Anime Illust Diffusion XL - v0.5-alpha
Parole Chiave e Tag Correlati
Immagini in evidenza





Prompt Consigliati
frieren from sousou no frieren,impasto style,beautiful color, detailed, aesthetic
best quality,masterpiece,vivid color,1girl,solo,bangs
Prompt Negativi Consigliati
worst quality:1.3,low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxl_neg
Parametri Consigliati
samplers
steps
cfg
resolution
vae
other models
Parametri Consigliati per Alta Risoluzione
denoising strength
Suggerimenti
Riduci il peso delle parole trigger di stile artista, es. (by xxx:0.6).
Ordina i tag del prompt per risultati migliori.
Usa il VAE del modello o sdxl-vae.
Punti Salienti della Versione
Aggiunti 143 nuovi trigger. Questa versione è un beta test di AIDXLv0.5. I nuovi stili non sono stabili. Consiglio AIDXLv0.41 per un'esperienza migliore.
Aggiunti 143 nuovi trigger. Questa versione è una beta di AIDXLv0.5. I nuovi stili non sono stabili. Raccomando AIDXLv0.41 per una miglior esperienza.
Sponsor del Creatore
Sponsorizzazione potenza di calcolo: Grazie alla comunità @NieTa (捏Ta (nieta.art)) per il supporto delle risorse computazionali;
Supporto dati: Grazie a @KirinTea_Aki (KirinTea_Aki Creator Profile | Civitai) e @Chenkin (Civitai | Share your models) per offrire un grande supporto dati;
Non ci sarebbe stata la versione 0.7 senza di loro.
Introduzione al Modello (Parte in inglese)
I Contenuti
In questa introduzione, imparerai riguardo a:
Informazioni sul modello (vedi Sezione II);
Istruzioni per l'uso (vedi Sezione III);
Parametri di addestramento (vedi Sezione IV);
Lista delle Parole Trigger (vedi Appendice Parte A)
II AIDXL
Anime Illustration Diffusion XL, o AIDXL, è un modello dedicato alla generazione di illustrazioni anime stilizzate. Disposne di oltre 800 stili di illustrazioni incorporati (con aggiornamenti continui), attivati da parole trigger specifiche (vedi Appendice A).
Vantaggi:
Composizione flessibile rispetto alle pose AI tradizionali.
Dettagli abili invece del caos disordinato.
Riconosce meglio i personaggi anime.
III Guida Utente
1 Uso di base
1.1 Prompt
Parole trigger: Aggiungi le parole trigger fornite in Appendice A per stilizzare l'immagine. Parole trigger adatte miglioreranno notevolmente la qualità;
Si raccomanda di ridurre il peso delle parole trigger di stile artista, es. (by xxx:0.6).
Ordinamento semantico: Ordinare i tag o le frasi del prompt aiuterà il modello a comprendere il significato.
Ordine consigliato dei tag: Parola trigger (by xxx) -> personaggio (una ragazza chiamata frieren dalla serie sousou no frieren) -> razza (elfo) -> composizione (cowboy shot) -> stile (impasto stile) -> tema (tema fantasy) -> ambiente principale (nella foresta, di giorno) -> sfondo (sfondo sfumato) -> azione (seduta a terra) -> espressione (senza espressione) -> caratteristiche principali (capelli bianchi) -> caratteristiche corporee (code di cavallo doppie, occhi verdi, labbro diviso) -> abbigliamento (vestito bianco) -> accessori abbigliamento (volant) -> altri oggetti (un gatto) -> ambiente secondario (erba, sole) -> estetica (colori belli, dettagliato, estetico) -> qualità ((migliore qualità:1.3))
Prompt negativi: (peggiore qualità:1.3), bassa qualità, bassa risoluzione, disordinato, astratto, brutto, sfigurato, anatomia scorretta, bozza, mani deformate, dita fuse, firma, testo, multi viste
1.2 Parametri di Generazione
Risoluzione: Assicurarsi che il numero totale di pixel (=larghezza * altezza) sia circa 1024*1024 e che larghezza e altezza siano divisibili per 32, in questo caso AIDXL produrrà il miglior risultato. Ad esempio, 832x1216 (2:3), 1216x832 (3:2) e 1024x1024 (1:1), ecc.
Sampler e passi: Usa il sampler "Euler Ancester", chiamato Euler A nel webui. Campionati circa ~28 passi con 7 a 9 CFG Scale.
'Raffina': L'immagine generata da text2image a volte è sfocata, in tal caso è necessario 'raffinarla' usando image2image o inpainting ecc.
Per semplici ingrandimenti, puoi fare riferimento a: Upscale to huge sizes and add detail with SD Upscale, it's easy! : r/StableDiffusion (reddit.com)
Altri componenti: Non è necessario usare modelli refiner. Usa il VAE del modello stesso o
sdxl-vae.
Q: Come riprodurre la copertina del modello? Perché non riesco a ottenere la stessa immagine della copertina usando gli stessi parametri di generazione?
A: Perché i parametri di generazione mostrati sulla copertina NON sono i suoi parametri di text2image , ma quelli di image2image (per ingrandire). L'immagine base è per lo più generata dal sampler Euler Ancester piuttosto che dal DPM sampler.
2 Uso speciale
2.1 Stili generalizzati
Dalla versione 0.7, AIDXL riassume diversi stili simili e introduce parole trigger di stile generalizzato. Queste parole trigger rappresentano ciascuna una categoria comune di stile di illustrazione animata. Si noti che le parole trigger di stile generali non sempre corrispondono al significato artistico che il loro significato letterale indica, ma sono parole trigger speciali ridefinite.
2.2 Personaggi
Dalla versione 0.7, AIDXL ha potenziato l'addestramento per i personaggi. L'effetto di alcune parole trigger per personaggi può già raggiungere l'effetto di Lora, e può separare bene il concetto del personaggio dal proprio abbigliamento.
Il metodo di attivazione del personaggio è: {personaggio} \({copyright}\). Ad esempio, per attivare l'eroina Lucy nell'animazione "Cyberpunk: Edgerunners", usa lucy \(cyberpunk\); per attivare il personaggio Gan Yu nel gioco "Genshin Impact", usa ganyu \(genshin impact\). Qui, "lucy" e "ganyu" sono nomi dei personaggi, "\(cyberpunk\)" e "\(genshin impact\)" sono le origini dei personaggi corrispondenti, e le parentesi sono escape con le barre "\" per evitare che vengano interpretate come tag pesati. Per alcuni personaggi, la parte dei diritti d'autore non è necessaria.
Dalla versione v0.8, esiste un altro metodo di attivazione più facile: un {ragazza/ragazzo} chiamato {personaggio} dalla serie {copyright}.
Per la lista delle parole trigger per personaggi, si prega di fare riferimento a: selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co). Inoltre, alcune parole trigger extra non menzionate in questo documento potrebbero essere incluse.
Alcuni personaggi richiedono un passaggio di attivazione extra. Quando si usa, se il personaggio non può essere completamente ricreato con una singola parola trigger, è necessario aggiungere al prompt le caratteristiche principali del personaggio.
AIDXL supporta il cambio d'abito dei personaggi. Le parole trigger dei personaggi di solito non includono il concetto delle caratteristiche dell'abbigliamento del personaggio. Se vuoi aggiungere l'abbigliamento del personaggio, devi aggiungere il tag dell'abbigliamento nelle parole del prompt. Ad esempio, silver evening gown, plunging neckline dà il vestito del personaggio St. Louis (Luxurious Wheels) dal gioco Azur Lane. Allo stesso modo, puoi aggiungere i tag dell'abbigliamento di qualsiasi personaggio a quelli di altri personaggi.
2.3 Tag di Qualità
I tag di Qualità e estetici sono formalmente addestrati. Inserirli nei prompt influirà sulla qualità dell'immagine generata.
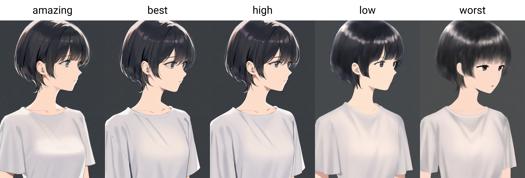
Dalla versione 0.7, AIDXL addestra ufficialmente ed introduce tag di qualità. Le qualità sono divise in sei livelli, dal migliore al peggiore: amazing quality, best quality, high quality, normal quality, low quality e worst quality.
Si consiglia di aggiungere peso extra ai tag di qualità, ad es. (amazing quality:1.5).
2.4 Tag Estetici
Dalla versione 0.7 sono stati introdotti tag estetici per descrivere le caratteristiche estetiche speciali delle immagini.
2.5 Fusione di Stili
Puoi unire alcuni stili nel tuo stile personalizzato. "Unire" in realtà significa usare più parole trigger di stile contemporaneamente. Ad esempio, chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Alcuni suggerimenti:
Controlla il peso e l'ordine degli stili per regolare lo stile finale.
Aggiungi alla fine del prompt piuttosto che all'inizio.
IV Strategia e Parametri di Addestramento
AIDXLv0.1
Usando SDXL1.0 come modello base, circa 22k immagini etichettate per addestrare circa 100 epoche con scheduler coseno a learning rate di 5e-6 e numero di cicli = 1 per ottenere modello A. Poi, con learning rate di 2e-7 e altri parametri uguali per ottenere modello B. Il modello AIDXLv0.1 è ottenuto fondendo i modelli A e B.
AIDXLv0.51
Strategia di Addestramento
Riprendi l'addestramento da AIDXLv0.5, ci sono tre fasi di training in pipeline una dopo l'altra:
Addestramento con didascalie lunghe: usa l'intero dataset, con alcune immagini didascalate manualmente. Avvia il training sia di U-Net sia del text encoder con AdamW8bit optimizer, alto learning rate (circa 1.5e-6) con scheduler coseno. Ferma il training quando il learning rate scende sotto una soglia (circa 5e-7).
Addestramento con didascalie corte: riprendi il training dall'output del passo 1 con stessi parametri e strategia ma dataset con didascalie più corte.
Fase di raffinamento: prepara un sottoinsieme del dataset del passo 1 che contiene immagini di alta qualità scelte manualmente. Riprendi il training dall'output del passo 2 con low learning rate (circa 7.5e-7), con scheduler coseno con restart da 5 a 10 giri. Allena fino a ottenere un risultato esteticamente buono.
Parametri fissi dell'addestramento
Nessun rumore extra come offset di rumore.
Min snr gamma = 5: accelera l'addestramento.
Precisione bf16 completa.
AdamW8bit optimizer: un equilibrio tra efficienza e prestazioni.
Dataset
Risoluzione: 1024x1024 risoluzione totale (= altezza per larghezza) con strategia di bucketing ufficiale modificata di SDXL.
Didascalie: generate tramite modello WD14-Swinv2 con soglia 0.35.
Ritaglio ravvicinato: taglia le immagini in più primi piani. Utile per immagini grandi o rare.
Parole trigger: mantieni il primo tag delle immagini come parole trigger.
AIDXLv0.6
Strategia di Addestramento
Riprendi l'addestramento da AIDXLv0.52, ma con strategia di ripetizione adattiva - per ogni immagine con didascalia nel dataset, incrementa il numero di ripetizioni durante il training soggetto a le seguenti regole:
Regola 1: più alta è la qualità dell'immagine, maggiore il numero di ripetizioni;
Regola 2: se l'immagine appartiene a una classe di stile:
Se la classe non è ancora adattata o è sottoadattata, allora aumenta manualmente il numero di ripetizioni della classe, o aumentalo automaticamente affinché il numero totale di ripetizioni dei dati nella classe raggiunga un certo valore preset, attorno a 100.
Se la classe è già adattata o soveradattata, allora riduci manualmente il numero di ripetizioni della classe forzandone il numero a 1 e scartala se la qualità è bassa.
Regola 3: il numero di ripetizioni è limitato a non superare una soglia, attorno a 10.
Questa strategia ha i seguenti vantaggi:
Protegge le informazioni originali del modello dall’addestramento nuovo, mantenendo la stessa idea dell'immagine regolarizzata;
Rende l'impatto dei dati di addestramento più controllabile;
Bilancia l'addestramento tra classi diverse motivando quelle non ancora adattate e prevenendo l'overfitting su quelle già adattate;
Risparmia significativamente risorse computazionali, e rende molto più facile aggiungere nuovi stili al modello.
Parametri fissi dell'addestramento
Stessi di AIDXLv0.51.
Dataset
Il dataset di AIDXLv0.6 è basato su AIDXLv0.51. Inoltre, si applicano le seguenti ottimizzazioni:
Ordinamento semantico delle didascalie: ordina i tag delle didascalie per ordine semantico, es. "gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun".
Rimozione duplicati nelle didascalie: rimuove tag duplicati, mantenendo quello che conserva più informazioni. I tag duplicati sono quelli con significati simili come "long hair" e "very long hair".
Tag extra: aggiunge manualmente tag aggiuntivi a tutte le immagini, es. "high quality", "impasto" ecc. Questo può essere fatto rapidamente con alcuni strumenti.
V Ringraziamenti Speciali
Sponsorizzazione risorse computazionali: Grazie alla comunità @NieTa (捏Ta (nieta.art)) per il supporto delle risorse computazionali;
Supporto dati: Grazie a @KirinTea_Aki (KirinTea_Aki Creator Profile | Civitai) e @Chenkin (Civitai | Share your models) per l'offerta di un grande supporto dati;
Non ci sarebbe stata la versione 0.7 senza di loro.
VI AIDXL vs AID
2023/08/08. AIDXL è stato addestrato sullo stesso set di addestramento di AIDv2.10, ma supera AIDv2.10. AIDXL è più intelligente e può fare molte cose che i modelli basati su SD1.5 non possono. Fa anche un ottimo lavoro nel distinguere concetti, apprendere dettagli dell'immagine, gestire composizioni difficili o addirittura impossibili per SD1.5 e AID. Complessivamente, ha un potenziale assoluto. Continuerò ad aggiornare AIDXL.
VII Sponsorizzazioni
Se ti piace il nostro lavoro, sei invitato a sostenerci tramite Ko-fi(https://ko-fi.com/eugeai) per supportare la nostra ricerca e sviluppo. Grazie per il tuo supporto~
Introduzione al Modello (Parte cinese)
I Indice
In questa introduzione, imparerai:
Introduzione al modello (vedi Parte II);
Guida all'uso (vedi Parte III);
Parametri di addestramento (vedi Parte IV);
Lista parole trigger (vedi Appendice A)
II Introduzione al Modello
Anime Illust Diffusion XL, chiamato anche AIDXL, è un modello dedicato a generare illustrazioni in stile anime. Integra oltre 800 stili (in continuo aumento) attivati da specifiche parole trigger (vedi Appendice A).
Vantaggi: composizione audace, senza pose artificiali, soggetto evidente, senza troppi dettagli disordinati, conosce molti personaggi anime (attivati dai nomi in romaji dei personaggi, es. “ayanami rei” corrisponde a “綾波麗”, “kamado nezuko” a “祢豆子”).
III Guida all'Uso (in continua evoluzione)
1 Uso Base
1.1 Scrittura del Prompt
Usa parole trigger: usa le parole trigger nell'Appendice A per stilizzare l'immagine. Le parole adatte migliorano notevolmente la qualità;
Taggare il prompt: usa tag nel prompt per descrivere l'oggetto da generare;
Ordinare il prompt: ordinare le parole aiuta il modello a capire il significato. Ordine consigliato:
Parola trigger (by xxx)->protagonista (1girl)->personaggio (frieren)->razzas (elf)->composizione (cowboy shot)->stile (impasto)->tema (fantasy)->ambiente principale (foresta, giorno)->sfondo (gradient background)->azione (seduta)->espressione (senza espressione)->caratteristiche principali (capelli bianchi)->caratteristiche corpo (code doppie, occhi verdi, labbro diviso)->abbigliamento (vestito bianco)->accessori abbigliamento (volant)->altri oggetti (bacchetta magica)->ambiente secondario (erba, sole)->estetica (colori belli, dettagliato, estetico)->qualità (best quality)
Prompt negativi: peggiore qualità, bassa qualità, bassa risoluzione, disordinato, astratto, brutto, sfigurato, anatomia sbagliata, mani deformate, dita fuse, firma, testo, viste multiple
1.2 Parametri di Generazione
Risoluzione: assicurati che la risoluzione totale dell'immagine (altezza×larghezza) sia intorno a 1024×1024 e che larghezza e altezza siano multipli di 32. Es. 832x1216 (3:2), 1216x832 (3:2), 1024x1024 (1:1).
Non usare "Clip Skip", ossia Clip Skip = 1.
Campionatore e passi: usa il campionatore “euler_ancester” (Euler A nel webui), 28 passi circa con CFG Scale 7.
Non serve usare modelli rifinitori (Refiner).
Usa VAE base o sdxl-vae.
2 Uso Speciale
2.1 Stili Generalizzati
Versione 0.7 raggruppa stili simili e introduce parole trigger di stili generalizzati, che rappresentano categorie comuni di illustrazione anime, ridefinite come parole trigger speciali.
2.2 Personaggi
Versione 0.7 potenzia l'addestramento per personaggi. Alcuni trigger per personaggi raggiungono l'effetto Lora e separano bene concetto di personaggio e abbigliamento.
Il trigger è nome_personaggio \(opera\). Es: per Lucy di "Cyberpunk: Edgerunners" usa lucy \(cyberpunk\); per Gan Yu di "Genshin Impact" usa ganyu \(genshin impact\). Nomi e opere sono escape con "\" per evitare interpretazioni errate. Per alcuni personaggi l'opera non è necessaria.
Trigger personaggi: selected_tags.csv (huggingface.co).
Se un solo trigger non basta a riprodurre il personaggio, aggiungi le caratteristiche principali al prompt.
I trigger per personaggi di solito non includono vestiti. Per aggiungere vestiti, aggiungi i tag di abbigliamento nel prompt, es. silver evening gown, plunging neckline per St. Louis (Luxurious Wheels) di Azur Lane. Puoi anche mischiare abiti di personaggi diversi.
2.3 Tag di Qualità
Da 0.7 tag qualità ed estetici sono formalmente addestrati e influenzano la qualità delle immagini generate.
I livelli di qualità da migliore a peggiore sono: amazing quality, best quality, high quality, normal quality, low quality, worst quality.
Consigliato dare peso extra, es. (amazing quality:1.5).
2.4 Tag Estetici
Introdotti per descrivere caratteristiche estetiche speciali dell'immagine.
2.5 Fusione Stili
Puoi unire più stili nel tuo stile personalizzato, usando più parole trigger contemporaneamente, es. chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
Consigli:
Controlla peso e ordine per regolare lo stile.
Aggiungi alla fine del prompt.
3 Precauzioni
Usa modelli VAE, embeddings e Lora compatibili con SDXL. Nota: sd-vae-ft-mse-original non è un VAE per SDXL; EasyNegative, badhandv4 e embeddings negativi simili non sono per SDXL;
Per versioni 0.61 e inferiori: si raccomanda fortemente di usare embeddings negativi specifici del modello (scaricabili nella sezione Suggested Resources), poiché sono progettati per il modello e hanno effetto positivo;
Nuove parole trigger per ogni versione potrebbero avere effetti più deboli o instabili nelle versioni correnti.
IV Parametri di Addestramento
Basato su SDXL1.0, con circa 20k immagini etichettate, addestrato per circa 100 epoche con learning rate 5e-6 e scheduler coseno con 1 ciclo per ottenere modello A. Poi addestrato con learning rate 2e-7 e stessi parametri per ottenere modello B. Infine fuso modello A e B per ottenere AIDXLv0.1.
Altri parametri di addestramento riferirsi alla versione inglese.
V Ringraziamenti
Sponsorizzazione potenza di calcolo: Grazie alla comunità @捏Ta (捏Ta (nieta.art)) per il supporto potenza di calcolo;
Supporto dati: Grazie a @秋麒麟热茶 (KirinTea_Aki Creator Profile | Civitai) e a @风吟 (Chenkin Creator Profile | Civitai) per il grande supporto dati;
Senza di loro non ci sarebbe la versione 0.7.
VI Changelog
2023/08/08: AIDXL ha usato esattamente lo stesso set di training di AIDv2.10 ma supera AIDv2.10. AIDXL è più intelligente, fa molte cose che SD1.5 non può. Distinzione concetti, apprendimento dettagli, gestione composizioni difficili o impossibili per SD1.5, capacità quasi perfetta su stili che AID vecchio non gestiva completamente. In sintesi, ha un potenziale superiore a SD1.5, continuerò ad aggiornare AIDXL.
2024/01/27: La versione 0.7 aggiunge molto contenuto, la dimensione del dataset più che raddoppiata rispetto alla versione precedente.
Ho provato nuovi algoritmi di elaborazione tag per ottenere etichette soddisfacenti, es. ordinamento tag, randomizzazione gerarchica, separazione caratteristiche personaggi. Progetto: Eugeoter/sd-dataset-manager (github.com);
Per controllare l'addestramento, ho creato uno script di training custom basato su Kohya-ss;
Per controllare la fusione dei modelli di diverse generazioni, ho sviluppato algoritmi euristici di fusione; per mantenere sufficiente stilizzazione ho rinunciato alla fusione dei layer OUT di text encoder e UNET perché danneggiava stabilità ed estetica del modello;
Per filtrare dati, ho addestrato modelli di rilevamento watermark, classificazione immagini e punteggio estetico per pulire i dati.
VII Supportaci
Se ti piace il nostro lavoro, puoi supportarci su Ko-fi(https://ko-fi.com/eugeai) per sostenere la nostra ricerca e sviluppo. Grazie per il tuo supporto!
Appendice / 附录
A. Lista Parole Trigger Speciali / 特殊触发词列表
Parole trigger di stile artistico: Cliccami
Parole trigger di stile di pittura: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: Colori piatti, usa linee per descrivere luce e ombra
平涂:Colori piatti, usa linee e macchie di colore per descrivere luce e livelli
clean color: Stile tra flat color e flat-pasto. Colorazione semplice e ordinata.
色彩 pulito: stile tra flat color e flat-pasto. Colorazione semplice e ordinata.
celluloid: Colorazione anime
色彩赛璐璐:Colorazione anime
flat-pasto: Colore quasi piatto, usa gradiente per descrivere luci e ombre
flat-pasto: Colore quasi piatto, usa gradiente per luci e ombre
thin-pasto: Contorno sottile, usa gradiente e spessore della pittura per luce, ombra e livelli
thin-pasto: contorno sottile, usa gradiente e spessore vernice per luce, ombra e livelli
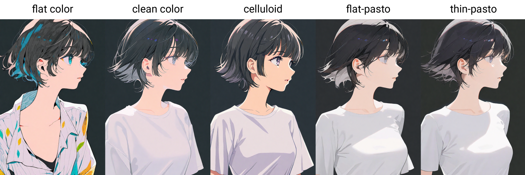
pseudo-impasto: Usa gradienti e spessore della pittura per luce, ombra e livelli
pseudo-impasto / semi-impasto: Usa gradienti e spessore per luce, ombra e livelli
impasto: Usa spessore della pittura per descrivere luce, ombra e gradazione
impasto: Usa spessore della pittura per luce, ombra e gradazioni
realistic
realistico
photorealistic: Ridefinito come stile più vicino al mondo reale
fotorealistico: ridefinito come stile vicino al mondo reale
cel shading: Stile di modellazione 3D anime
cel shading: stile 3D anime
3d

Parole trigger estetiche:
beautiful
bello
aesthetic: senso artistico leggermente astratto
estetico: senso artistico leggermente astratto
detailed
detagliato
beautiful color: uso sottile del colore
colori armoniosi: uso sottile del colore
lowres
messy: composizione o dettagli disordinati
disordinato: composizione o dettagli disordinati
Parole trigger di qualità: amazing quality, best quality, high quality, low quality, worst quality




Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Parole addestrate
Creatore
Discussione
Per favore log in per lasciare un commento.
Collezione di Modelli - Anime Illust Diffusion XL

Immagini di Anime Illust Diffusion XL - v0.5-alpha
Immagini con anime










Immagini con modello base

Immagini con illustrazione









