NEW ERA (New Esthetic Retro Anime) - Retro_v7.0R(VAE)
Parole Chiave e Tag Correlati
Immagini in evidenza


Prompt Consigliati
masterpiece,best quality,newest,official art,absurdres,highres,retro artstyle,1990s (style),1980s (style),2000s (style),anime screenshot,anime coloring,photo background
1girl
Prompt Negativi Consigliati
worst quality,low quality,(censored, bar censor, mosaic censoring, 4koma),multiple views,blurry,artistic error,bad anatomy,bad feet,wrong foot,bad hands,bad proportions,bad perspective,bad leg,bad arm,bad neck,bad vulva,bad reflection,bad ass,bad face,english text,chinese text,watermark,simple background
(worst quality, low quality, extra digits:1.4)
Parametri Consigliati
samplers
steps
cfg
resolution
Parametri Consigliati per Alta Risoluzione
upscaler
upscale
denoising strength
Suggerimenti
Usa lo scaling/upscale Latent (nearest-exact) per ridurre artefatti e preservare l'anatomia specialmente ad alte risoluzioni.
Applica Rate of caption dropout e Network dropout 0.05 per aumentare la coerenza anatomica in risoluzioni estreme.
Usa tag booru dettagliati dal sito danbooru nei prompt per migliorare i dettagli e ridurre la semplificazione.
Il prompt negativo 'sfondo semplice' aiuta a ridurre la semplificazione dell'immagine e migliora i dettagli per i modelli v-pred.
Non è necessario usare RescaleCFG con le versioni attuali dei modelli—compatibile con ComfyUI, Forge, Reforge e Automatic1111.
Installa l'estensione sd-webui-tagcomplete per completamento automatico dei tag da Danbooru per aiutare nella scrittura di prompt migliori.
Per risultati ottimali, inizia i prompt con 'capolavoro, migliore qualità'.
Punti Salienti della Versione
Una versione sperimentale con forte enfasi sullo stile retro
Riduzione dell'importanza dei prompt 1990s (style), 1980s \(style\), retro artstyle (Usa questi prompt solo se non hai abbastanza retro)
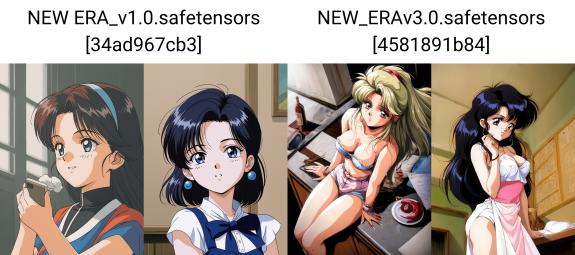
I personaggi di vecchi anime sono diventati più precisi
Sponsor del Creatore
Modello combinato degli anni '90, '80 e ora anni 2000
Ho ripristinato il mio PATREON (o meglio ne ho creato uno nuovo con il permesso di Patreon), se qualcuno vuole supportare ho caricato lì tutti i miei nuovi modelli e LoRA, che erano a pagamento su BOOSTY in un unico archivio. Sarò felice se anche solo vi iscrivete gratuitamente a Patreon, così saprò che vi interessa il mio lavoro e volete vedere aggiornamenti.
Informazioni sulla v5.0:
Si è deciso di implementare il modello basandosi su NAI-XL, un enorme salto di qualità rispetto all'ultima LORA. Poiché il modello è facile da affinare, ha un dettaglio migliorato dell'ambiente, degli occhi, anatomia migliorata, dita, varietà negli abiti e, cosa importante, contrasto ridotto. Ovvero, se nella versione 3.0 il contrasto era molto alto e risultava difficile usare LORA aggiuntive, bisognava usare cfg scale 2.5, ora cfg scale con lo stesso contrasto è circa 4, il che lascia margine per l'uso di LORA aggiuntive.
Usando lo scaling Latent (nearest-exact), ci sono molti meno artefatti (a volte assenti), indicando un significativo aumento della qualità e miglioramento dell'anatomia (quando si scala, l'anatomia viene conservata molto più spesso entro limiti corretti).
workflow (copia semplicemente le impostazioni, tutto tranne i prompt negativi, la migliore opzione è scritta sotto):
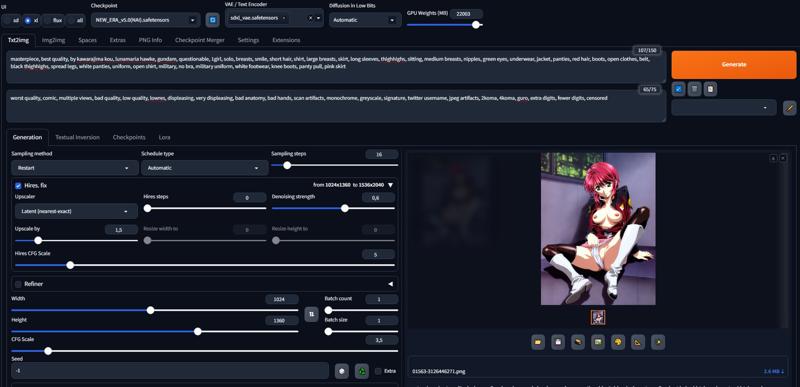 link all'immagine
link all'immagine
Informazioni su v6.3 & 6.69:
infine, ci è voluto un po' più tempo perché stavo rifacendo il fine tuning e allenando la lora per migliorare questo modello (e inoltre tutto il mio webui si è rotto dopo la reinstallazione di python e ho dovuto sistemare tutto)
Voglio dire subito che questo modello non è fatto su epsilon, ma su v-pred. V-pred (velocity prediction) e epsilon (ε-prediction) sono approcci matematici diversi per parametrizzare il rumore nei modelli di diffusione. Senza entrare nei dettagli, per anime, con le impostazioni giuste, vpred è migliore. Ma ha grossi problemi con il degrado dell'immagine e una convergenza leggermente peggiore a zero SNR (e vpred dovrebbe essere usato a 0 SNR). Ho risolto i problemi con forte contrasto e perdita di colore con le impostazioni giuste per la parametrizzazione v, disabilitando completamente l'SNR, regolando automaticamente il rumore invece dei valori fissi usati in SDXL, ecc. Non è stato facile, perché non ci sono dati concreti su internet, ma tramite tentativi ed errori e lettura chiara di studi scientifici su v-pred sono riuscito a comprendere alcune sottigliezze. In effetti l'originale NOOBAI con civitai è stato allenato in modo errato, il che è piuttosto divertente considerando il numero di persone che hanno aiutato con la configurazione e l'allenamento.
Infatti v-pred è molto esigente e non perfetto, si spera che lo sviluppo di approcci ibridi rimuova le limitazioni attuali, ma richiederà cambiamenti fondamentali nell'architettura dei modelli di diffusione.
Tornando ai modelli, perché due versioni? Ho notato un leggero peggioramento nei dettagli dei volti e degli occhi (non molto, ma comunque importante), quindi ho deciso di creare la versione 6.69, allenando inizialmente lo lore specializzato per migliorare i volti e regolare ulteriormente l'anatomia, che ha raggiunto un nuovo livello. Ma la versione 6.3 funziona visivamente meglio con le ombre circa del 5% nel 70-75% dei casi, cosa non significativa per molti, ma per me conta, quindi vi lascio scegliere. La versione 6.69 è migliore nell'anatomia, la 6.3 è leggermente migliore con le ombre. (prima posterò la 6.3)
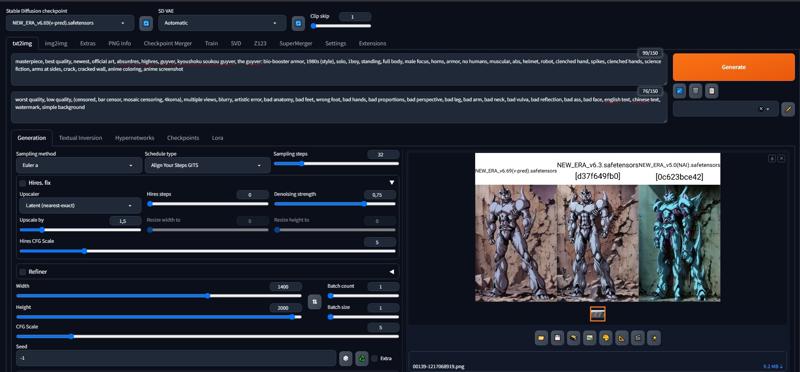
alcuni confronti tra versioni e versione 5.0 (Tutta l'arte è fatta senza upscaling a una risoluzione di 1024x1056):




 confronto dei sampler:
confronto dei sampler:

Ora parliamo di come questo modello gestisca la coerenza anatomica a risoluzioni estreme, rispetto ai modelli più vecchi, ho ottenuto questo aggiungendo Rate of caption dropout e Network dropout 0.05, che ha aumentato la consistenza diverse volte. Risoluzione 1400x2000 (nonostante questi risultati, questa risoluzione è estrema e non è raccomandata, è meglio usare l'upscale Latent (nearest-exact))



Il mio workflow
 Prompt davanti: capolavoro, migliore qualità, più recente, arte ufficiale, absurdres, highres
Prompt davanti: capolavoro, migliore qualità, più recente, arte ufficiale, absurdres, highres
Prompt negativi: peggiore qualità, bassa qualità, (censurato, censura a barre, mosaico, 4koma), molteplici viste, sfocato, errore artistico, cattiva anatomia, piedi brutti, piede sbagliato, mani brutte, cattive proporzioni, cattiva prospettiva, gamba brutta, braccio brutto, collo brutto, vulva brutta, riflesso brutto, fondoschiena brutto, faccia brutta, testo in inglese, testo cinese, filigrana, sfondo semplice
I prompt negativi sono standard, utilizzando tutti i difetti anatomici dal sito danbooru, tranne uno - sfondo semplice, ho notato che i modelli vpred tendono molto a semplificare, questo negativo aiuta e migliora il dettaglio complessivo.
RescaleCFG non è più necessario. Ora si può lavorare tranquillamente con comfi, forge, reforge e anche con l'automatic1111 standard.
Ricordate, i modelli vpred amano descrizioni dettagliate, usate i tag booru dal sito danbooru, i prompt regolari con 1 ragazza funzionano, ma l'immagine viene semplificata e standardizzata il più possibile, ciò è inevitabile in questi modelli, i modelli epsilon sono più diversi a riguardo, ma perdono su tutto il resto (assolutamente tutto).
Se non l'avete ancora fatto, installate l'estensione "sd-webui-tagcomplete". Mostra suggerimenti di completamento automatico per i tag riconosciuti da board "image booru" come Danbooru, usati principalmente per esplorare illustrazioni in stile Anime.
CFG Scale - qualsiasi, non ci sono più problemi con il contrasto eccessivo. Potete impostare 5-7 (valori standard).
Ah sì, quasi dimenticavo, ho aggiunto molte immagini Full HD degli anime dello studio ghibli degli anni
Anime aggiunti:
hotaru no haka
tonari no totoro
sen to chihiro no kamikakushi
howl no ugoku shiro
tenkuu no shiro laputa
NEW_ERA_v7.1 (NAI V-PRED) o PATREON (nuovo livello di arte retro, molto migliore delle versioni 6.3 e 6.69, più stabile, più bello, più facile da implementare)
















NEW ERA 4.0 (ILLUSTRIOUS-XL) / SDXL / LORA




 NEW ERA v1.0 (versione SDXL / PONY DIFFUSION che combina quasi tutti i miei modelli popolari con enfasi sull'anime retro)
NEW ERA v1.0 (versione SDXL / PONY DIFFUSION che combina quasi tutti i miei modelli popolari con enfasi sull'anime retro)
P.P.S. nuovo modello Anime Screencap / LORA / PONY DIFFUSION su Boosty


Ho realizzato un video su come ottenere la stessa qualità o semplicemente replicare la mia arte
Prompt negativi perfetti (ho usato tutti i prompt negativi dal danbooru):
Prompt negativi: peggiore qualità, bassa qualità, (censurato, censura a barre, mosaico, 4koma), molteplici viste, sfocato, errore artistico, cattiva anatomia, piedi brutti, piede sbagliato, mani brutte, cattive proporzioni, cattiva prospettiva, gamba brutta, braccio brutto, collo brutto, vulva brutta, riflesso brutto, fondoschiena brutto, faccia brutta, testo in inglese, testo cinese, filigrana, sfondo semplice
stile retro art - il token principale retro, presente in quasi tutte le immagini addestrate e fornisce risultati differenti negli anni '80-'90
1990s \(style\) - un marcatore molto forte che cambia significativamente lo stile del modello
1980s \(style\) - ha finalmente avuto un forte impatto sul risultato finale
2000s \(style\) - molto meglio di prima
anime screenshot, anime coloring - due token forti, funzionano bene, fanno sembrare l'immagine screenshot di anime, possono essere usati insieme per miglioramento o separatamente
photo background - rende l'ambiente realistico, lasciando i personaggi in stile anime (modificato per questo modello)
non dimenticare di scrivere all'inizio dei suggerimenti: capolavoro, migliore qualità
artisti:
di urushihara satoshi
di danmakuman
di kitazume hiroyuki
di kawarajima kou
di kotobuki tsukasa
di hirano toshihiro
nuovi
di mikimoto haruhiko
di kajishima masaki
di saotome nanda
di hakumai gen
P.S. 7.9V (basato su 1.5)
Uso sul servizio di generazione Civitai - la casella è selezionata, per qualche motivo non funziona
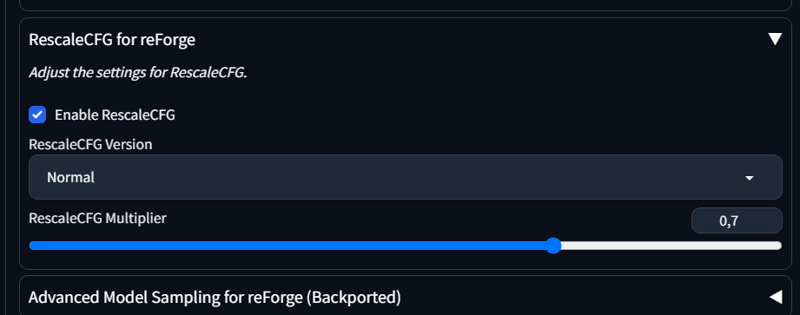
puoi usare RescaleCFG su reForge per ridurre il contrasto
Per favore pubblica il tuo lavoro con o senza commenti, mi aiuterà a migliorare. Grazie!
Se ti piace il mio lavoro, clicca sul cuore sopra, ne sarò felice :3

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Creatore
Discussione
Per favore log in per lasciare un commento.















































