AlbedoBase XL - v1.1
ハイライトされた画像



推奨ネガティブプロンプト
strabismus
inconsiderate details
推奨パラメータ
samplers
steps
cfg
resolution
vae
推奨ハイレゾパラメータ
upscaler
upscale
steps
denoising strength
ヒント
画像生成で結果が出ない場合は、CLIP SKIP 2に切り替えるか、プロンプトの単語順や表現を少し変更してみてください。
文章形式のプロンプトを使うとタグリスト形式よりも画質が向上しやすいです。
ネガティブプロンプト欄を空欄にしておくと、より良い画像が得られることが多いです。
使用前に仕様グリッドをチェックして最適な設定を確認してください。
『strabismus(斜視)』など特定のネガティブプロンプトを試して、非対称の目やピクセル化などの問題を改善してみてください。
バージョンのハイライト
クリエイタースポンサー
このモデルに価値を感じたら、ご支援をご検討ください。寄付はすべてSDXLコミュニティの発展に使われます。
🙋🏼♂️ 参加はこちら(discord) ㅤ|ㅤ 🛒 購入 ㅤ|ㅤ 🌱 寄付
このモデルが役に立ったと感じたら、ぜひご支援をご検討ください。いただいた寄付はすべてSDXLコミュニティの発展に充てられます。
🙋🏼♂️ 参加はこちら(discord) ㅤ|ㅤ 🛒 購入ㅤ |ㅤ 🌱 寄付
AlbedoBase XL (SFW&NSFW)
リファイナーは不要で、VAEが含まれています。
目的
Stable Diffusion XLは35億パラメータ(リファイナーを除く)を持ち、SD v1.5の約3.6倍の規模です。この数字は単なる数値ではなく、性能向上につながる重要な要素だと考えています。
コミュニティの爆発的な貢献によりSD v1.5の全体的な性能が想像を超えて向上したことを実感して久しく、その性能向上をこのXLバージョンでも最適に再現するためにAlbedoBase XLモデルの完成を目指しています。
公開されているすべてのCheckpointとLoRAの性能を直接テストし、複数のフィルターを通過した最適と判断されたリソースのみを統合することを目標としています。これによりMidjourneyなどの企業の画像生成AIを超える性能を実現します。
現在、AlbedoBase XL v3.1 Largeは約200の選択されたチェックポイントと251のLoRAを統合しています。
ログ
v3.1-Large
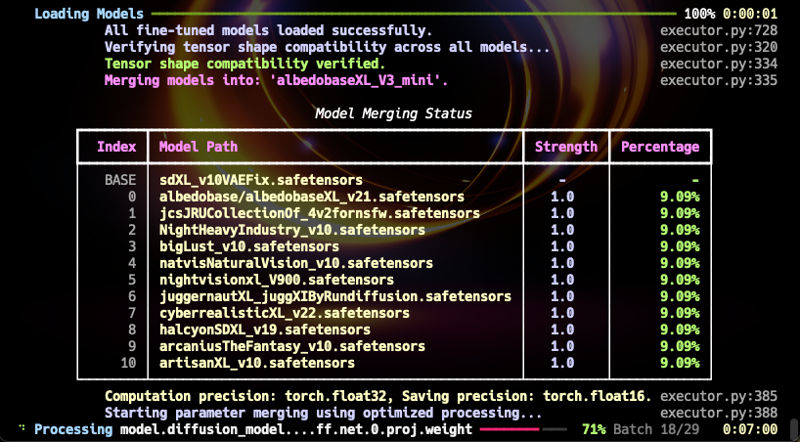
• V3で使用された再帰スクリプトを用いて、50以上の最新のSDXLモデルバージョンを統合しました。
仕様グリッド(370.7 MB): ダウンロード


v3-mini
長らくお待たせして申し訳ありません。
個人的な事情や健康問題に直面しながら新バージョンの開発に取り組んできました。このメッセージを書いている今もなお困難と闘っています。
簡単な報告だけでは足りないと感じ、この詳細な説明をお伝えいたします。
バージョン2.0のリリース以来、独学で深層学習を勉強してきました。正式な学位はなく、プログラミングの適性も低いため、多大な時間と労力を費やしても目覚ましい成果は達成できていません。それでも自己主導の学習と研究の経験は私の人生でかけがえのない宝です。
最近、バージョン2.0以降何百もの公式や手法を改良し、SDXL1.0とSD1.5を基に精選したモデルを5つの主要カテゴリー「ANIME」「REALISM」「ARTISTIC」「NSFW」「BASE」に分類して統合アルゴリズムに入力する新しい突破口となる手法を開発しました。この方法は魅力的な成果を生み出しています。
しかし、性能テスト段階は非常に困難で、肉体的・精神的に大きく消耗し、この作業を単独で続けることは難しいと判断しました。これがこのバージョンをリリースする決断に至った理由です。
このたび待望のAlbedoBaseXL V3 Miniバージョンをリリースできることを嬉しく思います。このモデルは小規模統合ながら特定の領域に限らず多方面で優れた性能を発揮し、SDXL1.0の新たなベースモデルとして活躍できます。(私の統合アルゴリズムは線形統合ではないため、本質的に新しいファインチューニングモデルと見なせます。)
このモデルは既存のAlbedoBaseモデルと同様に多用途で、すべての以前のバージョンを凌駕します。(NSFWコンテンツは過激ではありませんが、v2.1など以前のバージョンに比べて表現の幅が広がっています。専用のNSFW統合モデルも今後リリース予定です。)
一方で、最近多くの共有モデルに統合や外部商業利用を禁止するライセンスが導入されていることを残念に思っています。これにより、優れたモデルを統合に活用できないことが増えています。
多くの時間と労力をかけて高品質モデルを無料ライセンスで提供してくださった開発者の皆様に心より感謝申し上げます。
また近いうちに戻ってきます。
ANIME、REALISM、ARTISTIC、2.5D、3D、NSFWなど多岐にわたる分野での性能テストを心からお待ちしています。
モデル開発者は種をまくだけであり、それを育て花や実を実らせてくださるのはユーザーとアーティストの皆様です。
いつもありがとうございます。
私の活動を少額で支援してくださる方は、以下のリンクをご検討ください。現在、就職が困難で生活の見通しが立っていません。
仕様グリッド(380.5 MB): ダウンロード


v2.1
新しい統合アルゴリズムと公式を使ってv0.1から2.0までを再統合および調整。
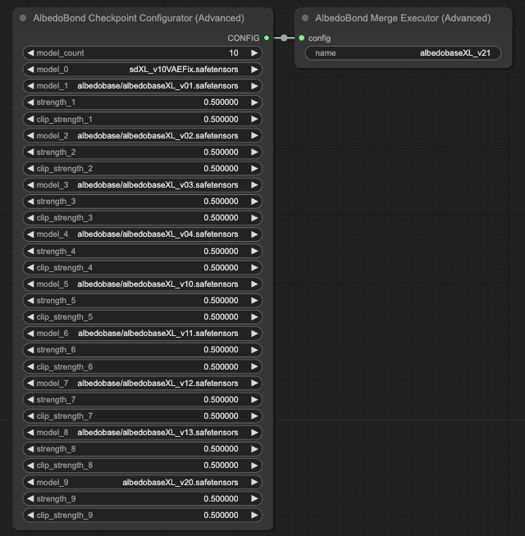
仕様グリッド(424.5 MB): ダウンロード

v2.0
AlbedoBase XL Preの開発に携わってくださった皆さまに感謝します。皆さまのおかげでリリース日を大幅に前倒しできました。ありがとうございます!
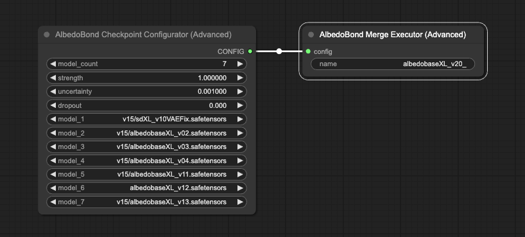
既存のAlbedoBase XLモデルを一つに収束させるカスタムスクリプトを作成し、独自の公式に基づいてすべてのU-NETおよびCLIPブロックの行・列の重みを精密に調整しました。
画像生成で何も生成されないバグが発生した場合は、CLIP SKIP 2に切り替えるか、プロンプトの順序や表現を少し変更してください。CLIPが認識しにくいプロンプトの組み合わせがある可能性があります。その場合、言葉の順番を変えたり、異なる単語にしたり、最も簡単にはCLIP SKIPを変えてみてください。今後v1.3のようにこれらの問題を徐々に解決していきます。
仕様グリッド(403.5 MB): ダウンロード
v1.3
モデルのランダム性に関する品質を示すため、サンプリング用のすべてのショーケース画像のシード値を「9」に統一し、即時生成しました。
特にこのバージョンでは、ネガティブプロンプトの影響が大きいため、ネガティブプロンプト欄を空欄にすることが高品質な結果を得るために推奨されます。
仕様グリッド(438.7 MB): ダウンロード

ご覧のように、Stepsを増やすことですべてのサンプラーに対応可能となり、品質も向上します。
下記のように、私が開発・統合したLoRAの効果により、タグリスト形式よりも文章形式のプロンプトの使用が品質向上に直接つながります。
45のチェックポイントと7のLoRAを統合しました。その後、AlbedoBase v0.4およびv0.3を順に0~5%未満で統合し、劣化した統合モデルを再活性化しています。
7つのLoRAのうち1つは私が作成したもので、GPT4-Vを使用して計174枚の高品質な絵画写真のキャプションを解析・注釈付けしました。このLoRAを統合することで驚くほど鮮明な画像とプロンプトの高度な理解を実現しました。
私が自作したLoRAは、Ko-fiのCreativeレベル以上の支援者のみ購入可能です。
v1.2
22の最新チェックポイントを統合しました。
仕様グリッド(565.6 MB): ダウンロード
v1.1
安定化。
詳細化。
上級ユーザーと思われる方にはv1.0を推奨します。v1.0では適切な設定を見つければより鮮明な作品を出力可能です。
仕様グリッド(349.7 MB): ダウンロード
v1.0
106のLoRAを統合。
19のチェックポイントを統合。
モデルは設定によって結果が変わるため、使用前に仕様グリッドを確認することが重要です。
非対称な目やピクセル化の問題を解決するために特定のネガティブプロンプトの使用が有効です。仕様グリッドはCPUやGPUの環境によって異なる場合があるため参考程度にご利用ください。統合LoRAが増えるにつれてすべての設定を均一に満たすのは難しいですが、v1.0の利点として適切な設定で驚異的な品質の作品が作成可能な点に注目してください。より安定したバージョンで戻ってきます。
ショーケースや他のユーザーの設定を検索して有用な設定値を見つけることができます。
常にネガティブプロンプトは空欄にするのが最良です。
v1.0は多くの労力を費やしたため、しばらく休息を取ります。モデルを楽しんで使っていただき、統合したモデルはCivitaiで無料共有していただけると嬉しいです。そうすることで皆で改良を続けられます。
仕様グリッド(479.4 MB): ダウンロード
v0.4
132のLoRAを統合。
4のチェックポイントを統合。
仕様グリッド: ダウンロード
v0.3
すべてのサンプラーにおいて改善。
リアルな写実性を達成。
安定化。
仕様グリッド: ダウンロード
v0.2
鮮明さとディテールの大幅な改善。
手足の表現向上。
美学面の大幅な改良:構図、抽象性、流れ、光と色など。
v0.1
SDXL1.0モデルに適切にファインチューニングした上で、Civitaiで公開された40以上の高品質モデルを精緻かつ意図的に統合。
主に最小限のプロンプトトークン数で最大品質を目指したテストであり、トークン数が多い場合の品質向上は未検証です。(ご自身でのテストと結果共有をお願いします)
最も美しい結果は一般的にリアリズムとアニメーションの中間点で得られます。
それでも適切なプロンプトを使えば表現できないものはほぼなく、他を凌駕する統合基盤モデルとしての価値を持つと主張します。ただし現状はv0.1であることをご理解ください。

モデル詳細
モデルタイプ
ベースモデル
モデルバージョン
モデルハッシュ
学習済みワード
作成者
ディスカッション
コメントを残すには log in してください。






































