Stable Cascade - base
Mots-clés et tags associés
Images en vedette


Paramètres recommandés
steps
resolution
Conseils
Utilisez la version à 3,6 milliards de paramètres de l'Étape C pour de meilleurs résultats puisque le finetuning principal y a été effectué.
Utilisez la variante à 1,5 milliard de paramètres pour l'Étape B afin d'exceller dans la reconstruction des petits détails fins.
Le modèle est bien adapté à la formation et à l'inférence efficaces grâce à un espace latent plus petit et supporte des extensions comme le finetuning, LoRA, ControlNet, IP-Adapter et LCM.
Le modèle est destiné uniquement à des fins de recherche et ne doit pas être utilisé pour générer des représentations factuelles ou violer la Politique d'utilisation acceptable de Stability AI.
Les visages et les personnes peuvent ne pas être générés correctement car l'auto-encodage du modèle est imparfait.
Sponsors du créateur
Démos :
- multimodalart : https://hf.co/spaces/multimodalart/stable-cascade
- ehristoforu : https://hf.co/spaces/ehristoforu/Stable-Cascade
Démos :
multimodalart : https://hf.co/spaces/multimodalart/stable-cascade
ehristoforu : https://hf.co/spaces/ehristoforu/Stable-Cascade
Stable Cascade
Ce modèle est basé sur l'architecture Würstchen et sa principale
différence par rapport à d'autres modèles comme Stable Diffusion est qu'il fonctionne dans un espace latent beaucoup plus petit. Pourquoi est-ce
important ? Plus l'espace latent est petit, plus l'inférence est rapide et la formation devient moins coûteuse.
Quelle est la taille de l'espace latent ? Stable Diffusion utilise un facteur de compression de 8, ce qui correspond à une image 1024x1024 encodée en 128x128. Stable Cascade atteint un facteur de compression de 42, ce qui signifie qu'il est possible d'encoder une
image 1024x1024 en 24x24, tout en maintenant des reconstructions nettes. Le modèle conditionné par le texte est ensuite entraîné dans cet
espace latent très compressé. Les versions précédentes de cette architecture ont permis une réduction de coût de 16x par rapport à Stable
Diffusion 1.5. <br> <br>
Ainsi, ce type de modèle est bien adapté aux usages où l'efficacité est importante. De plus, toutes les extensions connues
comme le finetuning, LoRA, ControlNet, IP-Adapter, LCM, etc. sont également possibles avec cette méthode.
Détails du modèle
Description du modèle
Stable Cascade est un modèle de diffusion entraîné pour générer des images à partir d'un prompt texte.
Développé par : Stability AI
Financé par : Stability AI
Type de modèle : Modèle génératif texte-image
Sources du modèle
Pour des fins de recherche, nous recommandons notre dépôt Github StableCascade (https://github.com/Stability-AI/StableCascade).
Vue d'ensemble du modèle
Stable Cascade se compose de trois modèles : Étape A, Étape B et Étape C, représentant une cascade pour générer des images,
d'où le nom "Stable Cascade".
Les Étapes A et B sont utilisées pour compresser les images, similaire au rôle du VAE dans Stable Diffusion.
Cependant, avec cette configuration, une compression beaucoup plus élevée des images peut être obtenue. Alors que les modèles Stable Diffusion utilisent un
facteur de compression spatial de 8, codant une image de résolution 1024 x 1024 en 128 x 128, Stable Cascade atteint
un facteur de compression de 42. Cela encode une image de 1024 x 1024 en 24 x 24, tout en étant capable de décoder précisément l'
image. Ceci présente l'avantage majeur de rendre la formation et l'inférence moins coûteuses. De plus, l'Étape C est responsable
de la génération des petits latents 24 x 24 à partir d'un prompt texte. L'image suivante illustre cela visuellement.
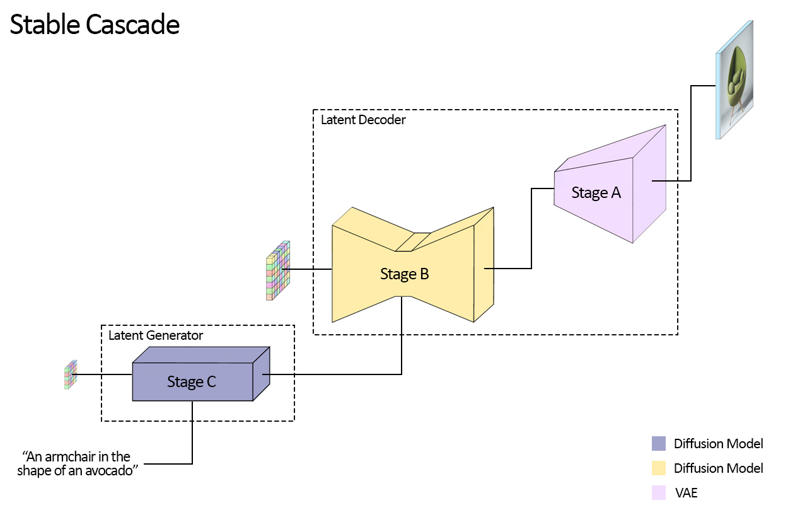
Pour cette version, nous fournissons deux checkpoints pour l'Étape C, deux pour l'Étape B et un pour l'Étape A. L'Étape C est disponible en versions 1 milliard et 3,6 milliards de paramètres, mais nous recommandons fortement l'utilisation de la version à 3,6 milliards, car c'est elle qui a reçu la majeure partie du finetuning. Les deux versions pour l'Étape B comportent 700 millions et 1,5 milliard de paramètres. Les deux donnent d'excellents résultats, cependant la version à 1,5 milliard excelle dans la reconstruction des petits détails fins. Par conséquent, vous obtiendrez les meilleurs résultats en utilisant la variante la plus grande pour chaque étape. Enfin, l'Étape A contient 20 millions de paramètres et est fixe en raison de sa petite taille.
Évaluation
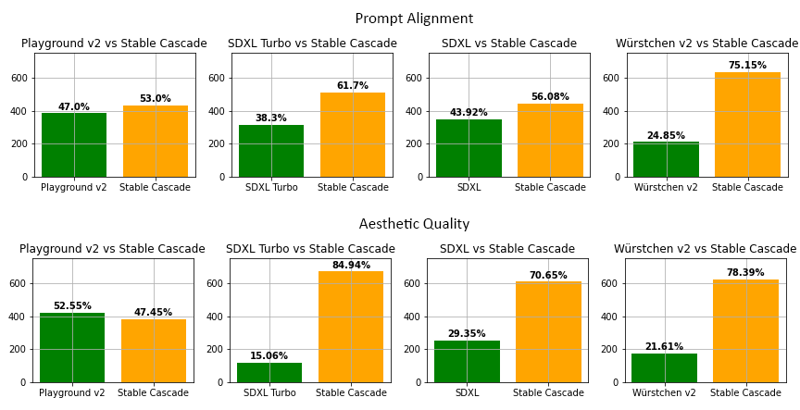
Selon notre évaluation, Stable Cascade offre les meilleures performances à la fois en alignement avec le prompt et en qualité esthétique dans presque toutes
les comparaisons. L'image ci-dessus présente les résultats d'une évaluation humaine utilisant un mélange de parti-prompts (lien) et de prompts esthétiques. Spécifiquement, Stable Cascade (30 étapes d'inférence) a été comparé à Playground v2 (50 étapes d'inférence), SDXL (50 étapes d'inférence), SDXL Turbo (1 étape d'inférence) et Würstchen v2 (30 étapes d'inférence).
Exemple de code
⚠️ Important : Pour que le code ci-dessous fonctionne, vous devez installer diffusers depuis cette branche tant que la PR est en cours.
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained("stabilityai/stable-cascade-prior", torch_dtype=torch.bfloat16).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained("stabilityai/stable-cascade", torch_dtype=torch.float16).to(device)
prompt = "Anthropomorphic cat dressed as a pilot"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#Maintenant decoder_output est une liste contenant vos images PILUtilisations
Usage direct
Le modèle est destiné pour l'instant à des fins de recherche. Les domaines et tâches de recherche possibles incluent
La recherche sur les modèles génératifs.
Le déploiement sécurisé de modèles pouvant générer du contenu nuisible.
L'analyse et la compréhension des limites et biais des modèles génératifs.
La génération d’œuvres d'art et l'utilisation dans le design et d'autres processus artistiques.
Applications dans des outils éducatifs ou créatifs.
Les usages exclus sont décrits ci-dessous.
Usages hors scope
Le modèle n'a pas été entraîné pour représenter fidèlement des personnes ou des événements,
et par conséquent, utiliser ce modèle pour générer un tel contenu est hors du cadre des capacités de ce modèle.
Le modèle ne doit pas être utilisé d'une manière qui viole la Politique d'utilisation acceptable de Stability AI.
Limitations et biais
Limitations
Les visages et les personnes en général peuvent ne pas être générés correctement.
La partie auto-encodage du modèle est imparfaite.
Recommandations
Le modèle est destiné uniquement à des fins de recherche.
Comment débuter avec le modèle

Détails du modèle
Type de modèle
Modèle de base
Version du modèle
Hash du modèle
Créateur
Discussion
Veuillez vous log in pour laisser un commentaire.
Collection de modèles - Stable Cascade
Images par Stable Cascade - base
Images avec anime










Images avec art










Images avec modèle de base

Images avec logo










