Animagine XL 4.0 - v4 Opt
Parole Chiave e Tag Correlati
Immagini in evidenza





Prompt Consigliati
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
Prompt Negativi Consigliati
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
Parametri Consigliati
samplers
steps
cfg
resolution
Suggerimenti
Usa didascalie basate su tag con il metodo di ordinamento dei tag per risultati migliori: 1girl/1boy/1other, nome del personaggio, serie, rating, altri tag, poi miglioramento della qualità.
Aggiungi tag di miglioramento della qualità alla fine del prompt: masterpiece, high score, great score, absurdres.
Usa prompt negativi raccomandati per evitare artefatti ed errori indesiderati.
Scala CFG ottimale tra 4 e 7, consigliata a 5.
Passi di campionamento ottimali tra 25 e 28, con 28 consigliati.
Sampler preferito è Euler Ancestral (Euler a).
Nota le limitazioni del modello come difficoltà con anatomia complessa e rendering di testo.
Personaggi recenti potrebbero avere minore accuratezza a causa di dati di addestramento limitati.
Punti Salienti della Versione
Con il rilascio di Animagine XL 4.0 Opt (Ottimizzato), il modello è stato ulteriormente perfezionato con un dataset aggiuntivo, migliorando le prestazioni per l'uso generale. Questo aggiornamento apporta diversi miglioramenti:
Migliore stabilità per output più coerenti
Anatomia migliorata con proporzioni più precise
Riduzione di rumore e artefatti nelle generazioni
Risolti problemi di bassa saturazione, risultando in colori più vivi
Migliore accuratezza dei colori per risultati più piacevoli visivamente
Sponsor del Creatore
Sostieni lo sviluppo di Animagine XL
- Fai una donazione ETH/USDT a
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - GitHub Sponsors: https://github.com/sponsors/cagliostrolab/
- Unisciti alla community su Discord: https://discord.gg/cqh9tZgbGc
Si prega di leggere la nostra Guida dettagliata per il prompting su Blog di Cagliostrolab
Panoramica
Animagine XL 4.0, anche stilizzato come Anim4gine, è il modello SDXL finemente ottimizzato a tema anime definitivo e l'ultima versione della serie Animagine XL. Pur essendo una continuazione, il modello è stato riaddestrato partendo da Stable Diffusion XL 1.0 con un enorme dataset di 8,4 milioni di immagini in stile anime da varie fonti con cutoff di conoscenza al 7 gennaio 2025 e finemente ottimizzato per circa 2650 ore GPU. Come nella versione precedente, questo modello è stato addestrato utilizzando il metodo di ordinamento dei tag per l'identità e lo stile.
Con il rilascio di Animagine XL 4.0 Opt (Ottimizzato), il modello è stato ulteriormente migliorato con un dataset aggiuntivo, migliorando la stabilità, la precisione anatomica, la riduzione del rumore, la saturazione dei colori e la precisione complessiva dei colori. Questi miglioramenti rendono Animagine XL 4.0 Opt più coerente e visivamente accattivante, pur mantenendo la qualità distintiva della serie.
Registro delle modifiche
- 2025-02-13 – Aggiunti Animagine XL 4.0 Opt e Animagine XL 4.0 Zero
Migliore stabilità per output più coerenti
Anatomia migliorata con proporzioni più accurate
Riduzione di rumore e artefatti nelle generazioni
Risolti problemi di bassa saturazione, con colori più intensi
Migliorata precisione dei colori per risultati più gradevoli
- 2025-01-24 – Prima versione
Dettagli del modello
Sviluppato da: Cagliostro Research Lab
Tipo di modello: Modello generativo testo-immagine basato su diffusione
Licenza: CreativeML Open RAIL++-M
Descrizione del modello: Modello utilizzabile per generare e modificare immagini specificamente a tema anime basate su prompt testuali
Fine-tuned da: Stable Diffusion XL 1.0
Linee guida per l'uso
Il riepilogo è visibile nell'immagine delle linee guida per il prompt.

1. Struttura del Prompt
Il modello è stato addestrato con didascalie basate su tag e il metodo di ordinamento dei tag. Usa questo schema strutturato:
1girl/1boy/1other, nome del personaggio, da quale serie, rating, tutto il resto in qualsiasi ordine e termina con miglioramento della qualità
2. Tag per il miglioramento della qualità
Aggiungi questi tag alla fine del prompt:
masterpiece, high score, great score, absurdres
3. Prompt negativo raccomandato
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. Impostazioni ottimali
CFG Scale: 4-7 (consigliato 5)
Passi di campionamento: 25-28 (consigliato 28)
Sampler preferito: Euler Ancestral (Euler a)
5. Risoluzioni consigliate
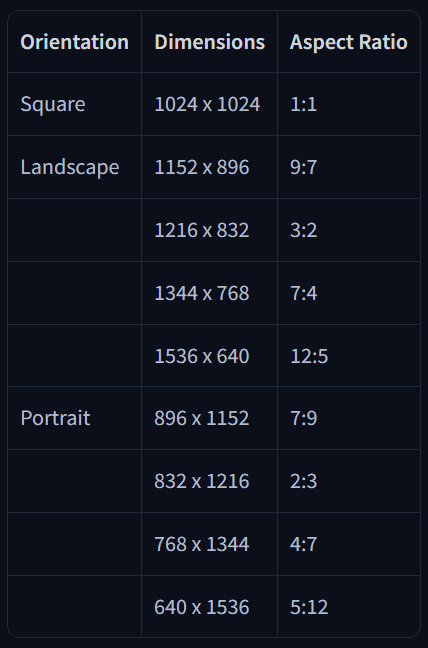
6. Esempio di struttura finale del prompt
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
Tag Speciali
Il modello supporta vari tag speciali che possono essere utilizzati per controllare diversi aspetti del processo di generazione dell’immagine. Questi tag sono attentamente ponderati e testati per fornire risultati coerenti attraverso prompt diversi.
Tag di qualità
I tag di qualità sono controlli fondamentali che influenzano direttamente la qualità generale e il livello di dettaglio dell’immagine. Tag di qualità disponibili:
masterpiecebest qualitylow qualityworst quality
Tag di punteggio
I tag di punteggio offrono un controllo più sfumato sulla qualità dell’immagine rispetto ai tag di qualità di base. Hanno un impatto più forte nel guidare la qualità dell’output in questo modello. Tag di punteggio disponibili:
high scoregreat scoregood scoreaverage scorebad scorelow score
Tag Temporali
I tag temporali permettono di influenzare lo stile artistico basato su specifici periodi temporali o anni. Possono essere utili per generare immagini con caratteristiche artistiche specifiche di un’epoca. Tag anni supportati:
year 2005year {n}year 2025
Tag di valutazione
I tag di valutazione aiutano a controllare il livello di sicurezza del contenuto delle immagini generate. Questi tag devono essere usati responsabilmente e in conformità con le leggi e le politiche della piattaforma. Valutazioni supportate:
safesensitivensfwexplicit
Informazioni sull’addestramento
Il modello è stato addestrato utilizzando hardware all’avanguardia e iperparametri ottimizzati per garantire l’output di massima qualità. Di seguito le specifiche tecniche dettagliate e i parametri usati durante il processo di addestramento:

Ringraziamenti
Questo progetto a lungo termine non sarebbe stato possibile senza il lavoro pionieristico, i contributi innovativi e la documentazione completa forniti da Stability AI, Novel AI e Waifu Diffusion Team. Siamo particolarmente grati per il grant iniziale di Main che ci ha permesso di progredire oltre la V2. Per questa iterazione desideriamo esprimere sincera gratitudine a tutta la community per il supporto continuo, in particolare:
Moescape AI: nostro partner prezioso nella distribuzione e testing del modello
Lesser Rabbit: per i finanziamenti essenziali a supporto di calcoli e ricerca
Kohya SS: per lo sviluppo del completo framework open-source di addestramento
discus0434: per la creazione del noto open-source Aesthetic Predictor 2.5
Tester iniziali: per la dedizione nel fornire feedback critici e assicurazione qualità approfondita
Contributori
Estendiamo il nostro sentito ringraziamento ai membri del team dedicati che hanno contribuito significativamente a questo progetto, inclusi ma non limitati a:
Modello
Gradio
Relazioni, finanza e assicurazione qualità
Dati
Le raccolte fondi sono riaperte!
Siamo entusiasti di introdurre nuovi metodi di raccolta fondi tramite GitHub Sponsors per supportare l’addestramento, la ricerca e lo sviluppo del modello. Il tuo supporto ci aiuta a spingere i limiti di ciò che è possibile con l’IA.
Puoi aiutarci con:
Donazioni: Contribuisci tramite ETH o USDT all'indirizzo sottostante.
Condivisione: Diffondi la voce sui nostri modelli e condividi le tue creazioni!
Feedback: Dicci come possiamo migliorare.
Indirizzo per donazioni:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
GitHub Sponsor: https://github.com/sponsors/cagliostrolab/
Perché usiamo le criptovalute?
Quando abbiamo inizialmente aperto la raccolta fondi tramite Ko-fi e l’uso di PayPal come metodo di prelievo, il nostro account PayPal è stato segnalato e infine bannato, nonostante i nostri sforzi per spiegare lo scopo del progetto. Sfortunatamente, questo ci ha costretto a rimborsare tutte le donazioni e ci ha lasciati senza un modo affidabile per ricevere supporto. Per evitare questi problemi e garantire trasparenza, abbiamo ora adottato le criptovalute come metodo di raccolta fondi.
Vuoi donare in valuta non cripto?
Sebbene abbiamo avuto una brutta esperienza con PayPal e tu voglia supportarci preferendo non usare criptovalute, sentiti libero di contattarci tramite Discord Server per metodi alternativi di donazione.
Unisciti al nostro Discord Server
Sentiti libero di unirti al nostro server Discord: https://discord.gg/cqh9tZgbGc
Limitazioni
Formato del prompt: Limitato a prompt testuali basati su tag; input in linguaggio naturale potrebbe non essere efficace
Anatomia: Può avere difficoltà con dettagli anatomici complessi, in particolare pose delle mani e conteggio delle dita
Generazione di testo: Rendering di testo nelle immagini attualmente non supportato e non raccomandato
Personaggi nuovi: Personaggi recenti potrebbero avere minore accuratezza dovuta a dati di addestramento limitati disponibili
Più personaggi: Scene con più personaggi potrebbero richiedere un’accurata progettazione del prompt
Risoluzione: Risoluzioni più alte (es. 1536x1536) potrebbero mostrare degradazione poiché l’addestramento ha usato la risoluzione originale di SDXL
Coerenza dello stile: Potrebbe richiedere tag specifici dello stile perché l’addestramento si è concentrato più sulla preservazione dell’identità che sulla coerenza stilistica
Licenza
Questo modello adotta la licenza originale CreativeML Open RAIL++-M License di Stability AI senza modifiche o restrizioni aggiuntive. I termini della licenza rimangono esattamente come specificato nella licenza SDXL originale, che include:
✅ Permessi: Uso commerciale, modifiche, distribuzioni, uso privato
❌ Proibizioni: Attività illegali, generazione di contenuti dannosi, discriminazione, sfruttamento
⚠️ Requisiti: Includere copia della licenza, dichiarare modifiche, preservare avvisi
📝 Garanzia: Fornita "COSÌ COM’È" senza garanzie
Si prega di fare riferimento alla licenza SDXL originale per i termini e le condizioni completi e autorevoli.

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Creatore
Discussione
Per favore log in per lasciare un commento.
Collezione di Modelli - Animagine XL 4.0
Immagini di Animagine XL 4.0 - v4 Opt
Immagini con anime










Immagini con modello base

Immagini con sdxl


