Old Consistency V32 Lora [FLUX1.D/PDXL] - Feminine v1.1 - e500 PDXL
ハイライトされた画像


推奨プロンプト
a woman sitting on a chair in a kitchen, from side, from above, cowboy shot, 1girl, sitting, from side, blue hair, green eyes
a super hero woman flying in the sky throwing a boulder, there is a severely powerful glowing menacing aura around her, realistic, 1girl, from below, blue latex bodysuit, black choker, black fingernails, black lips, black eyes, purple hair
a woman eating at a restaurant, from above, from behind, all fours, ass, thong
score_9, score_8_up, score_7_up, score_6_up, BREAK 1girl, solo, mature female, yellow eyes, red hair
推奨ネガティブプロンプト
greyscale, monochrome, multiple views
推奨パラメータ
samplers
steps
cfg
clip skip
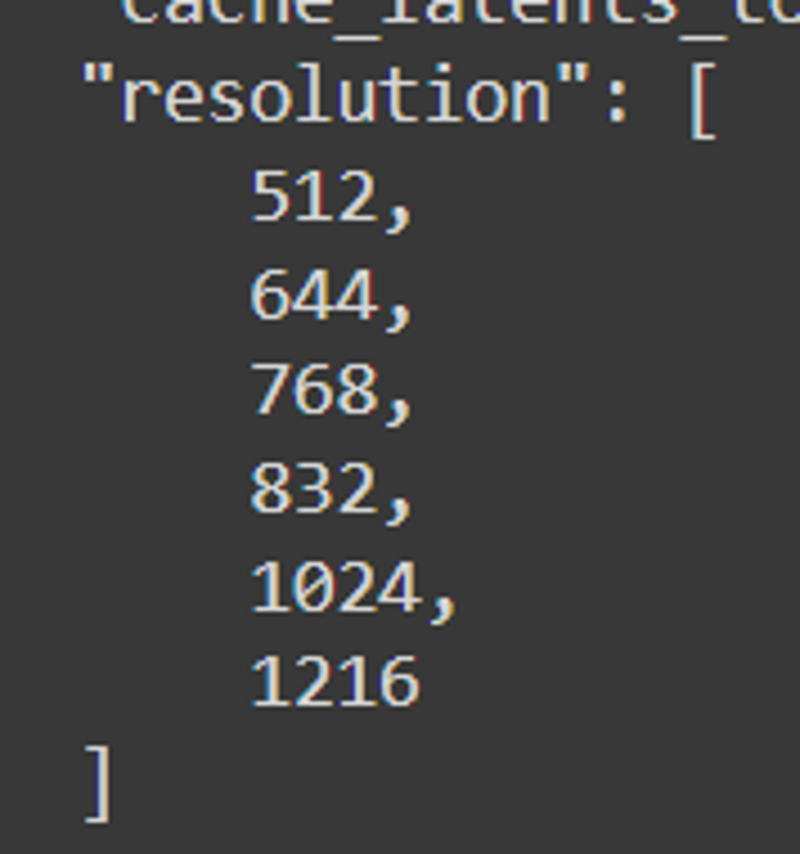
resolution
vae
other models
推奨ハイレゾパラメータ
upscaler
upscale
denoising strength
ヒント
複数のループバックを使用して画像の忠実度と一貫性を向上させましょう。
標準的なプロンプトと言語順序を守り、奇形の生成を避けましょう。
「from front」や「from side」、「from above」などの基本的なポーズや視点タグを使ってポーズ精度を高めましょう。
性行為ポーズは完成まで使用を控えましょう。
髪、目、衣装の色や素材など、多様な特性タグを試してください。
他のモデルやLoRAとのマージ時は読み込み順が結果に影響します。
セーフモードがデフォルトで有効になっており、疑わしいおよび露骨な内容を解禁可能です。
ポーズおよび指示タグシステムを活用し、キャラクターの位置とカメラ角度を正確に制御しましょう。
バージョンのハイライト
安定性チェック;
コンセプト - テスト済み画像
全身 - 48/48
カウボーイショット - 48/48
ポートレート - 48/48
クローズアップ - 48/48
**************************************
次の反復では単一レイヤー誘導の目ポーズサブセットを導入し、ポーズ角度タグ付けと角度バリエーション毎の目画像を増やし焼き込みを強固にします。色は不要で、形状が重要と私の研究で判明。
赤目 - 39/48
全身 - 6/12
カウボーイショット - 9/12
ポートレート - 12/12
クローズアップ - 12/12
青目 - 48/48
全ポーズ - 12/12
緑目 - 48/48
全ポーズ -12/12
黄目 - 42/48
全身 - 6/12 - 不安定の理由不明。
水色目 - 48/48
全ポーズ
紫目 - 48/48
全ポーズ
ラテックス - 36/48
クローズアップ - 5/12
ポートレート - 7/12 - ポートレートとクローズアップ画像が必要
カウボーイショット - 12/12
全身 - 12/12
ランジェリー - 36/48
クローズアップ - 7/12
ポートレート - 4/12 ? なぜ? - 直接のポートレートとクローズアップ顔画像が必要
カウボーイショット - 11/12
全身 - 12/12
カジュアル - 48/48
全ポーズ - 12/12
ビキニ - 48/48
全ポーズ - 12/12
ドレス - 16/48
追加タグ無しのポーズはドレスに合致せず→より具体的にタグ付け必要。
出力安定性は予想以上に高く、Ponyに既に多数の有用タグが実装済:
<color>髪
<color>服
胸サイズ
成熟女性
<color>イヤリング
<color>目
ぼやけたオブジェクト
<地域> <背景>
これらのタグは自由に試してください。
レイヤリングの成功例;
赤目 -> 青目;
[赤目:0.5], [青目:0.5] - 時折重複溢れで不安定。
赤目, 青目 - 重複漏れ減少
赤目 AND 青目 - より重複漏れ安定。更なる研究必要。
目はほぼ同様の問題を持ち、色が形状より過剰に重ねられるため、この実験は一旦停止しブロット実験に基づき続行します。
ドレス -> ラテックス
ドレス、スリット、カクテルドレス、ラテックス、ラテックスボディースーツ - レイヤーの複数部分に基づく衣装形成。安定性は低いが結果は有望。
ラテックス -> ドレス
ラテックス、ラテックスボディースーツ、ドレス、スリット - ドレスの透けムラを多用したドレス的オブジェクト形成。トレーニング過適合の可能性あり。
ラテックス -> ビキニ
ラテックス、ラテックスボディースーツ、ビキニ - ラテックスレギンスとビキニの混合。こちらも過適合の可能性。
レイヤー衣装の重なり問題の解決策があり、それにより目や肌色の問題も解決。多くの整合性はブロットに由来すると考えています。
クリエイタースポンサー
Illustrious Modelをチェックして補完的な機能を活用しましょう。
ComfyUIワークフローを使い、より良い画像生成とループ実験をしましょう。
強力なAI基盤Flux Modelもぜひ試してください。
優れたストーリーと画像生成の相乗効果のためNovelAIをサポートしましょう。
Fluxモデル設計の功労者Black Forest Labsに感謝。
タグ付けワークフローにはTagGUIが便利です。
トレーニング環境はAIToolkitで構築。
インスピレーションおよび対抗馬としてPonyDiffusion。

PDXL + ILLUSTRIOUS TRAIN V3.34:
IllustriousはPDXLの派生ではなく別物でとても優れています。機会があればぜひ試してください。
私はこれ専用にSimulacrumのバージョンをトレーニングしました。
V3-2はV3.22の代わりに:
v3.22の目標は変わり、fluxのテストと新機構の理解で迷子になりました。十分に学び、対象の固定方法やタグ付け、fluxがタグ付けを理解する仕組みを知った後、実際に適切なバージョン3を構築できます。
学習と試行のサイクルに付き合ってくれた皆さんに感謝します。これは試行錯誤や失敗、そして真の成功のローラーコースターでした。何ができるか、どうやるかを理解し、学びを反映して望むものを作る方法論を持ちました。完璧ではなく進行中に洗練されますが、どんなものを作っても理解と反復開発が重要です。自信を持って、初期の大きなダニング=クルーガーの崖を越え、今や実際に学び、有用な情報を教える段階に来ています。基本的および上級ユーザー向けに情報を適切に処理し理解する努力も続けます。
V4に向けた元々のアプローチは有効ですが、学習過程で使っていた方法は正しくありませんでした。より多くの失敗から学び成功に向けた土壌を耕しています。
指示に基づくバージョニングです。
バージョンごとに3つのコア指示トレーニングと一つのバニラnd(no directive)バージョンを導入予定です。
コアシステムと特定のテーマ画像に対して一般的な指示ベースのトレーニングを施し、意図したテーマをシステムに浸透させます。
タグ付けの技術的な部分は、私がなぜそうしているのかの理由を知らないと理解しづらく、とてもややこしいかもしれません。そのため詳細な仕様を知りたい場合は画像とタグが非常に混乱する可能性があります。
シンプルなタグ付けシステムも独立して残り、必要時に必要な結果を十分に生成可能です。
各リリースに「nd」または「no directive」バージョンを含め、テスト差異と結果が類似になるようにします。鉱山の鳥のように鳥が鳴き止んだら終わりです。この姉妹モデルたちは統合や概念の再利用、指示の有無に基づく効果の組み合わせが可能になるでしょう。
個別キャラクターへの固定がこのモデルの最重要目標です。固定対象は一人だけで、そのキャラクターの解像度は正しいFLUXトレーニングのパラメータに合わせて拡大・縮小されます。
V3.2の問題は思ったより顕著でなかった:
ほとんどの懸念は欠落している情報に基づくもので、時間をかけて補強していく予定です。反復的な開発の問題です。
現在3.21バージョンがテスト中で、まもなくリリース予定です。ポーズ制御が改善され、比較的長いカメラ指示に基づくモデルのフォーカスが変わりました。
テストした多くのLoRAとの互換性が良好で、現v32では動かしづらい硬いLoRAとも連携可能です。
Flux Unchainedや多数のキャラモデル、顔モデル、人間モデルなどとの互換性も高いです。システム間の競合や破損はほぼ起きていないのは良いことです。
V3.2で対処すべき問題:
一部のポーズや角度に一貫性の問題があります。側面、背面、上方、下方からのタグを使うLoRA間でクロスコンタミネーションが見られます。これを検証する新タグを使用し、将来的にカメラ制御精度のため別のLORAをトレーニング予定です。
主にアニメには問題なく動作しますが、LoRAが関与すると問題があります。
3.21バージョン向けの組合せタグ;
カメラの正確な動作を確認するための基準テストとして以下のタグを試します:
正面からの上方視点の被写体
正面側面の上方視点の被写体
前方で背面上方の被写体
背面で側面上方の被写体
flux_devベースでこれらのタグを使い、カメラを正しく配置し、画像の忠実度を保てるか検証します。
一般的な選択肢を使うと深いトレーニングがされる傾向があります。更なる試験が必要です。
「後ろから掴む」「後ろからのセックス」などは後ろタグと相性が悪いので、後側面タグを使います。
「側面から」「後ろから」「正面から」「視聴者を向く」などキャラ固有のsafebooru, danbooru, gelbooruの配置回転タグはトレーニングされません。キャラのインタラクションではなく視点ベースです。
POVの腕はほとんど表示しないようにテストし、腕や脚、胴体が誤生成されないように注意します。個別被写体に焦点を合わせることが重要です。
率直に言って一部のポーズはうまく機能しなかった:
組合せタグシステムが機能していなかったため、キャラ制御用の新しいタグ組合せが必要です。
脚の形状が歪んだり消失する。
腕の歪みや不適切な配置。
足が欠落。
上胴体が過度に強調されすぎる。<<< 過適合
下胴体の衣服表現が不適切。
首がスカーフ、タオル、チョーカー、襟など正しく表示されない。
乳首や性器の表現が乱雑。適切なNSFWコントローラー用の多様なフォルダが必要。
NAIはスタイル特化でファインチューニングすべき。
衣類オプションが体型生成を頻繁に誘発。
露骨な評価は時折アクセス困難、時には過剰に表示される。
疑わしい画像の重み付けが不足。露骨タグも疑わしいタグ付けと組み合わせるべき。
一部アニメキャラで視点が悪く、正確な関連視点取得が目標なので問題。
四つん這いは安定しているが視点問題あり。アニメキャラの3D認識が不十分で環境の忠実度がもう少し必要。
四つん這いは並びでは多く調整が必要。
跪きも並びでは多く調整が必要。
並びやグループはflux独特のフォーマットのようで更なる調査が必要。内部のループ処理のような仕組みかもしれません。
成功例もありました:
基礎忠実度は多数の画像で損なわれていません。
多くの新ポーズが動作します。時々不安定な場合もあります。
アニメスタイルはNAI独自のリアリズムを加えたユニークなものに変化しました。
複数キャラのポーズ付けは時々不自然ながら可能です。
どの角度の立ち姿でもNAIスタイルの素晴らしい忠実度と画質が得られます。
V3.3はもう少しお待ちください。
V3.3のロードマップ:
本ドキュメントの下部リソースを更新し、古いドキュメントはアーカイブ用に別記事に分岐しました。
結果がビジョンに近づいたので、次の目標であるオーバーレイに注力します。
V3.3では「ハイアルファ焼きつきオフセットタグ」を導入し、コミック制作、ゲームUI、オーバーレイ、ヘルスバー、ディスプレイなどを効率化します。
理論的には、一致性内で正しいオーバーレイと焼きつきを設定すれば偽ゲームが作成可能です。
これは任意の位置と奥行きのキャラ合成の基盤を築きますが、それは後の課題です。
すでに公平にスプライトシートを生成可能なので、タグシステムを活用し各サブシステムを試験予定です。既に存在する可能性が高く、単に解明が必要です。
V4の目標:
すべてが順調なら画像修正、動画編集、3D編集など多様な完全生産能力のシステムが完成します。
v33オーバーレイ
誤解されやすいですが次構造向けのシーン定義フレームワークです。
最も短時間かつ最長時間を要し、アルファ実験を行い機能させる予定です。メッセージ表示だけでなく奥行き制御にも効果的な選択肢になるでしょう。
v34キャラ合成、回転値計画、視点オフセット慎重調整:
特定キャラの存在と指示遵守の確認を重要視します。ときにキャラが存在しないことがあるからです。
度数ベースのピッチ/ヨー/ロール回転評価を実装予定。数学スキルや3Dソフトが足りず完璧ではないですが良い出発点で、既存のFLUXに絡めます。
v35シーンコントローラ
複雑なシーン内相互作用点、カメラ制御、フォーカス、奥行きなどを組み込み、シーン構築とキャラ配置を包括的に管理。
3D版オーバーレイコントローラを想像してください。強化版です。
v36照明コントローラ
区分的でシーン制御された照明制御により、シーン内のキャラ、オブジェクト、創造物すべてに影響。
それぞれの光源はUnrealの複数の照明タイプ、ソース、カラーに基づき配置・生成される予定。
理論的にはFLUXがギャップを補います。
v37体型とカスタマイズ
基本体型導入に続き、より複雑な体型作成を導入予定。例として以下を含みますが限定しません:
正しく動作しないポーズの修正
多彩な追加ポーズの導入
複雑な髪:
物体との相互作用、切れた髪、ダメージ髪、色落ち、多色、結び髪、かつらなど
複雑な目:
さまざまな目のタイプ、開閉、細めなど
多様な表情:
喜怒哀楽、目なし、シンプル、無顔など
耳のタイプ:
尖り、丸み、耳なし等
多彩な肌色:
薄い色、赤、青、緑、白、灰、銀、黒、漆黒、薄茶、茶、濃茶など
敏感な話題を避けつつ衣服のように豊富な色展開を目指します。
腕、脚、上胴体、ウエスト、ヒップ、首、頭サイズ調整:
上腕、肩、肘、手首、手、指などを長さ、幅、周囲で調整。
鎖骨や胴体タグも含む
ウエストおよび関連タグ
1から10の勾配で一般的体型評価。booru系の事前定義システムより柔軟。
v38衣装とカスタマイズ
約200種の衣装とそれぞれカスタムパラメータ。
v39 500以上のゲーム、アニメ、漫画キャラを高忠実度データからサンプリング
500体のキャラ。大量のミーム的キャラではなくデザインや原型に合理的に関連する多くのキャラです。
これ以降は好きなキャラを訓練可能。
大規模な忠実度と品質向上:
様々な高品質アニメ、3Dモデル、写真的リアリズムの数万画像を用い、このfluxバージョンをスタイリスティックかつパラメータに合致させて訓練。
画像はscore_1からscore_10の比率で評価・タグ付けされPonyと類似しつつ、このモデル独自の仕組みを備えます。
V3.2リリース - 4kステップ:
これは子供向けではありません。SFW/QUESTIONABLE/NSFWベースのモデルで、任意の用途にトレーニング可能。
スムッティングメーカではなく、プロンプト次第でNSFWを生成可能です。AIに特定情報を教えると責任も伴うというパッケージです。現在画像構成は概ね33%ずつで、NAIのように安全寄りに重み付けされています。
情報を解禁し教える立場から、利用者がどうするか決定できる仕組みが健全です。完全無修正AIに注意深く教えることは、AIの成長に健全であり、常に悪夢的な画像を見せられることも避けられます。
これは過去に見たどのモデルよりも大きな可能性を示しています。
ComfyUIのワークロードを利用してください。以下の全画像に添付されています。
デフォルトで安全モード有効:
questionable < より疑わしいランダム特性を解禁
explicit < 楽しいものがランダムに表示される解禁
視点起動タグ: "from front", "side view"などを混ぜて試してください。
from front, front view,
from side, side view,
from behind, rear view,
from above, above view,
from below, below view,
主な追加・強化ポーズ:
四つん這い
跪き
しゃがみ
立ち姿
前屈み
もたれかかり
横たわり
逆さま
うつ伏せ
仰向け
腕の配置
脚の配置
頭の傾き
頭の方向
目の方向
目の配置
目の色の濃さ
髪の色の濃さ
胸のサイズ
お尻のサイズ
ウエストのサイズ
多数の衣服オプション
多数のキャラオプション
豊かな表情オプション
性行為ポーズはまだ開発中で、完成するまでは避けてください。私の能力を超えており、進むべきルートが現時点でわかりません。
ポーズメーカー、角度メーカー、状況設定、コンセプト強化、補間構造は準備中で、更に訓練します。
楽しんでください。
V3.2ロードマップ:
2024/8/25 5:16 - プロセスは成功しており、システムは期待以上に高機能です。AIは想定以上に強力な挙動を示し、テストが始まっています。結果は素晴らしいものです。
最終解像度: 512, 640, 768, 832, 1024, 1216
2024/8/25 15時 - すべてのタグ付けとポーズ準備完了。実際のトレーニング開始。多次元テスト、学習率テスト、ステップチェック等でv32の最適候補を評価します。
2024/8/25 4時 - v32初版は1400ステップ付近で軽微な歪み、2200ステップ付近で重度の歪みを示し、怠惰なWD14タグ付けは失敗。手動タグ付けします。楽しい朝になりそうです。
2024/8/24 夕方 - 調理中です。
 これは動かないと思います。すべて自動タグ付けし、ポーズ角度は一時的にクリップ。WD14が自力でどう動くか見ます。成功か失敗か後に元のポーズ角度とタグ順を戻します。意図的なデータがまとまり使用ケース密度が高まった今どうなるか見ものです。
これは動かないと思います。すべて自動タグ付けし、ポーズ角度は一時的にクリップ。WD14が自力でどう動くか見ます。成功か失敗か後に元のポーズ角度とタグ順を戻します。意図的なデータがまとまり使用ケース密度が高まった今どうなるか見ものです。4000枚画像では潜在表現キャッシュに時間かかりそうですが、特定ドールやボディに注力しているため少なくとも問題ないと思います。
2024/8/24 昼 -
 精力的に進めています。
精力的に進めています。 すべて影の示唆的背景を持つフォーマットで、fluxによる表面や位置に基づく画像生成を支援。fluxが扱えないポーズを基にポーズ生成し、多数位置に重ね合わせ可能な主体に焦点を当てる設計。
すべて影の示唆的背景を持つフォーマットで、fluxによる表面や位置に基づく画像生成を支援。fluxが扱えないポーズを基にポーズ生成し、多数位置に重ね合わせ可能な主体に焦点を当てる設計。腕の配置に注力し、重なるタグ付けされた腕が点AからBまで構築されるようにしています。
2024/8/24 朝 - 腕の問題もあるようですがリストに組み込みます。指摘感謝。交差汚染もあるため対処が必要。私は特定のComfyUIループバックシステムを使っており、ウェブ生成には存在しないので、このバージョンではオンサイト生成を無効にするかもしれません。
 2024/8/23 - 均一なポーズ・ピッチ/ヨー/ロール識別子を持つ約340枚の高詳細アニメ画像を用意。胸、髪、尻の色調とサイズ違いも含む。554枚追加予定。V3.2はアニメ向けに重点化後、pony由来の合成リアリズム要素も採取予定。fluxで許可されればfluxだけで済むでしょう。
2024/8/23 - 均一なポーズ・ピッチ/ヨー/ロール識別子を持つ約340枚の高詳細アニメ画像を用意。胸、髪、尻の色調とサイズ違いも含む。554枚追加予定。V3.2はアニメ向けに重点化後、pony由来の合成リアリズム要素も採取予定。fluxで許可されればfluxだけで済むでしょう。 これらはポーズ単位で忠実度と評価の分離を保証。"from"と"view"キーワードの新手法により、理論的にはNovelAIのポーズ制御に極めて近く動くはずで、これが目標です。キャラの差異化は別問題です。
これらはポーズ単位で忠実度と評価の分離を保証。"from"と"view"キーワードの新手法により、理論的にはNovelAIのポーズ制御に極めて近く動くはずで、これが目標です。キャラの差異化は別問題です。すべて整然と並べる必要があります。さもなければ必要な情報を適切にモデルに与えられません。
デフォルトはSAFEモードで構築し、NSFWを有効にする機能を備えます。
このLoRAの複数反復トレーニングを行い、二つのバージョン間の差異を厳格に保ちつつ、NSFW版でより多くのユーザーを満足させます。
訓練後は5万枚の厳選データを投入し、Ponyに匹敵する強力な創造物を作り出す予定。その後はfluxの固有能力とconsistencyの骨格によって利用者が自在にカスタマイズ可能です。
最初のv3.2画像セットの訓練データは整理・訓練・テスト完了後に公開予定。週末にv3データを公開予定です。
寝た姿勢タグのポーズ不整合を特に認識。組み合わせをテストし、底辺の整合性を確保後、次段階のベース衣装選択や変化、効果の評価に移ります。疑わしい・NSFW要素の詳細も後続バージョンで追加予定。次バージョンで察しがつくでしょう。
それまでは指示通りにポーズが機能することを保証するため、新しい意図的組合せキーワードを作成し、ポーズごとの画像数、角度ごとの画像数、状況ごとの角度数を増やします。より複雑な状況・画像生成のためのプレースホルダー的データも作成しますが、fluxは多くを必要としないため段階的に実施。失敗時のデフォルト処理用の"base"タグも導入し、一貫性を高めます。
V3ドキュメント:
主にFLUX.1 Dev e4m3fnのfp8上でテスト済み。準備したチェックポイントのマージはアップロード完了時にこの値を反映。https://civitai.com/models/670244/consistency-v3-flux1d-fp8t5vae
ベースはFLUX.1 Devモデルだが、他のモデルやマージ、LoRAでも動作。結果は混在するため順序を試すこと。
これはFLUXの背骨と言えるもので、danbooruに似た有用なタグを付加しカメラ制御や支援を実現。FLUXが通常扱いづらいカスタムキャラ状況での実現を容易にする。
複数のループバック利用を強く推奨。反復で品質と忠実度が改善される。
個別指向が強いが、解像度の構成により多人数にも対応可。画面即変化するLoRAは文脈貢献しないため無効に近いが、特性追加や相互作用に特化したLoRAは良好。衣類、髪型、性別制御も作動。大半は正常利用可能だが一部無効LoRAもある。
マージではなくLoRAの組合せでもない。このLoRAはNAIとAutismPDXLの合成データにより1年かけて作成。画像セットは複雑で難選択。試行錯誤が膨大にあった。
一連のコアタグを含み、FLUXに無いバックボーンを追加。活性化パターンは複雑だがNAI風キャラを作れば類似の出力になる。
性能は過小評価されるべきでなく、強力なルアであり私の理解を超えている。
注意しないと奇形もあり得る。標準プロンプトかつ論理順序で使えば美しいアートが作成可能。
解像度: 512, 768, 816, 1024, 1216
推奨ステップ数: 16
FLUXガイダンス: 4、頑固なら3-5、非常に頑固なら15以上
CFG: 1
2回のループバックを使い運用。1回目は1.05倍アップスケール+0.72-0.88のデノイズ、2回目は0.8のデノイズでトレンド変化は少ない。特性の導入・除去に応じ調整。
コアタグプール:
anime - ポーズ、キャラ、衣装、顔などのスタイルをアニメ調に変換
realistic - スタイリングをリアル寄りに変換
from front - 人物の正面視点。肩が前方視聴者に向いており胴体中心が視聴者向きの状況。
from side - 人物の側面視点。肩が垂直でキャラが横向き。
from behind - 人物の真後ろ視点
straight-on - 水平面水平視点
from above - 45〜90度の俯瞰視点
from below - 45〜90度の仰視点
face - 顔の詳細に焦点を当てる。頑固な顔のディテールが必要な場合に有効。
full body - 個体の全身視点。複雑なポーズに適す。
cowboy shot - 標準的なカウボーイショットタグ。アニメには比較的合うがリアルには合いづらい。
looking at viewer, looking to the side, looking ahead
facing to the side, facing the viewer, facing away
looking back, looking forward
混合タグは意図した混合結果を生みますが結果にバラツキがあります
from side, straight-on - 水平面で個体側面を狙ったカメラ
from front, from above - 正面上方から45度俯瞰
from side, from above - 側面上方から45度俯瞰
from behind, from above - 背面上方から45度俯瞰
from front, from below
from front, from above
from front, straight-on
from front, from side, from above
from front from side, from below
from front from side, straight-on
from behind, from side, from above
from behind, from side, from below
from behind, from side, straight-on
from side, from behind, from above
from side, from behind, from below
from side, from behind, straight-on
これらのタグは似て見えますが順序で全く違う結果になります。例えばfrom behindタグをfrom sideより先に付けると背面寄りに重みづけされ、上胴体がひねられ45度体が傾くことがよくあります。
結果は混合しますが十分に使えます。
特性、色彩、衣装なども効果的です
赤髪、青髪、緑髪、白髪、黒髪、金髪、銀髪、ブロンド、茶髪、紫髪、ピンク髪、水色髪
赤目、青目、緑目、白目、黒目、金目、銀目、黄目、茶目、紫目、ピンク目、水色目
赤ラテックススーツ、青ラテックススーツ、緑ラテックススーツ、黒ラテックススーツ、白ラテックススーツ、金ラテックススーツ、銀ラテックススーツ、黄ラテックススーツ、茶ラテックススーツ、紫ラテックススーツ
赤ビキニ、青ビキニ、緑ビキニ、黒ビキニ、白ビキニ、黄ビキニ、茶ビキニ、紫ビキニ、ピンクビキニ
赤ドレス、青ドレス、緑ドレス、黒ドレス、白ドレス、黄ドレス、茶ドレス、ピンクドレス、紫ドレス
スカート、シャツ、ドレス、ネックレス、フルコスチューム
複数素材:ラテックス、メタリック、デニム、コットンなど
ポーズはカメラと連動しない場合や調整が必要な場合もあります
四つん這い
跪き
横たわり
横たわり、仰向け
横たわり、横向き
横たわり、逆さま
跪き、背面
跪き、正面
跪き、側面
しゃがみ
しゃがみ、背面
しゃがみ、正面
しゃがみ、側面
脚などの制御は特に細かく動作させる必要があるので操作してみてください
脚
脚を揃える
脚を開く
脚を広げる
足を揃える
足を広げる
数百のタグが使われており、数百万の組合せが可能
これらは個人の特性指定の前に、flux自身のプロンプトの後ろに組み合わせて使うのが良いです。
プロンプト:
とにかくやってみてください。何を書いてもいいです。FLUXには多くの情報が入っているので、ポーズなどで画像を強化してください。
例:
キッチンで椅子に座っている女性、側面から、上から、カウボーイショット、1人、座っている、側面、青髪、緑目

空を飛ぶスーパーヒロインが岩を投げている。周囲は強力で不気味な光のオーラがある。リアル、1人、下から、青ラテックススーツ、黒のチョーカー、黒い爪、黒い唇、黒い目、紫髪
 レストランで食事中の女性、上方から、背面から、四つん這い、お尻、Tバック
レストランで食事中の女性、上方から、背面から、四つん這い、お尻、Tバック うまくいきました。通常はうまく動きます。
うまくいきました。通常はうまく動きます。
基本的にほとんどの表現に対応可能ですが非常に複雑で、私の理解範囲外になる場合もあります。混沌を抑え、コアで有用なタグに絞って活用してください。
430回以上の失敗を経て遂に成功理論に辿り着きました。使用した訓練データは週末にまとめて公開予定です。長く困難な道のりでした。皆様の楽しみになりますように。
V2ドキュメント:
昨夜は疲れていて完全なまとめができませんでした。可能な限り早く、仕事中にもテストし値を記録しながら書き上げます。
Flux トレーニング概要:
以前はPDXLがdanbooruタグ付き少数画像でNAIに匹敵するfinetuneをしていましたが、今回少数画像は効果がなく、より多くのパワーが必要でした。
モデルは多くの情報を持ち、学習データの分散が予想以上に大きいです。より多くの分散は潜在能力の増大を意味し、なぜこれが効くのか理解に苦しみました。
調査後、このモデルが強力な理由はそこにありました。これは深さに基づき「指示」された画像を生成し、一枚の画像上に別の画像のノイズをガイドとして重ね合わせて分割・層化します。どうやってこれをコアの詳細を壊さず訓練するか考えました。拡縮、バケット化など検討しました。最初は何も考えず提案設定で始め、結果により調整。遅いプロセスなので文献も読みながら進めています。もし時間があれば50台同時運用も考えましたが一人では無理なので金をかけることも考えましたが設定は諦めました。
SD1.5, SDXL, PDXL LoRA訓練の経験から最良と思うフォーマットで始めました。良好でしたが明確に問題もあります。
訓練フォーマット:
数回のテスト実施。
テスト1 - danbooruランダム750枚:
UNET LR - 4e-4
他の要素は大半デフォルトで良いが、解像度バケット分けが重要。
1024x1024中心切り取り
2000〜12000ステップ
danbooruタグプールから750枚無作為抽出し、タグは均一化。
moat taggerでタグ付けし、タグファイルに追記。上書き防止。
結果は混沌。新規の人間要素(性器等)は出たり出なかったり、多くは存在しない。これは他の調査報告に一致。
タグの重複は少ないと考えていたため、これほどモデル全体に影響があるとは思わなかった。
2回試し、どちらも12kステップ付近でLoRAは無意味。1k〜8kでの乖離もほぼなくピークと谷に顕著な偏差なし。
何か見落としがあると感じた。人間やclip説明ではない「何か」がある。
失敗直前に発見したのは、この深度システムは2種の全く異なるプロンプトの補間と協調で成り立っていること。これら2つは補間的かつ協力的で使われ方は不明。数学的解析のため論文を調査中。
テスト2 - 10枚:
UNET LR - 0.001 <<< 非常に高い学習率
256x256, 512x512, 768x768, 1024x1024
初期ステップは少し変異が見え、SD3テストの焼き込みに似た感じ。ただし悪影響が発生。500ステップ付近から流出開始。1000ステップでほぼ無意味となる。繰り返し学習的な意味合いで失敗実験。
変異は強烈で、新しい文脈要素を導入後、一気に壊れてしまう。人の要素を見事に破壊し、ひどく設定されたインペイントと似た跡を残す。FLUXの耐性には驚き、攻撃には非常に強い。
失敗。別条件テストが必要。
テスト3 - 500ポーズ画像:
UNET LR - 4e-4 <<< これは4分割しステップ数を2倍にすべき。
完全バケット化 - 256x256, 256x316など多様サイズを野放し。予想外の結果。
結果はこのConsistencyモデルの核そのものであり驚異的。少し悪影響もあったが重要。
注目すべきは、一般的にアニメは被写界深度を使わず、このモデルは被写界深度とぼかしで深度を区別していること。これを担保する深度コントロールネットが必要だが詳細不明。深度マップと通常マップの併用が可能性だが、負のプロンプトが無いため破壊リスクもあり。
更なるテスト、追加データ、情報が必要。
テスト4 - 5000画像整合バンドル:
UNET LR - 4e-4 <<< 40分割しステップ数は20倍が望ましい。短期間でコアモデルに組込むのは容易でない。現行プロセスは数学的に適切でなく壊れるリスクがあるため初期結果を公開。
詳細な記述と続編があったが誤って消去し、後で書き直す必要あり。
大失敗点:
学習率が12kステップのLoRAに対して高すぎた。システムは勾配学習に基づくが、学習率が高すぎると情報保持が壊れる。モデルの再訓練になってしまった。欲しいものが不明確だったため、非指示的かつ勾配深度なしで失敗は必須であった。
FLUXのスタイルはPDXLやSD1.5のスタイルとは異なる。勾配システムはスタイライズするが、大量情報を急速に詰め込むと構造は大きく壊れる。PDXL LoRAは既存情報を拡張する性質なので破壊は少なめ。
重要な発見:
ALPHAが極めて重要。システムはアルファ勾配に大きく依存し、写真ベースの距離、深度、比率、回転、オフセットなどすべてが構成に不可欠。単一プロンプトでなく複数詳細が必須。
すべてを正しく説明すべき。単純なdanbooruタグはスタイルのみ。システムが想定するスタイルを認識させ、新規概念を適切に割り当てるタグが必要。さもなければゴミ出力になる。
ポーズ訓練は大規模ポーズ情報利用で非常に有効。既に多くのタグは認識済みだが何を認識するかは不明。タグ組織化と微調整に効果的。
ステップDocumentation;
v2 - 5572枚 -> 92ポーズ -> 4000ステップ FLUX
NAIをSDXLに持ってくる目標はFLUXにも適用された。今後のバージョンに注目。
安定性テストでPDXLを凌ぐ潜在能力を確認。追加訓練が必要だが低ステップで強力。
ポーズ第一層は約500枚で十分な見込み。整理でき次第HuggingFaceでデータセット公開予定。誤った画像やゴミ混入は避けたい。
続きは以下で:
https://civitai.com/articles/6983/consistency-v1-2-pdxl-references-and-documentation-archive
重要参考文献:
私は喫煙しませんが、FLUXには時々煙が必要です。
ワークフローと画像生成補助ツール。基本はコアノード中心だが実験や保存に他も活用。
非常に強力だが理解困難なAIモデル。潜在能力は多大。
彼らなしでは本モデル作成の動機はなかった。スタッフに感謝。絶大な画像生成力と最強の文章補助を持つ。投資を推奨。
Fluxを開発し柔軟性の大半を作り出した功労者。私は単に調整し導いているに過ぎない。
強力なタグ補助。自作しようとしたが見つけたパワフルなツール。
Flux版の訓練に使用。やや癖があるが複数システムで使えて仕事をこなす。
ライバルでありインスピレーション源。巨大な勾配場を生むモンスターで研究に不可欠。

モデル詳細
ディスカッション
コメントを残すには log in してください。
![Old Consistency V32 Lora [FLUX1.D/PDXL] Feminine v1.1 - e500 PDXL](https://diffus-s3.b-cdn.net/images/gallery/thumbnails/model_533690_be70b0496a7b4f37b5ae5a53be1892d6.webp?fit=cover)
















































