Anime Illust Diffusion XL - v0.61
ハイライトされた画像


推奨プロンプト
Trigger word (by xxx),a girl named frieren from sousou no frieren series,best quality,beautiful color,detailed,aesthetic,impasto style,cowboy shot,fantasy theme,gradient background,sitting on ground,expressionless,white hair,twintails,green eyes,parted lip,white dress,frills,a cat,grass,sunshine
best quality, 1girl, solo, looking at viewer, bangs
推奨ネガティブプロンプト
(worst quality:1.3),low quality,lowres,messy,abstract,ugly,disfigured,bad anatomy,draft,deformed hands,fused fingers,signature,text,multi views
aidxlv05_neg
推奨パラメータ
samplers
steps
cfg
resolution
vae
推奨ハイレゾパラメータ
denoising strength
ヒント
アーティストスタイルのトリガーワードの重みは(例:(by xxx:0.6))で減らす。
プロンプト内タグの順序を整えるとモデルが意味を理解しやすく、推奨タグ順序を参考に。
text2image出力がぼやけている場合は『リファイン』(image2imageやインペインティング)を使う。
スタイルマージの場合、重みと順序をコントロールし、スタイル語は前置せず末尾に追加。
キャラクタートリガーワードは通常服装を含まないため、服装タグは別途追加する。
バージョン0.61以下は、モデル専用のネガティブテキスト埋め込みを使うと最良結果。
生成する解像度は総ピクセルが約1024×1024かつ幅高さが32の倍数を確保。
バージョンのハイライト
より強力なスタイライズ。
さらに、トレーニングに追加ノイズを導入しました。一部のサンプラーは最終ステップでタイムステップがゼロにならず、結果として生成画像にノイズが残る可能性があります。従って、Euler AまたはEulerサンプラーの使用を推奨します。
风格化更明显。
另外,我在训练中使用了附加噪声。部分采样器的最终时间步不会归零,因此可能导致生成的图像带有噪声。因此,Euler A 或 Euler 采样器可能更适合您使用。
クリエイタースポンサー
私たちの作品が気に入ったら、Ko-fiで支援ください:https://ko-fi.com/eugeai
計算リソース提供に@NieTaコミュニティ(nieta.art)、データ提供に@KirinTea_Aki(Civitaiプロフィール)および@Chenkin(Civitaiプロフィール)に感謝します。
モデル紹介 (英文部分)
目次
この紹介では以下について学べます:
モデル情報(セクションII参照);
使用方法の指示(セクションIII参照);
トレーニングパラメータ(セクションIV参照);
トリガーワード一覧(付録A参照)
II AIDXL
Anime Illustration Diffusion XL、別名 AIDXLは、スタイライズされたアニメイラスト生成に特化したモデルです。 800以上(アップデートにより増加中)の組み込みイラストスタイルを有し、特定のトリガーワード(付録A参照)で発動します。
長所:
従来のAIポージングではなく、柔軟な構図を実現。
乱雑な表現ではなく、洗練された詳細描写。
アニメキャラクターをより深く理解。
III ユーザーガイド
1 基本使用法
1.1 プロンプト
トリガーワード:付録Aで提供されるトリガーワードを追加し、画像のスタイル化を図ります。適切なトリガーワードは著しく品質向上に寄与します。
アーティストスタイルのトリガーワードは重みを下げることを推奨します(例:(by xxx:0.6))。
意味的ソート:プロンプト内のタグや文の順序を整理するとモデルの理解が深まります。
推奨タグ順序:トリガーワード(by xxx)-> キャラクター(例:frieren (sousou no frierenシリーズ))-> 種族(エルフ)-> 構図(カウボーイショット)-> スタイル(インパストスタイル)-> テーマ(ファンタジー)-> 主な環境(森の中、昼間)-> 背景(グラデーション背景)-> アクション(地面に座る)-> 表情(無表情)-> 主な特徴(白髪)-> 体の特徴(ツインテール、緑の瞳、唇が分かれている)-> 服装(白いドレスを着用)-> 服飾アクセサリー(フリル)-> その他アイテム(猫)-> 二次環境(草、日差し)-> 美学(美しい色彩、詳細な表現、美学的)-> 品質((最高品質:1.3))
ネガティブプロンプト:(最低品質:1.3)、低品質、低解像度、乱雑、抽象的、醜い、変形、解剖学的に不正確、ドラフト、手の変形、指の融合、署名、テキスト、多視点
1.2 生成パラメータ
解像度:総ピクセル数(幅×高さ)が約1024×1024であり、幅と高さが32の倍数であることを確保すると、AIDXLは最良の結果を出します。例:832×1216(2:3)、1216×832(3:2)、1024×1024(1:1)など。
サンプラーとステップ数:"Euler Ancester"サンプラー(webuiではEuler Aと呼ばれる)を使用します。CFGスケール7から9で約28ステップを推奨。
『リファイン』:text2image生成画像がぼやけている場合はimage2imageやインペインティング等で『リファイン』してください。
簡単なアップスケールの場合は以下参照:巨大サイズにアップスケールしSDアップスケールでディテール追加する方法 : r/StableDiffusion (reddit.com)
その他のコンポーネント:リファイナーモデルは使用不要で、モデル本体のVAEか
sdxl-vaeを利用してください。
Q:モデルカバー画像を再現するには?同じ生成パラメータでなぜ再現できない?
A:カバー画像の生成パラメータはtext2imageパラメータではなく、image2image(アップスケール)パラメータです。ベース画像はDPMサンプラーではなく、主にEuler Ancesterサンプラーで生成されています。
2 特殊使用法
2.1 一般化スタイル
バージョン0.7から、AIDXLは類似のスタイルをまとめ、一般化スタイルトリガーワードを導入しました。これらのトリガーワードは一般的なアニメイラストスタイルカテゴリを表します。ただし、一般的なスタイルトリガーワードは単語通りの美術的意味と必ずしも一致せず、再定義された特別なトリガーワードです。
2.2 キャラクター
バージョン0.7からキャラクターの強化学習を実施。いくつかのキャラクタートリガーワードはLoraの効果を達成し、キャラクターコンセプトと服装をうまく分離します。
キャラクターのトリガー方法は:{character} \({copyright}\)。例:アニメ「Cyberpunk: Edgerunners」のヒロインLucyをトリガーするにはlucy \(cyberpunk\)、ゲーム「Genshin Impact」のキャラクターGan Yuはganyu \(genshin impact\)。ここで、"lucy"と"ganyu"はキャラクター名、"\(cyberpunk\)"と"\(genshin impact\)"は出典、括弧は重み付きタグとして解釈されないようエスケープしています。いくつかのキャラクターは出典不要。
バージョンv0.8からはより簡単なトリガー方法:a {girl/boy} named {character} from {copyright} seriesも追加。
キャラクターのトリガーワード一覧はこちら参照。また、文書に記載されていないトリガーワードも含まれる場合があります。
単一キャラクタートリガーワードで完全に再現できない場合は、キャラクターの主な特徴をプロンプトに追加してください。
AIDXLはキャラクタードレスアップをサポート。キャラクタートリガーワードは通常服装特徴を含まないため、服装タグをプロンプトに追加する必要があります。例:ゲーム「Azur Lane」のキャラクターSt. Louis (Luxurious Wheels)の衣装はsilver evening gown, plunging neckline。他のキャラクターにも任意の服装タグを追加可能。
2.3 品質タグ
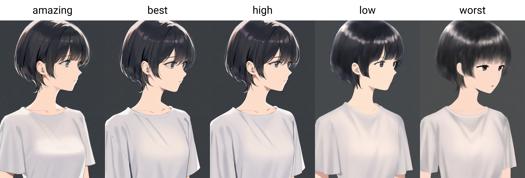
品質と美学タグは正式にトレーニングされています。プロンプトに付けると生成画像の品質に影響します。
バージョン0.7から品質タグは6段階で導入:優秀から劣悪まで、amazing quality、best quality、high quality、normal quality、low quality、worst quality。
品質タグには追加重み付けが推奨(例:(amazing quality:1.5))。
2.4 美学タグ
バージョン0.7から、美学タグが画像の特殊な美的特徴を表すために導入されました。
2.5 スタイルマージ
複数のスタイルトリガーワードを同時に使い、自作スタイルにマージできます。例:chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
いくつかのコツ:
重みと順序をコントロールし、スタイルを調整。
プロンプトに追加する時は先頭ではなく末尾に。
IV トレーニング戦略&パラメータ
AIDXLv0.1
SDXL1.0をベースモデルに約2万2千枚のラベル画像を用い、学習率5e-6、コサインスケジューラ・サイクル数1で約100エポックトレーニングしモデルAを得る。続いて学習率2e-7、他パラメータ同一条件でモデルBを得る。モデルAとBをマージしてAIDXLv0.1モデル完成。
AIDXLv0.51
トレーニング戦略
AIDXLv0.5からの継続トレーニングで、3段階パイプライン:
長文キャプショントレーニング:全データセット(手動キャプション付き含む)でU-NetとテキストエンコーダをAdamW8bit最適化、高学習率(約1.5e-6)、コサインスケジューラ。学習率が閾値(約5e-7)以下で停止。
短文キャプショントレーニング:ステップ1の出力から再開、パラメータは同じで短文キャプションのデータセット。
精製ステップ:ステップ1の高品質画像サブセット用意し、ステップ2の出力から再開、低学習率(約7.5e-7)、リスタート付きコサインスケジューラ5〜10回。美学的に良好になるまでトレーニング。
固定トレーニングパラメータ
ノイズオフセット等の追加ノイズなし。
最小SNRガンマ=5:トレーニング高速化。
完全bf16精度。
AdamW8bitオプティマイザ:効率と性能のバランス。
データセット
解像度:変更後のSDXL公式バケット戦略による1024x1024。
キャプション:WD14-Swinv2モデルで0.35閾値。
クローズアップクロップ:大きいまたは希少な画像のトレーニングに有効な複数クロップ。
トリガーワード:画像の最初のタグをトリガーワードとして保持。
AIDXLv0.6
トレーニング戦略
AIDXLv0.52から継続トレーニングだが、適応的リピート戦略導入。データセット内各キャプション付き画像のリピート回数を次のルールに従い増加:
ルール1:画像の品質が高いほどリピート回数増加。
ルール2:画像がスタイルクラスに属する場合:
クラスが未適合または過小適合であれば、手動または自動でクラスのリピート回数を増やし総リピート数が約100に達する。
クラスが適合済みまたは過剰適合の場合、リピート回数を1に強制し、品質が低い場合は除外。
ルール3:リピート回数の上限を約10に制限。
この戦略の利点:
新規学習からモデルの元情報を保護(正則化画像の考えに準拠)。
学習データの影響をより制御可能に。
未適合クラスを活性化し、適合済みクラスの過剰適合防止でクラス間のバランス維持。
計算資源を大幅節約し、新スタイル追加を容易に。
固定トレーニングパラメータ
AIDXLv0.51と同様。
データセット
AIDXLv0.51ベースで更に以下最適化施行:
キャプション意味的ソート:タグの意味順にソート(例:"gun, 1boy, holding, short hair" -> "1boy, short hair, holding, gun")。
キャプション重複除去:類義タグの重複削除し、最も情報保持したものを維持(例:「long hair」と「very long hair」)。
追加タグ:すべての画像に手動で追加タグ投入(例:「高品質」「インパスト」など)。ツールで迅速対応可能。
V 特別感謝
計算リソース提供:@NieTaコミュニティ(捏Ta (nieta.art))に感謝;
データ提供:@KirinTea_Aki(KirinTea_Aki Creator Profile | Civitai)および@Chenkin(Civitai | Share your models)に深謝;
彼らなしで0.7バージョンは存在しません。
VI AIDXL vs AID
2023/08/08。AIDXLはAIDv2.10と同じトレーニングセットで訓練されていますが、AIDv2.10を上回る性能を持ちます。 AIDXLはより賢く、SD1.5ベースモデルでは不可能な多くのことを実現しています。 概念の区別が非常に優れ、画像の詳細学習やSD1.5・AIDが苦手な構図表現もこなします。 総じて極めて高い潜在能力を持ち、今後もAIDXLを更新していきます。
VII スポンサー募集
私たちの仕事を応援してくださる方は、Ko-fiを通じてご支援いただけます(https://ko-fi.com/eugeai)。研究開発の支援に感謝いたします。
模型介绍(Chinese Part)
I 目录
在本介绍中,您将了解:
模型介绍(见 II 部分);
使用指南(见 III 部分);
训练参数(见 IV 部分);
触发词列表(见附录 A 部分)
II 模型介绍
动漫插画设计XL,或称 AIDXL 是一款专用于生成二次元插图的模型。它内置了 800 种以上(随着更新越来越多)的插画风格,依靠特定触发词(见附录 A 部分)触发。
优点:构图大胆,没有摆拍感,主体突出,没有过多繁杂的细节,认识很多动漫人物(依靠角色日文名拼音触发,例如,“ayanami rei”对应角色“绫波丽”,“kamado nezuko”对应角色“祢豆子”)。
III 使用指南(将与时俱进)
1 基本用法
1.1 提示词书写
使用触发词:使用附录 A 所提供的触发词来风格化图像。适合的触发词将 极大地 提高生成质量;
提示词标签化:使用标签化的提示词描述生成对象;
提示词排序:排序您的提示词将有助于模型理解词义。推荐的标签顺序:
触发词(by xxx)->主角(1girl)->角色(frieren)->种族(elf)->构图(cowboy shot)->风格(impasto)->主题(fantasy)->主要环境(forest, day)->背景(gradient background)->动作(sitting)->表情(expressionless)->主要人物特征(white hair)->人体特征(twintails, green eyes, parted lip)->服饰(white dress)->服装配件(frills)->其他物品(magic wand)->次要环境(grass, sunshine)->美学(beautiful color, detailed, aesthetic)->质量(best quality)
负面提示词:worst quality, low quality, lowres, messy, abstract, ugly, disfigured, bad anatomy, deformed hands, fused fingers, signature, text, multi views
1.2 生成参数
分辨率:确保图像总分辨率(总分辨率=高度x宽度)围绕1024*1024且宽和高均为32的倍数。例如,832x1216 (3:2), 1216x832 (3:2), 以及 1024x1024 (1:1)。
不进行“Clip Skip”操作,即 Clip Skip = 1。
采样器和步数:采用 “euler_ancester” 采样器(sampler),该组合在 webui 里称为 Euler A。在 7 CFG Scale 上采样 28 步。
仅需要使用模型本身,而不使用精炼器(Refiner)。
使用基底模型 vae 或 sdxl-vae。
2 特殊用法
2.1 泛风格化
0.7 版本归纳了若干相似插画画风,引入了泛风格触发词。泛风格触发词各代表一种常见动漫插画画风类别。
请注意,泛风格触发词并不一定符合其词义指代的美术含义,而是经过重新定义的特殊触发词。
2.2 角色
0.7 版本对强化训练了角色。部分角色触发词的还原度已经能够达到 lora 的效果,且能够很好地将角色概念与其本身的着装分离。
角色触发方式为 角色名 \(作品\)。例如,触发动画《赛博朋克:边缘行者》的女主角露西则使用 lucy \(cyberpunk\);触发游戏《原神》中的角色甘雨则使用 ganyu \(genshin impact\)。这里,“lucy” 和 “ganyu” 为角色名,“\(cyberpunk\)” 和 “\(genshin impact\)” 则为对应角色的作品出处,括号使用斜杠"\"转义以防止被解释为提示词加权。对于部分角色,出处并非必要。
角色触发词请参照 selected_tags.csv · SmilingWolf/wd-v1-4-convnext-tagger-v2 at main (huggingface.co)。
在使用中,若仅靠单个角色触发词无法完全还原角色,则需要在提示词中添加该角色的主要特征。
角色触发词通常不会携带角色本身的着装特征,若要添加角色着装,则需要在提示词中添加衣物名。例如,游戏《碧蓝航线》中角色圣路易斯 ( st. louis \(luxurious wheels\) \(azur lane\) ) 的衣装触发可使用 silver evening gown, plunging neckline。类似地,您也能对任何角色添加其他角色的衣装标签。
2.3 质量标签
0.7 版本的质量和美学标签经过正式训练,在提示词中尾随它们将影响生成图像的质量。
0.7 版本正式训练并引入了质量标签,质量标签分为六个等级,由好到坏分别为:amazing quality, best quality, high quality, normal quality, low quality 和 worst quality.
2.4 美学标签
0.7 版本起引入了美学标签,描述图像的特殊美学特征。
2.5 风格融合
您可以将一些样式合并到您的自定义样式中。 “合并”实际上意味着一次使用多种风格触发词。 例如,chun-li, amazing quality, (by yoneyama mai:0.9), (by chi4:0.8), by ask, by modare, (by ikky:0.9).
一些技巧:
控制风格的权重和顺序来调整最终风格。
尾随而非前置到提示词上。
3 注意事项
使用 SDXL 支持的 VAE 模型、文本嵌入(embeddings)模型和 Lora 模型。注意:sd-vae-ft-mse-original 不是支持 SDXL 的 vae;EasyNegative、badhandv4 等负面文本嵌入也不是支持 SDXL 的 embeddings;
对于 0.61 及以下版本:生成图像时,强烈推荐使用模型专用的负面文本嵌入(下载参见 Suggested Resources 栏),因其为模型特制,故对模型几乎仅有正面效果;
每个版本新增触发词将在当前版本效果相对较弱或不稳定。
IV 训练参数
以 SDXL1.0 为底模,使用大约 2w 张自己标注的图像在 5e-6 学习率,循环次数为 1 的余弦调度器上训练了约 100 期得到模型 A。之后在 2e-7 学习率,其余参数相同的条件下,训练得到模型 B。将模型 A 与 B 混合后得到 AIDXLv0.1 模型。
其他训练参数请参照英文版本的介绍。
V 特别鸣谢
算力赞助:感谢 @捏Ta 社区(捏Ta (nieta.art))提供的算力支持;
数据支持:感谢 @秋麒麟热茶(KirinTea_Aki Creator Profile | Civitai) 和 @风吟(Chenkin Creator Profile | Civitai)提供的大量数据支持;
没有它们就不会有 0.7 版本。
VI 更新日志
2023/08/08:AIDXL 使用与 AIDv2.10 完全相同的训练集进行训练,但表现优于 AIDv2.10。AIDXL 更聪明,能做到很多以 SD1.5 为底模型无法做到的事。它还能很好地区分不同概念,学习图像细节,处理对 SD1.5 来说难于登天的构图,几近完美地学习旧版 AID 无法完全掌握的风格。总的来说,它拥有比 SD1.5 更高的上限,我会继续更新 AIDXL。
2024/01/27:0.7 版本新增了大量内容,数据集大小是上一版本的两倍以上。
为了得到令人满意的标注,我尝试了很多新的标签处理算法,例如标签排序、标签分层随机化、角色特征分离等等。项目地址:Eugeoter/sd-dataset-manager (github.com);
为了使训练可控,且更加服从我的意愿,我基于 Kohya-ss 制作了特制的训练脚本;
为了掌控不同世代的模型的融合过程,我开发了一些启发式的模型融合算法;为了使模型达到足够的风格化,我放弃了通过融合文本编码器和UNET的OUT层来提高模型的稳定和美学,因为这会伤害模型的风格。
为了筛选和过滤数据,我训练了一个水印检测模型、一个图像分类模型、一个美学评分模型,来帮助我清洗数据。
VII 赞助我们
如果您喜欢我们的工作,欢迎通过 Ko-fi(https://ko-fi.com/eugeai) 赞助我们,以支持我们的研究和开发,感谢您的支持!
付録
A. 特殊トリガーワード一覧
アートスタイルトリガーワード: こちらをクリック
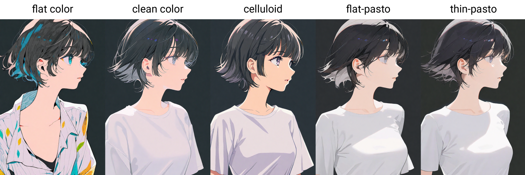
ペインティングスタイルトリガーワード: flat color, clean color, celluloid, flat-pasto, thin-pasto, pseudo-impasto, impasto, realistic, photorealistic, cel shading, 3d
flat color: フラットカラーで、線を用いて光と影を表現
平涂:平面色彩,使用线条和色块描述光影和层次
clean color: flat colorとflat-pastoの中間。シンプルで整った着色。
具有简洁色彩的平涂,介于 flat color 和 flat-pasto 之间
celluloid: アニメ風の着色
平涂赛璐璐:动漫着色
flat-pasto: ほぼフラットカラーで、グラデーションで光と影を表現
接近平面的色彩,使用渐变描述光影和层次
thin-pasto: 細い輪郭線を用いて、グラデーションおよび絵の具の厚みで光、影、階調を表現
细轮廓勾线,使用渐变和颜料厚度描述光影和层次
pseudo-impasto:グラデーションと絵の具の厚みで光、影、階調表現
伪厚涂 / 半厚涂:使用渐变和颜料厚度描述光影和层次
impasto:絵の具の厚みで光、影、グラデーションを表現
厚涂:使用颜料厚度描述光影和层次
realistic
写实
photorealistic:現実に近いスタイルに再定義
相片写实主义:重定义为接近真实世界的风格
cel shading: アニメの3Dモデリングスタイル
卡通渲染:二次元三维建模风格
3d

美学トリガーワード:
beautiful
美丽
aesthetic: やや抽象的な芸術的感覚
唯美:稍微抽象的艺术感
detailed
细致
beautiful color: 繊細な色使い
协调的色彩:精妙的用色
lowres
messy: 乱雑な構図やディテール
杂乱:杂乱的构图或细节
品質トリガーワード: amazing quality, best quality, high quality, low quality, worst quality




モデルコレクション - Anime Illust Diffusion XL


「Anime Illust Diffusion XL - v0.61」による画像
アニメ画像










基本モデル画像

平らな色画像










イラスト画像








