, outil inestimable de recherche et compréhension, et grande inspiration pour cette direction et progrès.

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.
![Old Consistency V32 Lora [FLUX1.D/PDXL] Féminin v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































