Old Consistency V32 Lora [FLUX1.D/PDXL] - Femminile v1.1 - e500 PDXL
Immagini in evidenza


Prompt Consigliati
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
Prompt Negativi Consigliati
greyscale, monochrome, multiple views
Parametri Consigliati
samplers
steps
cfg
clip skip
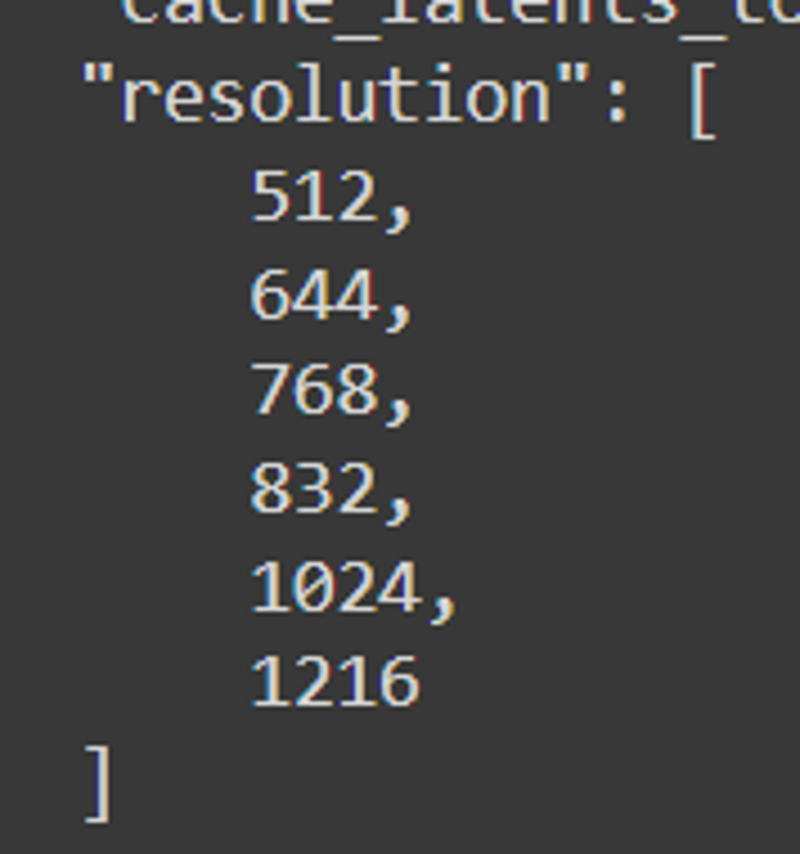
resolution
vae
other models
Parametri Consigliati per Alta Risoluzione
upscaler
upscale
denoising strength
Suggerimenti
Usa multipli loopback per migliorare fedeltà e coerenza delle immagini.
Attieniti a prompt standard e ordine logico per evitare aberrazioni.
Usa tag core di pose e angoli di visualizzazione come 'from front', 'from side', 'from above' per migliore accuratezza pose.
Evita l’uso di pose sessuali finché non sono adeguatamente raffinate.
Sperimenta con vari tag tratti per capelli, occhi, colori di abbigliamento e materiali.
L'ordine di caricamento influisce sui risultati quando si combinano modelli e LoRA.
La modalità sicura è attivata di default con opzioni per sbloccare contenuti discutibili ed espliciti.
Usa il sistema di tag pose e direttive per un miglior controllo di posizionamento personaggi e angoli camera.
Punti Salienti della Versione
Controlli di stabilità;
concetto - immagini/testate
corpo intero - 48/48
cowboy shot - 48/48
ritratto - 48/48
close-up - 48/48
**************************************
La prossima iterazione avrà un sottoinsieme di pose occhi indotto da singolo layer, taggato con angoli pose e includerà più immagini di occhi per ogni variazione per consolidare il burn. I colori occhi diretti probabilmente non sono necessari, la forma invece sembra cruciale secondo le mie ricerche.
occhi rossi - 39/48
corpo intero - 6/12
cowboy shot - 9/12
ritratto - 12/12
close-up - 12/12
occhi blu - 48/48
tutte pose - 12/12
occhi verdi - 48/48
tutte pose -12/12
occhi gialli - 42/48
corpo intero - 6/12 - non chiaro perché instabile.
occhi acqua - 48/48
tutte pose
occhi viola - 48/48
tutte pose
latex - 36/48
close-up - 5/12
ritratto - 7/12 - richiede ritratto e close-up
cowboy shot - 12/12
corpo intero - 12/12
lingerie - 36/48
close-up - 7/12
ritratto - 4/12 ? perché? - richiede immagini di ritratto diretto e close-up
cowboy shot - 11/12
corpo intero - 12/12
casual - 48/48
tutte pose - 12/12
bikini - 48/48
tutte pose - 12/12
vestito - 16/48
nessuna posa corrispondeva al vestito giusto se non con tag aggiuntivi -> serve taggare meglio i vestiti
La stabilità di output è stata molto più alta del previsto con molti tag già pronti in Pony, tra cui;
capelli <colore>
vestiti <colore>
seno <dimensione>
femmina <matura>
orecchini <colore>
occhi <colore>
oggetto <sfuocato>
area <sfondo>
Ci sono molte potenzialità di tag utili qui, quindi vanno usati come ho fatto io.
Successi di layering;
occhi rossi -> occhi blu;
[occhi rossi:0.5], [occhi blu:0.5] -> sovrapposizioni di bleed occasionali, instabili.
occhi rossi, occhi blu -> sovrapposizioni bleed meno coerenti
occhi rossi E occhi blu -> sovrapposizioni bleed più coerenti, serve più ricerca
la maggioranza degli occhi ha il problema che il modello impone troppo colore sull’occhio, quindi l’esperimento con layer occhi sarà sospeso e implementato basandosi sull’esperimento blot.
vestito -> latex
vestito, spacco laterale, cocktail dress, latex, tuta in lattice -> forma un outfit basato su più parti da layer. La coerenza è instabile, ma il risultato promette.
latex -> vestito
latex, tuta lattice, vestito, spacco laterale -> forma oggetto più elegante, che sembra sovrapporre i gap del vestito più che usarlo prima. Indica overfitting del training vestito e serve rivalutarlo.
latex -> bikini
latex, tuta lattice, bikini -> forma leggings lattice e bikini, suggerendo overfitting.
Credo di avere una soluzione per l’overlap degli abiti a layer, e con quella arriva la soluzione per occhi, colore pelle e altri. La maggior parte della consistency dovrebbe venire da blotting.
Sponsor del Creatore
Scopri il Modello Illustrious per capacità complementari.
Usa il workflow ComfyUI per migliore generazione immagini e sperimenta con loop.
Esplora il potente Modello Flux come framework AI base.
Supporta NovelAI per eccellenza nella sinergia tra storia e generazione immagini.
Crediti a Black Forest Labs per il design del modello Flux.
Migliora il workflow tag con TagGUI.
Setup training fatto con AIToolkit.
Ispirato e rivale di PonyDiffusion.

PDXL + ILLUSTRIOUS TRAIN V3.34:
Illustrious non è un derivato di PDXL, è differente e molto valido. Provalo se ne hai l'opportunità.
Ho allenato una versione di Simulacrum specificamente per esso.
V3-2 invece di V3.22:
L'obiettivo di v3.22 è cambiato e mi sono perso nel labirinto dei test Flux e nella scoperta di nuovi meccanismi. Dopo aver imparato abbastanza e determinato come fissare il soggetto, come taggare e come Flux interpreta i tag, posso effettivamente costruire una versione 3 adeguata.
Grazie a tutti coloro che hanno sopportato il mio ciclo di apprendimento ed esperimenti. È stata una vera montagna russa di test, fallimenti e alcuni successi veri. So cosa si può fare, come farlo, e ho una metodologia per approcciare e iterare ciò che ho imparato per creare ciò che voglio. Il processo non è perfetto e sarà affinato in corso d’opera, quindi sarà una questione di comprensione e sviluppo iterativo qualunque cosa costruisca. Ho abbastanza fiducia da aver superato la prima grande curva di Dunning-Kruger e posso iniziare a imparare e insegnare informazioni utili dopo gli esperimenti, cercando di elaborare e interpretare le informazioni in modo utile sia per utenti base che avanzati.
Ho determinato che il mio approccio originale verso V4 è praticabile, ma il processo che usavo non è valido come pensavo quando stavo imparando iterativamente i sistemi. Aspetti più approfonditi e più fallimenti da cui imparare per preparare il terreno per i successi futuri.
Versioni basate su direttive.
Ho in programma di introdurre TRE allenamenti con direttive principali per versione e una versione vanilla "nd" singolare.
Utilizzerò allenamenti basati su direttive molto generali non solo per il sistema core ma anche per immagini tematiche specifiche per far trasudare tutti gli aspetti tematici previsti nell'intero sistema.
La parte tecnica del processo di tagging sarà unica e difficile da capire se non si conosce il motivo del perché sto facendo certe cose al sistema, quindi immagini e tagging saranno probabilmente molto confusi se si cercano dettagli specifici.
Il sistema di tagging semplice rimarrà a sé stante e sarà comunque pienamente capace di produrre i risultati necessari quando richiesto.
La versione "nd" o "no directive" per ogni rilascio garantirà che le differenze di test e i risultati siano simili, come l’uccello nella miniera; è tempo di andare quando smette di cinguettare. Probabilmente questi modelli sorella potranno essere uniti e normalizzati per il riuso e per fondere concetti che potrebbero o meno aver funzionato a causa della direttiva usata.
La fissazione sui personaggi INDIVIDUALI è ora l'obiettivo primario per questo modello. Ci sarà un solo personaggio fissato e la risoluzione per quel personaggio sarà scalata in un rapporto discendente e ascendente in linea con i corretti parametri di formattazione del training FLUX.
I problemi di V3.2 erano meno pronunciati di quanto pensassi:
La maggior parte dei problemi derivava da informazioni mancanti che intendo colmare col tempo. Solo una questione di sviluppo iterativo.
Detto questo, la versione allenata 3.21 è attualmente in test e sarà rilasciata presto. Ha capacità migliorata nel controllo delle pose e un focus spostato sul modello usando una direttiva basata sulla camera relativamente lunga.
I risultati hanno mostrato buona compatibilità con la maggior parte delle lora testate e funziona anche con alcune lora molto rigide che non si riescono a stimolare o ruotare con la v32 attuale.
Ha mostrato buona compatibilità con Flux Unchained, molteplici modelli di personaggi, modelli basati sul volto, modelli umani, e così via. La maggior parte del sistema non si sovrappone né rompe altri sistemi finora, quindi è un aspetto positivo.
Problemi di V3.2 da affrontare:
Ci sono problemi di coerenza con alcune pose e angoli. C’è anche qualche contaminazione incrociata con varie altre lora quando usano i tag "from side", "from behind", "from above" e "from below". Userò nuovi tag come unità di verifica e allenerò una LORA separata per garantire fedeltà nel controllo della camera in futuro.
Sembra funzionare bene soprattutto per anime, ma quando entrano in gioco le lora ci sono problemi.
Combinazioni di tag per la versione 3.21;
Devo fare alcuni test base per assicurarmi che la camera funzioni correttamente basandosi sulla posizione, quindi testerò tag come:
un soggetto da vista frontale angolo dall'alto
un soggetto da vista frontale angolo laterale mentre è dall'alto
un soggetto da vista posteriore angolo dall'alto mentre è davanti
un soggetto da vista laterale angolo dall'alto mentre è dietro
e altri tag simili nel base flux_dev, in modo da assicurarmi che ciò che ho costruito posizioni correttamente la camera e che la fedeltà dell'immagine non si perda nel processo.
Dalle mie osservazioni il sistema allena grandi profondità se si usano opzioni generiche come queste. Sono necessari ulteriori test.
Tag come "grabbing from behind", "sex from behind", ecc. probabilmente non cooperano con i tag "behind", quindi userò i tag "rear".
"from side", "from behind", "straight-on", "facing the viewer" e tutto ciò associato a safebooru, danbooru, gelbooru specifici per personaggi non verrà addestrato. Sarà basato esclusivamente sulla VISUALIZZAZIONE di un personaggio, piuttosto che sull’INTERAZIONE con un personaggio.
Non vogliamo nemmeno che gli arti dal punto di vista (POV) siano presenti la maggior parte del tempo, quindi sarà necessario molto testing per garantire che i tag non generino accidentalmente braccia, gambe, torsioni o fissino il soggetto individuale in questione.
Alcune pose francamente non hanno funzionato:
C’è un sistema di tag combinati in gioco che non ha fatto il suo lavoro, quindi servirà un nuovo set di combinazioni di tag per controllare correttamente i personaggi.
Le gambe sono deformate o assenti.
Le braccia possono essere deformate o mal posizionate.
I piedi mancano.
Il busto superiore troppo pronunciato troppo spesso. <<< sovraddestrato
Il busto inferiore non mostra correttamente gli abiti.
Il collo non mostra correttamente sciarpe, asciugamani, collari, choker e altro.
I capezzoli e i genitali sono un disastro assoluto. Serve una cartella adeguata delle loro variazioni per un controller NSFW adeguato in questo caso.
NAI dovrebbe essere specifico per stile e ottimizzato come stile.
Opzioni di abbigliamento generano tipi di corpo più spesso di quanto dovrebbero.
La classificazione esplicita è quasi impossibile da controllare a volte, altre volte è fin troppo presente.
Non ci sono abbastanza immagini dubbie per fare peso, e il sistema taggato esplicito dovrebbe essere anche taggato come dubbio, per garantire che l'informazione dubbia sia anche accessibile.
Alcuni personaggi anime vengono generati con prospettive errate, il che è negativo considerando che l’obiettivo è una prospettiva associativa corretta.
Le pose a quattro zampe sono solide, ma hanno problemi di prospettiva. Non trattano spesso i personaggi anime come 3D, quindi gli ambienti necessitano di maggiore fedeltà.
Le pose a quattro zampe non funzionano in una formazione senza molte modifiche.
L’inginocchiarsi non funziona in una formazione senza molte modifiche.
Formazioni e gruppi sembrano essere formattati in maniera unica per Flux, merita ulteriori indagini, quasi come abilitare un ciclo interno per ogni tipo.
Ci sono stati alcuni successi:
La fedeltà base non ha subito danni nella maggior parte delle immagini.
Molte nuove pose FUNZIONANO, anche se a volte precise al limite.
Lo stile anime è stato modificato in modo unico con un tocco di realismo aggiunto.
Più personaggi possono essere posati, anche se in maniera a volte strana.
Stare in piedi da qualunque angolo mostra fedeltà e qualità d'immagine fantastiche con lo stile di NAI.
V3.3 dovrà aspettare.
Piano per V3.3:
Ho aggiornato le risorse in fondo a questo documento e ho separato la documentazione vecchia in un articolo per archivio.
Con il risultato che ora riflette meglio la mia visione, posso spostare il focus al prossimo passo nella lista degli obiettivi; Overlay.
V3.3 introdurrà ciò che chiamo tag offset burn ad alta alfa, che semplificheranno cose come realizzare fumetti, interfacce di gioco, overlay, barre di salute, display, ecc.
In teoria puoi creare falsi giochi in consistency se realizzo un overlay corretto con le giuste bruciature.
Questo porrà le basi per imporre personaggi in qualsiasi posizione da qualsiasi profondità di scena, ma quello verrà dopo.
Può GIÀ fare sprite sheet in modo discreto, quindi esplorerò il sistema di tagging integrato nei prossimi giorni per testare questi diversi sottosistemi usando un po' di prompt e potenza di calcolo. Probabilmente questo esiste già e deve solo essere scoperto.
Obiettivi V4:
Se tutto va bene, il sistema sarà pronto per capacità di produzione completa che include modifica immagini, editing video, editing 3D e molto altro che non riesco ancora a comprendere.
v33 overlay
È un po’ un nome improprio, è più un framework di definizione scena per la struttura successiva
Questo richiederà sia il minor che il maggior tempo e ho qualche esperimento da fare con l’alfa per farlo funzionare, ma sono abbastanza sicuro che l’overlay sarà una funzione opzionale non solo per mostrare messaggi ma anche per il controllo scena grazie alla profondità.
v34 imposizione personaggi, pianificazione rotazioni e offset punto di vista:
Garantire che certi personaggi esistano e seguano direttive è un obiettivo principale, perché a volte semplicemente non è così.
Implementerò una valutazione numerica completa della rotazione usando pitch/yaw/roll in gradi. Non sarà perfetta poiché non ho le competenze matematiche né dataset né competenze 3D, ma sarà un buon inizio e, si spera, si integrerà con quanto già ha FLUX.
v35 controller scena
Punti di interazione complessi in scena, controllo camera, focus, profondità, e altro che permettono la costruzione completa della scena con i personaggi inseriti.
Pensalo come versione 3D del controller overlay, ma potenziato notevolmente.
v36 controller illuminazione
Cambi di illuminazione segmentati e controllati per scena che influenzano tutti i personaggi, oggetti e creazioni.
Ogni luce sarà posizionata e generata seguendo regole specifiche definite in Unreal usando molteplici tipologie di illuminazione, sorgenti, colori, ecc.
In teoria FLUX dovrebbe colmare le lacune.
v37 tipi di corpo e personalizzazione
Con l’introduzione dei tipi di corpo base, voglio introdurre creazioni di tipi di corpo più complesse che includano, ma non solo:
correzione pose non corrette
aggiunta di molte pose aggiuntive
capelli più complessi:
interazione capelli con oggetti, capelli tagliati, danneggiati, scoloriti, multicolore, legati, parrucche, ecc.
occhi più complessi:
occhi di vari tipi, aperti, chiusi, socchiusi, ecc.
espressioni facciali di vari tipi:
felice, triste, :o, senza occhi, volto semplice, senza volto, ecc.
tipi di orecchie:
a punta, rotonde, senza orecchie, ecc.
colori della pelle di molti tipi:
chiaro, rosso, blu, verde, bianco, grigio, argento, nero, nero intenso, marrone chiaro, marrone, marrone scuro e altro.
Cercherò di evitare argomenti sensibili qui dato che la gente sembra preoccuparsene molto, voglio solo vari colori come per gli abiti.
controller per braccia, gambe, busto superiore, vita, fianchi, collo e dimensione testa:
bicipiti, spalle, gomiti, polsi, mani, dita, con controlli per lunghezza, larghezza e circonferenza.
clavicola e qualunque tag torso esista.
vita e qualunque tag vita esista.
generalizzazioni e specifiche di dimensioni basate su una scala da 1 a 10 piuttosto che sistemi predefiniti di booru.
v38 outfit e personalizzazione outfit
Quasi 200 outfit circa, ognuno con propri parametri personalizzati.
v39 500 personaggi di videogiochi, anime e manga selezionati da dati ad alta fedeltà
cinquecento sigarette— ehm... intendo... tanti personaggi. Sì. Sicuramente non una gran quantità di personaggi meme senza reale collegamento a design o archetipi.
Dopodiché puoi creare qualsiasi cosa o allenare qualsiasi personaggio.
massiccio aumento di fedeltà e qualità:
incluso decine di migliaia di immagini da varie fonti di alta qualità anime, modelli 3D e semi-realismo fotografico per sovrapporre e allenare questa versione finetuned di Flux in uno stile che rientra nei parametri.
ogni immagine sarà valutata e taggata da score_1 a score_10 in modo simile a pony, ma con una mia interpretazione unica a seconda di come andrà.
Rilascio V3.2 - 4k passi:
Questa versione non è per bambini, assolutamente. È un modello base SFW/QUESTIONABILE/NSFW che può essere allenato a qualsiasi cosa.
Non è costruito per fare smut, ma può se richiesto. Fa parte del pacchetto attivare certi comportamenti insegnando cose all’AI; porta conseguenze. Le immagini sono attualmente circa 33% ciascuno, con una leggera ponderazione verso il sicuro simile a NAI.
Sono fermamente a favore dell’attivare e insegnare informazioni così l’individuo può decidere cosa farne. Insegnare a un AI non censurato molte cose non censurate in modo controllato credo sia sano per la sua crescita e comprensione completa, e anche per chi genera immagini dall’AI per non dover vedere incubi 24/7.
Questo modello mostra grande promessa oltre qualunque altra cosa abbia visto.
Usa il mio workload ComfyUI. È allegato a tutte le immagini qui sotto.
Modalità sicura attivata di default:
questionable < sblocca altri tratti random dubbiosi
explicit < sblocca cose divertenti che appaiono casualmente
Tag di attivazione prospettica: prova a mixare; from front, side view, ecc
from front, front view,
from side, side view,
from behind, rear view,
from above, above view,
from below, below view,
Pose principali aggiunte e migliorate:
all fours (a quattro zampe)
kneeling (inginocchiato)
squatting (accovacciato)
standing (in piedi)
bent over (piegato)
leaning (appoggiato)
lying (sdraiato)
upside-down (sottosopra)
on stomach (a pancia in giù)
on back (a pancia in su)
arm placements (posizioni delle braccia)
leg placements (posizioni delle gambe)
head tilts (inclinazioni della testa)
head directions (direzioni della testa)
eye directions (direzioni degli occhi)
eye placement (posizione degli occhi)
eye color solidity (solidità del colore degli occhi)
hair color solidity (solidità del colore dei capelli)
breast size (dimensione del seno)
ass size (dimensione del sedere)
waist size (dimensione della vita)
molte opzioni di abbigliamento
molte opzioni di personaggi
molte espressioni facciali
pose sessuali sono un WIP molto attivo e consiglio vivamente di evitarle finché non saranno affinati. Sono ben oltre la mia capacità e ora non ho le energie mentali per decidere come procedere.
Il creatore di pose, creatore di angoli, setup situazioni, imposizione concetti e struttura di interpolazione sono in posto, allenerò altre versioni.
Godetevi.
Piano V3.2:
25/08/2024 5:16 - Ho identificato che il processo ha funzionato, e il sistema è funzionale a un alto grado oltre le aspettative. L’AI ha sviluppato comportamenti emergenti che hanno posato i personaggi in modi esponenzialmente più potenti del previsto. I test stanno iniziando e il risultato sembra fantastico.
Le risoluzioni finali erano: 512, 640, 768, 832, 1024, 1216
25/08/2024 15:00 - Tutto è correttamente taggato e le pose sono preparate. L’allenamento reale inizia ora, e il processo coinvolgerà test multidimensionali, test del conteggio lr, controlli di passo e molto altro per valutare il candidato giusto per il rilascio v32.
25/08/2024 04:00 - La prima versione di v32 ha mostrato deformità minime attorno al passo 1400 e deformità elevate attorno al passo 2200, il che significa che il tagging lazy WD14 non ha funzionato. Arriverà il tagging manuale. Sarà una mattinata divertente.
24/08/2024 sera - Sta cuocendo ora.
 Sospetto che questa versione non funzionerà. Ho autotaggato tutto e rimosso temporaneamente gli angoli delle pose. Voglio vedere cosa può fare WD14 da solo. Dopo il training, riuscito o meno, ripristinerò gli angoli pose originali e l’ordine tag stabilito. Vediamo come va ora che tutti i dati intenzionali sono concentrati e i casi d’uso sono densi.
Sospetto che questa versione non funzionerà. Ho autotaggato tutto e rimosso temporaneamente gli angoli delle pose. Voglio vedere cosa può fare WD14 da solo. Dopo il training, riuscito o meno, ripristinerò gli angoli pose originali e l’ordine tag stabilito. Vediamo come va ora che tutti i dati intenzionali sono concentrati e i casi d’uso sono densi.Con 4000 immagini sospetto che ci vorrà tempo per la cache dei latenti, ma con attenzione alle bambole e ai corpi specifici dovrebbe andare almeno bene.
24/08/2024 mezzogiorno -
 Siamo al lavoro.
Siamo al lavoro. Tutto è formattato in modo da avere sfondi con implicazioni di ombre, che aiuteranno Flux a generare immagini basate su superfici e posizioni. Tutto è costruito per pose che mancano e che Flux non riesce a gestire. Tutto è costruito per fissare soggetti che possono essere sovrapposti moltiplicativamente in molteplici locazioni.
Tutto è formattato in modo da avere sfondi con implicazioni di ombre, che aiuteranno Flux a generare immagini basate su superfici e posizioni. Tutto è costruito per pose che mancano e che Flux non riesce a gestire. Tutto è costruito per fissare soggetti che possono essere sovrapposti moltiplicativamente in molteplici locazioni.Mi sto concentrando sul corretto posizionamento delle braccia e garantendo che le braccia taggate che si sovrappongono formino braccia da punto A a B.
24/08/2024 mattina - Ci sono anche problemi con le braccia, ma va bene, li inserirò nella lista. Grazie per averlo segnalato, c’è sicuramente contaminazione incrociata da risolvere. Uso un sistema loopback specifico di ComfyUI non presente nel sistema del sito, quindi potrei dover disabilitare la generazione sul sito per questa versione.
 23/08/2024 - Sono arrivato a circa 340 nuove immagini anime ad alto dettaglio con pose quasi uniformi, identificatori pitch/yaw/roll per garantire solidità, variazioni di colore, differenziazione dimensioni tra seni, capelli e sedere. Ne restano 554. V3.2 sarà fortemente dedicato ad anime, poi userò Pony per generare abbastanza realismo sintetico da creare gli elementi realistici necessari. A meno che Flux lo permetta dopo l’allenamento, in quel caso userò solo Flux.
23/08/2024 - Sono arrivato a circa 340 nuove immagini anime ad alto dettaglio con pose quasi uniformi, identificatori pitch/yaw/roll per garantire solidità, variazioni di colore, differenziazione dimensioni tra seni, capelli e sedere. Ne restano 554. V3.2 sarà fortemente dedicato ad anime, poi userò Pony per generare abbastanza realismo sintetico da creare gli elementi realistici necessari. A meno che Flux lo permetta dopo l’allenamento, in quel caso userò solo Flux. Queste DOVREBBERO garantire fedeltà e separazione della valutazione su base pose per pose, soprattutto dato che ho una nuova metodologia con parole chiave from e view. In teoria dovrebbe funzionare quasi identico al controllo pose di NovelAI una volta finito, che è praticamente il mio obiettivo. Personaggi e differenziazione sono tutt’altra storia ovviamente.
Queste DOVREBBERO garantire fedeltà e separazione della valutazione su base pose per pose, soprattutto dato che ho una nuova metodologia con parole chiave from e view. In teoria dovrebbe funzionare quasi identico al controllo pose di NovelAI una volta finito, che è praticamente il mio obiettivo. Personaggi e differenziazione sono tutt’altra storia ovviamente.Tutto deve essere perfettamente ordinato e allineato, altrimenti non aggiungerà semplicemente il contesto necessario ai ritmi necessari per influenzare abbastanza il modello base per essere utile.
Di default SAFE sarà il preset, quindi tutto il sistema sarà costruito con un peso verso il sicuro, con possibilità di abilitare NSFW.
Allenerò più iterazioni di questa LORA per garantire una netta separazione tra le versioni, permettendo comunque al pubblico NSFW di divertirsi con la versione più esplicita.
Spero che, quando sarà allenato, possa caricare un dataset selezionato di 50.000 immagini nel sistema e creerà qualcosa di magico. Qualcosa magari con potenza simile a Pony per qualsiasi desiderio. Allora potrò riposare sapendo che l’universo è grato. Poi voi potrete caricare qualsiasi cosa e farà ciò che volete grazie al potere innato di Flux con la spina dorsale di Consistency.
Ho in programma di rilasciare i dati di training per l’intero set immagini iniziale consistency v3.2 quando sarà organizzato, allenato, testato e pronto. Rilascerò i dati v3 questo weekend quando avrò tempo.
Ho identificato diverse incoerenze nelle pose, soprattutto con la parola chiave "lying" combinata con gli angoli. Testerò ogni combinazione e consoliderò la loro coerenza prima di passare alla fase successiva; scelte outfit base, cambi outfit e derivati basati sulle pose che funzionano o meno. Inoltre dovrò includere info più dettagliate per gli elementi dubbiosi e NSFW più avanti. Puoi immaginare cosa siano dopo la prossima versione.
Fino ad allora devo assicurarmi che le pose funzionino come diretto, quindi creerò nuove parole chiave di combinazione intenzionale, aumenterò i conteggi pose per più immagini per posa, più immagini per angolo e più angoli per situazione. Creerò anche dati che funzionano come segnaposto per situazioni più complesse e immagini, ma Flux non ne ha bisogno di molte quindi lo farò di volta in volta. Includerò anche una serie di tag "base" che faranno di default certe cose quando si raggiungono punti di fallimento, per migliorare la coerenza.
Documentazione V3:
Testato principalmente su FLUX.1 Dev e4m3fn a fp8, quindi il checkpoint merge preparato rifletterà questo valore quando sarà caricato. https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
Funziona sul modello base FLUX.1 Dev, ma anche su altri modelli, merge e lora. I risultati saranno misti. Sperimenta con l’ordine di caricamento, poiché i valori modello cambiano sequenzialmente in gradi variabili.
È praticamente la spina dorsale di FLUX. Potenzia tag utili molto simili a danbooru per stabilire controllo camera e assistenza che rende più facile creare personaggi molto personalizzabili in situazioni che FLUX PUÒ FARE, ma richiede molto più sforzo di default.
Consiglio VIVAMENTE di usare un sistema multiplo di loopback per migliorare fedeltà delle immagini. Consistency migliora qualità e fedeltà in iterazioni ripetute.
È MOLTO orientato al singolo individuo. Però grazie alle risoluzioni strutturate può gestire MOLTE persone in situazioni simili. Le lora che causano cambiamenti immediati senza contesto spesso sono inutili. Le lora specifiche per aggiungere TRAITS o creare interazioni contestuali sembrano funzionare bene. Abbigliamento, tipi di capelli, controllo del genere funzionano. La maggior parte delle lora provate funziona, ma alcune non fanno nulla.
Non è un merge. Non è una combinazione di lora. Questa lora è creata con dati sintetici generati da NAI e AutismPDXL in un anno. Il set immagine è complesso e le immagini scelte sono difficili da selezionare. Ci sono stati molti tentativi ed errori.
C’è una SERIE di tag core introdotti con questa lora. Aggiunge un’intera struttura a FLUX che di default non ha. Il pattern di attivazione è complesso, ma se costruisci il personaggio simile a NAI, apparirà simile a come NAI crea personaggi.
Il potenziale e la potenza di questo modello non va sottovalutata. È un lora molto potente e il suo potenziale supera la mia comprensione.
Può comunque produrre alcune aberrazioni se non si sta attenti. Se si usa il prompting standard e un ordine logico, si possono creare bellissime opere con esso velocemente.
Risoluzioni: 512, 768, 816, 1024, 1216
Step suggeriti: 16
FLUX guidance: 4 o 3-5 se testardo, 15+ se molto testardo
CFG: 1
Usato con 2 loopback. Il primo è un upscaling 1.05x e denoise 0.72-0.88; il secondo denoise 0.8 quasi mai variato, a seconda di quanti tratti volevo introdurre o rimuovere.
ELENCO TAG CORE:
anime - trasforma stile di pose, personaggi, abiti, visi, ecc. in anime
realistic - trasforma lo stile in realistico
from front - vista frontale di una persona, spalle allineate e rivolte verso chi guarda, massa centrale del torso verso lo spettatore.
from side - vista laterale, spalle verticali rivolte allo spettatore, significando che il personaggio è visto di lato
from behind - vista direttamente da dietro la persona
straight-on - vista verticale diretta, per angolo orizzontale piano
from above - inclinazione da 45 a 90 gradi verso il basso su un individuo
from below - inclinazione da 45 a 90 gradi verso l’alto su un individuo
face - immagine focalizzata su dettagli del volto, utile se sono recalcitranti
full body - vista a figura intera, utile per pose più complesse
cowboy shot - tag standard cowboy shot, funziona bene con anime, meno con realistico
looking at viewer, looking to the side, looking ahead (guardando lo spettatore, di lato, avanti)
facing to the side, facing the viewer, facing away
looking back, looking forward
I tag misti creano risultati misti previsti, ma con esiti variegati
from side, straight-on - camera orizzontale puntata lateralmente su individuo/i
from front, from above - inclinazione 45 gradi verso il basso da camera sopra frontale
from side, from above - inclinazione 45 gradi verso il basso da camera sopra laterale
from behind, from above - inclinazione 45 gradi verso il basso da camera sopra retro
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front from side, from below
from front from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
I tag possono sembrare simili, ma l’ordine crea spesso risultati molto diversi. Usare "from behind" prima di "from side" orienta il sistema verso il dietro più che lato, ma spesso si vedrà il busto superiore ruotare e il corpo inclinarsi di 45 gradi in una direzione o l’altra.
Il risultato è misto, ma è decisamente usabile.
funzionano anche tratti, colorazioni, vestiti e altro
capelli rossi, blu, verdi, bianchi, neri, dorati, argento, biondi, marroni, viola, rosa, acqua
occhi rossi, blu, verdi, bianchi, neri, dorati, argento, gialli, marroni, viola, rosa, acqua
tuta in lattice rossa, blu, verde, nera, bianca, dorata, argento, gialla, marrone, viola
bikini rosso, blu, verde, nero, bianco, giallo, marrone, viola, rosa
vestito rosso, blu, verde, nero, bianco, giallo, marrone, rosa, viola
gonne, camicie, vestiti, collane, outfit completi
materiali multipli; lattice, metallico, denim, cotone, ecc.
Pose possono o non possono funzionare con la camera, serve aggiustamento
a quattro zampe
inginocchiato
sdraiato
sdraiato, a pancia in su
sdraiato, di lato
sdraiato, sottosopra
inginocchiato, da dietro
inginocchiato, da davanti
inginocchiato, da lato
accovacciato
accovacciato, da dietro
accovacciato, da davanti
accovacciato, da lato
controllare gambe e simili può essere pignolo, quindi sperimenta un po’
gambe
gambe unite
gambe divaricate
gambe aperte
piedi uniti
piedi divaricati
Centinaia di altri tag usati inclusi, milioni di combinazioni possibili
Usali insieme prima di specificatori per tratti di una persona, ma dopo il prompt per Flux stesso.
PROMPT:
Semplicemente, fallo. Digita quello che vuoi e guarda cosa succede. Flux ha già molte informazioni, quindi usa pose e simili per arricchire le tue immagini.
Esempio:
una donna seduta su una sedia in cucina, da lato, dall’alto, cowboy shot, 1 ragazza, seduta, da lato, capelli blu, occhi verdi

una supereroina che vola nel cielo lanciando un masso, un’aura potente, luminosa e minacciosa intorno, realistico, 1 ragazza, da sotto, tuta in lattice blu, collarino nero, unghie nere, labbra nere, occhi neri, capelli viola
 una donna che mangia in un ristorante, dall’alto, da dietro, a quattro zampe, sedere, perizoma
una donna che mangia in un ristorante, dall’alto, da dietro, a quattro zampe, sedere, perizoma Sì, ha funzionato. Di solito funziona così.
Sì, ha funzionato. Di solito funziona così.
Questo modello dovrebbe gestire quasi tutto il caos, ma sarà sicuramente oltre la mia completa comprensione. Ho cercato di mitigare il caos e includere abbastanza tag pose per farlo funzionare, quindi cerca di attenerti principalmente ai tag core utili.
Oltre 430 tentativi falliti separati hanno finalmente portato a teorie di successo. Scriverò un report completo delle informazioni necessarie e rilascerò i dati di training probabilmente questo weekend. È stato un processo lungo e difficile. Spero vi piaccia a tutti.
Documentazione V2:
Ieri sera ero molto stanco, quindi non ho finito di compilare il report e i risultati. Aspettatevelo presto, probabilmente durante il giorno mentre lavoro farò test e prenderò appunti.
Introduzione Training Flux:
Prima, PDXL richiedeva poche immagini con tag danbooru per un risultato finetuned comparabile a NAI. Pochi dati in quel caso era un vantaggio perché riduceva il potenziale; qui invece pochi dati non funzionano. Serviva qualcosa di più potente.
Il modello ha molto, ma le differenze tra dati appresi hanno una variazione molto più alta del previsto. Più variazione significa più potenziali, e non capivo perché funzionasse con alta varianza.
Dopo ricerca ho scoperto che il modello è potente PROPRIO PER QUESTO: può produrre immagini “DIRETTE” basate sulla profondità, dove l'immagine è segmentata e stratificata su un'altra usando il rumore di un’altra immagine come guida. Mi ha fatto pensare a come allenare >>QUESTO<< senza distruggere i dettagli core. Prima pensavo a resizing, poi ho ricordato il bucketing. Questo porta al primo punto.
Sono entrato praticamente alla cieca, impostando parametri su suggerimenti e giudicando dal risultato. È un processo lento, quindi leggo paper per velocizzare. Se avessi abbastanza risorse farei tutto in parallelo, ma sono solo uno e ho lavoro da fare. Ho provato tutto. Se avessi più tempo ne farei 50 insieme, ma non ho modo di configurarlo. Potrei pagare ma non posso configurarlo.
Ho scelto ciò che pensavo fosse il miglior formato basato sulla mia esperienza con SD1.5, SDXL e PDXL lora training. È andata abbastanza bene, ma ci sono problemi evidenti di cui parlerò.
Formattazione Training:
Ho fatto alcuni test.
Test 1 - 750 immagini casuali dal mio campione danbooru:
UNET LR - 4e-4
Ho notato che altri parametri non contavano molto, tranne l’attenzione al bucketing risoluzione.
Solo 1024x1024, centro ritagliato
Tra 2k e 12k passaggi
Ho scelto 750 immagini da uno dei pool random di tag danbooru assicurandomi che i tag fossero uniformi.
Ho usato moat tagger sulle immagini e aggiunto i tag al file evitando sovrascritture.
Risultato non promettente. Il caos è atteso. Introduzione di nuovi elementi umani come genitali era presente o meno, o spesso assenti. È in linea con quanto altri hanno trovato.
Non mi aspettavo che il modello intero soffrisse dato che i tag non si sovrapponevano molto.
Ho fatto il test due volte e ho due lora inutili a circa 12k passi ciascuno. Test 1k-8k non ha mostrato deviazioni utili verso obiettivi, nemmeno guardando attentamente le curve del tag pool.
C’è qualcos’altro qui. Qualcosa che ho perso e non credo sia umanistico o descrizione clip. C’è qualcosa... di più.
Durante questo fallimento ho fatto una scoperta. Questo sistema di profondità è interpolativo e si basa su due prompt totalmente diversi e devianti. Questi due prompt sono in effetti cooperativi e interpolativi. Come determina questo è sconosciuto, ma oggi leggerò i paper per capire la matematica.
Test 2 - 10 immagini:
UNET LR - 0.001 <<< LR molto potente
256x256, 512x512, 768x768, 1024x1024
I primi passi mostravano deviazioni simili a quanto imponeva SD3. Non era buono però. Il bleeding iniziava verso il passo 500. Era inutile già al passo 1000. So che uso "repeat" qui, ma è stato un buon test fallito.
Deviazioni sono molto dannose. Introduce un nuovo elemento di contesto e lo trasforma in una slot machine. Sostituisce elementi delle persone con quasi niente o artefatti bruciati simili a un inpaint male settato. Interessante quanto FLUX resiste e funziona ancora. Test potente a mostrare resistenza di FLUX.
Fallimento, servono test con impostazioni diverse.
Test 3 - 500 immagini pose:
UNET LR - 4e-4 <<< dovrebbe essere diviso per 4 e dato doppio dei passi.
Bucking completo - 256x256, 256x316, ecc. L’ho lasciato libero e gli ho dato molte immagini di varie dimensioni. Risultato inatteso.
Il risultato è letteralmente il cuore di questo modello consistency, così potente il risultato. Ha fatto un po’ più danni del previsto, ma è stato notevole.
Nota: gli anime di solito non usano profondità di campo. Questo modello invece prospera con profondità e sfocatura per differenziare profondità. Serve una specie di controlnet profondità per queste immagini per garantire variazione profondità, ma non so come farlo. Allenare mappe di profondità con normali potrebbe funzionare o distruggere il modello perché non ha negative prompt.
Servono altri test. Più dati di training. Più informazioni.
Test 4 - 5000 bundle consistency:
UNET LR - 4e-4 <<< Dovrebbe essere diviso per 40 e dato 20x i passi, circa. Allenare questo nel modello base non è semplice né rapido. La matematica non gioca bene con il processo attuale, ma ho fatto il test e rilasciato i risultati iniziali.
Ho scritto una sezione intera più una a seguire e stavo per andare ai risultati, ma ho cliccato indietro col mouse e ho perso tutto, la riscriverò dopo.
I grandi fallimenti:
Il learning rate era TROPPO ALTO per le mie lora a 12k passi. Il sistema si basa sull’apprendimento a gradiente, ma la velocità a cui ho insegnato era troppo alta perché potesse trattenere senza rompere il modello. Non li ho bruciati, ho fatto riaddestrare il modello a fare ciò che volevo. Il problema è che non sapevo cosa volevo, quindi il sistema si basava su cose non dirette e senza gradiente di profondità. Era destinato a fallire, più passi o meno.
Lo STILE per FLUX non è ciò che la gente pensa sia basato su PDXL e SD1.5. Il sistema a gradiente stilizza, ma l’intera struttura soffre molto quando si impone TROPO informazioni troppo in fretta. È MOLTO distruttivo, a differenza di PDXL lora che erano più un insieme di imposizioni. Aumentavano ciò che già c’era più che allenare nuove cose.
Scoperte cruciali:
ALFA, ALFA e ANCORA ALFA<<<< Il sistema si basa pesantemente sui gradienti alfa. Tutto DEVE essere trattato specificamente per gestire gradienti alfa basati su dettagli fotografici. Distanza, profondità, ratio, rotazione, offset ecc. sono chiavi integrali per la composizione di questo modello e per creare un compositore stilistico corretto servono questi dettagli in più di un singolo prompt.
TUTTO deve essere descritto correttamente. Il tagging semplice danbooru è solo stile. Stai forzando il sistema a riconoscere lo stile che vuoi implementare, quindi non puoi imporre concetti senza tag di allocazione necessari. Altrimenti stile e concept linker falliscono, dando output spazzatura. Spazzatura dentro, spazzatura fuori.
Il training delle pose è ESTREMAMENTE potente usando grandi quantità di info pose. Il sistema RICONOSCE già gran parte dei tag, solo non sappiamo quali ancora. Il training per collegare ciò che C’È a ciò che VUOI usando tag specifici sarà potentissimo per organizzare e affinare i tag.
Documentazione passaggi;
v2 - 5572 immagini -> 92 pose -> 4000 passi FLUX
L’obiettivo originale di portare NAI a SDXL è ora applicato anche a FLUX. Seguite per ulteriori versioni.
Serve test di stabilità, ma finora mostra capacità distinte oltre qualunque cosa PDXL possa fare. Serve ulteriore training, ma è molto più potente del previsto a passi così bassi.
Credo che il primo strato di training pose sia circa 500 immagini, quindi questo è ciò che taglia di più. I dati completi saranno rilasciati su HuggingFace quando avrò un set immagini organizzato e completo. Non voglio rilasciare immagini sbagliate o spazzatura selezionata.
Continua a leggere qui:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
Riferimenti importanti:
Non fumo, ma FLUX ogni tanto ne ha bisogno.
Workflow e assistente generazione immagini. Uso principalmente nodi core ComfyUI, ma uso anche altri per sperimentare e salvare.
Modello AI molto potente e difficile da capire con grande potenziale.
Senza di loro non avrei mai voluto fare questo. Un grande grazie a tutto lo staff NAI per il duro lavoro e per il mostro generatore d’immagini insieme al fenomenale assistente di scrittura. Donate loro.
Hanno creato Flux e si meritano la maggior parte del merito per la flessibilità del modello. Io sto semplicemente finendo e indirizzando questa bestia al suo destino.
Assistente tag potente e valido. Ero quasi pronto a scriverne uno mio finché non ho trovato questo gigante.
Usato per allenare le mie versioni di Flux. Un po’ delicato e pignolo, ma funziona bene su vari sistemi.
Non dimenticate il rivale in campo. La bestia è un mostro assoluto per generare immagini in un enorme campo di gradiente, uno strumento di ricerca e comprensione prezioso, e un’ispirazione per questa direzione e progresso.

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Creatore
Discussione
Per favore log in per lasciare un commento.
![Old Consistency V32 Lora [FLUX1.D/PDXL] Femminile v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































