Illustrious XL 1.0 - v1.0
関連キーワード&タグ
ハイライトされた画像


推奨プロンプト
night, vivid colors
推奨ネガティブプロンプト
very displeasing, displeasing, bad anatomy, artistic error, lowres, bad hands, signature, artist name, multiple views, artist sign
推奨パラメータ
samplers
steps
cfg
resolution
ヒント
繊細な画像生成には自然言語とDanbooruタグベースのプロンプトの両方を使用してください。
LoRAおよびControlNetモジュールに対応しており、スタイル、ポーズ、構図のファインチューニングが可能です。
Illustrious XL v1.0はさらなるファインチューニングやLoRAトレーニングに適した生の事前トレーニング済みベースとして機能します。
クリエイタースポンサー
私たちのウェブサイトで最新モデルの開発状況をチェックしてください!
→https://www.illustrious-xl.ai/
公式サイトでIllustrious XLモデルを使用した画像生成が直接可能になりました:illustrious-xl.ai。高解像度出力、自然言語プロンプト、カスタムプリセットを備えた完全な画像生成プラットフォームを立ち上げました。また、他のハブでは見られない限定モデルも複数用意しています。モデル階層や名称の詳細はこちら:Model Series。使い方がわからない方は、こちらのガイドをご覧ください:ILXL Image Generation User Guide。
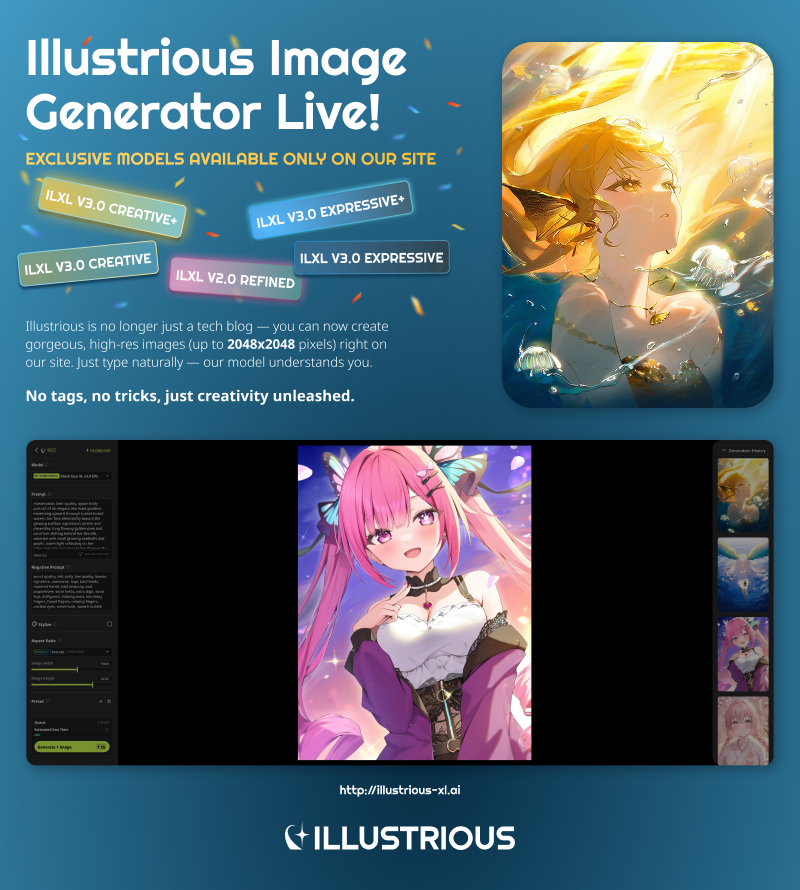 私たちのウェブサイトで最新モデルの開発状況をチェックしてください!
私たちのウェブサイトで最新モデルの開発状況をチェックしてください!
→https://www.illustrious-xl.ai/
公式サイトでIllustrious XLモデルを使った画像生成が直接可能になりました: [illustrious-xl.ai]。高解像度出力、自然言語プロンプト、カスタムプリセットを備えた完全な画像生成プラットフォームを立ち上げました。また、他のハブでは見られないいくつかの限定モデルも用意しています。モデル階層や名称の詳細はこちら:[Model Series]をご覧ください。使い方がわからない方は、こちらのガイドをご覧ください:[ILXL Image Generation User Guide]。
Illustrious XL v1.0 - 高解像度特化イラスト生成モデル
概要
Illustrious XL v1.0はOnomaAIによって開発された最先端の生成モデルで、Stable Diffusion XLアーキテクチャを基に、以前のチェックポイントIllustrious XL v0.1からトレーニングされており、驚異的な高解像度画像を生成します。1536×1536というSDXLフレームワーク内で前例のないネイティブ解像度を実現し、これまでにない細密さと鮮明さを誇ります。モデルは自然言語理解とDanbooruスタイルのタグベースプロンプトをシームレスに組み合わせており、詳細な文でも特定のタグでも柔軟に対応可能です。結果として、Illustrious XL v1.0は、忠実度を犠牲にすることなく多用途のコンテンツ生成が求められるクリエイターにとって強力な基盤となります。
知識のカットオフ
Illustrious XL v1.0は2024年7月にトレーニングされ、2024年6月までの知識を有しています。
しかし、v0.1 LoRAのネイティブサポートにより知識の制限を気にする必要はあまりありません!
主な特徴
1536×1536のネイティブ解像度:
1536px解像度をネイティブにサポートする初のStable Diffusion XLモデルです。これまでのSDXLでは達成できなかった細部の精密さ、鮮明さ、クリアさを持つ高解像度画像を生成します。512x512から1536x1536まで幅広い解像度に対応し、1248x1824のような解像度も高解像度改変なしで可能です。
NLP+タグベースプロンプト:
高度な自然言語処理とDanbooruタグベースのプロンプトを統合しています。タグベースの方がより簡潔かつ正確ですが、このハイブリッドプロンプトシステムにより、単純な英語の説明文や正確なタグ(またはその両方)を使え、モデルはそれぞれを理解し活用して画像生成におけるより細やかな制御とニュアンスを可能にします。
広範な互換性:
多様な拡張機能やアドオンと完全に互換性があります。LoRA、ControlNetモジュール、その他のIllustrious v0.1でトレーニングされた適応手法はv1.0でもシームレスに動作します。スタイル、ポーズ、構図の微調整において拡張を組み合わせても互換性を損ないません。
事前トレーニング済みベースモデル:
Illustrious XL v1.0は特定の美学やバイアスに特化したファインチューニングを施していない事前トレーニング済みのベースチェックポイントとして提供されます。この「生」モデルは更なるトレーニングのための堅牢な基盤を提供し、特定のアートスタイルや専門的な成果を実現するためのファインチューニング(例:LoRAトレーニング)を望むクリエイターに理想的です。新たな革新的アプローチの出発点となります。
今後の計画
v2/v3でより高解像度対応:
今後リリース予定のIllustrious XL v2およびv3では、さらに大きな解像度(最大2k以上)をサポート予定です。より詳細で拡大可能な超高解像度画像の生成が可能になります。
vパラメータ化モデルと色彩制御:
SD XLの従来の制限を突破する特化型のvパラメータ化バリアントが準備されています。これと並行して将来のリリースでは、色調整の精度を高め、生成画像の色彩バランスや一貫性の細かなコントロールに焦点を当てます。
継続的な改良:
Illustriousのロードマップは野心的で、各バージョンでコミュニティのフィードバックや最新の研究を積極的に取り入れます。これまで困難とされてきた壁を打ち破る高解像度研究を引き続き継続し、慎重かつ洗練されたアプローチで展開します。

モデルコレクション - Illustrious XL 1.0
「Illustrious XL 1.0 - v1.0」による画像
基本モデル画像

輝かしい画像


