RedCraft | 红潮 CADS | Aggiornato-GIU29 | Ultimo - Red-K Kontext DEV NSFW - 赩梦|REDiDream(NSFW i1)
Parole Chiave e Tag Correlati
Immagini in evidenza

Parametri Consigliati
samplers
steps
cfg
Suggerimenti
Per l'editing In-Context con ICEdit, aggiungere il pre-prompt fisso: "A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {instruction}" per migliorare i risultati.
Nell'editing In-Context, ridimensionare la larghezza dell'immagine di input a 512 senza restrizioni sull'altezza.
Usare Normal LoRA e non MoE-LoRA per ComfyUI poiché MoE-LoRA non è compatibile.
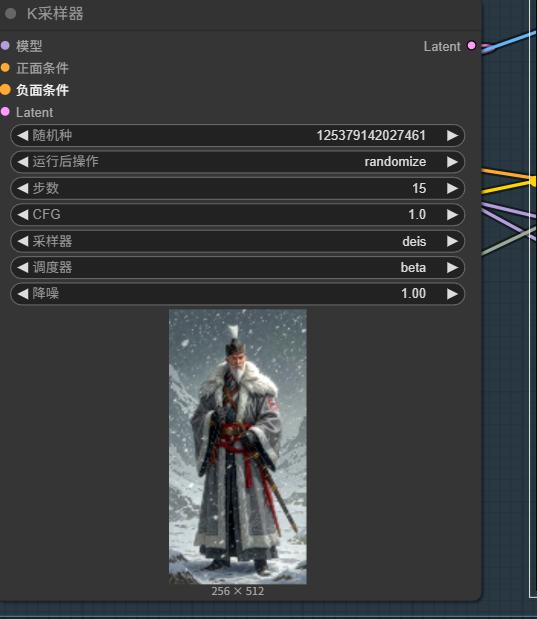
I passi di campionamento consigliati per REDiDream Pro sono 15 per generazione efficiente.
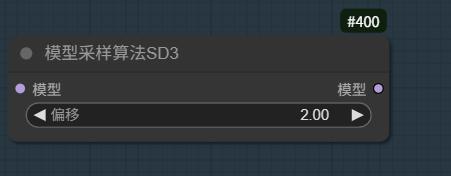
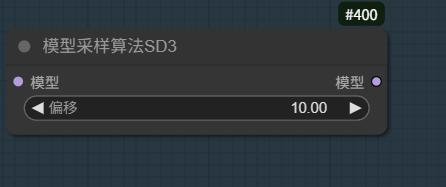
Regolare il bias dello Shift del modello per sbloccare più caratteristiche di stile e capacità NSFW.
Usare campionatori come Deis, DPM++2M, Euler, EulerA con valori CFG comunemente intorno a 1-7, a seconda del modello.
Usare scaling UNET o script di chunking per immagini ad alta risoluzione in output.
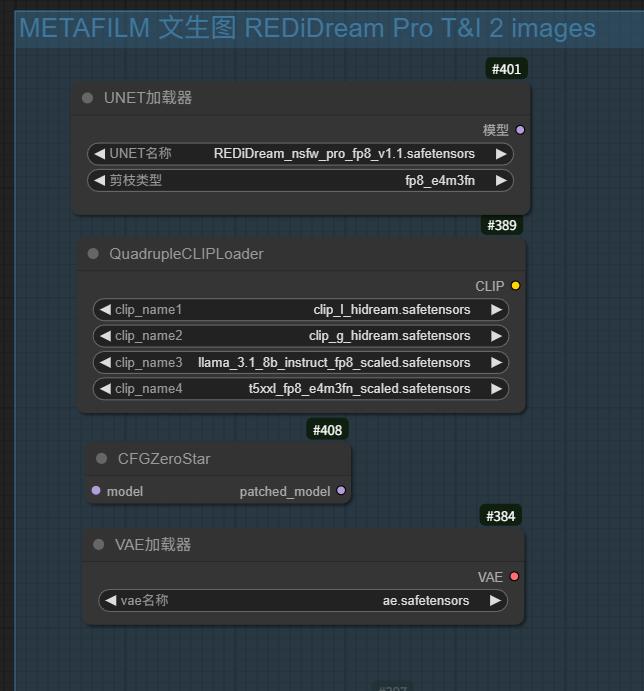
Per le versioni UNET, assicurarsi di scaricare anche gli encoder di testo e il VAE per una migliore guida dei prompt.
Installare nodi custom speciali di ComfyUI per supportare modelli quantizzati BNB NF4 e GGUF.
Punti Salienti della Versione
Introduzione a REDiDream Pro
---
La comunità ha quantizzato una versione safetensors bnb-nf4/fp4, caricabile direttamente in ComfyUI con loader bnb_fp4_nf4, evitano il caricatore GGUF: https://huggingface.co/mengqin1/RedidreamNSFWI1-bnb-4bit
Grazie a mengqin1 (Qing Meng) (pare sia una ragazza =)
---
Ora abbiamo la quantizzazione GGUF:
https://huggingface.co/Sikaworld1990/Redidream/tree/main
Grazie a Sikaworld1990
Grazie a sikasolutionsworldwide709
Grazie a City96 https://huggingface.co/city96
---
HiDream-I1 è un modello generativo open-source con 17 miliardi di parametri che raggiunge qualità di generazione immagine leader in pochi secondi. REDiDream Pro è un modello di generazione efficiente basato sulla versione completa di HiDream-I1, ottimizzato attraverso DEV / FAST e ulteriori allenamenti per migliorare efficienza e stabilità, e parzialmente sbloccare capacità generative NSFW.
---
Caratteristiche chiave di REDiDream Pro
---
Generazione efficiente
Ottimizzato da HiDream-I1 full, con velocità tra dev e fast, passi inferenza consigliati: 15.
---
Aumento stabilità
Ottimizzato da DEV FAST, REDiDream offre performance più stabili nella generazione immagini.
---
Open source e flessibilità
Ereditando licenza MIT di HiDream-I1, non limita modifiche o distribuzioni da parte degli utenti.
---
Commercial-friendly
Le immagini generate possono essere liberamente usate per progetti personali, ricerca scientifica e applicazioni commerciali, conforme a licenza HiDream-I1.
Sponsor del Creatore
Risorse di modelli e workflow disponibili nei repository e link ufficiali:
RedCraft-红潮-METAFILM
Essere un buon assistente, servire gli artisti
Yuan Studio Intelligente di Ai²Anon Non umano
Per sempre in memoria del fondatore di METAFILM Studio Sig. Yuan Bo
RED-K🧡红桃K Editor 6/29/2025
Unione di Reveal.6 & BFL.Kontext[DEV] NSFW Sbloccato
v1.2 6/29
Unione di Clothes Remover(fm00) & Reveal.6
---
Licenza Pubblica
Licenza Pubblica Generale GNU Affero v3.0
GNU AGPLv3
I permessi di questa potente licenza copyleft sono condizionati alla messa a disposizione del codice sorgente completo delle opere licenziate e delle loro modifiche, inclusi lavori più grandi che utilizzano l'opera licenziata, sotto la stessa licenza. Avvisi di copyright e licenza devono essere conservati. I contributori concedono esplicitamente diritti di brevetto. Quando una versione modificata viene usata per fornire un servizio tramite rete, il codice sorgente completo della versione modificata deve essere reso disponibile.
https://choosealicense.com/licenses/agpl-3.0/
RED-OMNI Kontext Editor 5/31/2025
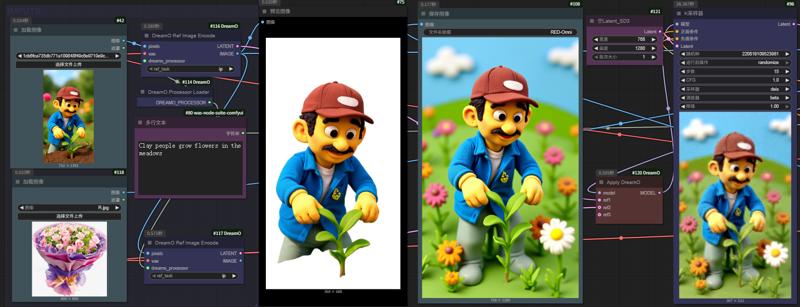
Compiti supportati
IP: Simile a IP-Adapter, supporta personaggi, oggetti e animali. Usa codifica basata su VAE per maggiore fedeltà e migliore conservazione dell'identità del personaggio rispetto ai metodi precedenti.
ID: Si concentra sull'identità facciale, simile a InstantID e PuLID. Offre maggior fedeltà facciale ma introduce più contaminazione del modello rispetto a PuLID.
Consiglio: se il volto appare troppo lucido, ridurre la scala di guida.Prova-Indosso: Supporta prova virtuale per top, pantaloni, occhiali e cappelli, inclusi più indumenti. Generalizza bene a combinazioni multi-indumento e ID+indumento non viste nonostante dati di addestramento limitati.
Stile: Simile a Style-Adapter e InstantStyle. La coerenza dello stile è meno stabile e attualmente non può essere combinata con altre condizioni. Sono in corso miglioramenti.
Multi Condizione: Combina ID, IP e Prova-Indosso per output creativi. La restrizione di instradamento delle caratteristiche minimizza conflitti e intrecci tra entità.
ComfyUI: Supporto nativo tramite ComfyUI-DreamO
Uso Avanzato Advanced
OmniConsistency è una combinazione open-source di modelli e algoritmi di trasferimento di stile con preservazione della coerenza sviluppata da Show Lab, National University of Singapore. Poiché usa FLUX.1dev come base di allenamento, si è testato che DreamO e OmniConsistency possono funzionare in “collegamento onirico” tramite ComfyUI.
OmniConsistency è una combinazione di modelli di trasferimento stile preservativo di coerenza open-source da Show Lab, National University of Singapore. Grazie all’uso di FLUX. 1dev come base, è stato testato che DreamO e OmniConsistency raggiungono un "collegamento onirico" tramite il workflow ComfyUI.
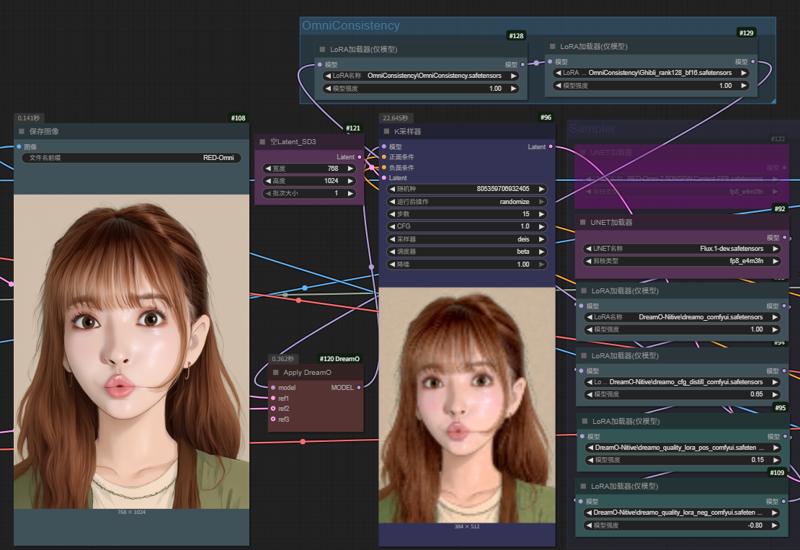
Basta collegare la LoRA OmniConsistency con 22 stili diversi di LoRA, inserirle in RED-Omni (2.5D NSFW) o via modalità nativa DreamO al gruppo modello Flux.1 dev per effettuare contemporaneamente modifica in linguaggio naturale e trasferimento stile di riferimento.
[ Per ulteriori divertimenti vi aspettiamo ] In attesa di BFL Kontext (dev)
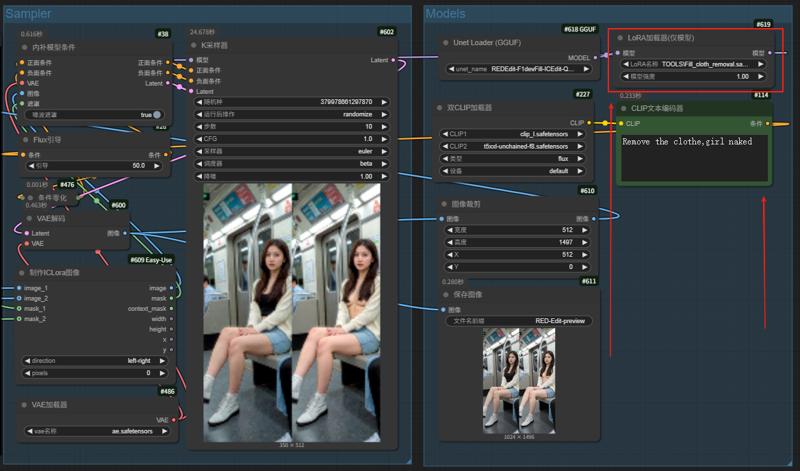
REDEdit IC (FP8) 5/11/2025
Modifica In-Context: Abilitare l’Editing Istruttivo di Immagine con Generazione In-Context in Large Scale Diffusion Transformer
ICEdit Controllore multimodale (editing immagine sotto guida IC)
![]()
Basato su Flux.tools-Fill richiede minimo solo 6G VRAM
I recenti controllori multimodali sono sempre meno amichevoli per utenti C-end
Richiedono 20-30+ di VRAM, scoraggiando
Il team di sviluppo, dopo aver sentito le critiche dalla community, ha fornito un workflow ufficiale (bravi 👍)
After experiencing the critical hits in the C-end player community, the development team actively provided the official workflow.
E ha fornito metodi più completi per l’uso client:
Devi aggiungere il pre-prompt fisso "A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {instruction}" prima di inserire le istruzioni di modifica, altrimenti potresti ottenere risultati scadenti! (Citato nel paper!) Datou ha aggiornato il suo workflow ComfyUI, prova! (Il codice per la demo Hugging Face gradio incorpora già questo prompt, quindi puó essere inserito direttamente senza ulteriori configurazioni.)
La larghezza dell’immagine in input deve essere ridimensionata a 512 (nessuna restrizione per l'altezza).
Usa Normal LoRA e non MoE-LoRA per ComfyUI poiché MoE-LoRA non è compatibile con il caricatore lora di ComfyUI.
Repository Github ufficiale: River-Zhang/ICEdit: Image editing is worth a single LoRA! 0.1% training data and 1% training parameters for fantastic image editing! Surpasses GPT-4o in ID persistence! Official ComfyUI workflow release! Only 4GB VRAM is enough to run!
LoRA normal (non-moe) ufficiale: RiverZ/ICEdit-normal-lora at main
Consigliamo vivamente di costruire un ambiente di inferenza indipendente locale (o usare il pacchetto integrato fornito da 十字鱼)
5.11 🔥 Aggiornamento RED-Edit v1.1 (basato su ICEdit normal LoRA) con ottimizzazione multi-istruzione
5.11 🔥 Aggiornamento workflow nella lista download "Trainning data" a destra
Esegue contemporaneamente rimozione abiti, occhiali da sole e maschera, con aumento significativo del tasso di successo 🔥 Ottimizzazione qualità immagine consigliata a 15 passi
Prompt: A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {Women's naked,Wearing sunglasses,facemask}
Per utenti avanzati: sovrapporre Flux.fill LoRas per risultati di modifica più stabili
Rimozione Oggetti Flux Fill v2
@xiaozhijason / Rimozione Oggetti Flux Fill v2 - v2.0 | Flux LoRA | Civitai
Descrizione Modello Fill.LoRas di xiaozhi
Questa è una LoRA di rimozione oggetti, rifinita dal modello Flux Fill Dev.
La LoRA è progettata per rimuovere oggetti in aree mascherate specificate, utile per editing immagini dove oggetti indesiderati devono essere cancellati senza soluzione di continuità.
Questa LoRA si ispira a Object Drop. Object Drop ha ottenuto risultati eccezionali nella rimozione oggetti e ho voluto provarla con il modello Flux Fill.
Per limitazioni di potenza computazionale, questa versione alpha è stata addestrata solo su un dataset molto piccolo.
Se qualcuno è interessato e vuole sponsorizzare la potenza di calcolo, contattatemi.
Contatti autore Fill-LoRas
Twitter: [@Lrzjason](https://twitter.com/Lrzjason)
Email: lrzjason@gmail.com
CivitAI: https://civitai.com/user/xiaozhijason
ICEdit & Xiaozhi facciamo tornare a credere nella luce
RED-Edit è basato su RED-Fill (NSFW) unito a pesi di allenamento ICEdit, con inferenza minima di 8 passi
Workflow e file modello sono nella lista download, il workflow è impacchettato in un archivio "Trainning data"
Rispetto ai modelli commerciali come Gemini e GPT-4O, i nostri metodi sono comparabili e persino superiori nella conservazione dell’ID personaggio e nel seguire istruzioni. Siamo più open-source, con costi inferiori, velocità maggiore (circa 9 secondi per immagine) e prestazioni potenti.
Ringraziamenti a: @river-zhang e membri del team Università di Zhejiang e Università di Harvard
@article{zhang2025ICEdit,
title={In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer},
author={Zhang, Zechuan e altri},
journal={arXiv},
year={2025},
url={https://arxiv.org/abs/2504.20690},
}
REDiDream Pro (FP8) 28/4/2025
Introduzione a REDiDream Pro
HiDream-I1 è un modello open-source di base per generazione immagini con 17 miliardi di parametri, che raggiunge qualità all’avanguardia in pochi secondi. REDiDream Pro è un modello efficiente basato sulla versione completa di HiDream-I1, ottimizzato tramite versioni DEV / FAST e ulteriore addestramento per migliorare l’efficienza e la stabilità e sbloccare parzialmente capacità NSFW.
HiDream-I1 is an open-source image generative foundation model with 17 billion parameters, achieving state-of-the-art image generation quality in seconds.
REDiDream Pro è un modello efficiente basato sulla versione completa di HiDream-I1, ottimizzato tramite DEV / FAST e training aggiuntivo per migliorare efficienza e stabilità, e sbloccare parzialmente capacità generativa NSFW.
Ora disponiamo di quantizzazione GGUF:
https://huggingface.co/Sikaworld1990/Redidream/tree/main
Grazie a Sikaworld1990
Grazie a sikasolutionsworldwide709
Grazie a City96 https://huggingface.co/city96
Segue introduzione alle caratteristiche principali:
Caratteristiche principali | Key Features
Generazione efficiente | Efficient Generation
REDiDream Pro è ottimizzato dalla versione completa HiDream-I1, con velocità di generazione tra le versioni dev e fast, raccomandati 15 passi di inferenza.
Optimized from HiDream-I1 full, with generation speed between dev and fast versions,
recommended inference steps: 15.
Migliorata stabilità | Enhanced Stability
Ottimizzato tramite versioni DEV FAST, REDiDream offre prestazioni di generazione immagini più stabili.
Optimized via the DEV FAST version, REDiDream offers more stable image generation performance.
Open source e flessibilità | Open Source and Flexibility
Ereditando licenza MIT di HiDream-I1, permette agli utenti di modificare e distribuire liberamente senza restrizioni.
Inherits HiDream-I1’s MIT license, allowing users to freely modify and distribute without restrictions.
Commercial-friendly | Commercial-Friendly
Le immagini generate possono essere liberamente usate per progetti personali, ricerca scientifica e applicazioni commerciali, conformi ai termini di licenza HiDream-I1.
Generated images can be freely used for personal projects, scientific research, and commercial applications, compliant with HiDream-I1’s license terms.
Data la grande quantità di parametri del modello e il supporto alle più complete 4TE layers per codifica testuale, un opportuno aggiustamento dello Shift bias del modello può ottenere più caratteristiche stilistiche e sblocco capacità NSFW.
Supporto ComfyUI | ComfyUI Support
Supporto nativo | Native Support
REDiDream offre supporto nativo per ComfyUI versione 3.30, tutte le immagini d'esempio sono generate con questa versione.
REDiDream provides native support for ComfyUI version 3.30, with all example images generated using this version.
Ambiente di training | Training Environment
REDiDream Pro è stato allenato su hardware L40s 48G e sviluppato usando ComfyUI.
REDiDream Pro was trained on L40s 48G hardware and developed using ComfyUI.
Requisiti prestazionali | Performance Requirements
Requisiti hardware | Hardware Requirements
Le prestazioni di REDiDream Pro sono paragonabili alla versione HiDream-I1 dev, adatte per inferenza efficiente.
REDiDream Pro’s performance requirements are comparable to HiDream-I1 dev, suitable for efficient inference.
Velocità di generazione | Generation Speed
La velocità è tra HiDream-I1 dev e fast, ottimizzando l’equilibrio tra efficienza e qualità.
Generation speed falls between HiDream-I1 dev and fast versions, balancing efficiency and quality.
Accordo di Licenza | License Agreement
Licenza del modello | Model License
I modelli Transformer adottano licenza MIT. Il VAE è di FLUX.1 [schnell], i codificatori testuali da google/t5-v1_1-xxl e meta-llama/Meta-Llama-3.1-8B-Instruct, soggetti alle rispettive licenze.
Transformer models are licensed under the MIT License. The VAE is from FLUX.1 [schnell], and text encoders are from google/t5-v1_1-xxl and meta-llama/Meta-Llama-3.1-8B-Instruct, subject to their respective license terms.
Responsabilità d'uso | Usage Responsibility
Gli utenti possiedono tutti i contenuti generati ma devono rispettare la licenza, evitando contenuti illegali, dannosi o che prendono di mira gruppi vulnerabili.
Users own all generated content but must comply with the license agreement, avoiding illegal, harmful, or content targeting vulnerable groups.
REDiDream Pro | Licenza ereditata
Eredita licenza MIT di HiDream-I1, rispettando le rispettive clausole.
REDiDream inherits HiDream-I1’s MIT License.
Ringraziamenti | Acknowledgements
Fonti dei pesi | Weights Sources
HiDream-ai/HiDream-I1-Full · Hugging Face
Comfy-Org/HiDream-I1_ComfyUI · Hugging Face
GuangyuanSD/REDiDreamviaHiDreami1Uncensored · Hugging Face
Fonti componenti | Component Sources
Il VAE proviene da FLUX.1 [schnell] (licenza Apache 2.0), i codificatori testuali da google/t5-v1_1-xxl (Apache 2.0) e meta-llama/Meta-Llama-3.1-8B-Instruct (licenza comunitaria Llama 3.1).
The VAE is from FLUX.1 [schnell] (Apache 2.0 license), and text encoders are from google/t5-v1_1-xxl (Apache 2.0 license) and meta-llama/Meta-Llama-3.1-8B-Instruct (Llama 3.1 Community License Agreement).
Origine del nome REDiDream:
Dopo questo viaggio, abbiamo Re-Did-(un)Sogno
RED. UNO In-Context (FP8) 14/4/2025
REDAIGC Modello FT per abbinamento alla generazione UNO In-Context
(con aumento qualità rispetto a F.1 dev)
Risolve problema di incompatibilità FLUX FT modello base con componente UNO, pesi FP8 (16GB VRAM), supporta Diffusers e ComfyUI
---
Script Diffusers:
https://github.com/bytedance/UNO
Pesi Dit-LoRA:
bytedance-research/UNO · Hugging Face
ComfyUI-nodi componente:
https://github.com/QijiTec/ComfyUI-RED-UNO
Versione Diffusers-VAE:
https://huggingface.co/GuangyuanSD/16C_vae_Diffusers
---
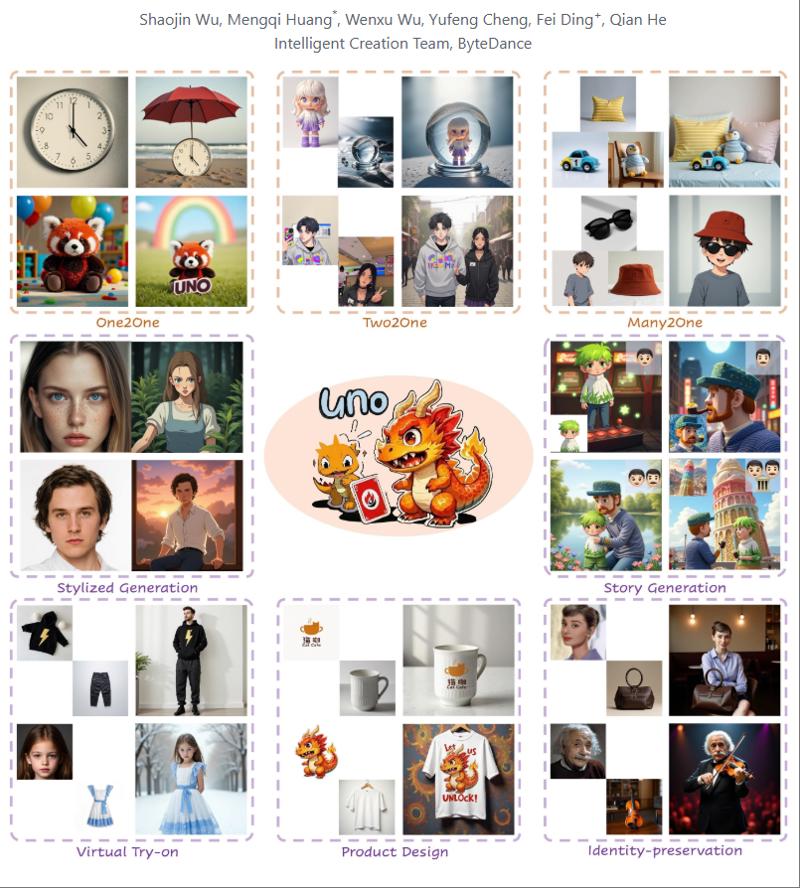
Propone una pipeline di sintesi dati altamente coerente per affrontare questa sfida, sfruttando capacità intrinseche di generazione in-context dei transformer di diffusione e generando dati multi-soggetto ad alta coerenza. Introduce inoltre UNO, con progressivo allineamento cross-modale e incorporamento universale di posizione rotatoria. È un modello multi-immagine condizionato soggetto-a-immagine addestrato iterativamente da un modello testo-immagine. Esperimenti mostrano alta coerenza e controllabilità in generazione singolo e multi-soggetto.
ULTRAREVEAL5 SFW Rilascio urgente 25/3
In risposta a feedback degli utenti che trovavano la serie Reveal troppo NSFW
Abbiamo rilasciato la prima versione Reveal con blocco contenuti per adulti
[ ALIMENTATO DA FLUX Contrast Enhancement Training ]
REALREVEAL5 Rilascio improvviso 18/3
F.1 DEV LoRA Ecosistema Compatibilità totale
De-distillazione ultra alta qualità (trainabile)
CFG restore a 1 per mantenere stessa velocità di F.1 DEV
LoRA Compatibilità completa De-Distill UH Material (trainabile)
[ ALIMENTATO DA FLUX Ultimate Realism Enhancement Training ]
---
Illust3Relustion PRO rifatto con Flux1-DedistilledMixTuned v3 PAP
Set di allenamento Ultimate Realism dopo DMT v3 PAP risampling
Immagini ultra-realistiche 2k usate come dataset di allenamento
Aggiornato modello base flux DEV versione 4k ultra HD EOR v3:
Flux.1 Dev Edge of Reality reale-bordo - v3 | Flux Checkpoint
---
NSFW sbloccato
---
RedCraft RealReveal5 per campionamento 20 passi
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
Consigliato abilitare campionatore DetailDaemon e impostare quantità 0.6-0.8
---
SOTA capacità adattativa per Tutte le All-F.1-LoRA!
Serie RedCraft uncensored vietata nelle aree NSFW non autorizzate
Modelli non commerciali, vietata qualsiasi forma di distribuzione o diffusione
Leggi e regolamenti nelle zone di pubblicazione non commerciale
illustriousRelustion3 Aggiornamento 11/3
Basato su RETROSD / FLUX Reveal / EDGE4k, creato modello FT fotografico realistico globale Illustrious
Tornando ai giorni gloriosi dell’era SD!
CFG 5.5 Deis / DPMM++2M | SGM Uniform / beta
campionamento circa 30 passi
immagini preview includono workflow e prompt
accoppiato con acceleratori Hyper / DMD2 / TDD
Campionamento ottimale 25-30 passi, uso consigliato acceleratori Hyper/DMD2/TDD
Design del modello con Hi-RES 2M (2 milioni pixel)
Risoluzione design: Hi-RES 2M (200 milioni pixel), alta risoluzione supporta scaling UNET
Grazie di cuore a tutti per il vostro supporto!
PONYRelustion3 PRO Rilascio ufficiale 3/3
Basato su un dataset leak 33 milioni di immagini
Supporto 91大神 per modello fotografico realistico est-asiatico PONY
Favorisce creatività illimitata nel mondo PONY!
Creatività illimitata nel mondo PONY!
---
CFG 5 Deis | DPMM++2M | SGM Uniform
Campionamento ottimale ~30 passi, parametri replicabili dall’immagine di esempio
Compatibile con acceleratori Hyper/DMD2/TDD
---
Risoluzione design Hi-RES 2M (200 milioni pixel)
Proporzioni mantenute con super adattabilità di PONY
Aspect ratio come la capacità ULTRA adattativa di PONY
---
Obiettivo: creare modello base maturo di alta qualità e creatività per mondo PONY!
Grazie a tutti per il continuo supporto!
base maturo, di alta qualità per il mondo PONY!
Grazie di cuore a tutti per il vostro supporto!
FLUX.Fill NSFW Ripristino rilascio 22/2
FLUX.Fill [NSFW] nuovo modello Reveal F.1 inPainting
Sblocco elementi concettuali NSFW per F.1 Fill
Da abbinare al modello NewReveal F.1 con Fill [NSFW]
Sblocco elementi concettuali NSFW come in ULTRA
Il modello di inpainting va caricato con un workflow inpainting specializzato e campionatore inpainting, l’immagine deve avere una maschera per scopi speciali come ritocco o espansione.
Nota: modello inPainting Fill.NSFW deve essere usato con workflow inpainting dedicato e campionatore inpainting; l’immagine richiede maschera, usato per ritocco o espansione
Per uso normale usare: RedCraft | 红潮 | Commercial & Advertising Design System - 🌹NewReveal[F.1]ULTRA🌹
Usato principalmente per riparazione di anatomia femminile e organi umani
La resa di genitali maschili non è ancora ideale
Principalmente usato per riparare arti femminili e organi umani
[ Espressione per genitali maschili non ancora ottimale ]
RED.epicus BIG Movie (FP8) 23/2/2025
Noioso! Ripetitivo! Spam!
RED[creativo] Epicus modello epico BIG Movie
A causa del diffuso uso di tecniche di cifratura e di distillazione nei modelli T2I
la creatività delle opere della comunità F.1 cala...
Se ami tanto la foto realistica! Perché non fare un servizio fotografico dal vivo?!
Monotono, ripetitivo, senza fine
Perciò il gruppo Sunset Red ha creato questo FT creativo basato su tecnologia di de-distillazione
Senza dataset bloccato né stili overfittati, nato per la creatività,
per far mostrare al modello di diffusione la sua vera natura (anche se il tasso di errore è alto)
---
NSFW sbloccato
---
RedCraft DRD (De-Re-Distilled) NewReveal.4M per 20 passi
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
"Possa questo San Valentino riempire i vostri cuori di amore e gioia. Auguro a tutti una giornata circondata da affetto e momenti preziosi." 🌹🌹🌹🌹🌹🌹
Felice San Valentino! 情 人 节 快 樂 14/2/2025
Felice Anno Nuovo del Serpente
Preparati al nuovo modello F.1 Schnell FT — RUSHReveal·Schnell 「绝情 · 抽卡机」
Miglior rifinitore per IL / PONY / XL / MJ / SD15
Nuovo Reveal ULTRA 08/02/2025
De-distillazione ultra alta qualità (trainabile)
CFG restore a 1 per mantenere stessa velocità di F.1 DEV
LoRA Compatibilità completa De-Distill UH Material (trainabile)
[ ALIMENTATO DA FLUX Aesthetics Enhancement LoRA ]
NSFW sbloccato
---
RedCraft DRD (De-Re-Distilled) NewReveal.4M per 20 passi
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
Dr Wikeeyang's ultime ricerche
Flux1-Dedistilled 3.0
F.1 Distilled2PRO leaked 🏴☠️
https://civitai.com/models/941929/flux1-dedistilledmixtuned
NewREVE[AL Rilascio anticipato 22/1
F.1 DEV LoRA Ecosistema Compatibilità totale
De-distillazione ultra alta qualità (trainabile)
CFG restore a 1 per mantenere stessa velocità di F.1 DEV
LoRA Compatibilità completa De-Distill UH Material (trainabile)
[ ALIMENTATO DA FLUX Aesthetics Enhancement LoRA ]
---
Il modello si basa su versione F.1 Distilled2PRO de-distillata "leaked" (attualmente pubblica):
Flux1-DedistilledMixTuned V3 versione escape (Pubblicata)
Flux1-DedistilledMixTuned - v3.0 fp8 | Flux Checkpoint | Civitai
---
Aggiornato modello base flux DEV versione 4k ultra HD EOR v3:
Flux.1 Dev Edge of Reality reale-bordo - v3 | Flux Checkpoint
Aggiunto peso modello base RED.2 [ArtAUG] BF16 per estetica:
RedCraft | 红潮 CADS - RED.2 BF16 (ArtAug) | Flux Checkpoint
---
NSFW sbloccato
---
RedCraft DRD (De-Re-Distilled) NewReveal.4M per 20 passi
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
---
SOTA capacità adattativa per Tutte le All-F.1-LoRA!
Ringraziamenti speciali
Opere eccellenti di SHM_AI:
SHM Realistic - v4.0 | Stable Diffusion Checkpoint | Civitai
Opere eccellenti di HudujnikBezKisty:
The Super Realistic - TSR 2.0 | Stable Diffusion Checkpoint | Civitai
Opere eccellenti di Astraali:
AstrAnime - AstrAnime_V6 | Stable Diffusion Checkpoint | Civitai
E a tutti quelli che hanno contribuito silenziosamente a SD1.5
SD15RelustionHD rilascio 18/1
Relustion1.5HD pubblicazione alta definizione 18/1/2025
Basato su RETROSD e HD4K ricostruito SD1.5
Tornando ai giorni gloriosi dell’era SD!
Returning to the glorious years of SD!
CFG 5-7 DPM++2M /EulerA | SGM Uniform
Miglior numero di passi 25~30, VAE incluso
Risoluzione design Hi-RES 0.9M (92 milioni pixel)
Per alta definizione diretta attivare scaling UNET o chunking script
[ Basato su FP32 precisione completa, prima versione FP16 ]
RETRORelustion2 Pubblicazione gloriosa 16/1
Basato su RETROSD / FLUX Reveal / EDGE4k per modello fotografico realistico est-asiatico Illustrious FT
Tornando ai giorni gloriosi dell’era SD! Returning to the glorious years of SD!
CFG 5 Deis | EulerA | SGM Uniform
Miglior numero passi 25-30, compatibile con acceleratori Hyper/DMD2/TDD
Risoluzione design Hi-RES 2M (200 milioni pixel), scaling UNET abilitato
Grazie moltissimo a tutti per il supporto!
PONYRelustion2 Rilascio felice 11/1
Basato su serie FLUX Reveal / EDGE4k, modello 32-bit fotografico realistico est-asiatico PONY
Modello FP32 completo (12.92 GB) ad alta precisione, senza distillazione né contaminazione, uso VRAM BNB 7GB
Prima versione FP32 pubblicata, creatività illimitata nel mondo PONY!
Favorisce creatività illimitata nel mondo PONY!
CFG 5 Deis | EulerA | SGM Uniform
Miglior numero di passi ~25, compatibile con acceleratori Hyper/DMD2/TDD
Risoluzione design Hi-RES 2M (200 milioni pixel), proporzioni mantenute con super adattabilità
Aspect ratio come la capacità ULTRA adattativa di PONY
Obiettivo: modello base maturo di alta qualità e creatività nel mondo PONY!
Grazie di cuore a tutti per il continuo supporto!
Ringraziamenti speciali
per i loro eccellenti contributi all’ottimizzazione dei parametri!
RED.2 15.2 GB(BF16) 8/1/2025
ALIMENTATO DA FLUX Aesthetics Enhancement LoRA
Laboratorio di Intelligenza Computazionale presso ECNU
RED.2 valutazione estetica basata su DiffSynth-Studio progetto di allenamento interattivo di generazione comprensiva ArtAug
 Paper: https://arxiv.org/abs/2412.12888
Paper: https://arxiv.org/abs/2412.12888
Modello: ModelScope, HuggingFace
Demo: ModelScope, HuggingFace (in arrivo)
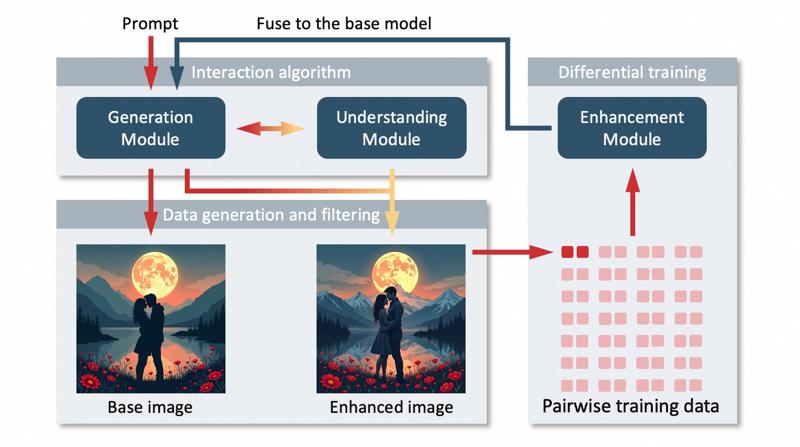
Il processo di allenamento di ArtAug consiste nei seguenti passi:
Interazione Sintesi-Comprensione: dopo generazione immagine col modello di generazione, si analizza contenuto con modello multimodale grande linguaggio (Qwen2-VL-72B) che suggerisce modifiche per rigenerare immagine migliorata.
Generazione e filtraggio dati: la generazione interattiva richiede lunga inferenza e a volte povera qualità. Si genera un grande batch offline di coppie immagini, si filtra e usa per allenamento successivo.
Allenamento differenziale: si usa allenamento differenziale per LoRA, insegnandogli differenze tra immagini prima e dopo miglioramento, non direttamente il dataset ampliato.
Miglioramento iterativo: il modello LoRA allenato si fonde nel modello base; processo ripetuto più volte fino a che l’algoritmo interattivo non apporta più miglioramenti significativi. I modelli LoRA prodotti in ogni iterazione sono combinati per produrre modello finale.
Questo modello integra la comprensione estetica di Qwen2-VL-72B in FLUX.1[dev], migliorando qualità immagini generate.
Uso
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
Generazione senza acceleratore con 25 passi
Acceleratore raccomandato per RED.2 : RED-AIGC / TDD
Target-Driven Distillation: Consistency Distillation con selezione tempo target e guida decoupled
Generazione con TDD-distilled RED.2 in solo 4-8 passi
Scala peso acceleratore distillazione a 0.12~0.13
[ Usare Re-sampling con Sampler LCM/EulerA dà risultati migliori ]
I modelli a questo link sono in relazione parallela, non upgrade di versione
I modelli in questo link sono in relazione parallela, non versioni successive
Le differenze si trovano nella sezione 'Informazioni su questa versione' a destra
Descrizioni versioni diverse nella lista ‘About this version’ a destra
Segue lista modelli list of models:
TURBO Reveal2 Primo rilascio di Natale! Merry Christmas!
(HOTFix v2.1 caricato - Migliorata adattabilità Lora)
Basato su Reveal NSFW integrando più ritratti!
Reveal2 Turbo 8-10 passi
Combinazione di più ritratti sulla base di Reveal NSFW
RedCraft | 红潮 CADS - Reveal2 TURBO
Auguri di buone feste!
Questo modello non usa pesi de-distillati
Does not use any De-distilled weights
PONY Relustion Celebrazione solstizio d’inverno Winter Solstice Festival
Design prioritario creativo basato su stile realistico di alta qualità
↳ RedCraft | 红潮 CADS - PONY Relustion
Design creativo prioritario basato su stile realistico di alta definizione
Sono passati sette mesi dall’ultimo rilascio modello PONY:
MIST XL Hyper Character Style Model versione accelerata
Chi è interessato può rivedere il primo modello Hyper-PONY super veloce online
Reveal NSFW
Modello FT FP8 DEV di FLUX.1, focalizzato su lunghe relazioni amorose e body art:
↳ RedCraft | 红潮 CADS - Reveal NSFW
Modello FT FP8 DEV FLUX.1 con azioni romantiche e arte del corpo
Reveal3 ULTRA
(HOTFix v3.2 - caricamento PENE)
Versione alta definizione combinando FLUX.1 DEV e tecnica de-distillazione:
↳ RedCraft | 红潮 CADS - Reveal3 uncensored
Update alta definizione Reveal tramite ottimizzazione qualità De-Re-Distillation
Relustion IL NSFW
Versione FT fotografica realistica del modello Illustrious XL addestrato completamente SDXL:
↳ RedCraft | 红潮 CADS - Relustion IL NSFW
FT realistica di Illustrious XL, ottimizzazione completa su base SDXL
Relustion ULTRA
Versione HD che migliora ulteriormente il realismo di Relustion IL:
↳ RedCraft | 红潮 CADS - Relustion ULTRA
Versione alta definizione che potenzia realismo su Reliability IL
Relustion XL
Versione HD quantizzata basata su SDXL CADS3 combinata con dataset NSFW:
↳ RedCraft | 红潮 CADS - Relustion XL
Versione HD quantizzata basata su CADS3 e dataset NSFW, usata per affinamento HD di modelli FLUX e IL
RASCH.1 / 2
Due diversi modelli Schnell de-distillati FT, combinati con stile RED.1 ad alta velocità:
↳ RedCraft | 红潮 CADS - RASCH.2
↳ RedCraft | 红潮 CADS - RASCH.1 Forge
ReFLEX NSFW
Modello di disegno anime Schnell NF4 che punta a stabilità strutturale e fedeltà prompt:
↳ RedCraft | 红潮 CADS - REFLEX NSFW
Modello ad alta velocità mescolato RED.1 su diversi modelli Schnell De-distillati FT
Conferendo accuratezza prompt, modello Schnell De-Re-Distilled soddisfa velocità e qualità,
e modelli distillati offrono stabilità intrinseca degli arti e dello stile, anche in versione quantizzata a 4bit con ottimi risultati
Uso VRAM 6~10GB, output immagine in 4-8 passi, velocità elevata (particolarmente adatto per creazione stili artistici e modelli decorativi architettonici)
Segue introduzione alla serie RedCraft e al modello base estetico Red.1
RedCraft RED.1
BF16 CADS Commercial & Advertising Design System
Probabilmente il miglior modello base BF16 rapido (meno di 10 passi) ad alta qualità e ricchezza di dettagli finora disponibile.
Modello di qualità fine per 10-20 passi, in alcuni dettagli supera i modelli Flux ed è vicino ai modelli da 20 miliardi di parametri.
Basato su METAFILM AI - Commercial & Advertising Design System, unione di flux-dev-de-distill, rifinito da ComfyUI, Block_Patcher_ComfyUI, ComfyUI_essentials e altri strumenti. Raccomandati 10-20 passi. Qualità molto superiore ad altri modelli 12B.
Basato su
De-Distill & CADS materiale commerciale FP16
Supporta generazione online ComfyUI WebUI
10-20 passi Euler / DPM++2M | beta / SGM_Uniform
CFG 3-3.5
CFG reale va impostato (ignorare guida o impostare 0)
——————————————————————————
Versioni con AIO (All in one) includono UNET + VAE + CLIP L + T5XXL (fp8). Note anche come Checkpoint o versione compatta.
Usare BNB NF4 e GGUF quants in ComfyUI richiede installazione di nodi custom per loader speciali:
NF4 + supporto Lora: https://github.com/bananasss00/ComfyUI_bitsandbytes_NF4-Lora
(obsoleto) NF4 UNET: https://github.com/DenkingOfficial/ComfyUI_UNet_bitsandbytes_NF4
(obsoleto) NF4 checkpoint AIO: https://github.com/comfyanonymous/ComfyUI_bitsandbytes_NF4
Per usare versioni UNET serve anche scaricare ENCODER TESTO e VAE.
Se non li hai, scaricali qui:
T5XXL - CLIP L: https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main
GGUF T5XXL: https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf
VAE: https://huggingface.co/black-forest-labs/FLUX.1-schnell/tree/main/vae
Posiziona modello in "models/diffusion_models" o "models/unet", entrambi gli encoder testo in "models/clip" e vae in "models/vae".
In ComfyUI, usa workflow flux standard o aggiungi nodi 'Load Diffusion Model', 'DualClipLoader' e 'Load VAE' per sostituire loader checkpoint e completare setup.
In Forge, imposta opzione "Diffusion in low bits" a "bnb-nf4"
Grazie a city96 per script quantizzazione gguf.
Grazie a reddit user a_beautiful_rhind per script quantizzazione bnb.——————————————————————————
Si consiglia versione finetuned 8bit di Yang Laoshi:
Flux1-DedistilledMixTuned-V1 - v1.0 fp8 | Flux Checkpoint | Civitai
Probabilmente il miglior modello accelerato finora trovato conforme a stile ufficiale e con ottimi risultati
Consigliato:
Versioni UNET (solo modello) richiedono encoder testuali e VAE, si consiglia usare i seguenti CLIP e modelli encoder testo per guida prompt migliorata:
Encoder Testo: https://huggingface.co/silveroxides/CLIP-Collection/blob/main/t5xxl_flan_latest-fp8_e4m3fn.safetensors
VAE: https://huggingface.co/black-forest-labs/FLUX.1-schnell/tree/main/vae
Versione GGUF: serve installare nodi di supporto GGUF, https://github.com/city96/ComfyUI-GGUF
Workflow semplice: workflow molto semplice mostrato sotto, non serve altro nodo custom ComfyUI (per versione GGUF usare nodo UNET Loader(GGUF) di city96):

Grazie a:
https://huggingface.co/wikeeyang, Wikee Yang per il finetune preciso del modello 8-bit e fornitura dettagli modello; info qui:
wikeeyang/Flux.1-Dedistilled-Mix-Tuned-fp8 · Hugging Face
https://huggingface.co/Anibaaal, Flux-Fusion è un ottimo modello mixato e rifinito.
https://huggingface.co/nyanko7, Flux-dev-de-distill è un ottimo progetto sperimentale! Grazie per gli script inference.py.
https://huggingface.co/MonsterMMORPG, Furkan condivide molti test e tuning modelli Flux.1, test speciali per de-distill modello.
https://github.com/cubiq/Block_Patcher_ComfyUI, cubiq con patcher Flux blocks mi ha permesso molti test su come i parametri dei blocchi Flux.1 influenzano le immagini. Il suo ComfyUI_essentials include nodo FluxBlocksBuster per facilitare la regolazione blocchi. Gran lavoro!
https://huggingface.co/twodgirl, condivide script quantizzazione e dataset di test.
https://huggingface.co/John6666, condivide script di conversione modello e raccolte modello.
https://github.com/city96/ComfyUI-GGUF, supporto nativo per modelli quantizzati GGUF.
https://github.com/leejet/stable-diffusion.cpp, fornisce script convertitore puro C/C++ per modelli GGUF.
In Cina già pubblicato su Modelscope community per download veloce!
RedCraft | 红潮 CADS Commercial & Advertising Design System · Model Repository
Unica piattaforma online (comunità gratuita) a supportare generazione di modelli FLUX de-distillati:
AIGC Zone - Generazione Immagini · Modelscope
Piattaforma unica che supporta generazione online modelli FLUX de-distillati (gratuita community).

Presto anche su Huggingface.co
————————————————————————————————————————
Per problemi di test lascia messaggio, per collaborazioni vedi homepage personale +V Zyuan980
Essere un buon assistente, servire gli artisti. Ulteriori informazioni: https://x1f3ewlrcf.feishu.cn/wiki/BjJ1waQaLitPB4k7Lbvc0MaVnzb?fromScene=spaceOverview&open_tab_from=wiki_home
————————————————————————————————————————

Dettagli del Modello
Tipo di modello
Modello base
Versione del modello
Hash del modello
Creatore
Discussione
Per favore log in per lasciare un commento.
Collezione di Modelli - RedCraft | 红潮 CADS | Updated-JUN29 | Latest - Red-K Kontext DEV NSFW

RedCraft | 红潮 CADS | Aggiornato-GIU29 | Ultimo - Red-K Kontext DEV NSFW - Reveal5[SFW]ULTRA

RedCraft | 红潮 CADS | Aggiornato-GIU29 | Ultimo - Red-K Kontext DEV NSFW - 赩梦|REDiDream(NSFW i1)






































