AlbedoBase XL - v1.3
Immagini in evidenza





Prompt Negativi Consigliati
strabismus
Parametri Consigliati
samplers
steps
cfg
resolution
vae
Suggerimenti
Se la generazione dell'immagine non produce risultati, prova a passare a CLIP SKIP 2 o modifica leggermente il prompt cambiando ordine o parole.
L'uso di prompt in forma di frasi tende a migliorare la qualità delle immagini più rispetto ai prompt con lista di tag.
Lasciare il campo del prompt negativo vuoto spesso dà risultati migliori.
Controlla la griglia delle specifiche per le impostazioni ottimali prima di usare il modello.
Sperimenta con alcuni prompt negativi specifici come 'strabismo' per risolvere problemi come occhi asimmetrici o pixelazione.
Punti Salienti della Versione
v1.3
Per illustrare la qualità legata alla casualità del modello, ho standardizzato il valore seed a '9' per tutte le immagini di demo destinate al campionamento e ne ho generato immediatamente.
Soprattutto con questa versione, a causa dell'impatto significativo dei prompt negativi, lasciare il campo prompt negativo vuoto dovrebbe produrre la migliore qualità.
La griglia delle specifiche(438,7 MB): scarica
Come puoi vedere, all'aumentare del numero di Steps, diventa disponibile per tutti i sampler e la qualità migliora.
Grazie all'effetto del LoRA che ho sviluppato e fuso, come descritto di seguito, usare prompt in forma di frasi anziché tag (lista di parole) è direttamente correlato al miglioramento della qualità.
Ho fuso 45 checkpoint e 7 LoRA. Successivamente ho fuso AlbedoBase v0.4 e v0.3 in ordine, meno del 0~5%, per risvegliare i modelli fusi diluiti diventati obsoleti.
Tra le 7 LoRA, una è creata da me. Consiste nell'analizzare e annotare didascalie per un totale di 174 foto pittoriche di alta qualità usando GPT4-V. La fusione di questa LoRA ha prodotto immagini sorprendentemente chiare e una comprensione impressionante dei prompt.
Le mie LoRA auto-create sono disponibili esclusivamente all'acquisto per i miei supporter Ko-fi al livello Creative o superiore. Prevedo di rilasciare sempre più aggiornamenti in futuro. I prezzi variano da 10 a 50 dollari.
Sponsor del Creatore
Se hai trovato valore nel modello, considera di offrire il tuo supporto. Il tuo contributo sarà interamente dedicato all'avanzamento della comunità SDXL.
Se hai trovato valore nel modello, considera di offrire il tuo supporto. Il tuo contributo sarà interamente dedicato all'avanzamento della comunità SDXL.
🙋🏼♂️ unisciti a noi (discord) ㅤ|ㅤ 🛒 acquistaㅤ |ㅤ 🌱 dona
AlbedoBase XL (SFW&NSFW)
Il refiner non è necessario e il VAE è incluso.
OBIETTIVO
Stable Diffusion XL ha 3,5 miliardi di parametri (escludendo il Refiner), circa 3,6 volte più di SD v1.5. Credo che questo non sia solo un numero, ma un valore che può portare a un miglioramento significativo delle prestazioni.
È da tempo che abbiamo realizzato che le prestazioni complessive di SD v1.5 sono migliorate oltre ogni immaginazione grazie ai contributi esplosivi della nostra comunità. Perciò sto lavorando per completare questo modello AlbedoBase XL per riprodurre in modo ottimale il miglioramento delle prestazioni avvenuto in v1.5 anche in questa versione XL.
Il mio obiettivo è testare direttamente le prestazioni di tutti i Checkpoint e LoRA pubblicamente caricati su Civitai e unire solo le risorse giudicate ottimali dopo diversi filtri. Questo supererà le prestazioni dell'AI di generazione immagini di aziende come Midjourney.
Al momento, AlbedoBase XL v3.1 Large ha fuso circa 200 checkpoint selezionati e 251 LoRA.
LOG
v3.1-Large
• Fusi oltre 50 ultime versioni selezionate di modelli SDXL usando lo script ricorsivo impiegato in V3.
La griglia delle specifiche(370,7 MB): scarica


v3-mini
Mi scuso sinceramente per avervi fatto aspettare così a lungo.
Ho affrontato questioni personali e, mentre lavoravo sulla nuova versione, ho anche avuto problemi di salute. Ancora ora, mentre scrivo, sto combattendo con queste difficoltà.
Ho sentito che una breve aggiornamento non sarebbe stato sufficiente, quindi vi chiedo comprensione mentre condivido questo messaggio più dettagliato.
Da quando è uscita la versione 2.0, mi sto dedicando allo studio del deep learning in modo indipendente. Non ho una laurea formale e, a parte una modesta attitudine alla programmazione, il mio background è nelle arti. Di conseguenza, mi manca la base matematica e scientifica per ottenere grandi progressi, dato il tempo e lo sforzo investiti. Tuttavia, questa esperienza di studio e ricerca autonoma è stata un tesoro inestimabile nella mia vita.
Recentemente ho avuto un'idea che potrebbe essere una svolta significativa. Dopo aver rielaborato centinaia di formule e metodi dalla versione 2.0, sono riuscito a sviluppare un algoritmo piuttosto interessante e di successo. Il processo di fusione dei modelli si è basato su SDXL1.0 e SD1.5, insieme ad altri modelli accuratamente selezionati. Questi sono stati categorizzati in cinque classificazioni principali: “ANIME,” “REALISMO,” “ARTISTICO,” “NSFW,” e “BASE,” e alimentati nell'algoritmo di fusione come dataset. Questo approccio ha prodotto risultati affascinanti.
Tuttavia, tanto impegnativo quanto è stato sviluppare l'algoritmo, nulla è stato più arduo della fase di test delle prestazioni. La mia salute fisica e mentale si è deteriorata notevolmente durante questo periodo, fino a capire che non potevo continuare da solo. Questo mi ha spinto a decidere di rilasciare questa versione.
Sono quindi entusiasta di annunciare il rilascio della tanto attesa versione AlbedoBaseXL V3 Mini. Sebbene questo modello fuso sia su scala più piccola, non è limitato a nessun ambito specifico e funziona egregiamente in vari domini. Ha il potenziale per servire come nuovo modello base per SDXL1.0. (Per riferimento, il mio algoritmo di fusione non è una “fusione lineare,” quindi può essere considerato essenzialmente un nuovo modello fine-tuned.)
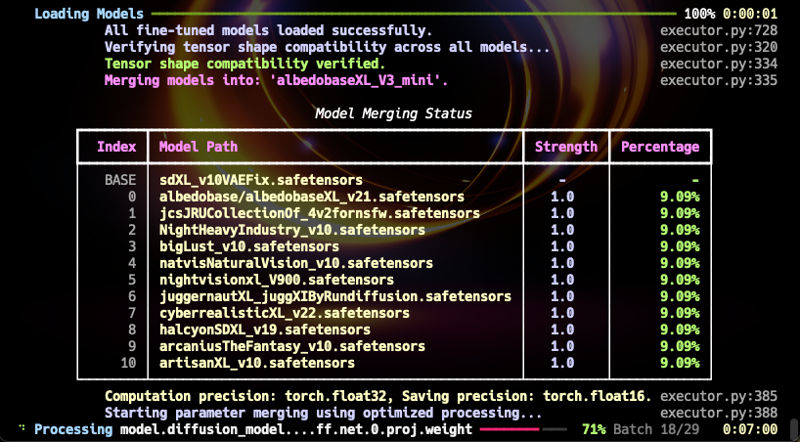
Questo modello, insieme ai modelli AlbedoBase esistenti, è versatile e supera tutte le versioni precedenti in ogni aspetto. (I contenuti NSFW, pur non essendo estremi, offrono una gamma più ampia di espressioni rispetto alle versioni precedenti come la v2.1. Un modello dedicato per la fusione NSFW sarà rilasciato in futuro.)
Da un altro punto di vista, ho notato che molti modelli condivisi hanno iniziato recentemente ad adottare licenze che vietano la fusione o la commercializzazione esterna. Questo è stato deludente, perché mi ha impedito di utilizzare alcuni modelli veramente eccellenti per la fusione.
Vorrei esprimere la mia profonda gratitudine agli sviluppatori di modelli che hanno fornito licenze gratuite, permettendo così che i loro modelli di alta qualità—frutto di notevoli tempi e sforzi—possano essere usati per la fusione.
Tornerò presto.
Attendo con ansia i vostri test delle prestazioni in un'ampia gamma di aree, inclusi ANIME, REALISMO, ARTISTICO, 2.5D, 3D e NSFW.
Come sviluppatori di modelli, noi piantiamo solo i semi. Siete voi, utenti e artisti dei modelli, a coltivarli e far fiorire i frutti.
Grazie, come sempre.
Per chi desidera supportare il mio lavoro con un piccolo contributo finanziario, considerate i link seguenti. Attualmente non posso assicurarmi un impiego e il mio futuro economico è incerto.
La griglia delle specifiche(380,5 MB): scarica


v2.1
Rifusione e aggiustamento da v0.1 a 2.0 usando il nuovo algoritmo di fusione e formula.
La griglia delle specifiche(424,5 MB): scarica

v2.0
Vorrei ringraziare tutti coloro che mi hanno aiutato nel progetto AlbedoBase XL Pre. Senza di voi, la data di rilascio sarebbe probabilmente stata molto più tardiva. Grazie di cuore!
Ho scritto uno script personalizzato per convergere insieme i modelli AlbedoBase XL esistenti. Allineando accuratamente i pesi di riga e colonna di tutti i blocchi U-NET e CLIP secondo una formula unica sviluppata da me.
Se incontri un bug nella generazione delle immagini (se non viene generato nulla), prova a passare a CLIP SKIP 2 o modifica leggermente il prompt! Potrebbero esserci combinazioni di prompt non riconosciute da CLIP. In tal caso, puoi cambiare l'ordine delle parole, usare parole diverse o, più semplicemente, modificare il CLIP SKIP. Lavorerò gradualmente per risolvere questi problemi in futuro come in v1.3.
La griglia delle specifiche(403,5 MB): scarica
v1.3
Per illustrare la qualità legata alla casualità del modello, ho standardizzato il valore seed a '9' per tutte le immagini di demo destinate al campionamento e ne ho generato immediatamente.
Soprattutto con questa versione, a causa dell'impatto significativo dei prompt negativi, lasciare il campo prompt negativo vuoto dovrebbe produrre la migliore qualità.
La griglia delle specifiche(438,7 MB): scarica

Come puoi vedere, all'aumentare del numero di Steps, diventa disponibile per tutti i sampler e la qualità migliora.
Grazie all'effetto del LoRA che ho sviluppato e fuso, come descritto di seguito, usare prompt in forma di frasi anziché tag (lista di parole) è direttamente correlato al miglioramento della qualità.
Ho fuso 45 checkpoint e 7 LoRA. Successivamente ho fuso AlbedoBase v0.4 e v0.3 in ordine, meno del 0~5%, per risvegliare i modelli fusi diluiti diventati obsoleti.
Tra le 7 LoRA, una è creata da me. Consiste nell'analizzare e annotare didascalie per un totale di 174 foto pittoriche di alta qualità usando GPT4-V. La fusione di questa LoRA ha prodotto immagini sorprendentemente chiare e una comprensione impressionante dei prompt.
Le mie LoRA auto-create sono disponibili esclusivamente all'acquisto per i miei supporter Ko-fi al livello Creative o superiore. Prevedo di rilasciare sempre più aggiornamenti in futuro. I prezzi variano da 10 a 50 dollari.
v1.2
Fusi gli ultimi 22 checkpoint.
La griglia delle specifiche(565,6 MB): scarica
v1.1
Stabilizzato.
Più dettagliato.
Se pensi di essere un utente avanzato, ti consiglio la versione 1.0. Se la versione 1.0 trova le impostazioni giuste, può produrre lavori molto più vividi.
La griglia delle specifiche(349,7 MB): scarica
v1.0
Fusi 106 LoRA.
Fusi 19 Checkpoint.
Il modello può produrre risultati diversi a seconda delle impostazioni scelte, quindi è importante controllare la griglia delle specifiche prima di usarlo.
Ho scoperto che l'uso di alcuni prompt negativi specifici può aiutare a risolvere problemi come occhi asimmetrici o immagini pixelate. La griglia delle specifiche può variare a seconda del tuo dispositivo CPU o GPU, quindi usala come riferimento generale. Sperimenta con alcuni prompt negativi per migliorare la qualità (es: strabismo). Ho trovato difficile soddisfare tutte le impostazioni allo stesso modo con l'aumento delle LoRA fuse. Tuttavia, vorrei che ti concentrassi su questo vantaggio nella versione 1.0, poiché può produrre lavori di qualità sorprendente in vari aspetti con le impostazioni giuste. Tornerò con una versione più stabile in futuro.
Puoi trovare valori utili per le impostazioni nelle demo o cercando altri.
Come sempre, è meglio lasciare il prompt negativo vuoto per ottenere i migliori risultati.
Questa v1.0 è stata molto lavoro, quindi sto prendendo una pausa. Spero ti piaccia usare il modello e, se lo fonde, condividilo su Civitai gratuitamente. Così potremo continuare a migliorarlo insieme.
La griglia delle specifiche(479,4 MB): scarica
v0.4
Fusi 132 LoRA.
Fusi 4 Checkpoint.
La griglia delle specifiche: scarica
v0.3
Migliorato in tutti i sampler.
Raggiunto realismo vivido.
Stabilizzato.
La griglia delle specifiche: scarica
v0.2
Miglioramenti significativi nella chiarezza e nei dettagli.
Migliorata l'implementazione di mani e piedi.
Miglioramenti estetici maggiori; composizione, astrazione, flusso, luce e colore, ecc.
v0.1
Dopo un fine-tuning appropriato sul modello SDXL1.0, ho meticolosamente e intenzionalmente fuso oltre 40 modelli di alta qualità pubblicamente disponibili su Civitai.
I test si sono concentrati principalmente sull'assicurare la massima qualità con il minimo numero di token nel prompt, e non è stato confermato quanto la qualità possa migliorare usando molti token. (Ti invito a fare i tuoi test e condividere i risultati)
Tipicamente, i risultati più belli si ottengono a metà strada tra realtà e animazione.
Tuttavia, usando un prompt appropriato, in generale non c’è nulla che non possa esprimere. (Affermo che possiede un grande valore come modello base che supera altri modelli in fusione. Comunque, tieni presente che questa è attualmente la v0.1)

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Parole addestrate
Creatore
Discussione
Per favore log in per lasciare un commento.






































