Animagine XL 4.0 - v4 Opt
ハイライトされた画像





推奨プロンプト
1girl, firefly (honkai: star rail), honkai (series), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
masterpiece, high score, great score, absurdres
1girl, sensitive, looking at viewer, solo, masterpiece, high score, great score, absurdres
推奨ネガティブプロンプト
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
推奨パラメータ
samplers
steps
cfg
resolution
ヒント
タグベースのキャプションとタグ順序付け法を使うと良い結果が得られます:1girl/1boy/1other、キャラ名、シリーズ名、評価、その他タグ、最後に品質向上タグ。
プロンプトの最後に品質向上タグを追加してください:masterpiece、high score、great score、absurdres。
望ましくないアーティファクトやエラーを避けるため推奨ネガティブプロンプトを使用しましょう。
最適なCFGスケールは4〜7の間で、推奨は5です。
最適なサンプリングステップは25〜28の間で、28が推奨です。
推奨サンプラーはEuler Ancestral(Euler a)です。
複雑な解剖学や画像中のテキスト生成に課題がある制限を踏まえてください。
最近のキャラクターは訓練データ不足で精度がやや低い場合があります。
バージョンのハイライト
Animagine XL 4.0 Opt(最適化版)のリリースにより、追加データセットを用いたさらなる改良が加えられ、一般用途向け性能が向上しました。アップデート内容は以下の通りです:
より一貫した出力のための安定性向上
より正確なプロポーションによる解剖学の強化
生成時のノイズやアーティファクトの削減
彩度低下問題の修正により、色彩を豊かに
より魅力的な結果のための色精度の向上
クリエイタースポンサー
Animagine XL開発支援のお願い
- ETH/USDTを下記アドレスへ寄付:
0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C - GitHub Sponsors: https://github.com/sponsors/cagliostrolab/
- Discordコミュニティに参加:https://discord.gg/cqh9tZgbGc
詳しいプロンプトガイドラインは Cagliostrolabブログ をご覧ください
概要
Animagine XL 4.0(別表記:Anim4gine)は究極のアニメテーマ特化型ファインチューンドSDXLモデルで、最新のAnimagine XLシリーズです。継続モデルですが、元はStable Diffusion XL 1.0から再訓練されており、様々なソースから集めた840万枚の多様なアニメ風画像データセットを用い、2025年1月7日までの知識カットオフで約2650 GPU時間かけてファインチューニングされています。前バージョン同様に、タグ順序付けメソッドでアイデンティティとスタイルの学習を行っています。
Animagine XL 4.0 Opt(最適化版)のリリースにより、追加データセットを用いてさらに改善され、安定性、解剖学的精度、ノイズ低減、色の彩度、そして全体的な色精度が向上しました。これにより、Animagine XL 4.0 Optはシリーズの特徴である品質を維持しつつ、より一貫して視覚的に魅力的な成果物を提供します。
変更履歴
- 2025-02-13 – Animagine XL 4.0 Opt と Animagine XL 4.0 Zero を追加
より一貫した出力のための安定性向上
より正確なプロポーションによる解剖学の強化
生成時のノイズやアーティファクトの削減
低彩度の問題を修正し、色彩を豊かに
より魅力的な結果のための色精度の向上
- 2025-01-24 – 初版リリース
モデル詳細
モデルタイプ: 拡散ベースのテキストから画像生成モデル
ライセンス: CreativeML Open RAIL++-M
モデル説明: テキストプロンプトに基づき特にアニメ風画像を生成・修正可能なモデル
ファインチューンド元: Stable Diffusion XL 1.0
使用ガイドライン
プロンプトガイドラインは下記図の要約を参照してください。

1. プロンプト構造
本モデルはタグベースキャプションとタグ順序付け法で訓練されています。以下の構造的テンプレートを使用してください:
1girl/1boy/1other, キャラクター名, シリーズ名, 評価, その他タグを任意順で書き、最後に品質向上タグを付ける
2. 品質向上タグ
プロンプトの最後にこれらのタグを追加してください:
masterpiece, high score, great score, absurdres
3. 推奨されるネガティブプロンプト
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
4. 最適な設定
CFGスケール: 4-7(推奨は5)
サンプリングステップ: 25-28(推奨は28)
推奨サンプラー: Euler Ancestral (Euler a)
5. 推奨解像度
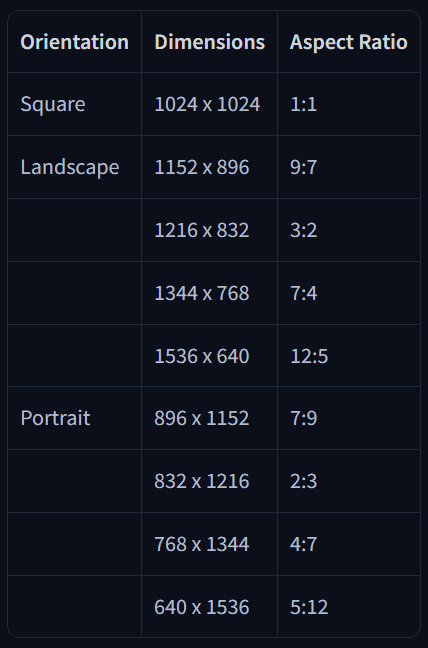
6. 最終プロンプト構造例
1girl, firefly \(honkai: star rail\), honkai \(series\), honkai: star rail, safe, casual, solo, looking at viewer, outdoors, smile, reaching towards viewer, night, masterpiece, high score, great score, absurdres
特殊タグ
本モデルは、画像生成の様々な側面を制御するための複数の特殊タグをサポートしています。これらのタグは入念に重み付け・検証されており、異なるプロンプトでも一貫した結果を提供します。
品質タグ
品質タグは画像の総合的な品質やディテールレベルに直接影響を与える基本コントロールです。利用可能な品質タグ:
masterpiecebest qualitylow qualityworst quality
スコアタグ
スコアタグは基本的な品質タグに比べ、より微妙で詳細な品質調整を可能にし、このモデルでは出力品質の制御に強く影響します。利用可能なスコアタグ:
high scoregreat scoregood scoreaverage scorebad scorelow score
時間タグ
時間タグは特定の年代や年次を基にした芸術スタイルに影響を与えるためのものです。時代特有の芸術性を持つ画像生成に役立ちます。対応年タグ:
year 2005year {n}year 2025
レーティングタグ
生成される画像の内容安全度を制御します。責任を持って使用し、関連法令やプラットフォームの方針を順守してください。対応レーティング:
safesensitivensfwexplicit
トレーニング情報
本モデルは最先端のハードウェアと最適化されたハイパーパラメータにより最高品質の出力を目指して訓練されました。以下は訓練時に用いられた詳細な技術仕様とパラメータです:

謝辞
この長期プロジェクトは、Stability AI、Novel AI、Waifu Diffusion Teamによる画期的な作業、革新的な貢献、充実したドキュメントなしには成し得ませんでした。特にV2以降の進展を可能にしたMainからのキックスターター助成に心から感謝します。このバージョンに際し、コミュニティの皆様の継続的な支援に深く感謝いたします。特に:
Moescape AI: モデル配布およびテストの重要な協力パートナー
Lesser Rabbit: 重要な計算資源および研究助成の提供
Kohya SS: 包括的なオープンソース訓練フレームワークの開発
discus0434: 先進的なオープンソースAesthetic Predictor 2.5の作成
初期テスター: 重要なフィードバックと品質保証の提供に尽力
貢献者
本プロジェクトに多大な貢献をした献身的なチームメンバーに心より感謝します。代表的なメンバーは以下の通りです:
モデル
Gradio
関係者・財務・品質保証
データ
募金活動が再開されました!
GitHub Sponsorsを通じた新しい募金方法を導入し、トレーニング、研究、モデル開発を支援しています。皆様のご支援がAIの可能性を広げる力となります。
ご支援いただける内容:
寄付: 下記アドレスへETHまたはUSDTでご寄付ください。
共有: モデルについて広め、作品を共有しましょう!
フィードバック: 改善点をお知らせください。
寄付アドレス:
ETH/USDT/USDC(e): 0xd8A1dA94BA7E6feCe8CfEacc1327f498fCcBFC0C
Githubスポンサー: https://github.com/sponsors/cagliostrolab/
なぜ暗号通貨を使うのか?
かつてKo-fiやPayPalで募金を受け付けていた際、PayPalアカウントがプロジェクトの目的説明を尽くしても不正と判断され停止されてしまいました。そのため全ての募金を返金し、信頼できる支援受領手段が無くなりました。こうした問題を避け、透明性を保つため、現在は暗号通貨での募金方法を採用しています。
暗号通貨以外で寄付したい場合
PayPalでの経験は良くなかったものの、暗号通貨を使わずに支援したい方は、 Discordサーバーで代替募金方法をお問い合わせください。
Discordサーバーに参加しよう
ぜひ当サーバーへお越しください: https://discord.gg/cqh9tZgbGc
制限事項
プロンプト形式: タグベースのテキストプロンプトに限定。自然言語入力は効果的でない可能性があります。
解剖学: 複雑な解剖学的ディテール、特に手のポーズや指の本数には弱いです。
テキスト生成: 画像内のテキスト描画は現状サポートせず推奨されません。
新しいキャラクター: 訓練データ不足により最近のキャラクターは精度が低い場合があります。
複数キャラクター: 複数キャラシーンは慎重なプロンプト設計が必要です。
解像度: 元のSDXL解像度で訓練されているため、高解像度(例:1536x1536)では劣化が見られるかもしれません。
スタイル一貫性: アイデンティティ保持に重きを置いたトレーニングのため、スタイル一貫性には特定タグが必要となる場合があります。
ライセンス
本モデルはStability AIのCreativeML Open RAIL++-M ライセンスをオリジナルのまま変更・追加制限なく採用しています。ライセンス条件は元のSDXLライセンスのままで、以下を含みます:
✅ 許可されていること: 商用利用、改変、配布、個人使用
❌ 禁止されていること: 違法行為、有害コンテンツ生成、差別、搾取
⚠️ 要件: ライセンス文書の同梱、変更の明示、通知の維持
📝 保証: 「現状のまま」で保証なし
詳細かつ正式な条件は元のSDXLライセンス文書を参照してください。

モデル詳細
ディスカッション
コメントを残すには log in してください。
モデルコレクション - Animagine XL 4.0
「Animagine XL 4.0 - v4 Opt」による画像
アニメ画像










基本モデル画像

sdxl画像


