Colossus Project Flux - v10_int4_SVDQ
関連キーワード&タグ
ハイライトされた画像

推奨ネガティブプロンプト
blurry
推奨パラメータ
samplers
steps
cfg
resolution
vae
ヒント
『blurry』(ぼやけ)という単語をネガティブプロンプトで使うと出力品質が向上します。
FP4バージョンはNvidia 50xxシリーズのGPUのみ対応、int4バージョンは40xx以下(最低20xxシリーズ)をサポートします。
"All in One"モデルにはClip_l、T5xxl、VAEが埋め込まれており、使いやすくなっています。
Euler、Heun、DPM++2M、deis、DDIMなど多彩なサンプラーを試してください。スケジューラーは"Simple"を推奨します。
ガイダンススケール(cfg)は1.5から3の範囲で実験し、通常は2.2〜2.3が最適です。
FP8バージョンは品質と性能のバランスが良好です。
特別な『デディスティル』バージョンではFlux Guidanceスケールを無効にし、cfgスケールを代わりに使用してください。
アーティファクトが出た場合は、小さなアップスケール(例:1.2倍ではなく1.14倍)を試して問題を軽減してください。
詳細なワークフローやガイドはCivitaiの記事リンクから参照可能です。
バージョンのハイライト
バージョン V10_int4_SVDQ "Nunchaku"
インストール:ワークフロー・インストールガイドはこちら:https://civitai.com/articles/15610
まずFP16_Unetをint4_SVDQに変換してくれたtheunlikelyさんに感謝します。https://huggingface.co/theunlikely を訪れていいねを残してください。
このバージョンはほぼFP8版と同等です。通常モードのワークフロー内でも通常モデルより2〜3倍速いです。ワークフローの「高速モード」では、3090tiで約19秒で2MP画像をレンダリングできます。
SVDQ "Nunchaku"とは?
この新しい量子化方法でFluxモデル(ここではネイティブFP16モデル)を24GBから約6.7GBに縮小可能です。しかしそれだけでなく、クオリティをそれほど損なうことなくかつてない高速生成が可能になります。32GB_Behemothとの小さな差はありますが、この小型モデルはかなりのVRAM/RAM量がないと動作しません。
詳しくは以下参照:https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
クリエイタースポンサー
クリエイターをKo-Fiで応援:https://ko-fi.com/afroman4peace
Muyang Li(Nunchakutech)による量子化モデルをダウンロード:https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
Civitaiのワークフローガイド:
https://civitai.com/articles/17313
https://civitai.com/articles/17358
https://civitai.com/articles/17163
https://civitai.com/articles/15610
https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
https://civitai.com/articles/8419
https://civitai.com/articles/7946
なくてはならないNunchaku SVDQ量子化のGitHub:https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
山の奥深くには眠る巨人がいて、人類を助けるか破壊をもたらすかの力を持っています…
コロッサスが目覚める…
私のSDXLシリーズの後、いよいよこのプロジェクトのFLUXシリーズの番です…今回はこのモデルを一からトレーニングしました。トレーニングには自分の画像を使いました。DemonFlux/Colossus Project schnellという私のschnell Fluxモデルと、リファイナーとしてSDXL Colossus Project 12を組み合わせて作成しました。
このSD Fluxチェックポイントはほぼすべてを生成可能です。Colossusは非常にリアルな画像、アニメ、アートの作成に優れています。
気に入ったらぜひフィードバックをください。また支援していただければこちらで応援できます。Fluxモデルのトレーニングには高性能なPCを構築し、多くの時間と電力もかかっています。
https://ko-fi.com/afroman4peace
バージョン V12 "Hephaistos"
このチェックポイントの公開は嬉しくもあり悲しくもあります。V12がこのシリーズの最後のチェックポイントになるからです。主な理由は今後のEUのAI法規制、もう一つはFlux .1 DEV自体のライセンスです。皆さんのサポートに感謝します!このプロジェクトには昨年多くの時間を費やしました。次は別のプロジェクトに進みます。
ともあれ、このシリーズは最高の形で終えます…
V12はV10B "BOB"をベースにしていますが、このシリーズのベストな部分をブロックマージして1つのチェックポイントにまとめました。(約1時間30分かかり、128GBのRAMを使い切りました)V10と比べて顔や肌の質感を強化し、目はよりリアルで生き生きとしています。
ぜひ自分で試し、V12のフィードバックをください。低速なインターネット接続のため、まずFP8_UNETからアップロードします。その後FP8 "all in one"、FP16_unet、FP16_BEHEMOTHの順に公開予定です。int4やfp4への変換も試みます(成功を祈ってください)。
いつも通りV12の感想をお待ちしています…
バージョン V12 "Behemoth"(AIO)
この"all in one"モデルはV12シリーズで最高かつ最大のモデルです:-)
BehemothにはカスタムのT5xxlとClip_lが組み込まれています。品質を求めるならこれがおすすめのチェックポイントです!
バージョン V12 FP4/int4
NunchakutechのMuyang LiによるV12の量子化に感謝します。https://huggingface.co/nunchaku-tech と彼らの素晴らしいnunchaku!
このバージョンは本当に驚異的です。これまでにない品質と速度の両立を実現しています。
注意!
FP4とint4の2バージョンがあります。FP4はNvidia 50xxシリーズのグラフィックカード専用、int4は40xx以下に対応(最低でも20xxシリーズのGPUが必要)です。
両方のバージョンはここから直接ダウンロードできます:https://huggingface.co/nunchaku-tech/nunchaku-flux.1-dev-colossus
インストールガイドとワークフロー
簡単なインストールガイドと進行中のワークフローはこちらです。
https://civitai.com/articles/17313
ワークフローの詳細ガイド
https://civitai.com/articles/17358
私はまだNunchaku用の新ワークフローを開発中なので、以下のワークフローはまだ作業中です。週末に詳細な記事を追加予定です。
バージョン V12 FP16_B_variant
深夜(午前2時ごろ)の小さなミスで「間違った」チェックポイントをリネーム・アップロードしてしまいました。これは非常に実験的なチェックポイントで、公開するつもりはありませんでした。テストはあまり行っていませんが、ショーケース作成時には非常に良い結果を出しました。標準版より良いかもしれません。
アジア系の顔に傾きやすいです。これは私がまだ作業中のサイドプロジェクトを混ぜるテストをしているためです。このチェックポイントでの体験を教えてください:-)
バージョン V12 AIO FP8
このバージョンはV12のオールインワン版です。すべてのクリップが組み込まれており、FP8_unetと私のカスタムclip_lと同様の出力が得られます。
バージョン V12 GGUF Q5_1
リクエストで作成したバージョンです。品質は悪くありません。
バージョン V10B "BOB"
これはV10の別バージョンです。V10のFP8版を改善するために作成しました。一般にFP8版はより精細で色彩も良いです。最近あまり時間が取れていません(現実生活優先)。そのため公開が遅れました。このバージョンの方が好きなら教えてください。「BOB」のFP16版もあります。フィードバックによってはint4版も公開を検討します。
ワークフロー:
V12とV10のワークフローはこちら:https://civitai.com/articles/17163
バージョン V10_int4_SVDQ "Nunchaku"
まずはFP16_Unetをint4_SVDQに変換してくれたtheunlikelyさんに感謝します。https://huggingface.co/theunlikely を訪れていいねを残してください。
このバージョンはほぼFP8版と同等です。通常モードのワークフロー内でも通常モデルより2〜3倍速いです。ワークフローの「高速モード」では、3090tiで約19秒で2MP画像をレンダリングできます。
SVDQ "Nunchaku"とは?
この新しい量子化方法でFluxモデル(ここではネイティブFP16モデル)を24GBから約6.7GBに縮小可能です。しかしそれだけでなく、クオリティをそれほど損なうことなくかつてない高速生成が可能になります。32GB_Behemothとの小さな差はありますが、この小型モデルはかなりのVRAM/RAM量がないと動作しません。
詳しくは以下参照:https://github.com/mit-han-lab/ComfyUI-nunchaku?tab=readme-ov-file
インストール:インストール・ワークフローガイドはこちら:https://civitai.com/articles/15610
バージョン V10 "Behemoth"(FP16_AIO)
このバージョンはまだ実験的です。主な目的はよりリアルな結果を出すこと。また「Fluxライン」の軽減にも成功しています。このモデルはColossus Project V5.0_Behemoth、V9.0および私が「Ouroborus Project」と呼ぶ別プロジェクトをベースにしています。
FP16版は非常に安定しています。FP8版もまもなくリリース予定で、こちらは良いですが安定性では劣ります。
ご自身でも試して、意見を聞かせてください。
制作を楽しんでください:-)
バージョン V9.0:
なぜこれがV9.0かを説明しなければなりません…
最近新しい部屋に引っ越しましたが、インターネット回線の問題でほとんど接続できませんでした。引越し中もPCを起動しっぱなしにしていた結果、多くの(ほとんど壊れた)チェックポイントを作ってしまいました。良いV8バージョンもありますので今後公開を検討しています。
変更点は?
V5.0のベスト結果を利用して顔や肌のテクスチャ、新たに足と脚の解剖学的トレーニングを追加しました。V5.0では頭や足にクリップが見られましたが、いくつか修正できたと思います。
さらに、自分の風景画像も多く使ってトレーニングしました。引越し中に訓練したので約2週間の計算時間がかかりました。電力コストは非常に高いです(1時間あたり約25セント)。
気に入っていただければ嬉しいです。支援したい場合は、素敵な画像投稿やBuzzやKo-fiでのチップをお願いします。
感想を聞かせてください:-)
バージョン 5.0:
V5.0は実はV4.2とV4.4(まもなくリリース予定)がベースです。肌質や解剖学的ディテール(主に手や乳首)を追加トレーニングし、多くの問題を修正しました。顔のディテールもより良くなりました。Fluxラインの軽減も試みています。
このバージョンはV4.2よりリアルで細部も優れています。さらに、V4.2同様ハイブリッドのデディスティルモデルです。同じ設定で使えます。
新しいワークフローも用意しています:https://civitai.com/articles/11950/workflow-for-colossus-project-flux-50
V4.2やV2.1と比較した感想を教えてください。
バージョン 4.4 "Research":
このバージョンは完成のためだけに追加しました。V4.2より少しリアルで、V5.0の基盤になっています。お試しいただけます。また、V5.0とV4.2のワークフローにも対応しています。
バージョン 4.2:
このバージョンは主にDemoncore FluxとColossus Project Fluxの更なる進化版です。より安定した出力を目標に、肌、手、顔のバリエーションを強化しました。ハイブリッドモデルで一部Demoncore Fluxを含みます。乳首とNSFWも少し改良しました。V2.1よりV4.2の方が好きな方は教えてください:-)
ショーケース画像にはSDXL解像度または2MP(例:1216x1632)のネイティブ画像のみを使用しました。このモデルはもっと高い解像度にも対応可能で、最大2500x2500までテスト済みですが、約2000x2000程度を推奨します。
生成設定は30ステップ、cfgは2~2.5くらいがおすすめです。私は主に2.2や2.3を使い、DPM++ 2MとSimple schedulerをショーケースで使いました。
クリスマス前までは時間が少ないため、今後のバージョン追加は遅れそうです。
設定
専用のComfyワークフローを近日公開予定です。今はショーケース画像をダウンロードしてご確認ください。
All in One版はForgeでも問題なく動作します。
基本的にV2.1の設定と同じです(下記参照)。
20~30ステップ、cfgは約2.2くらいで試してください。
バージョン 2.1 デディスティル実験版(マージ)
このバージョンは普通のFluxモデルとは全く異なります!
これは私のV2.0とデディスティル版https://huggingface.co/nyanko7/flux-dev-de-distillの実験的マージです。偶然の産物ですが、結果は驚異的です。凄まじいディテールを出し、プロンプトにも非常に忠実です。次は直接デディスティルモデルでトレーニング予定で、すでにテスト用のLoraを作成済みです。非常に実験的なため、不具合があれば教えてください。良い画像や悪い画像を投稿してもらえると改善につながります:-)。V2.0も試して、どのチェックポイントが合うか教えてください。
注意!
通常のFluxワークフローは動作しません。必ず私のワークフローをダウンロードしてください!
独自で工夫することも可能ですが、悪い画像の責任は負いかねます。また非常に実験的なモデルなので欠点もご確認ください。
このチェックポイントの長所と短所:
非常に細部まで描画可能ですが、通常のFluxチェックポイントより処理が遅いというコストがあります。アップスケールをあまり必要としない点は利点です。Flux Guidanceではなくcfgスケールを用いるため、標準的なワークフローでは動作しません。
ネガティブプロンプトが使用可能で、不要な要素を画像から排除できます。
時折アーティファクトが発生する可能性があり、小さなアップスケール(例:1.14倍)で解決できる場合があります。私は修正作業中です。すべてのシードで起きるわけではありません。

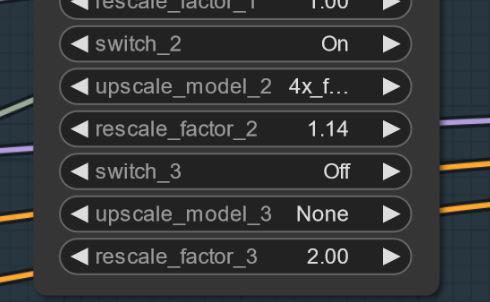
設定とワークフロー V2.1:
詳細はワークフローをご覧ください:https://civitai.com/articles/8419
通常のFluxとは違いFlux Guidanceスケールは使わずcfgで代用してください。ワークフローでは主に3cfgを使います。画像によってはさらに低いスケールが必要な場合もあります。
Flux Guidanceスケールはオフにすることが重要です。
ワークフローを使わない場合は30ステップ、2〜3cfgで試しました。Forgeにも同じ設定がおすすめです。
ネガティブに"blurry"を入れることを推奨します。
サンプラーとスケジューラー:
以下のサンプラーが良く動作します:
Euler, Heun, DPM++2m, deis, DDIM です。
スケジューラーは"simple"を主に使っています。
良い設定を見つけたら教えてください:-)
ForgeにはAIOモデルを推奨します。設定例はこちら:
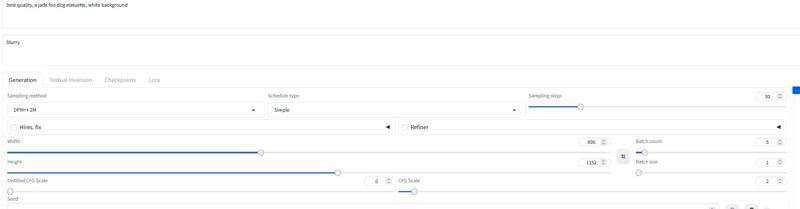
バージョン 2.0_dev_experimental
これは実験的なバージョンです。より一貫して高速なモデルを作ることを目標にしました。追加のトレーニング済みLoraをいくつか統合し、特殊な方法(テンソルマージ)で合成しました。カスタムのT5xxlを「Attention Seeker」で修正し、速度と品質向上のためByteDanceのHyper Flux Loraを導入しました。これにより作動域がシフトしています。タイトル画像はこちらです。
16ステップ V 2.0
 30ステップ V 1.0
30ステップ V 1.0
 短所:
短所:
まず、このバージョンは前より少し大きいです。次にUNetのみのバージョンをまだ作成していません。完成したら更新します。
設定とワークフロー V2.0:
このモデルはステップ数を少なくして動かせます。16ステップは旧モデルの30ステップに相当します。
それでも多くの場合、品質向上のため20~30ステップを推奨します。
サンプラー:Eulerを好み、スケジューラーはSimpleを推奨します。ガイダンス値は1.5~3の範囲で調整可能です。1.8はリアルな画像に適しています。他のサンプラーも試してください。DPM++2MやHeunも良好です。
ワークフロー 2.0:
V2.0およびV1.0用の新しいワークフローを作成しました。Fluxプロンプトジェネレーターが導入され、第2アップスケール段階も動作します。https://civitai.com/articles/7946
Forge:
Forgeでもテストし非常に良好でした。ただしComfy UIとForgeで生成画像が多少異なる場合があります。
バージョン 1.0_dev_beta:
このモデルはシリーズの最初のエントリーです。フィードバックや画像投稿があると今後の改善に役立ちます。選べるバージョンは複数ありますが、品質面で最良なのはFP16版です。FP16はサイズが非常に大きく、高性能GPUと大量のRAMが必要です。FP8版は品質とパフォーマンスのバランスが良いと考えています。GGUF版を希望するならQ8_0をダウンロードしてください。GGUF Q4_0/4.1はリクエスト由来で、小さい代わりに若干品質が落ちます。
大きく分けて2種類のモデルがあります。1つは"All in one"で、一つのファイルダウンロードだけで済むタイプです。Clip_l、T5xxl、fp8、VAEが組み込まれています(下記参照)。チェックポイントフォルダに配置してください。
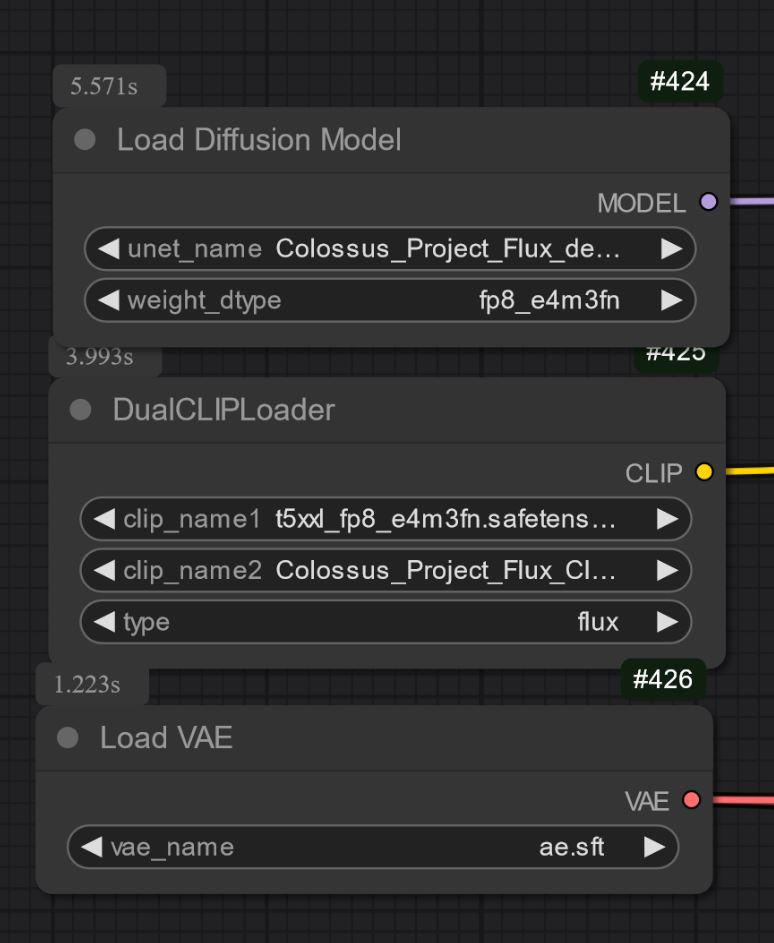
もう1つはUNETのみのタイプで、すべてのファイルを個別に読み込む必要があります。
いずれにせよ、このモデルを正しく動作させるには私のClip_Lをダウンロードする必要があります。
また、適切なT5xxlクリップの選択も重要です。FP8版はfp8_e4m3fn t5xxlを、FP16版はFP16クリップを使ってください。デフォルトの重みタイプを選択してください。(下記にFP8の例画像があります)
GGUF版はGGUFローダーが必要です!
V1.0の既知の問題:
シリーズ最初のモデルなので、一部プロンプトやアートスタイルに弱い場合があります。次バージョンでトレーニングを強化します。モデルにできないことを教えてください。
設定およびワークフロー:
30ステップ程度、Eulerサンプラー、Simpleスケジューラーで試験済みです。ガイダンス値は1.5〜3の範囲で調整可能です。
1.8はリアルな画像に好適です。
設定を試行錯誤して良い結果が出たら、ぜひ投稿してください。
ショーケース画像はトレーニングデータに含めています。Comfyのワークフローは以下からダウンロードできます:https://civitai.com/articles/7946
"All in one"モデル:
UNETのみ:
 Clip_Lもダウンロードしてください。約240MBです。
Clip_Lもダウンロードしてください。約240MBです。
GGUF: GGUF用のワークフローはこちら:https://civitai.com/articles/7946
重要:
この開発モデルは商用利用を意図していません。商用利用には別の場所でschnellモデルを公開予定です。個人または学術利用が主な用途です。
ライセンス:
https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
クレジット:
theunlikely https://huggingface.co/theunlikel(改めて感謝)
バージョン 2.1/V4.2/5.0: nyanko7によるFlux_dev_de-distill
https://huggingface.co/nyanko7/flux-dev-de-distill
V2.0より: ByteDanceによるHyper Lora https://huggingface.co/ByteDance/Hyper-SD
Black Forrestの素晴らしいFluxモデルに感謝 https://huggingface.co/black-forest-labs

モデル詳細
ディスカッション
コメントを残すには log in してください。
モデルコレクション - Colossus Project Flux

Colossus Project Flux - v12_int4_SVDQ_nunchaku

Colossus Project Flux - V12 "Hephaistos" FP8_UNET

Colossus Project Flux - v10_AIO_FP8

Colossus Project Flux - v10_int4_SVDQ

Colossus Project Flux - v10_Behemoth_AIO_FP16
「Colossus Project Flux - v10_int4_SVDQ」による画像
動物画像









アニメ画像










描画画像










人画像










宇宙画像









